问答 请教一下,爬虫怎么爬取知乎话题下面所有回答的图片
先获取全部的回答,然后在去获取图片。但是一次性获取太多回答,前端页面会崩溃
# -*- coding: utf-8 -*-
from time import sleep
import ahttp
import urllib.request
import re
import socket
import os
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36 "
}
a = []
b = []
cc = []
qq = 0
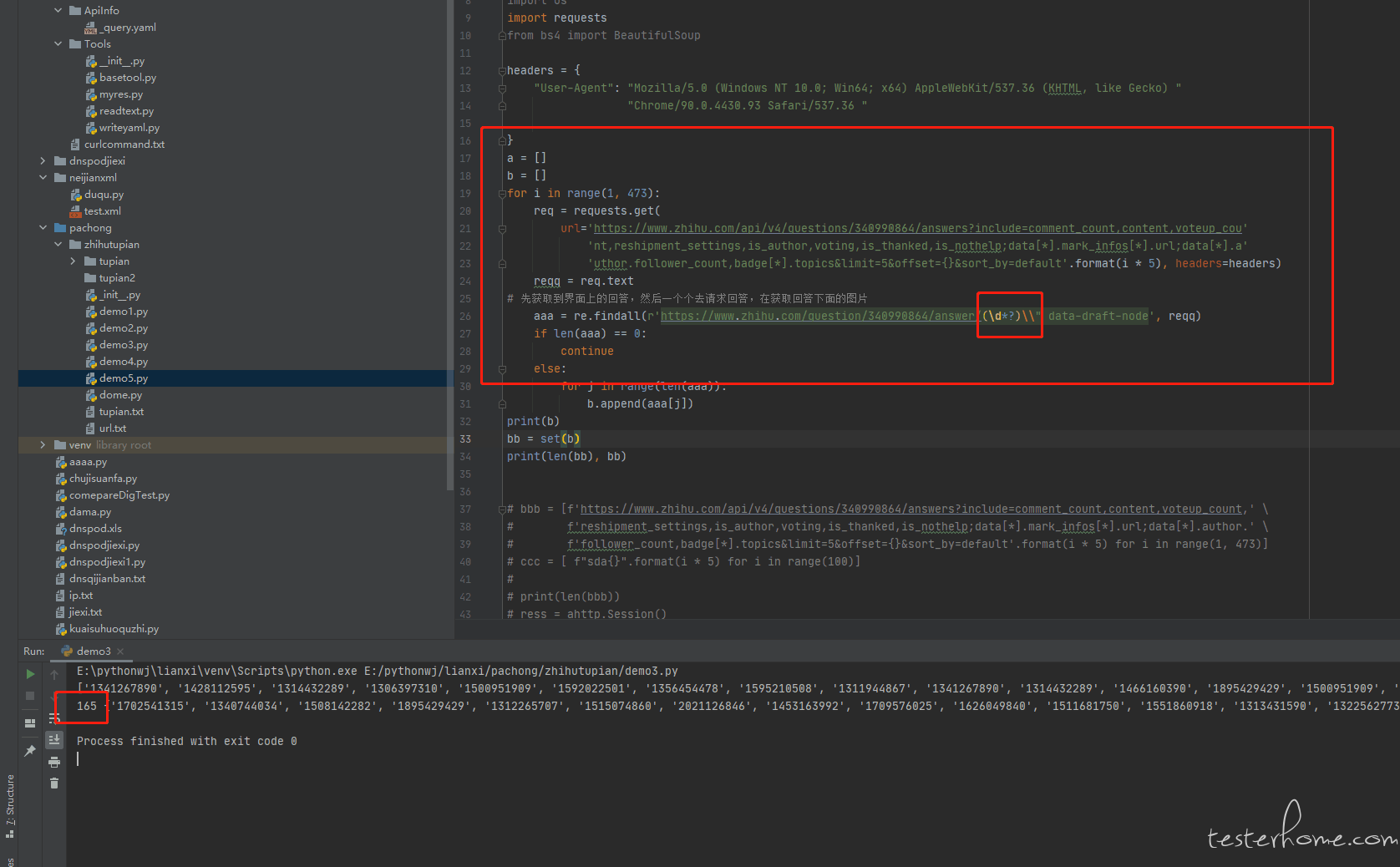
for i in range(0, 467):
req = requests.get(
url='https://www.zhihu.com/api/v4/questions/340990864/answers?include=comment_count,content,voteup_cou'
'nt,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].a'
'uthor.follower_count,badge[*].topics&limit=5&offset={}&platform=desktop&sort_by=default'.format(3 + qq),
headers=headers)
sleep(5)
qq += 5
if 3 + qq > 467:
break
reqq = req.text
# print(reqq)
# 先获取到界面上的回答,然后一个个去请求回答,在获取回答下面的图片
aaa = re.findall(r'https://www.zhihu.com/question/340990864/answer/(\d*)', reqq)
print(aaa)
print(3 + qq)
if len(aaa) == 0:
continue
else:
for j in range(len(aaa)):
b.append(aaa[j])
print(len(b), b)
bb = list(set(b))
print(len(bb), bb)
bbb = [f"https://www.zhihu.com/question/340990864/answer/" + str(bb[i]) for i in range(len(bb))]
print(len(bbb))
ress = ahttp.Session()
res1 = [ress.get(url) for url in bbb]
res2 = ahttp.run(res1)
tupian = []
m = 0
for j in range(len(bb)):
res3 = res2[j].text
tu = re.findall(r'https://pic2.zhimg.com/v2.*?\.jpg', res3)
if len(tu) == 0:
continue
else:
for k in range(len(tu)):
tupian.append(tu[k])
print(len(tupian), j)
tupian2 = set(tupian)
print(len(tupian2))
while m < len(list(tupian2)):
print(list(tupian2)[m])
urllib.request.urlretrieve(list(tupian2)[m], filename='./tupian2/' + str(m) + '.jpg')
m += 1
print(m)
看你截图,你这个爬虫不是访问服务端接口么,为啥会说前端页面崩溃?没理解这个点。
访问的不是服务器端口,是 url 链接。只能获取到前 20 几个回答,然后后面的回答获取不了,如果 offset 的值太大了,只能获取到一个回答
抓包返回的都是回答的 id,然后接口通过回答 id 进行访问。知乎的回答不是翻页的,是底部触发返回的,所以回答太多,前端页面会崩溃
我还是没明白,你的前端页面崩溃到底是啥概念。你这里没有用到 selenium 通过浏览器实际打开页面,只不过是通过请求接口,获取了一个 html 格式的返回值内容。
我理解的前端页面崩溃应该是 js 执行耗费资源过多,导致整个前端卡死没反应,但这种是浏览器打开才会有的,你这个接口返回值不应该有?
然后底部触发返回,我理解本质上也是翻页。翻页不只是真正界面看到上一页下一页,拉到底获取新内容也属于翻页的一种。翻页的本质应该是通过分页限制单次返回内容的个数,避免一次性返回过多内容,引起各种性能问题。
抱歉,这里是我的表达有问题。获取返回的一个 html 格式的返回内容,html 格式的返回内容里面的内容太多了,会导致 html 返回的值只会有一个回答,其他的回答不会返回。
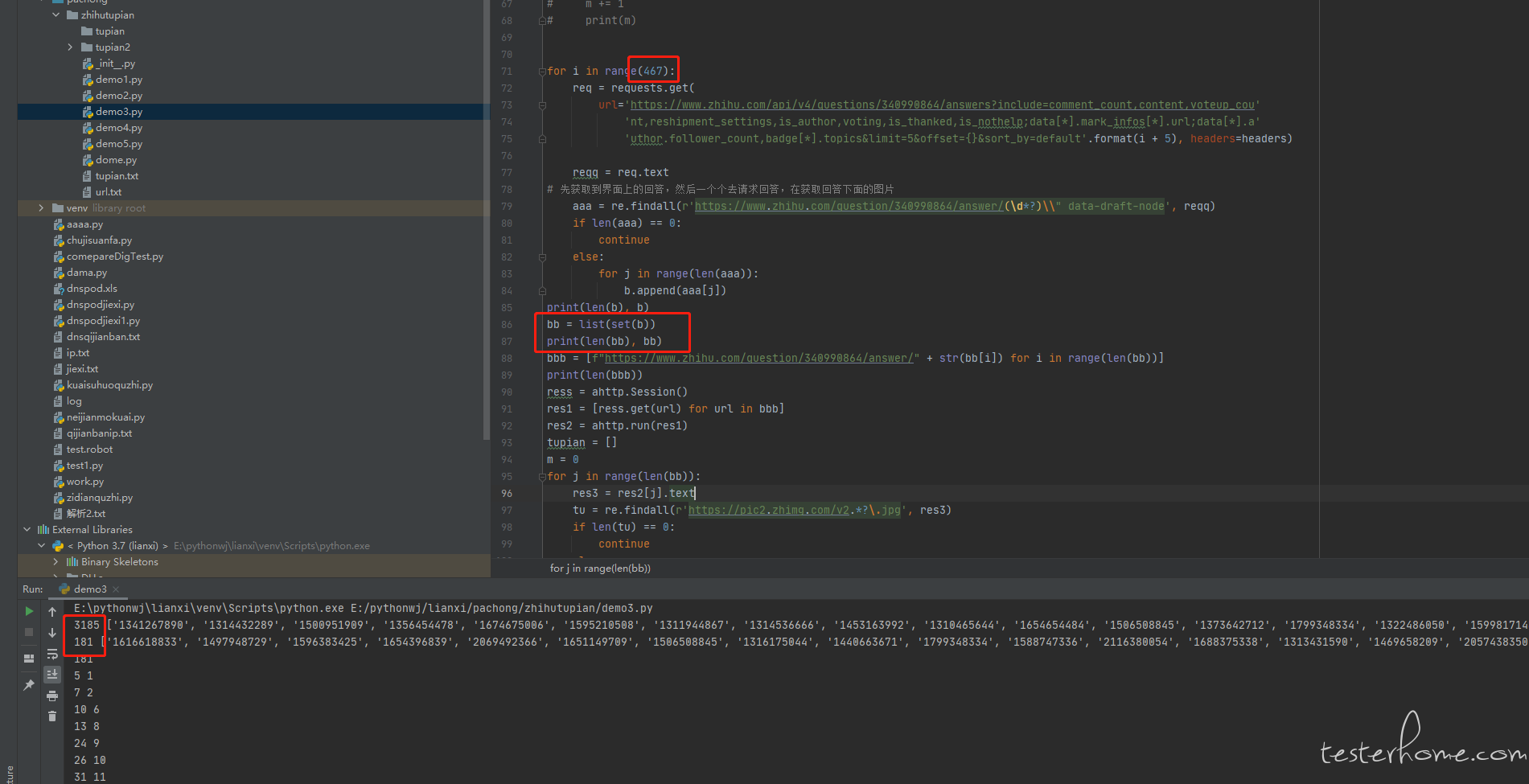
这个回答下面一共有 467 个回答,我通过这样去请求,只会获取到 181 个回答,其他的回答就获取不到,如果把 467 设置为更大的值,获取到的还是 181 个回答
这个回答下面一共有 467 个回答,我通过这样去请求,只会获取到 181 个回答,其他的回答就获取不到,如果把 467 设置为更大的值,获取到的还是 181 个回答
后端的防护性编程,为了防止前端传参过于离谱导致数据库压力过大,合理操作。你就自己设置一个合理 offset 分几次循环去请求就行了,也没必要非得一个请求拉下来所有回答。如果你嫌弃 for 循环串行请求耗时长,你就上多线程或者异步,网上很多资料。
看了下知乎现在的前端界面,基本是通过类似 app 的方式,下滑到底部请求下一页的内容,直到达到最后一页。
然后看了下你的逻辑,有几个奇怪的地方:
1、offset 按照知乎目前的方式,表示的应该是当前页面第一条记录从实际数据库第几条开始。知乎貌似是固定每页 5 条数据,所以 offset 应该是 1、6、11 这样的。你这里面 offset 是 i+5,i in range(467) ,意思是 offset 的值是 6、7、8...472 ,逻辑不大对吧?
2、只能拿到 181 个回答,有打印看过每个接口请求的返回值,大概循环到第几次的时候,返回值数据开始不正常么?你这里 for 循环没有任何控制速度的措施,都是以最高速度循环获取,有很大可能触发了知乎的接口单 ip 访问的限流策略,直接不返回回答,导致你得到的回答数不增加(你用正则获取,所以也不会抛异常,只是匹配不到任何回答而已)。181 这个统计数据只是个结果,需要有每次接口的具体返回值这些过程数据才能定位问题呀。
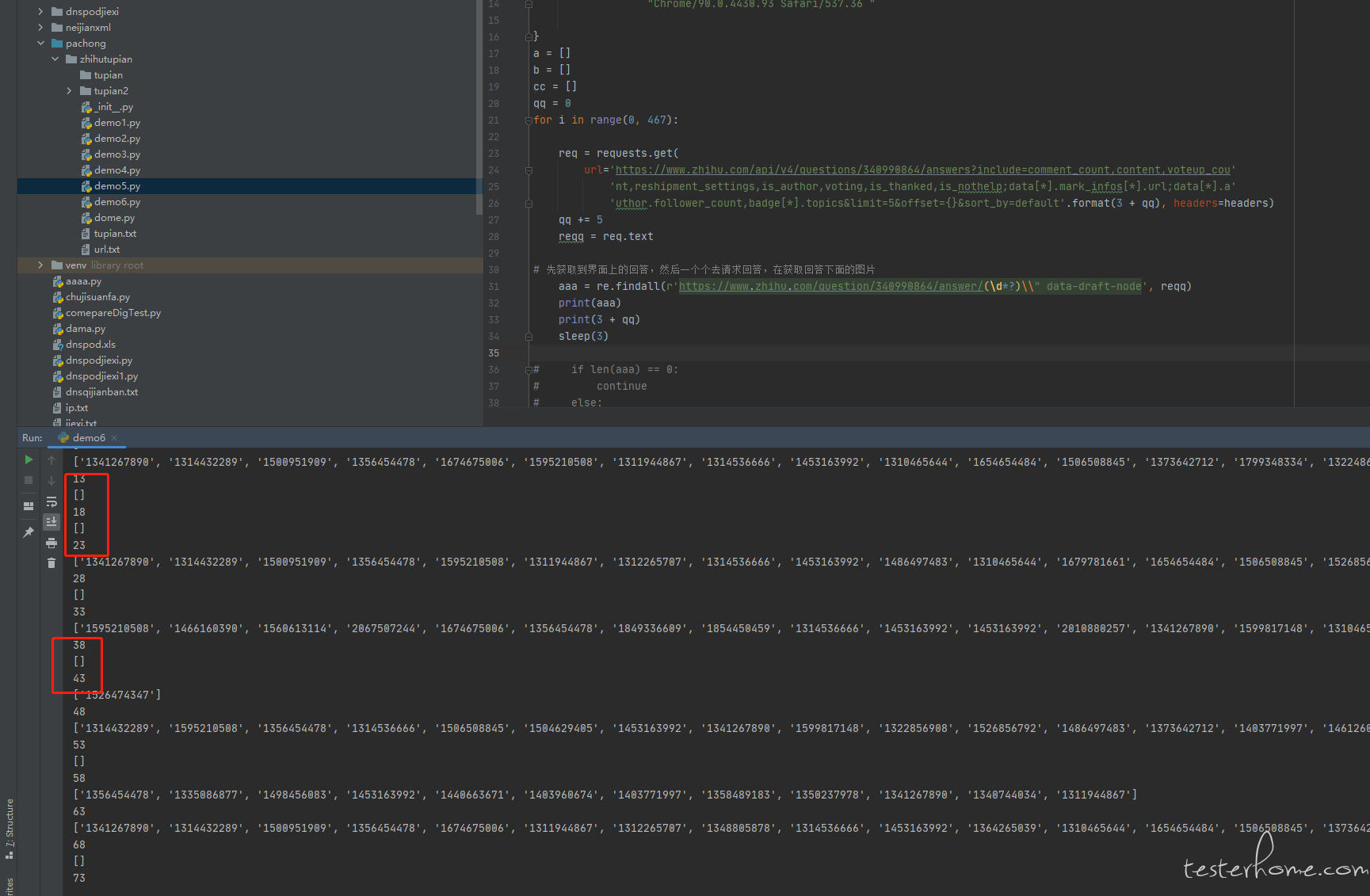
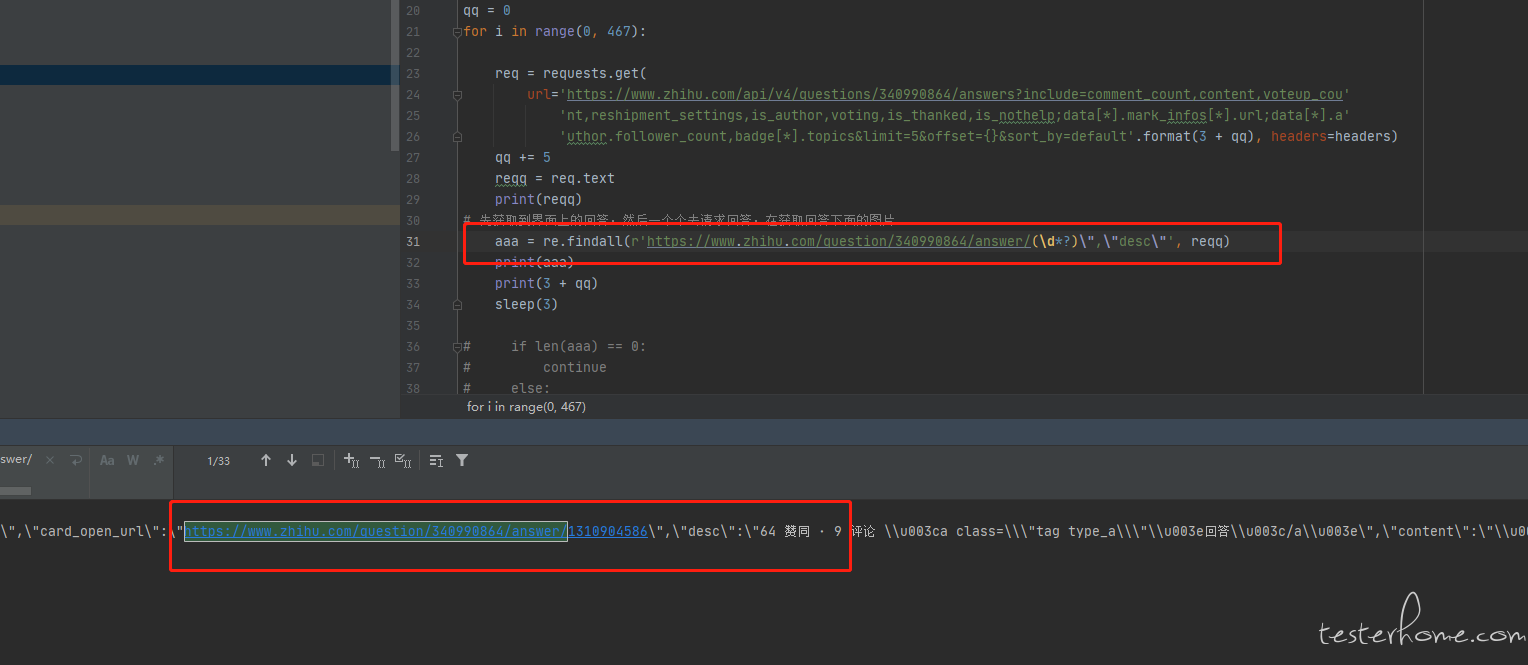
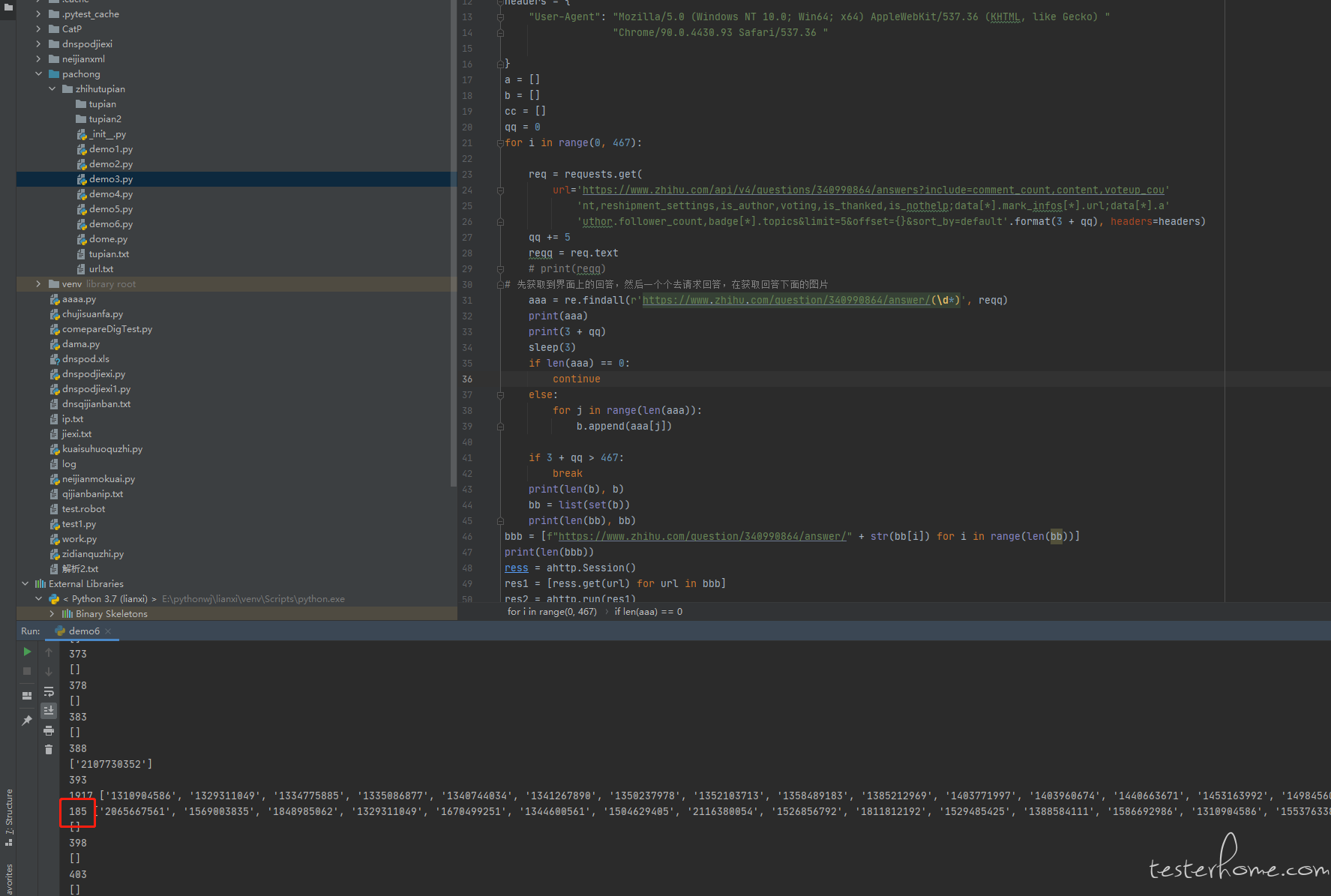
你这个逻辑不大对呀,request 的 get 方法,如果响应超时导致没有返回,应该会抛异常的,而不是导致你的正则表达式匹配不到答案。知乎的服务器不至于那么差,offset 大点返回值就出问题。
你把你这部分爬虫的代码直接用 markdown 的代码块贴出来吧,看截图好累。具体 markdown 怎么写代码块,可以看看右下角的排版说明。
也建议你代码里加一个逻辑,凡是回答数为 0 的,都打印原始返回值,你自己看看到底是返回值格式变了导致你获取不了,还是格式没变单纯你正则没写好所以没匹配。
-- coding: utf-8 --
from time import sleep
import ahttp
import urllib.request
import re
import socket
import os
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36 "
}
a = []
b = []
cc = []
qq = 0
for i in range(0, 467):
req = requests.get(
url='https://www.zhihu.com/api/v4/questions/340990864/answers?
'include=comment_count,content,voteup_cou'
'nt,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[].mark_infos[].url;data[].a'
'uthor.follower_count,badge[].topics&limit=5&offset=
'{}&platform=desktop&sort_by=default'.format(3 + qq),
headers=headers)
sleep(5)
qq += 5
if 3 + qq > 467:
break
reqq = req.text
# print(reqq)
# 先获取到界面上的回答,然后一个个去请求回答,在获取回答下面的图片
aaa = re.findall(r'https://www.zhihu.com/question/340990864/answer/d*)(\', reqq)
print(aaa)
print(3 + qq)
if len(aaa) == 0:
continue
else:
for j in range(len(aaa)):
b.append(aaa[j])
print(len(b), b)
bb = list(set(b))
print(len(bb), bb)
bbb = [f"https://www.zhihu.com/question/340990864/answer/" + str(bb[i]) for i in range(len(bb))]
print(len(bbb))
ress = ahttp.Session()
res1 = [ress.get(url) for url in bbb]
res2 = ahttp.run(res1)
tupian = []
m = 0
for j in range(len(bb)):
res3 = res2[j].text
tu = re.findall(r'https://pic2.zhimg.com/v2.?\.jpg*', res3)
if len(tu) == 0:
continue
else:
for k in range(len(tu)):
tupian.append(tu[k])
print(len(tupian), j)
tupian2 = set(tupian)
print(len(tupian2))
while m < len(list(tupian2)):
print(list(tupian2)[m])
urllib.request.urlretrieve(list(tupian2)[m], filename='./tupian2/' + str(m) + '.jpg')
m += 1
print(m)
我这个是只获取一个固定话题下面的回答,回答数不会为 0 ,获取不到回答的时候我看了 html 格式返回的内容,返回的全部都是图片,没有回答
# -*- coding: utf-8 -*-
from time import sleep
import ahttp
import urllib.request
import re
import socket
import os
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36 "
}
a = []
b = []
cc = []
qq = 0
for i in range(0, 467):
req = requests.get(
url='https://www.zhihu.com/api/v4/questions/340990864/answers?include=comment_count,content,voteup_cou'
'nt,reshipment_settings,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].a'
'uthor.follower_count,badge[*].topics&limit=5&offset={}&platform=desktop&sort_by=default'.format(3 + qq),
headers=headers)
sleep(5)
qq += 5
if 3 + qq > 467:
break
reqq = req.text
# print(reqq)
# 先获取到界面上的回答,然后一个个去请求回答,在获取回答下面的图片
aaa = re.findall(r'https://www.zhihu.com/question/340990864/answer/(\d*)', reqq)
print(aaa)
print(3 + qq)
if len(aaa) == 0:
continue
else:
for j in range(len(aaa)):
b.append(aaa[j])
print(len(b), b)
bb = list(set(b))
print(len(bb), bb)
bbb = [f"https://www.zhihu.com/question/340990864/answer/" + str(bb[i]) for i in range(len(bb))]
print(len(bbb))
ress = ahttp.Session()
res1 = [ress.get(url) for url in bbb]
res2 = ahttp.run(res1)
tupian = []
m = 0
for j in range(len(bb)):
res3 = res2[j].text
tu = re.findall(r'https://pic2.zhimg.com/v2.*?\.jpg', res3)
if len(tu) == 0:
continue
else:
for k in range(len(tu)):
tupian.append(tu[k])
print(len(tupian), j)
tupian2 = set(tupian)
print(len(tupian2))
while m < len(list(tupian2)):
print(list(tupian2)[m])
urllib.request.urlretrieve(list(tupian2)[m], filename='./tupian2/' + str(m) + '.jpg')
m += 1
print(m)
本地调试了下你的完整代码,看到了完整的知乎接口返回值,终于知道足够的细节了。。。
先说明下,为啥你会拿不到,原因是你这个正则匹配的内容就不对。
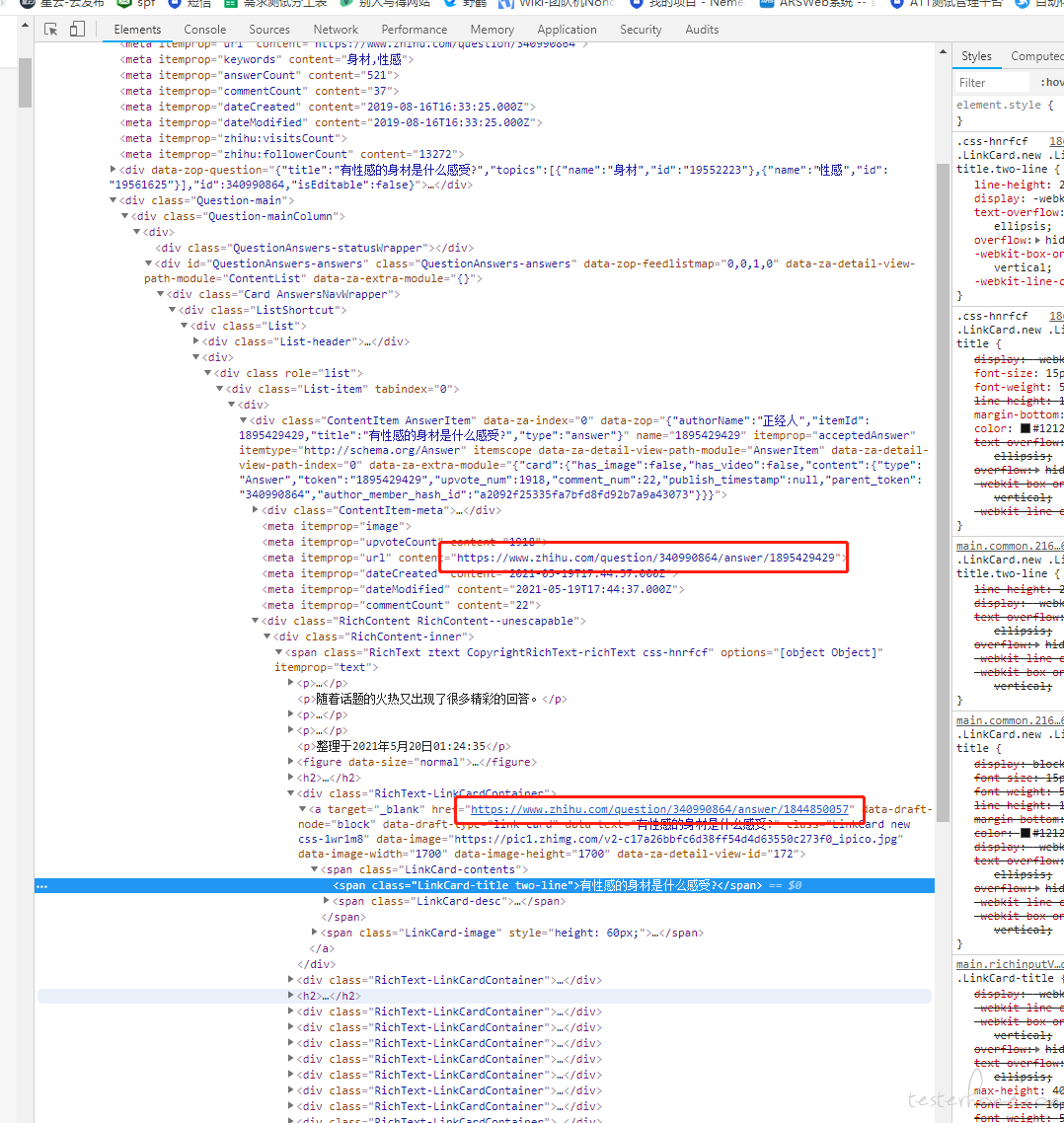
你这个正则匹配的值,实际上只会在返回值 json 里面一个 "link_card_info" 字段里的 key 会匹配得上,而这个字段对应的展示内容,实际是回答里的引用其他回答样式,类似下图(我直接在 chrome 浏览器搜索能匹配你正则的 url ,就找到这个 html 元素了):
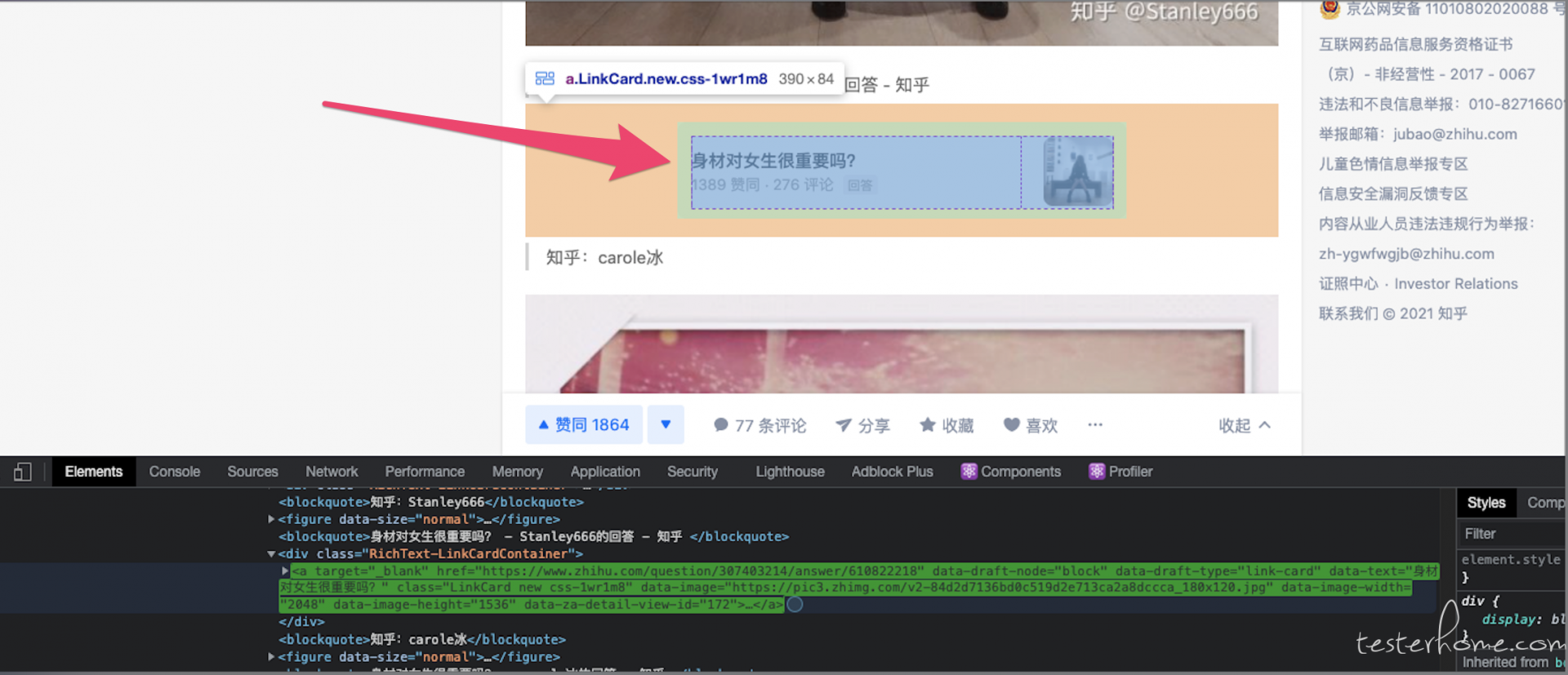
你得到的 184 ,代表的是所有回答里一共有 184 个引用其他回答的内容。和这个问题一共有多少个回答,是两个完全不同的概念。。。
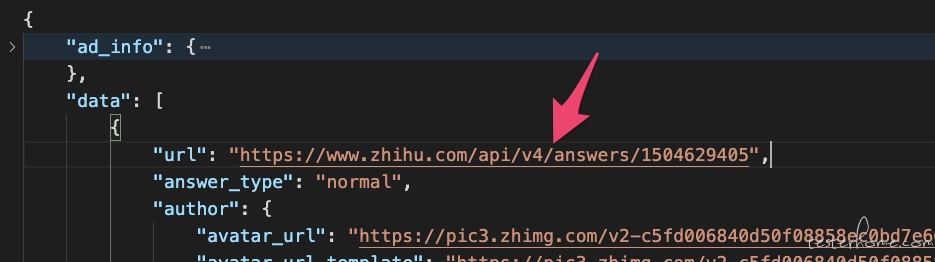
要想拿到所有 400 多个回答的独立地址,个人感觉应该拿 data 里面的这个地址,具体你可以试验一下:
提几个建议:
1、爬虫少用正则,多用 path 型的匹配或者直接代码解析数据。json 可以用 jsonpath ,html 可以用 xpath 。直接正则看起来省力,实际规则太宽松,非常容易匹配错误,而且导致你偷懒不去研究清楚返回值和界面内容的对应映射关系,出现方向完全错误的问题。
2、代码里变量命名永远、永远、永远不要用 aaa、bbb 这些无意义字符。要看懂你这段逻辑太费劲,看到一个变量还得去看变量怎么来的才知道这个变量是啥,阅读效率大幅度下降。
3、提问的时候,要 尽可能把问题描述得足够清楚 。有具体数据的直接给具体数据,不要文字概括性描述。 talk is cheap , show me your code 。如果自己不知道要提供多少信息,就直接把你的代码贴出来。只要有代码,就有办法本地跑,跑起来才能最自由地得到所有信息。
好的 谢谢,非常感谢您提的意见。这个正则的匹配方式是我按照前端界面的 url 去匹配的,不知道匹配到的是引用其他回答。
因为获取的是 html 的格式返回内容,会获取到回答的 ID,然后也会获取到这个回答下面引用的回答的 ID,然后在通关 ID 去进行访问,这样加起来只有 181 个,所以看起来就很懵
建议后续可以你先对比下接口数据和当时的浏览器界面对应关系,确认有 2-3 个都和对应关系匹配上,这个字段确实满足需要。先根据经验提出假设没问题,假设的验证也要做好。你这次的问题就在于验证做得不够严谨,发现有匹配就认为是对了,没有确认匹配的数量是否对的上界面实际看到的回答数。
也分享下我当时是怎么一步一步分析到这个正则不大对的,你后面可以参考下:
1、跑起程序后,先 print 一个返回值。看到里面有匹配正则的,但位置怪怪的,和常见的分页不大一样(一般分页每一页的内容个数是固定的,但这个和正则匹配的值每一页数量都在变,比较奇怪)
2、重点看正则匹配数量为 0 的,发现返回值格式其实没啥大的差异,只是返回值没有能匹配正则的值。再用在线 diff 工具看一下有匹配和没匹配的返回值,会比较明显看出是因为 link_card_info 字段缺失了所以没有任何匹配。说明这个字段是个可选字段,应该不是一个回答有一个值这样的固定字段。
3、到这里已经比较确定获取的字段不大对了,但还是很疑惑 link_card_info 到底是干嘛的,为啥有的有有的没有,所以打开浏览器上知乎,通过 network 查看翻页请求的返回值,刚好第一页就有 link_card_info ,拿里面 2-3 个值在开发者工具的 elements 里搜(这里是计算后的结果,和看到的内容是完全实时同步的,所以只要界面有显示这里都能被搜到),就看到原来这个字段的值对应的是上面截图里的 引用外部回答 了。这样整个逻辑就很清晰了。

正则匹配到很少回答 ID 或者没有的时候,html 返回的格式内容里面的图片很多,都是一些图片,没有回答的 ID 了
先修正一下你的术语用法,用的不大对。这样会造成沟通上有很大的误差。
知乎 api 接口返回值的格式是 json ,不是 Html 。里面没有 html 标签,所以不应该被称为 “html 返回的格式”
html 内容实际是前端的 javascript 脚本,基于这个 json 再去生成出来的。你的爬虫没有这个前端 javascript 的部分,所以是看不了生成后的 html 的,自然不可能基于这个 html 来做匹配或者解析。
然后,你截图里的图片 url 很多,这个截图只是一个很局部的内容,只是 json 数据众多字段里其中一个字段的数据而已。你用一些在线 json 解析器解析一下,看下整体的 json 的结构?绝大部分情况下,这个 json 数据的结构一定是固定的,不会少字段,所以不应该会没有回答 id 这个字段。如前面所说,请不要用正则来找内容,用 path 型的匹配方式或者直接代码逻辑解析数据吧
举个例子,返回值是这样的:
{"data": [
{"id": 123, "url": "http://zhihu.com/answer/123"},
{"id": 123, "url": "http://zhihu.com/answer/444"}
]}
你要打印这个 json 里的所有 url 数据,应该是把它转为 python 的 dictionary 类型数据,然后再按类似下面的方式解析:
for item in response_json["data"]:
print(item["url"])
这样才是按结构去解析数据。这种解析方法,只要结构不变,不管 url 变成什么值,你都一定能拿到,而且不会拿错。
懂了,看了一下 json 格式,正则匹配的出来的是回答里面引用的回答。还是得用 json 去匹配出来回答 ID,然后在通过 ID 去请求回答
获取到的回答跟前端界面上显示的回答有差异,查看了一下是因为有些回答被删除了,所以获取不到,到了删除回答的直接就跳出循环了。这样是正常的吗?
你的期望是跳过这些已删除的回答吗?还是什么?
如果是跳过,那现在程序的行为和你的期望不一致,属于不正常。那你改下代码,在采集逻辑里根据答案是否被删除状态,剔除掉删除状态的回答就好了。哪个字段代表删除,你需要自己找下、验证下。
另外,你的日志加一些描述信息吧,像截图里面那样的纯数字,完全看不懂对应意义,你就算用红框框住还是看不懂的,所以没法基于你这个信息给建议。
举个例子:
459 [xxx,xxx]
改为
回答抓取完毕,共计抓取到 459 个回答。对应id为:[xxx,xxx]
好的 谢谢。我的期望是获取到所有的答案,不需要跳过已删除的回答。现在的这个逻辑已经够使用了。疑惑是上面的代码逻辑是没有跳过已删除的回答的,但是获取到的回答是全部回答减去已删除的回答的
@ 陈恒捷 卧槽 时隔两年 在看到这个回答。最后一条回复已经忘记那个时候是咋解决的了。但是看代码 看到了那个 if 3 + offer > 467 branck 自己跳出循环了