大家好,我是司文,就职于国内某股份制商业银行,担任 “技术经理” 一职。拥有 16 年以上的软件测试、开发和项目管理经验。
在 TesterHome 大概潜水了 6 年,基本上不怎么发帖,经常看着各位大牛、专家发表文章,今天我也来发一篇「我对测试覆盖率的理解」,顺便给自己出版的新书《敏捷测试高效实践 测试架构师成长记》打打广告~!希望大家多多支持,感谢。
正文
在金庸的武侠小说中,提到了「中国的六大门派」,分别有:武当、华山、峨眉、少林、昆仑和崆峒派。
测试行业也是如此,山头众多,帮派林立。每个帮派都有一定数量的弟子,以便代代相传,连绵不绝。
在测试行业呆了这么久,一直有一个困扰我的问题:大家是怎么做测试覆盖率的呢?
大家都知道,测试覆盖率通常被用来衡量对某个系统测试的充分性和完整性。
经过我的多方打探,终于探知了测试行业中的六大测试覆盖率的门派,到底哪些才是名门正派?今天让我来一一向大家介绍。
01 捷径派
俗话说:山重水复疑无路,柳暗花明又一村。顾名思义,捷径派的宗旨就是「走捷径」。
在捷径派内,是如何计算测试覆盖率呢?方法是看:本次手工测试覆盖了多少测试用例。

分母是:所有测试用例。分子是:手工测试用例覆盖。
两者一除,得出的数字就是测试覆盖率。但是,手工测试如何标记用例的覆盖率呢?对,还是靠手工,也就是拍脑袋。
这 10 条用例我刚刚好像执行完了,好吧,那就是 100% 测试覆盖率啦。
如何定义「所有的测试用例」呢?捷径派的做法依然是「拍脑袋」,A 系统目前 3 个测试工程师参与了 4 个月,写了近 300 条测试用例,OK,那目前的 300 条就作为整个测试覆盖率的分母吧。
这倒是省事,千万别笑,还真有很多公司是这么做的。
02 数据派
数据派比较典型,很多传统软件公司都属于数据派。
这里简单说三种做法。
做法 1 接口覆盖率
这个系统有 10 个接口,对其中 8 个做了接口自动化测试(每个接口用一个自动化测试脚本来编写),那么覆盖率就是 80%。

分母是:接口总数。分子是:测试涉及的接口总数。
做法 2 自动化测试覆盖率
这个系统有 100 条测试用例,其中有 60 条用例已经被自动化脚本化了,执行完这些自动化测试脚本,那么覆盖率是 60%。

分母是:测试用例总数。分子是:自动化测试涉及的测试用例总数。
做法 3 测试用例覆盖率
这个系统有 100 条测试用例,400 个测试功能点(checkpoint),其中 200 个 Checkpoint 已经被自动化测试脚本测试,那么覆盖率是 50%。

分母是:测试功能点总数。分子是:自动化测试涉及的测试功能点。
这三种统计方法看起来很简单,实则应用特别广泛,很多公司都是按照这个套路统计的。
数据派的好处是数据相对严谨,以自动化测试脚本的形式来代替人工验证,用不同测试方法来代替「拍脑袋」式的。
03 专利派
这个流派特别传统和复古,让我们看看他们专栏说明:
本发明提供一种自动化测试覆盖率的计算方法及系统,方法包括如下步骤:获取原始测试需求;从原始测试需求中获取适合自动化测试的需求,设定为有效需求;将每个有效需求拆分成若干个自动化测试用例,设定每个有效需求的自动化测试用例为有效用例,获取有效用例的数目;根据实际可以覆盖的有效用例获取每个有效需求的覆盖用例数目;计算所有有效需求的有效用例的总数,计算所有有效需求的覆盖用例的总数;计算自动化测试有效覆盖率;系统包括原始测试需求获取模块,有效需求获取模块,有效需求自动化测试用例拆分模块,覆盖用例数目获取模块,有效用例总数及覆盖用例总数计算模块以及自动化测试有效覆盖率计算模块.
挺乱的,我来帮大家梳理一下:
需求 --> 自动化测试用例 --> 有效用例 --> 被覆盖用例 --> 算总数 --> 再算有效需求的有效用例总数......算了,我实在编不下去了。

图为业内某大神申请的「测试覆盖率计算的专利」
看来专利一派的水太深,内容晦涩难懂,并不适合大部分朋友。
04 需求派
测试用例通常是基于软件需求而不是软件实现所设计的。因此,度量这类测试完整性的手段一般是需求覆盖率,即测试所覆盖的需求数量与总需求数量的比值。
如果需求的力度比较粗,一般会将需求先转为「用户故事(Story)」,然后再拆分「任务(Task)」,根据这两层颗粒度去统计覆盖率。

分母是:所有用户故事或任务。分子是:已被测试的用户故事或已被测试的任务。
和捷径派一样,这里同样有个局限性,已被测试的数据还是得依赖「人工」去标记是否覆盖,最后算出覆盖率,笔者目前还未看到有工具代替人工的。
很多朋友在这里会有疑问,需求如何进行拆分?拆分到何种程度算作合适?颗粒度如何把握?
具体情况具体分析,每一家公司的业务都有其特殊性,重要的是把握好拆分需求的「道」。
给大家分享一则小故事:
在庄子的《南华经》中有一则寓言。说是有位叫丁的厨师,替梁惠王杀牛,其技法之娴熟,有行云流水一般的顺畅感。惠王就问他为什么有如此高超的技术。他回答说:“臣所喜好的是『道』,早就超越所谓的技术了。最初臣杀牛的时候,眼里看到的都是『完整的牛』;三年之后眼中就再看不到『完整的牛』。到了现在,臣以精神接触,而不用眼睛看牛,视觉感官停止了而精神在活动。按天然的道理,击入牛筋骨的缝隙,顺着筋骨的空洞进刀,依照它本来的构造,牛的筋骨接合的地方,臣都未以刀刃碰到过,而何况是大骨头呢!”

同样的道理。当我们在面对一头牛(复杂的业务需求时),如果不得其构造,不明其法,是不能够很好的拆解的。只有对需求深入了解,按照其本来的构造,在筋骨的缝隙处下刀,才能拆出不错的用户故事。
再通过拆分每一个用户故事,拆分成一个一个的任务(Task),每一条或多条用例对应覆盖一个任务(Task)。
需求派在进行覆盖率统计时,最终的目的也是为了「测试的行为覆盖了每一个需求,最终保障了产品质量」。
05 缺陷派
这一派用的人比较少,方法比较偏门。
我举个我见到过的例子,曾经有家大厂的团队是这么做的:
A 系统上线了,从接到需求到上线花了 3 个月时间,上线之后,该系统将持续进行一些小需求的改动。在这 3 个月内,测试团队共发现了 70 个缺陷,测试工程师使用自动化测试脚本,将这 70 个 “已经被修复” 的缺陷写成了自动化测试用例,每天回归执行自动化测试以防止程序员在「自己曾经摔倒的地方再次跌跟头」。
拿其中一个缺陷举例:
缺陷:A 页面有一个按钮 B 点击后应该出现一个弹窗,全屏分辨率。
期望:弹窗应全屏展示。
实际:弹窗并未全屏展示,而是以窗口形式展示。
这个缺陷已经被修复了,当然系统点击按钮 B 也有全屏弹窗,但是为了避免程序员再犯错误,我干脆把缺陷做成了自动化测试脚本,验证弹窗是不是全屏,如果是全屏就 Pass,不是全屏就 Fail。

分母是:已被发现并修复的缺陷。分子是:对缺陷进行自动化测试化的数量。
总之,缺陷派的做法就是反其道而行之,喜欢的朋友可以借鉴。
06 代码派
代码派终于登场了,目前,被业内广泛认可的还是以代码行、代码分支为主的测试覆盖率统计。
1 代码行覆盖率
代码行覆盖率是指:系统中被执行的代码行数与代码总行数之间的比值。

分母是:代码总行数。分子是:被执行过的代码行数。
2 代码分支覆盖率
代码分支覆盖率是指:系统中被执行的代码分支数与代码总分支数之间的比值。

分母是:代码总分支数。分子是:被执行过的代码分支数。
假如,一个 Java 应用有 10W 行代码,我执行了一次手工回归测试,同时也触发了自动化测试脚本,然后利用 Jacoco 组件查看看测试覆盖率,发现 10W 行代码中,有 3W 行代码已经被覆盖了,那么代码行覆盖率就是 30%。
同理,除了代码覆盖率,还有源文件覆盖率、类覆盖率、函数覆盖率、判定覆盖率、分支覆盖率等。它们形式各异,但本质是相同的,只是统计维度上的不同而已。
关于如何度量代码覆盖率?一般可以通过第三方工具完成。不同编程语言,有不同的工具。
例如,Java 语言有 Jacoco,Go 语言有 GoCov,Python 语言有 Coverage.py 等,如果你做的是 iOS 移动端的代码覆盖率测试,还有 gcov、llvm 等组件供你使用。
自动化测试覆盖率
笔者公司内所用到的自动化测试覆盖率,结合了代码派和数据派,使用了 Jacoco 组件进行了工具的封装,最终参考一个相对有价值的覆盖率数据。
何为「相对有价值」呢?我们认为应该剔除哪些「无意义的套路代码」,剩下的才是精华。
具体的做法我简单说 1 下:
01 搭建测试覆盖率环境
笔者以 Java 代码开发的系统为例,使用的是 Jacoco 组件,其他编程语言可以使用其他覆盖率统计组件。网上有相关教程,这里不细说了,感兴趣的小伙伴可以去搜索「Jacoco 测试覆盖率」关键字。
02 执行自动化测试脚本
统计覆盖率的环境搭建好之后,我们可以打开 Jacoco 的覆盖率报告界面查看 1 下,这时测试覆盖率值应该显示为 0%。
触发自动化测试脚本执行,等待执行完毕。
大家请看下图,我来进行说明。
绿色区域:代码行覆盖率充分,100% 覆盖了该代码。
黄色区域:代码行覆盖不充分。
红色区域:代码行未经过覆盖。
绿色钻石:代码分支覆盖率充分,100% 覆盖了该代码分支。
黄色钻石:代码分支覆盖率不充分。
红色钻石:代码分支未经过覆盖。
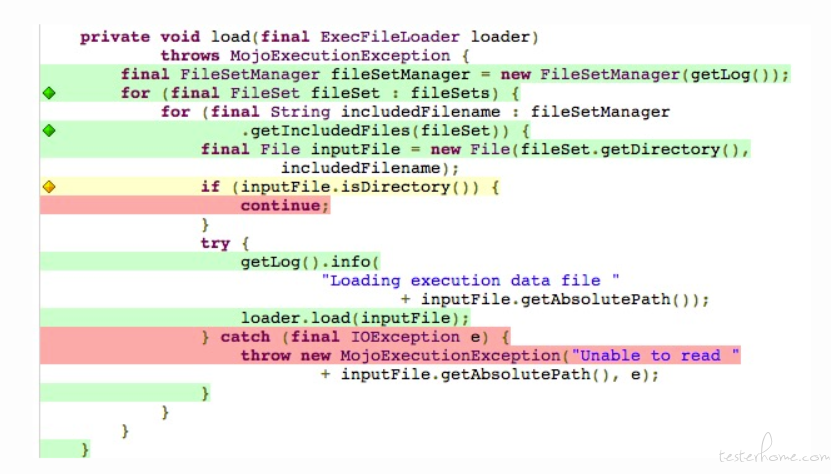
请注意,此时请勿打开测试环境的系统页面、接口调用等操作,保证数据的真实性。
03 筛选掉「无意义的套路代码」
以 SpringBoot 框架为例,框架工程目录已经帮程序员进行了分门别类,我们需要关注的是「有价值的代码」,剔除掉「套路代码」。
何为「套路代码」呢?如 bean、model、entity、util、mapper、dao、constant、config 等目录,大部分都是套路的代码统统过滤掉。
留下有业务意义的代码目录:controller、service、biz 目录和自己封装的业务函数类,服务端代码的业务逻辑运算、接口的代码逻辑都在这里,这才是代码的核心部分。
如果我们统计的覆盖率是「有价值」的,那么我们得到的数值才「有价值」。
最后,你的自动化脚本执行完成后,从 0% 变成了多少,那么我认为目前的自动化测试脚本覆盖率就是多少。
划重点
码覆盖率的局限性
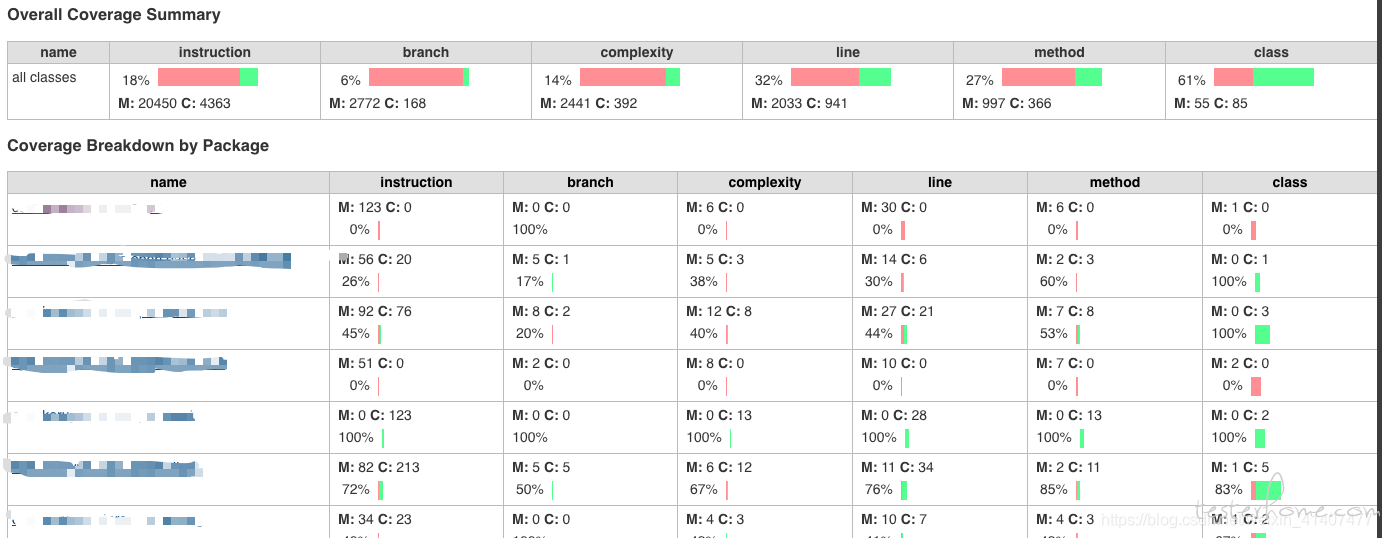
就代码覆盖率来说,最为大家诟病的一点就是:100% 的代码覆盖率并不能说明系统质量没有问题。
因为代码的执行顺序和函数的参数值,都可能是千变万化的。一种情况被覆盖到,不代表所有情况都会被覆盖到。
做过测试的同学都知道,我们所用到的等价类、边界值、因果图等方法,就是为了使用不同的测试数据来对某个功能点进行验证,这里说到的「已经被测试行为覆盖的代码」特指:至少被执行一次的测试行为,并不能展示出来那些「未考虑的异常数据」以及「未处理的异常情况」。
如果一个被测函数里面只有一行代码,只要这个函数被调用过了,那么衡量这一行代码质量的所有覆盖率指标都会是 100%,但是这个函数是否真正实现了应该需要实现的功能呢?答案肯定是否定的。
如下图所展示的代码,这是一个解析配置文件的方法,try-catch 前面的代码行都是「绿色」的(被测试覆盖的),我们能认为这一片绿色的代码质量是 100% 没问题吗?
当然不能!!!
因为,这也许是被执行了一次的测试行为,通俗点说,只能代表「测试曾经执行过这里」,并不能代表「完整的测试执行了这片代码」。
就好比,你曾经去过北京故宫,跟着旅游团旅游过一次。和你是北京故宫的审计检查员反复检查故宫每个园区的一草一木,完全是两个概念。

我的观点是,除了关注「已经被测试行为覆盖的代码」之外,还会观察「未被覆盖的代码」,这才是测试工程师需要关注的部分,关注「未被覆盖的代码」的意义在于:你还有很多测试用例是遗漏的,赶紧抓紧补全他们吧。
我认为这才是做自动化测试覆盖率真正「有价值」的地方,让测试工程师发现自己思维的不足、潜在遗漏的用例,最终补全自己的测试工作。

总结 测试覆盖率
笔者认为,关于测试覆盖率,最重要的一点应该是迈出第一步,即有意识地去收集这种数据。
没有覆盖率数据,测试工作会有点像在「黑灯瞎火」中走路。有了覆盖率数据,并持续监测,利用和改进这个数据,才能让我们的测试工作越做越好。
在这里隆重推荐一本作者出版的书籍,书中的其中一个章节详细介绍了客户端代码染色覆盖率工具从 0 到 1 的开发过程:
《敏捷测试高效实践 测试架构师成长记》


本书的特色是:介绍了三款测试创新工具平台的开发过程。从架构到技术细节,详细诠释说明了每个工具为什么开发、设计和开发过程、投产使用的优化。
01 代码染色覆盖率工具
市面上完整介绍「代码染色覆盖率工具」的技术书籍并不多,本书从为什么做这款工具、产品功能设计、技术选型、设计架构图、核心代码编写、经验总结等等,原原本本地还原了整个工具从 0 到 1 的过程。
目前,代码染色覆盖率工具已经在作者公司进行了投产使用,效果还不错,有学习诉求的朋友可以来看看,包括这款工具对测试技术的思考,应该能对你的工作有所帮助。
02 PostSuperman 自动化测试脚本一键生成工具
上文有介绍过,本书除了开源了 PostSuperman 这款工具,还把如何做 PostSuperman 工具的每个步骤都讲透了,整个工具开发的过程,都事无巨细的记录了下来。你可以下载后直接使用,也可以自己再加工开发改造,我们的目的帮大家把整个工具的技术设计、编程语言和功能细节都讲透、讲明白。
03 自动化测试平台
作者公司所使用的自动化测试平台,详细介绍了:
为什么做这个平台
这个平台能带来哪些价值,解决什么样的问题
怎样做架构设计的
用了什么编程语言、如何开发的
等等……
特色
觉得这本书的特色不足?还不够吗?再来重点介绍一项特色吧。
虽然本书是一本非常严肃的技术书籍,但是,处处却不乏创新。
全书有 22 副漫画贯穿全书,讲述了一位从校园毕业的「测试小工」如何逐渐成长为「测试架构师」的,这期间经历的磨难、焦虑和有趣的事,凭着主人公自身的付出和努力,终于成长为一名优秀的「测试架构师」。
整个过程是非常有意思的,与其说这是一本技术书,不如说是一本「测试工程师的凡人修仙传」,生动搞笑的叙述风格贯穿整本书,让你在努力学习技术的同时,劳逸结合。



购买链接(JD 和当当有折扣哦~)
