专栏文章 如何做好性能压测 4-并发模式与 RPS 模式之争,性能压测领域的星球大战
本文是《如何做好性能压测》系列专题分享的第四期,该专题将从性能压测的设计、实现、执行、监控、问题定位和分析、应用场景等多个纬度对性能压测的全过程进行拆解,以帮助大家构建完整的性能压测的理论体系,并提供有例可依的实战。
该系列专题分享由阿里巴巴 PTS 团队出品,欢迎在文末处加入性能压测交流群,参与该系列的线上分享。
第一期:《压测环境的设计和搭建》,点击这里。
第二期:《性能压测工具选型对比》,点击这里。
第三期:《阿里巴巴在开源压测工具 JMeter 上的实践和优化》,点击这里。
1996 年, LR 4.0 版本发布,将性能测试专业理论工具化、产品化,这直接影响之后 20 多年性能测试领域的理论基础。但是 LR 作为一款商业化产品,因其价格昂贵,推广和传播受限。1998 年底,JMeter 开源 ,并发布 1.0 版本,性能测试领域逐渐蓬勃发展起来。
Loadrunner、Jmeter 引领了性能测试领域的一个时代,功能强大,脚本化,扩展性强,将性能测试标准化、专业化,后续几乎所有性能测试工具或者商业化产品都马首是瞻。本文就性能测试做了一个纯 YY 的 “实践”(真的只是纯理论分析!),有一些不一样的思路跟大家一起探讨下,望轻踩。
前言:并发、RPS 和 RT
接触性能测试的同学要理解的概念有非常多,在正文之前先跟大家就几个核心指标统一下口径:
并发用户、并发、VU:一般用来表示虚拟用户(Virutal User,简称 VU),对应到 Jmeter 的线程组线程,对应到 Loadrunner 的并发 Concurrency ,在本文都是一个意思。
每秒发送请求数、RPS:指客户端每秒发出的请求数,有些地方也叫做 QPS,本文不单独讨论 “事务” 所以可以近似对应到 Loadrunner 的 TPS(Transaction Per Second, 每秒事务数),本文统一叫做 RPS。
响应时间、RT:对,没错,这个就是你理解的那个意思,从发起请求到完全接收到应答的时间消耗。
根据 “Little 定律”,在平衡状态下,我们可以等价认为并发、RPS 和 RT 之间的关系可以概括为:并发数 = RPS * 响应时间
偷懒的话,可以把它当成性能测试领域的 “乘法口诀”,直接背下来吧,他会帮助你快速理解很多问题;如果想深入了解具体的原理可以去拜读下 Eric Man Wong 在 2004 年发表了名为《Method for Estimating the Number of Concurrent Users》的文章,这两者是等价的。
100 工人的问题
如果你还不了解 “RT 对于并发模式的性能测试的影响” 或者还存在一些疑惑,强烈建议读完本节;如果不想理解细节,可以选择直接跳到本节末尾看结论;如果已经充分了解了,可以直接跳过本节。
先从一个大家相对熟知的例子开始,假设有这么一条生产箱子的流水线,安排了 100 个工人,条件如下:
100 个工人的身体素质一模一样, 因此可以近似的认为工作效率只与工作的复杂度有关;
这个流水线有 3 份工作(如下图所示的节点 A、节点 B 和节点 C),所有工人都可以胜任;
节点 A 工人包装箱子平均耗时 RT1=0.5s(秒),节点 B 工人包装箱子平均耗时 RT2=3s(秒),节点 C 工人包装箱子平均耗时 RT3=1.5s(秒);
同一个箱子必须按照 节点 A、节点 B、节点 C 的顺序被包装。
问:节点 A、节点 B、节点 C 分别安排多少工人 X、Y、Z 可以让这个流水线达到最大的产能,并且求得流水线的最大产能 T/s?(如下图)
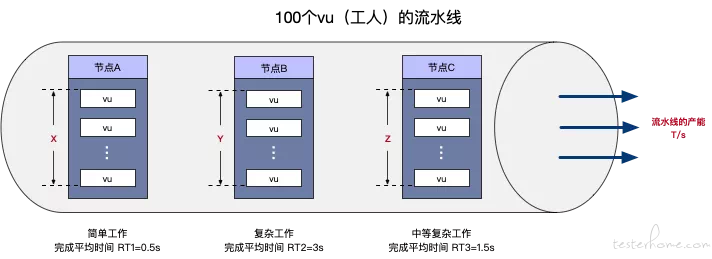
在平衡状态下,我们从宏观的视角来分析下,整条流水线包装完一个箱子的 总耗时=(0.5+3+1.5) s,那么我们可以很轻易地得到流水线的产能:
流水线的产能 T = 100 / (0.5 + 3 + 1.5) = 20 /s
可能很多人有疑问,“什么是平衡状态?”,这个可以这么理解,为了保证所有工人都可以达到最大的工作效率,主管会非常睿智的调配各个节点之间的工人分配直到 “所有工人都有事可做,也不会存在工人忙不过来”,那么从微观的角度去看,如果节点之间的产能不一致,有些节点就会出现箱子等待被处理,有些节点的工人等待箱子的情况。所以,我们可以得到这样的结论 在平衡状态下,所有节点产能肯定是一致的:
T(A) = T(B) = T(C) = T = 20 /s
从而,根据 Little 定律,我们可以推算出来,各个节点的人员(vu)分配了:
X = T(A) * RT1 = 20 * 0.5 = 10
Y = T(B) * RT2 = 20 * 3 = 60
Z = T(C) * RT3 = 20 * 1.5 = 30
下面这张 Jmeter 的图,相信大家可以轻易地跟前面的自理找到对照关系,我这里不再赘述了:
产能 = RPS
工人 = 并发
完成平均时间 RT = 响应时间、RT(rt)
综上所述,我们可以得出两个结论:
在平衡状态下,所有节点的 RPS 必然一样。
在平衡状态下,任意节点的 RT 都会影响整体 RPS ,进而会影响并发在节点之间的分配关系。
为了描述方便,我们将节点 A、节点 B 和节点 C 组成的 “100 人的流水线” 叫做 “串联链路”。
节点 A 的 RPS = 节点 B 的 RPS = ... = 串联链路 RPS
串联链路 RPS = 并发数 / (RT1 + RT2 + ... )
节点 N 的并发数 = RTn * 节点 N 的 RPS = RTn * 串联链路 RPS**
你确定考虑全面了吗?
控制并发是目前最为普遍被使用到的压测模式,打个比方,有一个网站大概会在 下周一 10:00 预估有 10w 人同时访问,那么为了保障网站的问题,很自然的想到使用 10w 个并发来压测下整个网站的接口,对应到 JMeter 即为设置线程组的线程数,对应到 LoadRunner 设置 VU(Visual User)数,很容易理解。
另外,我从阿里云 PTS 官方拿到近 6 个月的数据显示,选择并发模式与 RPS 模式分别占比 89% 与 11%,并发模式占据绝对的规模优势。
但是,如果你已经充分了解了 “RT 对于固定并发模式的性能测试的影响”,这里我不禁要问一句(邪恶脸)“Emm... 你有想过类似 Jmeter、LR 等并发模式压测工具拿到的结果是真实的吗?准确吗?”。
下面我要讲一个 “恐怖故事”,先来看一张相对抽象的环境结构图,
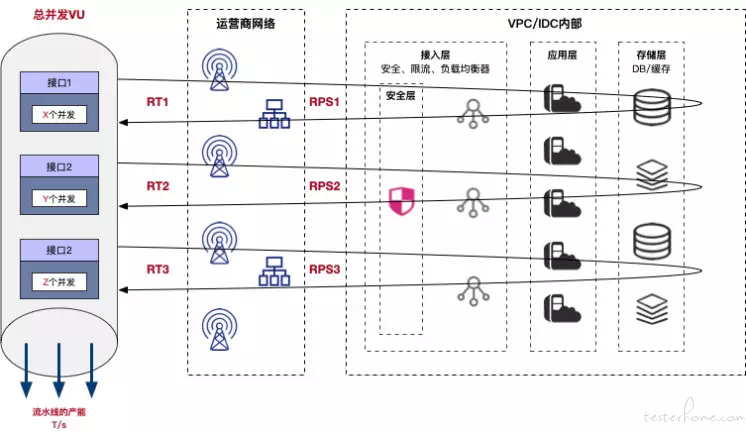
在平衡状态下,已知总并发 VU,以及 接口 1、接口 2、接口 3 的响应时间分别为 RT1、RT2、RT3,通过前面的理论基础,我们可以轻易地写出下面的算式:
T = RPS1 = RPS2 = RPS3 = VU / (RT1 + RT2 + RT3)
接口 1 的并发 X = T * RT1
接口 2 的并发 Y = T * RT2
接口 3 的并发 Z = T * RT3
分析下接口的 RT 的构成,大致概括为下面 5 部分:
压测工具耗时:这个很好理解,压测工具在发送请求之前会做参数的拼装/替换、下载应答报文、解析应答报文(断言)等都是需要耗费时间的,一般情况下压测工具的时间消耗会非常低,可以忽略。但是对于报文较大或者断言较复杂的情况下,压测工具耗时过大也会出现瓶颈;
网络时间:一般来说在 VPC/IDC 内部的网络消耗非常低,所以我们可以近似地认为网络时间消耗都来源于运营商网络。同样,对于接口的请求和应答报文比较大的情况下,不论是运营商网络还是内网网络的带宽都更容易出现瓶颈;
安全、鉴权、负载均衡模块耗时:这一块的时间消耗一般来说相对较低,受限于连接数、带宽等,可能会出现由于配置问题,比如连接数上限超过预期,则会造成等待建连超时;
应用业务处理耗时:一般情况下,应用业务处理耗时占据 RT 的百分比最高,也是一般我们可以通过优化提高吞吐量的重点区域。可能包含 应用之间 RPC 服务调用、数据库 SQL 执行、读写缓存、读写消息等。
第三方依赖耗时:这里就复杂了,各种情况都有,你可以完全信赖或者完全不信赖它的稳定性。一般它的 RT 评估有相关 SLA 的要求,一般压测实施的时候根据 SLA 约定的 RT 要求,mock 掉第三方接口依赖,正式压测的时候再一起联压。
更进一步,可以得出这样的结论,在并发模式下,影响压测结果以及应用服务器的吞吐量的因素有:
压测工具的性能
网络状态
接入层配置和性能
应用服务性能
第三方依赖的 SLA
...
因此,出现了一种混沌状态,可能由于压测工具所在宿主机负载变化、网络环境变化、应用服务性能优化或者劣化等因素的干扰,拿着相同的脚本进行了 10 次,每次得到的接口 RPS 都不一样,服务器端的压力也不一样,但是从表象来看,一切正常,但这样的性能测试并不能真实反映任何问题,也并不能指导运维做出正确容量规划的决策。因为影响 RT 的因素实在是太多太多了,任何客观因素的影响都直接影响测试结果的准确性。
并发模式 = 性能瓶颈 “定性” 分析
在这里,我更愿意定义并发模式性能测试为一种性能瓶颈分析的定性工具,在尽量相同的条件下经过反复测试,通过分析各个接口的 RT 构成找到 “相对的” 性能瓶颈。但是大家有没有想过,将所有接口优化到极限的性能之后,可以拍胸脯说 “我们的系统已经可以抗住 XXX 并发用户量的访问了” 吗?答案是否定的,原因有三:
不真实,主要体现在 ① 环境不真实;② 压测(脚本)模型不真实;
主体错误,并发只是一个诱因和触发器,影响性能的主体是服务端的 RPS;
并发测试的效果真实性依赖于 RT,而 RT 的构成异常复杂。
对了,前面的分析漏了一个影响并发性能测试结果的非常重要的因素:思考时间(用户在操作的时候,步骤之间用户会停顿一段时间)。思考时间的引入会将并发的建模的复杂度带到几乎不能实现的地步,因为它不像其他相对客观的因素,它是非常主观的。假如用户停留的时间很长,可能是因为感兴趣多看一会儿,或者页面上有 100 个表单需要填写,或者看不懂文案是啥意思正在 Google,或者...去冲咖啡了。
有人可能会追问 “思考时间究竟要设置多少合适呢?”,我可以非常明确的说 “不知道!”,如果你有时间,可以通过大数据 BI 分析统计学意义上的每个接口之间用户停顿的时间,然后将它设置上,假设每个接口的思考时间总和为 S=(S1+S2+S3),那么我们可以更新下公式:
T = RPS1 = RPS2 = RPS3 = VU / (RT1 + RT2 + RT3 + S)
接口 1 的并发 X = T * RT1
接口 2 的并发 Y = T * RT2
接口 3 的并发 Z = T * RT3
可以看到,增加了思考时间之后,整体的吞吐量、所有接口的并发都下降了,因为有部分用户在 “思考”。增加 “思考时间” 有助于提高并发模式下性能测试的准确性,除此之外,还有一些提高并发模式的准确性的手段:
压测工具地域定制、运营商定制
增加条件跳转,模拟用户重试行为
增加集合点
...
这些手段你可以非常轻易的在市面上的开源或者云测平台上找到(有些功能可能需要支付一些费用),在这里不再一一赘述,归根到底,可以总结为 “优化接口 RT 使其接近真实值以提高并发模式的准确性”。
但并发模式始终都受制于 “不稳定的”、“难模拟的”、“难预测的” 接口 RT ,通过并发模式拿到指导运维进行容量规划的结果,是要付出的代价会非常大的,甚至也不能达到想要的结果。
在真实情况下,接口 1、接口 2、接口 3 的 RPS 是不一样的,抛开接口异常断言失败不继续调用后面的接口的情况,接口 RPS 关系是呈倒金字塔分布,比方说,浏览商品(接口)了之后不一定会去下单购买(接口),因为大家一般会反复浏览不同的商品选择最中意的再下单,所以浏览商品(接口)的 RPS 必然会比下单购买(接口)的 RPS 要高,用户有放弃继续 “走下一步” 的权利,但是这种情况你如果尝试对并发的分布来建模,是一个非常庞大且复杂工程问题,因为影响的因素实在太多了。
如下图所示,并发压测模式下,所有接口的 RPS 都是一样的,与 “实际情况”(图右部分)大相径庭。
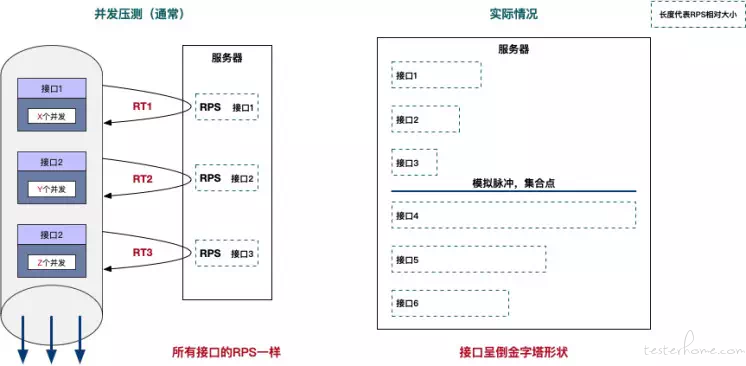
受传统性能测试思路的影响,目前有接近 90% 的企业用户(数据来源于 阿里云 PTS )将并发模式性能测试的结果作为稳定性、容量验收的依据,所以说这是一件非常恐怖的事情。
容量规划:从定性分析到定量分析
在这里我非常乐意跟大家分享一份来源于 QA Intelligence《State of Testing™ Report 2019》关于 2016~2019 年软件开发模式的调查数据:
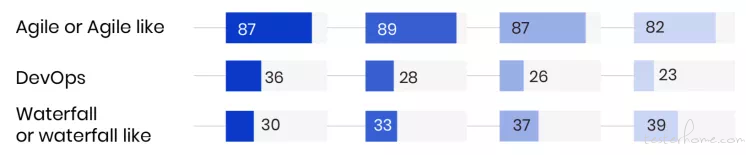
软件开发模式占比(2019、2018、2017、2016)
数据显示,DevOps 第一次超过 Waterfall(瀑布模式)成为第二位被越来越多的企业接受的开发模式,而瀑布模式等传统开发模式有逐渐退出历史舞台的趋势。敏捷开发和 DevOps 大行其道,开发、测试和运维等部门、角色之间需要有一种高效的沟通和协作手段。
想到了一句非常 “肤浅” 但有点道理的话,“性能问题优化之后最终都可以转化为容量问题”,简单地可以理解为测试同学发现了性能瓶颈,然后开发同学经过了优化,运维同学根据优化之后的系统的能力进行扩容或者缩容。瞧!这不就是开发、测试和运维完美协作的一个典型实践嘛?!
这个过程,我们叫做 “容量规划” 的实施过程,重点不是容量而是规划,如果成本不是任何问题,我们可以堆砌无限大的资源,用户体验会极其好,但是会造成极大的资源浪费。所以这里说的 “容量规划” 是在保证用户体验不受影响(稳定性)的前提下,使有限的资源的利用率最大化(成本)的方法论。打个比方,运维准备了 100 台机器,有 5 个应用,那么 “怎么分配这 100 台机器给 5 个应用可以使系统既可以正常对外服务又可以使系统达到最大的吞吐量能力” 就是容量规划要解决的问题。
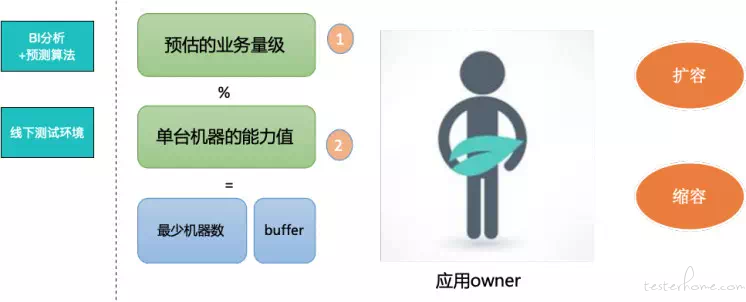
容量规划的核心有一张已经用的 “泛黄” 的图,大家应该一看就明白,有两个核心指标:
- 预估的业务量级:对于单应用而言就是这个应用的 RPS 吞吐量峰值,这个数据一般可以来源于流量模型和历史数据沉淀;
- 单台机器的能力值:在某一个流量模型下,单台机器系统水位达到安全水位时的 RPS 峰值。
上面提到一个概念叫做 “流量模型”,这个流量模型你可以近似的认为就是前面图中 “实际情况” 的 RPS 倒金字塔,他有两个要素:
接口范围
每个接口的 RPS
容量规划的目的性非常强,也就是在特定 “流量模型” 下,给出资源分配的最优解。在压测实施的时候,压测的主体是接口的 RPS,按照流量模型进行试压。(如果你还在想为什么主体是 RPS 而不是并发的话,请在仔细阅读前面那章)
RPS 模式压测在容量规划的典型应用,是并发模式无法实现的。正式因为此,我们才能将性能测试从 “定性分析” 转化为 “定量分析”。
阿里在 2013 年构建了一整套基于线上全链路压测的容量规划体系,逐渐替代之前单应用、单接口这种低效的容量评估手段,过程也是非常曲折的。容量规划是一个非常大的课题,本文的重点不是 “容量规划”,如果你对 “智能化全链路容量规划” 感兴趣,请在文末留言或加入我们的性能压测交流钉群。
结尾:无意引战
并发模式与 RPS 模式压测各有各自的使用场景,并发模式更加适用于对于系统定性的分析,比如帮助定位性能瓶颈,单接口的性能基线沉淀(对比历史性能优化 or 劣化);而 RPS 模式在对系统做定量的分析有杰出表现,比如容量规划、全链路性能基线沉淀,当然也可以帮助定位性能瓶颈。并发模式的难点在于 RT 的准确性拟真, RPS 模式的难点在于模型的准确性评估和预测,从实现难度上来说,前者相对于后者来说难度更大一些、掌控度更低一些。
当然,我无意引战,并发模式、RPS 模式、你想要的和你还没有想到未来想要的都可以在 阿里云 PTS 上找到。
** 本文作者:** 韩寅,花名隐寒,阿里云 PTS 高级技术专家,2014 年加入阿里巴巴,一直从事性能测试和高可用领域的相关工作。

