之前采用 Pytest 做了一个配置表检查工具,最近看了一些 “数据驱动” 和 “关键字驱动” 的相关文章,有了一些新的思路,并用这种思想重新做了一个配置表检查工具,只需要 3 个 py 文件 + 一张 xlsx 表格就可以实现,比用 pytest 来实现更简单更高效。并且不了解代码的人也可以写用例,只需要懂一点正则表达式即可。
效果展现:
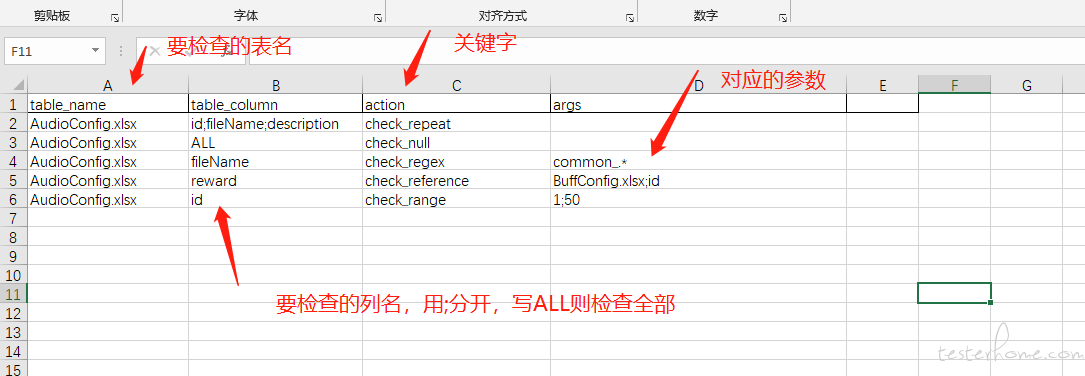
关键字:
check_null 为空检查
check_repeat 重复检查
check_regex 格式检查,后面的参数配对应的正则表达式
check_reference 索引检查,后面的参数配对应的表格和列名
check_range 值域检查,后面的参数配值域
运行脚本直接把结果写入另外一张表格中,如图

代码只有 3 个 py 文件
XlsxReader.py 用于读表格
ConfigCheckerXlsx.py 用来写检查逻辑
ConfigCheckDriver.py 用来执行检查
XlsxReader.py
#coding=utf-8
import xlrd
xlsx_path = r"E:\Common\Config"
class XlsxReader:
def __init__(self,xlsx_name):
self.path = xlsx_path
self.xlsx_name= xlsx_name
self.ignore_lines = 3;#忽略的行数,一般配置表前3行有特殊作用不做配置,所以读取数据时忽略这3行
self.xl = xlrd.open_workbook(self.path+"\\"+self.xlsx_name)
#self.xl = xlrd.open_workbook(self.xlsx_name)
self.sheet = self.xl.sheet_by_index(0)
self.column_name_list = self.get_head_list() #得到表的列名(表头)
self.num_rows = self.sheet.nrows # 获取总行数
#得到列名也就是第一行(表头)
def get_head_list(self):
return self.sheet.row_values(0)
#通过列名得到某一列的数据
def get_column_list_by_name(self,name):
#把名字转换成index再通过self.sheet.col_values(index)得到整列数据
head_list = self.get_head_list()
if name in head_list:
index = head_list.index(name)
return self.sheet.col_values(index,self.ignore_lines)
else:
print("该配置表没有%s列"%name )
#得到一行的数据
def get_row_list_by_index(self,index):
return self.sheet.row_values(index)
if __name__ == '__main__':
xlrd = XlsxReader("ChapterConfig.xlsx")
res = xlrd.get_column_list_by_name("id")
print(res)
ConfigCheckerXlsx.py
import pytest
import re
from collections import Counter
from xlutils.copy import copy
import xlrd
import xlwt
import time
class ConfigCheckerXlsx:
def __init__(self,check_table):
#一般配置表前3行是表头,不参与检查
self.ignore_row = 3
self.check_table = check_table
self.oldwb = xlrd.open_workbook(check_table)
self.newWb = copy(self.oldwb)
self.newWbs = self.newWb.get_sheet(0)
# 索引检查
def check_reference(self, list_checK,column_name, com_table_name,com_column_name,com_column_list,row,column):
# list_check 被检查的列
# com_talbe_name 需要索引到的表名
# com_column_name 需要索引到的列名
print("check reference")
res_list= list()
for index, sub in enumerate(list_checK):
if sub not in com_column_list:
res_list.append(index+self.ignore_row+1)
if(len(res_list)==0):
self.newWbs.write(row, column, "pass")
else:
self.newWbs.write(row,column,'{0}列 第{1}行 无法索引到 {2}表的{3}列'.format(column_name,res_list,com_table_name,com_column_name))
# 为空检查
def check_null(self, list_check,column_name,row,column):
print("check null")
res_list= list()
self.newWbs.write(row, column,"pass")
for index, sub in enumerate(list_check):
if(len(str(sub).strip()) == 0):
res_list.append(index+self.ignore_row+1)
if (len(res_list) == 0):
self.newWbs.write(row, column, "pass")
else:
self.newWbs.write(row,column,' {0}列 第{1}行 为空 '.format(column_name,res_list))
# 重复检查
def check_repeat(self, list_check,column_name,row,column):
print("check repeat")
if(list_check==None):
self.newWbs.write(row,column, "{0}为空".format(list_check))
else:
if (len(set(list_check)) == len(list_check)):#set() 的长度和原来的相等说明没有重复项
self.newWbs.write(row,column, "pass")
return
counter_list_check = Counter(list_check)
repeat_item = [key for key,value in counter_list_check.items() if value>1] #得到重复元素的列表
res_str= str()
for item in repeat_item:
item_repeat_row = [i+self.ignore_row+1 for i,sub in enumerate(list_check) if sub == item]
res_str+=' {0}列 {1} 在{2}行重复\n '.format(column_name,item,item_repeat_row)
self.newWbs.write(row,column ,res_str)
# 格式检查
# 检查指定列是否符合给定的正则表达式
def check_regex(self,list_check,regex ,column_name,row,column):
print("check regex")
self.newWbs.write(row, column, 'pass')
res_list= list()
for index, sub in enumerate(list_check):
#sub= str(sub)
pattern = re.compile(regex)
if pattern.fullmatch(sub)==None:
res_list.append(index+self.ignore_row+1)
if (len(res_list) == 0):
self.newWbs.write(row, column, "pass")
else:
self.newWbs.write(row, column, ' {0}列 第{1}行 格式有误'.format(column_name, res_list))
# 值域检查
def check_range(self,list_check,min,max,column_name,row,column):
#被检查的内容必须是数值
#todo 考虑字符也可以装换成数字
res_list = list()
for index,sub in enumerate(list_check):
if len(str(sub).strip()) != 0:
num = float(sub)
if(num<min or num>max or len(str(sub).strip()) == 0):
res_list.append(index+self.ignore_row+1)
if(len(res_list)==0):
self.newWbs.write(row,column,'pass')
else:
self.newWbs.write(row,column,' {0}列 第{1}行 超出预期范围[{2} ,{3}]'.format(column_name,res_list,min,max))
def save_xls(self):
time_str= time.time()
now = time.strftime("%Y%m%d_%H%M%S", time.localtime(time.time()))
self.newWb.save("result/result"+now+".xls")
ConfigCheckDriver.py
from Tools.XlsxReader import XlsxReader
from Tools.ConfigBase import ConfigBase
from Tools.ConfigCheckerXlsx import ConfigCheckerXlsx
import pytest
config_path= "E:\Common\Config\\"
configChecker =ConfigCheckerXlsx("E:\Common\Config\checklist.xlsx")
xlsxReader_checklist = XlsxReader("checklist.xlsx")
for index in range(1,xlsxReader_checklist.num_rows):
check_row = xlsxReader_checklist.get_row_list_by_index(index)
table_name =check_row[0]
xlsxReader_table = XlsxReader(table_name)
column_name_list =list()
if check_row[1] == "ALL":
column_name_list = xlsxReader_table.get_head_list()
else:
column_name_list =check_row[1].split(";")
# action 关键字驱动
action = check_row[2]
for index_column_name_list,column_name in enumerate(column_name_list):
list_check = xlsxReader_table.get_column_list_by_name(column_name)
if action == "check_repeat":
configChecker.check_repeat(list_check, column_name, index, 4+index_column_name_list)
elif action == "check_null":
configChecker.check_null(list_check,column_name,index,4+index_column_name_list)
elif action == "check_range":
range_list = check_row[3].split(";")
configChecker.check_range(list_check,float(range_list[0]),float(range_list[1]),column_name,index,4+index_column_name_list)
elif action == "check_regex":
regex = check_row[3]
configChecker.check_regex(list_check,regex,column_name,index,4+index_column_name_list)
elif action == "check_reference":
com_table_info = check_row[3].split(";")
com_table_name = com_table_info[0]
com_column_name = com_table_info[1]
com_column_list =XlsxReader(com_table_name).get_column_list_by_name(com_column_name)
configChecker.check_reference(list_check,column_name,com_table_name,com_column_name,com_column_list,index,4+index_column_name_list)
configChecker.save_xls()
「原创声明:保留所有权利,禁止转载」
