匿名职言 当大数据平台在一些配置普通的物理机上时,有必要进行测试吗?
运维提供了搭建好的 CDH 后,我发现环境存在问题,什么任务都没运行,内存和磁盘的占用率都很高,如下图:
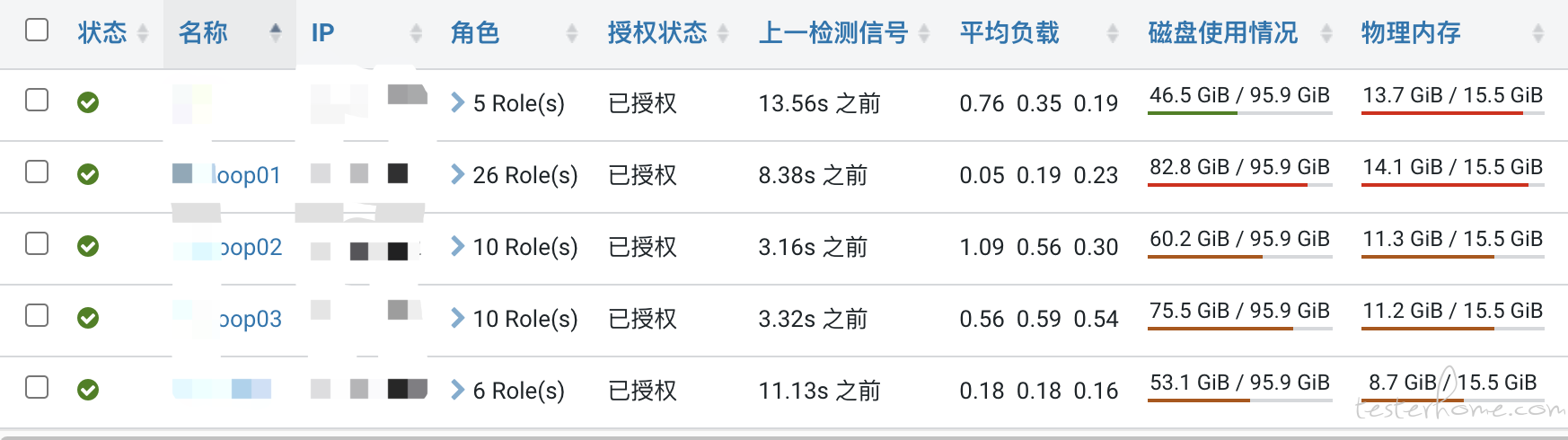
一开始我想到是否是运维采取在少量物理机上,使用虚拟化部署的方式搭建的,于是找运维沟通确认是使用物理机还是虚拟机,运维答复物理机。
公司部门层级管理严格,物理机的连接用户名等信息,不能给出。我就一边建议运维帮忙查找原因帮忙修复,一边和领导说明情况申请获得连接信息。我这边尝试先用小数据量跑一些任务,例如:数据导入导出,输出处理,打标等,结果有坑不说,还慢的可怕...
等了些日子后,我拿到了登录服务器的信息,我分别查了这几台的磁盘信息,内存信息,进程占用信息,分析得出这个 CDH 集群就是采用虚拟机方式搭建,于是再次找到运维反馈,运维的答复是 “我理解岔了”,我真的想...
那么如果你是我,你会怎么办?
有条件的话,硬件资源方面,尽可能将测试环境的配置与客户的环境是一致的
我公司一台机就 256G 了,16G 内存太小啦。磁盘是有几个 2T 的
如果我是你,給運維兩巴掌
讓他長長記性
部署环境问题肯定要解决了再测
你的配置挺不错的呀,结合实际经验而言,大数据算力想要上去,内存和磁盘的配置要求并不低,目前这个环境配置太差了。好比自行车当小汽车,想要载人快跑,奈何自身水平有限。 
用这个配置 部署 CDH 是搞笑么。。。。。。 咱们 尊重一下大数据吧。。。。。 这个配置跑不起来什么大数据任务的。
建议在流程上可以改进一下,比如部署环境前,说清楚你的最低环境配置要求,环境部署完毕后,写一个测试脚本验证环境配置是否满足你的要求。
嗯嗯,我知道这个配置不能跑不起来大数据任务,之前了解大数据,硬件环境要求:物理机配置内存推荐都是 128G,至少 64G,OS 盘至少 300G,数据分区磁盘至少 6 块,CPU 也要双路的。但目前根据实际数据量规划磁盘容量,内存,我没有相关方面的经验... 大佬有例子可以参考吗?
欢迎探讨~
1、根据业务需求,了解此次大数据平台的数据功能和非功能要求。例如:存储的数据,具体数据的大小、特点等占比
2、假设大数据平台需要满足全量 1PB 数据的存储要求,根据数据的特点,大概 30% 为结构化数据,70% 为非结构化数据,并以此进行估算。
其中:
结构化数据的数据量为: 1PB*30%=0.3PB=307TB(结构化数据全部进入数据仓库)
对于结构化数据存储容量要求为: 307TB*(3+1+0.5)/3*1.3=599TB
注:对结构化数据,采用 3 倍副本冗余存储,1 倍中间结果余留,0.5 倍索引存储空间,3 倍数据压缩,0.3 倍空间余留。
非结构化数据的数据量为: 1PB*70%=0.7PB=717TB
对于非结构化数据存储要求为: 717TB*3=2151TB
非结构化数据采用 3 倍副本冗余存储。
全量数据存储容量要求为:
599TB(结构化数据)+2151TB(非结构化数据)=2750TB
DataNode 单节点存储容量推荐配置为:4TB*12=48TB
基础 Hadoop 平台 DataNode 节点数为:2750TB/48TB=58 节点
因此,DataNode 服务器推荐配置为
CPU 两路 8 核处理器 E5-2650 v3 或以上
内存 64GB 及以上
硬盘 SAS 盘 2 个 600G 做 RAID1,SATA 盘 12 个 4TB 不做 RAID1
网络 最好是双口万兆网卡
此外:对于大规模的 Hadoop 集群,需单独规划
Zookeeper 3 个节点,NameNode 1 个节点,Resource Manager 个节点,HMaster 3 个节点,总共 3+1+1+3=8 个节点
针对 NameNode,Zookeeper,Resource Manager,HMaster 等角色的功能和性能要求,服务器建议采用如下配置
CPU 两路 8 核处理器 E5-2650 v3 或以上
内存 128GB 及以上
硬盘 SAS 盘 2 个 300G 做 RAID1,SAS 盘 7 个 300G 不做 RAID1
网络 最好是双口万兆网卡
综上,基础 Hadoop 平台节点规模为 58+8=66 节点
...
此外还有数仓集群配置,存储结构化数据,并提供高复杂度、高负载的计算、分析任务,提供数据仓库、数据集市等功能
预计 31 台
总共 66+31=97 台
计算节点有条件的可选 SSD ,此外还有需万兆交换机若干,机柜若干
3、横向纵向扩展都支持的,若后续随着集群规模的扩展可增设核心数据层交换机,向下负责汇聚多个集群节点...
大数据很烧钱的,如果数据量没那么大,搭建大数据平台的成本收益不成正比... 量力而行!!!