前言
话接上篇https://testerhome.com/articles/27202。 之前主要讨论的是数据一致性的测试场景。 这次我们讲讲跟功能测试有关系的。
场景回顾
让我们先回顾一下流计算的一个典型场景
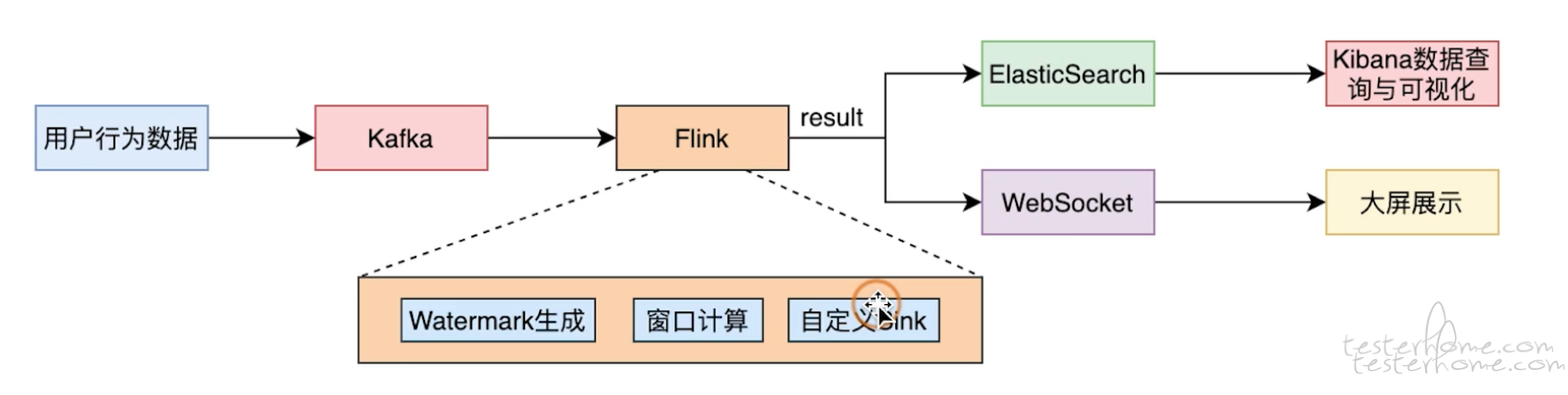
可以看到在这样一个场景中, 数据流的入口是将数据推送到 kafka, 而出口则是另外一个存储介质或者是一个用来做数据可视化的大屏。 要测试这样的场景与我们平时还是不一样的, 让我们跟随下面的思路去思考。
- 我们在刚看到这个系统的时候潜意识的会希望使用跟其他场景下一样的黑盒测试方式来进行测试。 但我们发现整个系统中并没有一个可供调用的接口来验证相应的数据处理算子。
- 当没有接口调用的时候我们理所当然想到的是自己编写造数工具向数据流的源头也就是 kafka 中灌入测试数据,然后在数据的出口也就是大屏上查看数据计算的结果来完成测试。比如还是计算 PV 的场景, 那我们就会根据产品要求的数据格式将 10 条数据推送到 kafka 中,然后观察大屏中显示 pv 的值是否也是 10.
- 使用上面说的方式测试的时候并没有想的那么简单, 我们需要注意流计算中的一些特殊的地方,比如 Flink 中关于窗口的定义, 窗口是流计算中一个比较特殊的逻辑。 比如还是 PV 这个场景,为了提升性能我不希望每次来一条数据就计算一次然后产出到大屏中, 而是定义一个 time window 或 count window。比如我希望每来 100 个数据的时候才触发一次窗口计算,一起计算这 100 个数据。 也就是说即便你向 kafka 里 push 了 99 个数据, 实际上你在大屏上也是什么都看不到的, 因为没有满足 100 个数据的窗口触发条件,所以他是不会进行计算的。 这种窗口逻辑层出不穷,在 Flink 中有不定长的 session window,有基于时间的滚动窗口和滑动窗口,也有基于数量的 count window, 也有可以持续更新的 continues 系列的窗口。 如果不去了解具体的窗口逻辑,那么在测试的过程中是没办法造出合适的数据的。 也就是说你还是不能把整个系统当成一个黑盒子进行测试。
- 通过上面说的方式测试在理论上是没问题的,只要能够完全摸清产品的数据处理逻辑那么就可以完成这种全链路的测试场景。 但在实际的业务场景中我们可能会遇到非常复杂的数据处理流程,一个数据流可能会经过十数个甚至数十个算子的处理, 而这些算子处理过程很可能是没有文档的, 因为在很多公司流计算场景是没有产品经理来跟进的,即便有产品经理,可能他的 PRD 里写的也只是说我想在大屏中实时的看到 PV 数据, 至于里面是怎么计算的他是不管的,就比如说上面的窗口设计。所以需要花费大量的经理梳理数据处理逻辑和对应的业务逻辑。
根据上面我们一步一步思考的结果来看,端到端的测试方法可行但是付出的成本会很高,没有一个循序渐进的过程,属于必须一步做到位 -- 在 QA 彻底摸清数据处理逻辑前几乎是无法产出测试用例的,而为了摸清这个逻辑可能会比较长的时间 (虽然比较高,但是如果是 TO B 类型或者支付类业务,对数据准确性要求很高的场景,还是需要去做的。)
PS: 如果数据处理业务并不复杂,那其实这种测试方式是最好的。
单算子测试
根据刚才讨论的,如果遇到数据处理逻辑很复杂的场景, 我们可能面对的是数十个算子的流式计算,每个算子都会对数据进行加工, 想要在这种情况下造出高质量的测试数据确实是比较困难的,而且测试出 bug 以后想要分析出究竟是哪一个算子导致的数据错误也是很复杂的。 这个的问题困扰了我们很久, 于是后面我们按照以前的分层测试的思路去找方法, 我们意识到如果可以把一个大的数据流拆封若干的比较小的流, 比较小的流又可以拆开成为一个一个的算子, 我们针对单算子进行测试, 那么这种测试方式的成本就会很低。 那么基于这个思路我们来看我写的一个 demo 吧。
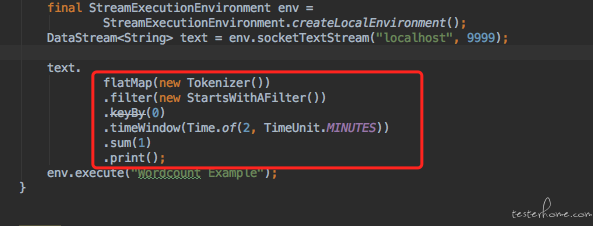
这是我模拟的一个 world count 场景,它从本地端口 9999 上读取数据流,分别经过 flatmap 算子来加工数据, filter 算子过滤数据,keyBy 算子按 world 进行分组,再经过一个 2 分钟宽度的滚动窗口来聚合数据, 最后 sum 算子计算词频并通过 print 算子打印出来。 从代码结构上来看,Flink 的 API 设计的也很流式, 我们编写的代码就有如 pipeline 一样一层一层往下传递。 所以按照刚才说的思路, 是否可以先去测试这每一个算子的正确性呢? 答案是肯定的, 我们完全可以把这个数据流拆成一个一个的算子进行单独的测试。 当然 Flink 内置的算子我们肯定是不测的,我们必须默认 flink 是没有 bug 的, 否则这活就没法干了, 所以 Flink 内置算子我们不测,我们要测试的是研发自定义的算子,比如在我们这个 demo 中:
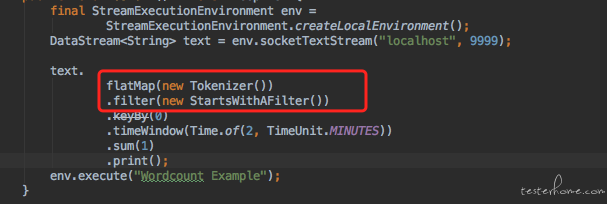
在 flink 中 flatmap 和 filter 是需要传递一个算子对象,这个算子对象就是需要研发自己来编写的, 它的定义如下:
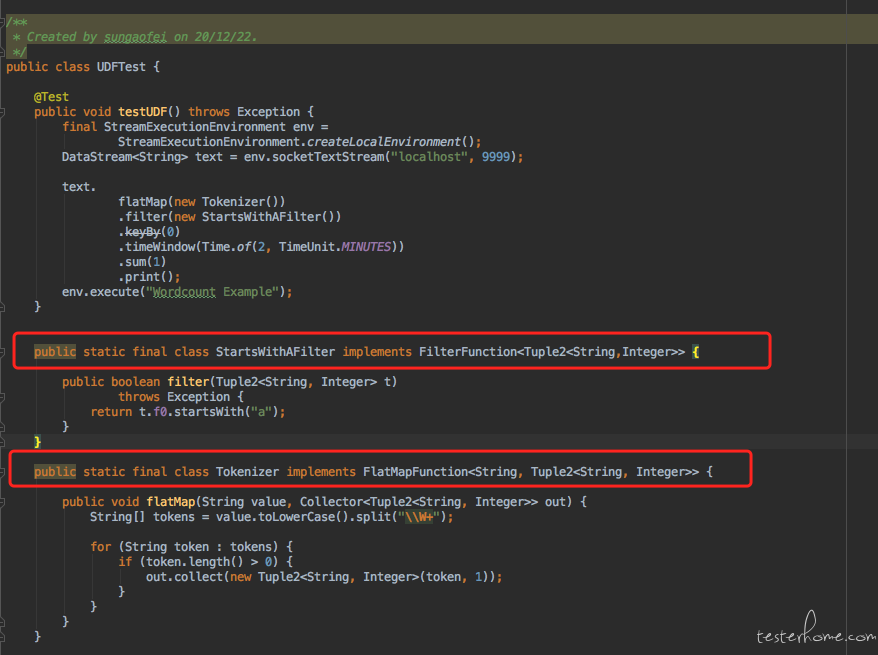
而针对其中一个方法的测试用例如下:
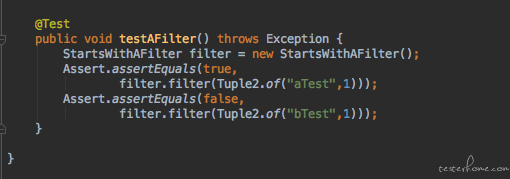
demo 中自定义的 filter 算子的逻辑很简单, 它只会收集数据中首字母为 a 的字符串, 其他数据均会被过滤掉,方法的返回值是一个 Boolean 类型。 所以我们的测试用例其实很简单,直接在 junit 或者 testng 中直接对其功能进行测试,分别判断返回值即可。 也就是说我们这一次把算子作为黑盒,我们不管算子有多复杂的逻辑, 调用了其他多少个函数处理, 我们针对该算子的输入和输出进行测试。 至于算子内部更细粒度的方法的单元测试则交给研发来做。 而实际上这是我们特征引擎团队最主要的测试方式, 在实际的产品研发会比较少使用到内置算子的,大量的复杂逻辑都必须由研发同学来通过编写自定义算子的方式进行处理。在 Flink 中 sql 有自定义算子, stream api 中有 process function, 也有 demo 中要传递给 flatmap 或者 filter 的算子, 这种函数我们习惯统称为 UDF(User Define Function)。 在我们的特征引擎团队中,研发同学开发了百余个 UDF 以应对不同的特征处理的需求。每个 UDF 可能需要产出几十甚至上百的自动化测试用例, 加起来就是数以千计的 case。 这里要介绍一下第四范式质量部对测试开发岗位的定位, 我们不仅仅要在业务层面进行黑盒的测试, 我们更鼓励的是测试开发同学深入研发架构中,与研发共同建设质量保证体系, 所以玩 API 和 UI 自动化测试并不是我们全部的工作。 我们同样有非常底层的自动化测试手段。 在时序数据库,特征引擎以及算法团队中, 均有测试人员跟进, 这些产品很多是没有 UI 也没有 API 的纯技术性的产品,在架构中属于中间件层或存储层。 我们的测试人员都是在产品的代码仓库中编写代码进行测试的。
所以在这个背景下我们就有了接下来的合作方式, 算子研发的同学要忙于开发工作没有精力去构建数以千计的 UDF 的自动化测试, 于是我们以 UDF 为边界, 研发负责编写 UDF 中调用的更细粒度的函数的单元测试, 而测试人员编写 UDF 和 UDF 之上的集成测试用例。 当然如果研发有余力也会加入到 UDF 的测试用例的编写工作中。
这种测试方式的优点:
- 单算子测试不必真正的提交大数据任务,测试人员可不用懂 spark/flink,因为 UDF 的编写其实就是一个很简单的方法,运行这个方法不需要构建什么依赖环境也不用调用 spark/flink 的 API
- 把数据流拆成单算子,数据处理的流程就变简单了, 不必构建那么复杂的数据进行验证。 所以这个复杂度就降低下来了。
- 不必真的提交大数据任务,运行速度是很快的, 稳定性也很高。
我们评估这是性价比最高的测试方法, 测试人员可以完全不用懂 spark/flink 的知识。 只需要懂得编写基本的 java 代码即可。
PS: 使用这种测试方式需要研发配合,不要在 flatmap 和 filter 这种算子里用什么鬼 lamda 表达式来搞匿名函数,而是直接单拎一个类正经八本的实现他
把数据流拆开
我们已经可以做到单算子的测试, 但是根据以前的测试经验,我们希望进行更进一步的集成测试, 我们想要测试一下多个算子集成一个流的时候,它是不是还能正常的工作。 但是如果我们是面对最终的那个好几十个算子组合成的庞大无比的流的话, 我们就会遇到跟端到端的测试一样的窘境 ---- 太复杂了。 所以我们要做的是将这个大的流按照业务属性拆分成一股一股小的流。 每个小的流可以汇集成一个大的流提供给最终用户, 也可以单独的提供给测试人员做算子的集成测试。 比如在这种模式下研发的流的调用方式就变成了这样:
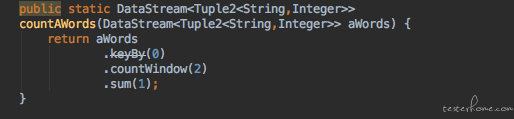
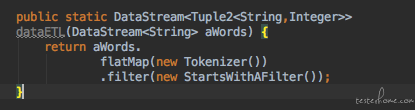
可以看到,研发会把流中算子按一定规则分组, 在我们的 demo 中,我们把流拆分成 2 个, 一个做计算词频, 一个做数据的预处理。 提供给用户的时候它的 API 就变成了下面的样子:
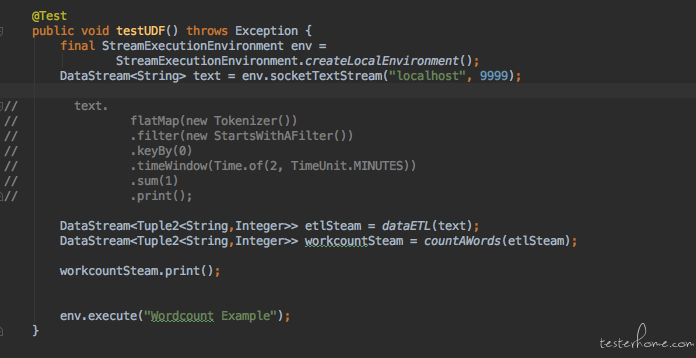
可以看到功能是跟以前一样的没有变化,只是组成 stream 的逻辑分开封装了而已。 要求研发这样设计单纯的就是为了可测试性。 因为一旦他们这样编写代码后,我们就可以根据拆分出来的小的 stream 进行测试了 。 如下:
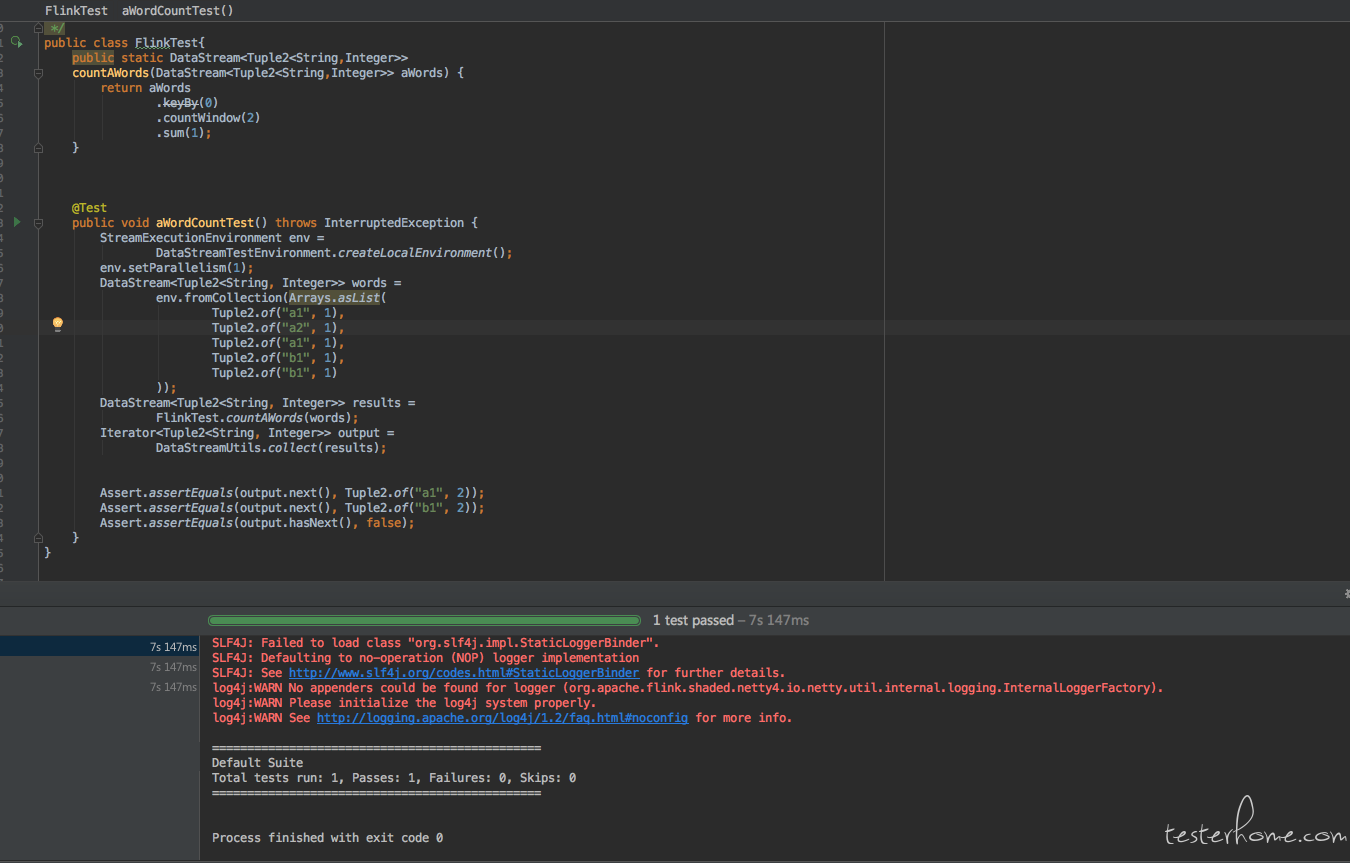
- DataStreamTestEnvironment.createLocalEnvironment(); 是 flink 提供的测试框架的自带功能, 它会在本地起一个虚拟的 flink cluster,完全是在内存中的,可以不必担心会有很大的开销以及事后的清理问题。 因为我们现在要对流进行测试了, 不模拟一个 flink 集群的话任务提交不上去。
- env.fromCollection 方法可以从集合中创建一个 data stream,然后我们使用 countAWords 来进行流的拼接,这相当于把数据传递给被测的流。
- DataStreamUtils.collect(results); 方法是在流针对数据计算完成后,把数据提取出来的方法, 也是 flink 内置的函数。
- 最后我们使用 Assert 方法针对数据处理的结果进行断言
PS:解释一下为什么最后断言的结果是 a1 和 b1 的值是 2, 而 a2 不见了, 是因为我们的流里使用了.countWindow(2) 这个窗口, 只有数据累计到 2 个的时候才会触发计算, 所以 a2 只有一个数据灌进去,窗口还没有触发计算。
通过这种方式我们就拥有了比单算子测试更上层的集成测试,这种方式也被证明是十分有效的, 相当于我们大一个庞大无比的流按功能拆分成了互相独立的小的流, 针对每个小的流我们可以进行独立的测试。 就比如我们这个 worldcount 的 demo 来说, 完整的流是要先有个 ETL 的过程去过滤和加工数据,然后才会去计算 world count。 而我们就把这个大场景拆分成了 ETL 和 worldcount 两个小的流分别进行测试。 上面的测试代码就是我们绕过 ETL 的过程直接测试 worldcount 这条包含着 3 个算子的小的流。 这是一种层层集成测试的思路: UT --> 单算子测试 --> 拆分流测试 --> 完整的流的测试。 实际上当你集成到最后就是针对完全的流进行测试了, 这就跟端到端的测试已经很接近了。
这种测试方法的特点:
- 在本地启动虚拟的 cluster,并不提交真的数据到集群上,运行速度快并且稳定
- 在单算子的测试下,增加了多算子合并成流的测试, 更贴近用户场景。
- 层层集成, 并且由于不是对完整的流进行测试,复杂度被层层拆解。
- 需要懂一些 spak/flink 的 api 但是很有限, 毕竟不必启动集群, 只针对结果测试的话不必学习 flink/spark
- 需要研发在编写代码的时候对流进行拆分,提高可测试性
再谈谈端到端测试
我们回过头来再聊聊端到端测试吧, 我们在开始的时候就聊到在复杂的场景下执行端到端的测试是多么的困难。 但当你一定要测试端到端场景的时候, 我还是给你一些建议。
只测试最主要的数据规则
如果数据处理的逻辑实在是难以梳理清楚, 那么可以梳理一个大概的逻辑, 最后检查数据的时候只针对性的检查重要的点。 比如说你知道数据处理的逻辑里要对数据进行过滤, 所以就验证是否有没有过滤干净的数据。 这种重要的逻辑能梳理出来几个就几个然后进行测试, 有时候甚至最后数据的行数都是一个很重要的测试点。 这个测试思路是一种折中的办法,如果有 1000 条数据处理的逻辑需要验证, 但你只能梳理出重要的 10 条来, 那就只针对这 10 条规则进行测试吧, 剩下的就相信底层的测试用例。比如我们在测试某些流的时候如果逻辑太复杂,灌入的数据太多, 那么其实在代码层进行测试的时候, 我们也不会精准的一条数据一条数据进行测试, 而是测试主要规则,比如:
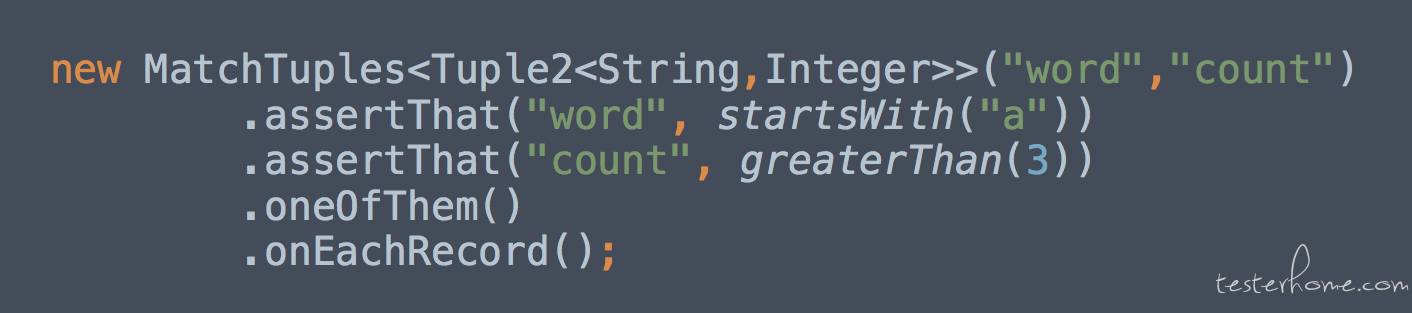
上面的断言出自 flink 的测试框架, 它只会断言数据中每一行中 world 是否是以 a 开头的以及最后的值是否都是大于 3 的, 至于它具体的值是什么我们并不关心。 复杂条件下不去一条一条数据进行测试已经是大数据领域的共识了,所以这种断言方式都加入到了 flink 的测试框架中来。
数据 diff
我们也曾经试过精准的数据测试。 我们会找一个人,可以是这方面的研发也可以是测试开发, 就是对数据处理程序非常熟的人,根据他想到的测试逻辑构造一份测试数据以及预期的结果数据, 测试数据灌入系统, 然后对比预期的结果数据和系统实际产出的数据, 也就是数据和数据的 diff。 之后把这部分固化成自动化测试,每次迭代都进行回归。 当然, 这个前提我们默认这个梳理的人是正确的, 如果你怀疑他有问题, 让他提供他自己设计的测试用例没问题的证明的话, 就变成套娃逻辑了。 因为当他提出新的方法来证明自己的测试用例的时候, 你就又会说你怎么证明你用来证明自己测试用例没问题的这个证明方式是正确的? 这样就没个玩了, 这个逻辑一层一层套下去没完没了。
PS: 如果你们有线上环境, 完全可以把数据引流到测试环境上来,然后与线上环境的数据处理结果做 diff,这个前提是你相信线上的逻辑是正确的且功能没有变化。 也就是第一次测试的时候,你还是得自己想办法测试,这个跑不了。 如果第一次测试有问题的话,那么其实线上也是有问题的, 数据分析领域的 bug 都是隐藏性很高的, 我见过有些 bug 隐藏了几年才被发现的。 因为数据分析和统计的结果是靠人肉眼上片段不出来是正确还是错误的, 除非是错的太离谱了,一眼就看出来了。 细节的问题用户很可能是感知不到的,一直存在系统中。这就更依赖底层的测试要完善。
逻辑 diff
上面讲的两种测试方法是我们端到端测试的主要方法。 其实这里还有一种, 是我不喜欢的。 就是测试人员参照对需求的理解自己写一套数据处理的程序。 将自己处理的数据结果与产品的结果做 diff, 我不太推荐这种方式,成本太高,需要测试人员很懂 flink/spark 的开发,并且出错的概率很高。
总结
OK,今天也先写到这里吧, 这是我们团队总结出来的功能测试的方法, 如果有疑问或者有更好的测试方法的同学,我们可以留言区讨论。
