前言:
很多项目组也都有自己的检配表查方法,我也见过两个项目组的两种不同做法,但是我是不太认同的。我综合考虑出另外一种做法(个人觉得是不错的,而且目前实行起来深得我意),但是由于某些原因,我没有在原来项目中去推动我的想法实现。
这个想法两年前就有了,可惜一直没机会实践。2020 年 4 月的时候终于迎来一次机会,于是把想法付诸实际。如今回望,也是颇有感慨。写一写我怎么做的吧。
准备:
我需要去考虑的一些点:
- 配表改动可能会很频繁,包括但不限于增删表头、改数据格式等
- 配表可能会有多文件夹同名表格(SLG 多赛季,不同赛季会有 season1、season2 文件夹,而且 season 下也可能有同名表)
- 当配置表多、规则多的情况下,需不需要去考虑效率问题。小几分钟出检查结果,我可以接受,10 以上是不能接受的。
- 简单、方便快捷支持规则配置,规则增删
- 简单明了输出错误问题
- 要不要考虑平台化
- ......
尝试实现:
不知道咋想的,当时就有一个想法,通过规则表映射去检查配表(刚好满足很多我的需求)。具体做法是:
- 新建规则检查文件夹
- 将需要检查的表格复制过来,删除表格内容,在对应列配置规则
这个做法在落实之后也有一些小问题持续优化,这点后面说。先说下核心做法的实现:
main 函数
if __name__ == '__main__':
table = Table()
//这里用xlsx作为规则配置表,是因为后面优化有自动写入功能,相比xls,xlsx会更方便一些
excel = file.File.get_file_dir(config.RULE_DIR, file_type=".xlsx")
d_excel = file.File.get_file_dir(config.DOC_DIR, file_type=".xls")
dd_excel = [i+"x" for i in d_excel]
print("策划配置表有但是规则表没有的表格(注意补充):", list(set(dd_excel).difference(set(excel))))
print("规则表有但是策划配置表没有的表格(可以删除):", list(set(excel).difference(set(dd_excel))))
for every_excel in excel:
# if every_excel != "\冬天的秘密表.xlsx":
# continue
check_excel(every_excel)
check_excel 方法核心代码
for head_name in head_list:
if head_name == '':
continue
if head_name not in d_head_list:
print(head_name, excel_name, "规则表的表头不存在配置表的表头")
continue
d_col = d_head_list.index(head_name)
col = head_list.index(head_name)
for i in range(config.ROW_START, sheet.nrows):
if sheet.cell_value(i, col) is "":
continue
cell = str(sheet.cell_value(i, col)).replace('\r', '').replace('\n', '').replace('\\', '\\\\')
try:
# value_dict = json.loads(cell)
value_dict = json.loads(cell, strict=False)
except ValueError:
print("@@@@@@@@@@@@@@@@@@@规则配置错误{}".format(cell), excel_name)
(key, value), = value_dict.items()
# 传参:所检查的表的相关信息
getattr(rule, config.switch[key])(value, excel_name=excel_name[:-1], sheet_name=sheet_name, col_index=d_col)
Rule 规则定义与代码实现
我希望把 rule 分别归类,这样会非常容易去找到我对应的规则。我在 config 中会配置有多少类规则,比如 In 类规则,泛指 A 列存在 B 列、当 A=X,B 列存在 C 列...此类规则;Match 规则,包含 A 列满足正则表达、当 A 列=X,B 列满足正则表达这两种规则。
switch = {
"_Only": "Only",
"_In": "Ainb",
"_Equal": "Equal",
"_Match": "Match",
"_Dict": "Dictionary",
"_Condition": "Condition",
"_Increasing": "Increasing",
}
接下来我以 In 类为例,说下我的做法。
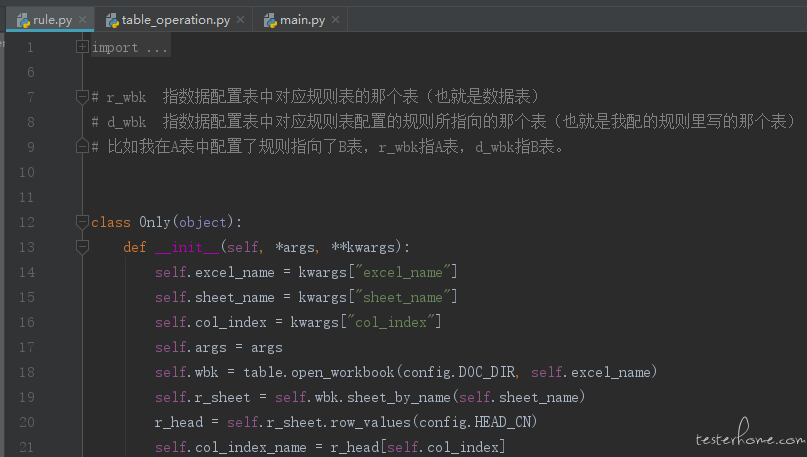
class Ainb(object):
def __init__(self, *args, **kwargs):
# **kwargs 记录正在检查的表格的相关信息
# r_wbk 指数据配置表中对应规则表的那个表(也就是数据表)
# d_wbk 指数据配置表中对应规则表配置的规则所指向的那个表(也就是我配的规则里指向的那个表)
self.excel_name = kwargs["excel_name"]
self.sheet_name = kwargs["sheet_name"]
self.col_index = kwargs["col_index"]
self.args = args
self.r_wbk = table.open_workbook(config.DOC_DIR, self.excel_name)
self.r_sheet = self.r_wbk.sheet_by_name(self.sheet_name)
r_head = self.r_sheet.row_values(config.HEAD_CN)
self.col_index_name = r_head[self.col_index]
temp = {"All": "all_in",
"Assign": "assign_in",
"Part": "part_in",
"Sequence": "sequence",
"Whenassign": "whenassign",
"Whenpoint": "whenpoint",
"Every": "every_in",
"Neighbor": "neighbor",
"Allpoint": "allpoint"}
if isinstance(self.args[0], dict):
(key, value), = self.args[0].items()
self.__getattribute__(temp[key])(value)
# 每个单元格都in指定的表格指定列的合集
# {"_In":{"All":["/冬天的秘密.xls","冬天的秘密--sheet","冬天的秘密--colname"]}}
def all_in(self, _value):
d_wbk = table.open_workbook(config.DOC_DIR, _value[0])
d_sheet = d_wbk.sheet_by_name(_value[1])
d_head = d_sheet.row_values(config.HEAD)
d_index = d_head.index(_value[2])
d_col_list = table.get_content_by_col(
config.DOC_DIR, _value[0], _value[1], d_index)
d_col_list1 = [str(j) for j in d_col_list]
for i in range(config.ROW_START, self.r_sheet.nrows):
if not agent.pass_empty(i, self.r_sheet, self.col_index):
continue
temp = Common.change_format(
self.r_sheet.cell_value(
i, self.col_index))
if str(temp) not in d_col_list1:
agent.pri_excel(
self.excel_name,
self.sheet_name,
i,
self.col_index_name)
print("规则:每个单元格都in指定的表格指定列的合集。数据:::{}--{}". format(
str(self.r_sheet.cell_value(i, self.col_index)), _value))
如上代码,In 为大类,大类包含小类。In 类型规则,包含 All 类规则(每个单元格都 in 指定的表格指定列的合集)、Assign 类规则(每个单元格都存在于由你设定的合集)等等(其他规则就不详细说了)。self.__getattribute__(temp[key])(value)会根据映射关系去执行对应方法来做检查。all_in方法会打印错误的规则以及错误数据;pri_excel方法负责通用打印,主要打印错误位置。下面给出打印结果示例。
@staticmethod
def pri_excel(name, sheet, row='', col=''):
if row == '' and col == '':
print(
"表格位置----------------------------------{}-------------------------{}".format(name, sheet,))
else:
print(
"表格位置----------------------------------{}--------------------------{}--行{}--列{}".format(
name,
sheet,
row,
col))
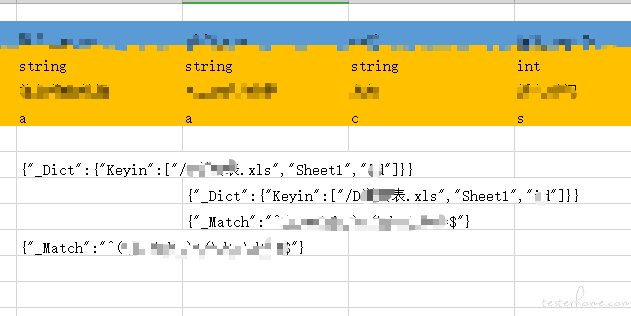
//规则:每个单元格都in指定的表格指定列的合集。数据:::208--['/冬天的秘密--表.xls', '冬天的秘密--Sheet1', '冬天的秘密--列']
//表格位置----------------------------------\XXX表.xls--------------------------Sheet1--行712--列XXX(冬天的秘密--列名,注意不是列的index哦,列名,直接让你快速找到位置)
//根据上面输出立刻可以得知,712行,列名为冬天的秘密,数据内容为208,本来应该存在与冬天的秘密表,冬天的秘密sheet,冬天的秘密列该列中,但是没有存在,所以需要检查208这个数据。
整体思路:
- 遍历规则表
- 根据配置在规则表对应列下的规则,找到对应需要检查的配置表,以及规则中指向需要配合检查的另一个配置表(如果有的话)
- 按照规则执行检查,打印错误输出
实际应用与优化:
好的方面:
- 目前我有的规则类,在上文中的
switch可以看出来,有 7 大类,每个类下可能有不定数量的规则,总体来说 99% 满足了我的日常需要了。 - 代码结构支持随时自定义规则,你想增加删除规则,也是分分钟的事。你的想法有多优秀,规则就可以有多优秀。
- 配规则很简单。有多简单?找到对应规则表位置,打开,写入规则,完事了。规则很复杂吗?看你自己定义了。我日常做法:复制规则,改规则中的 excel name,sheet name,col name 三个参数,完事。
- 输出结果一目了然。错在哪,哪一行,列名是什么,因为什么规则错了,统统都有,会有人看不明白?看不明白的话,那我是真的佛了。
优化:
问题一:表头经常改动,列名也经常变化,规则表的表头就得手动更改保证和配置表一样(我强迫症,我就想一样,这样子很容易找位置)。比如原来配置表 ABCD 列,规则表也是 ABCD 列,后来迭代多次表变成了 ABCFG 列,我就又要手动删除 D,又要手动补充 FG。麻烦。于是自动同步表头配置脚本,又应运而生了。
这个脚本主要做什么事?帮我把 D 删除,帮我新建 FG,如果 AB 之间多了个小三,那么也会自动把 B 列(以及 B 列下的所有规则)往后挪,小三则按照顺序放在 A 之后。总之,就是同步表头,同时把对应表头下的规则跟着表头一起挪动。
# 只支持xlsx
def write_excel(excel, df):
# 先清除格式,再写入,才能成功
pd.io.formats.excel.header_style = None
with pd.ExcelWriter(excel) as writer:
df.to_excel(writer, sheet_name='Sheet1', startrow=0, index=False, header=False)
workbook = writer.book
worksheets = writer.sheets
worksheet = worksheets['Sheet1']
worksheet.set_column('A:AD', 20)
format1 = workbook.add_format({
# 'bold': True, # 字体加粗
# 'border': 20, # 单元格边框宽度
# 'align': 'left', # 水平对齐方式
# 'valign': 'vcenter', # 垂直对齐方式
'fg_color': '#FFC000', # 单元格背景颜色
# 'text_wrap': True, # 是否自动换行
})
for k in range(2, 5):
worksheet.set_row(k, 20, format1)
format2 = workbook.add_format({'fg_color': '#5B9BD5'})
worksheet.set_row(1, 20, format2)
for j in range(5, 15):
worksheet.set_row(j, 20)
弄完之后,所有表长得一模一样,还有背景颜色,一家人就要整整齐齐,真开心。
问题二:平台化?
不打算,不建议搞,于是我砍掉了这个优化。我出于以下考虑:
游戏行业人员会更喜欢和 excel 打交道
表头过多,web 很难操作,样式也没 excel 好看。excel 和策划配置表长的一样,容易形成习惯,有助于规则配置。
平台化的话,需要数据库。那就又要重新优化问题一了(又要写自动同步数据库表头的脚本)
我懒,不想搞平台,也不会搞前端。就是懒,咋的啦。
问题三:工具运行中,某些规则兼容性不好,报错,就阻断了后面的检查。
举个例子,你配置一个Dict类规则,默认这个表格内容是可以转换为json或者python dict去做检查,但是配表数据出现了问题,导致报错,阻断后面流程(然后有人就会来找我说报错啦)。我目前的做法是,持续优化规则代码,增加兼容性,提前检查必要的数据格式,或者对易报错代码使用try。现在持续优化后,已经很少出现报错阻断了。一个字,美滋滋(三个字)。
问题四:效率问题?
目前 100+ 表格,各种规则配置起来也蛮多的,但是运行时间不需要超过 1 分钟。所以暂时不用管了。
其实我也蛮期待,在更多表格数据、规则数据的情况下,工具的运行效率。我也提前预想过一些优化方案来提高效率。
问题五:规则维护问题 ---- 会不会出现同个规则存在很多表,然后你需要一个一个去更改这些规则的写法?
我认为是不会出现的。在定义规则之前,就已经考虑通用性了,后续基本不会变动原有规则的写法,最多只会新增新的规则写法。所以旧的规则写法永远不需要去改动,也不建议去改动。如果实在要改动,建议改动代码去兼容原有规则写法。反正至今我都没改动过。
其他: 有点想把取出来的规则归类整理,再getattr一个类,跑完一个类的检查,再做下一个类,而不是现在混着检查(简单说就是检查顺序跟着大类走)。不过检查顺序又想着跟着表走也好,输出结果也能按照表顺序,也蛮好的。也有点想加入协程,但是涉及open同个表的问题,需要上锁,麻烦,算了,先这样,反正几十秒出结果了,效率能接受。
附言:
仁者见仁智者见智,希望这个工具,成为比较好的配置表检查方案,也期待有人告诉我更好的方案。