做自动化测试快 1 年,分享一下工作经验和看法,并提出一些疑问
工作经历
2018 年上半年离职之后,在家蹲了几个月,学了点 python 爬虫方面的知识,终于找到家要我做去自动化测试公司,也算是成功转行了。
没想到去了之后就我一个人在做自动化测试,一切都是从零开始,技术栈都还在选择中,于是就一边自学,一边做技术验证,一边写自动化测试框架,过了两个月,框架也差不多成形了,技术问题基本上都解决了,才慢慢加入几个人,最后也算是有了一个 5 个人的小团队。
关于自动化测试框架
自动化测试框架的作用在我的理解里就是封装了一些操作方法,降低编写脚本的难度,能够组织自动化测试用例运行,并有相应的产出结果(测试报告和运行日志)。
我的框架是在网上流传的使用 Python+Selenium+Unittest+Htmlreport 搭建的框架基础上面改的,基本上那个框架在公司里使用是不可能的,缺少了很多东西,操作的封装也不够。
后来又了解到有 sikuli 和 Airtest ,这两个工具使用图片识别的方法,相对于 selenium 来说,写起来方便一些,而且公司前端页面比较复杂(报表系统),总是需要在 iframe 跳来跳去,所以仿照 sikuli ,用 python 重写了 sikuli 的 api ,并集成到了框架中。
但是缺少一个可以截取图片、填充代码、操作图片和带图片预览代码的 IDE(这部分功能可以参考 sikuli 和 airtest 的 ide),于是想到了开发一个 Pycharm 插件(功能也是仿照 sikuli ide),这样做也有一个好处,pycharm 毕竟是一个成熟的 IDE.
于是就有了一套自动化测试脚本的开发工具(源码目前不会分享出来):
框架:Python + Selenium + Unittest + Htmlreport + 图片识别(opencv)
项目结构:一些必要的文件夹、配置文件
辅助工具:Pycharm 插件,插件已经开源啦,看这里
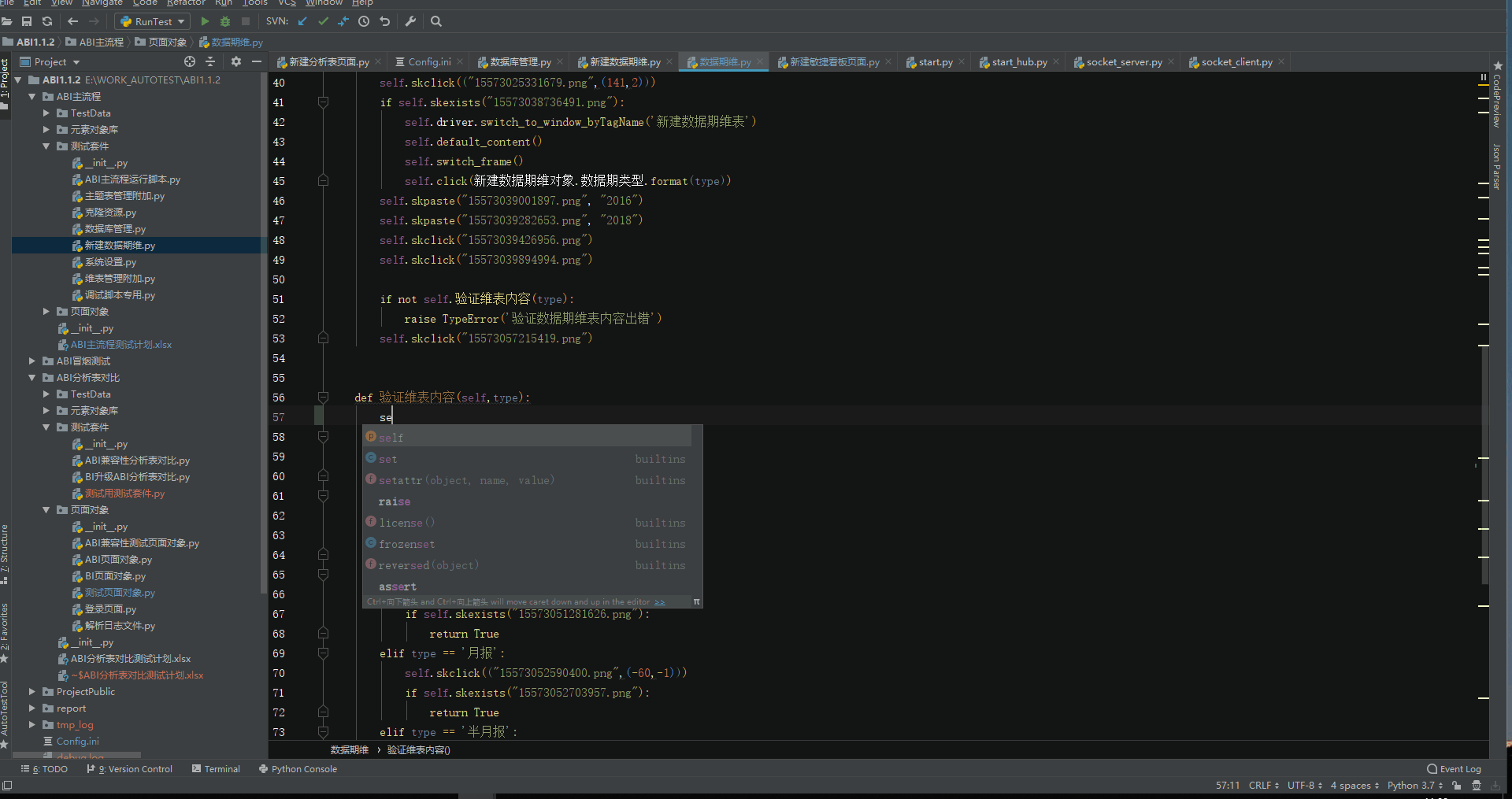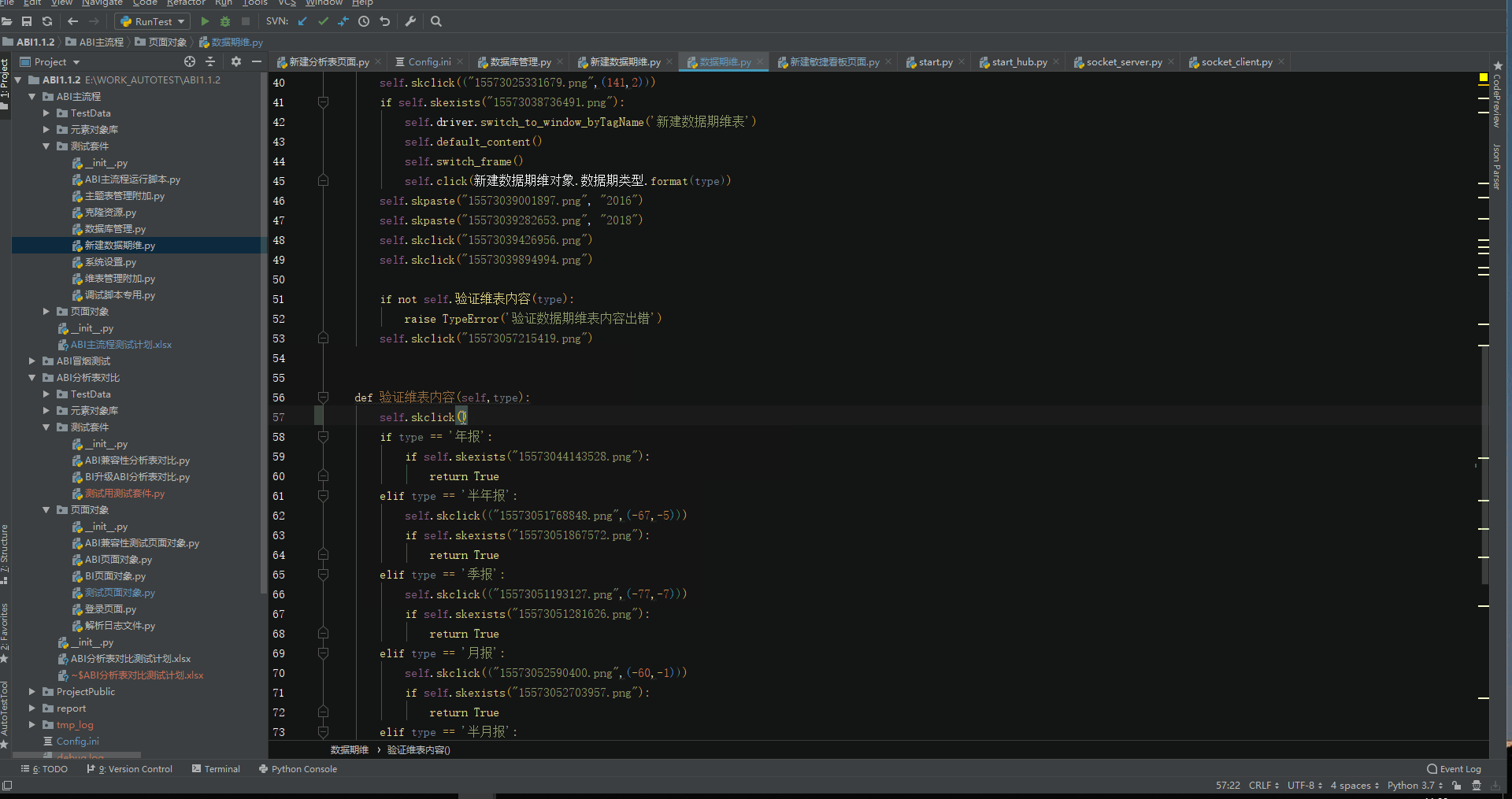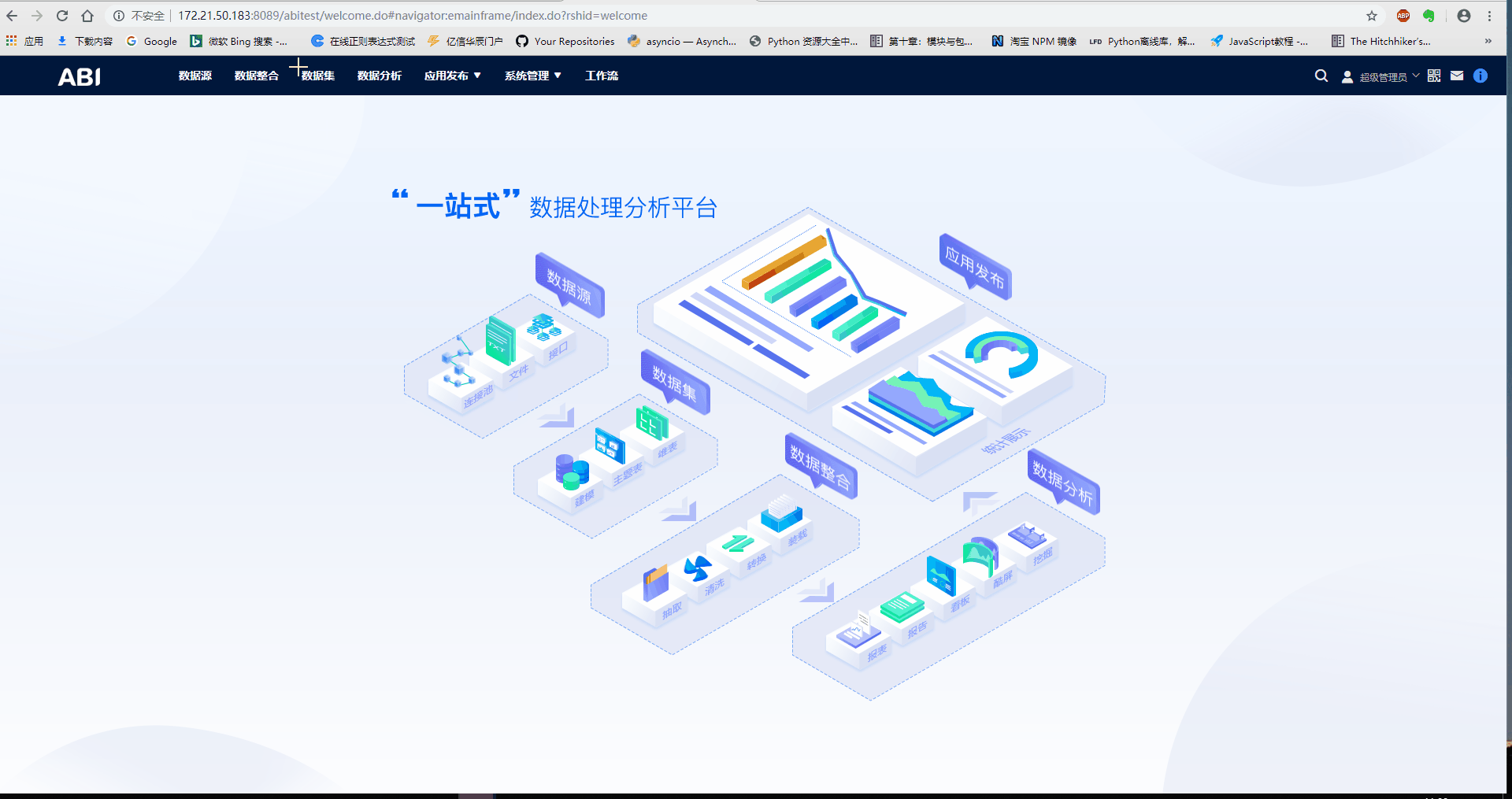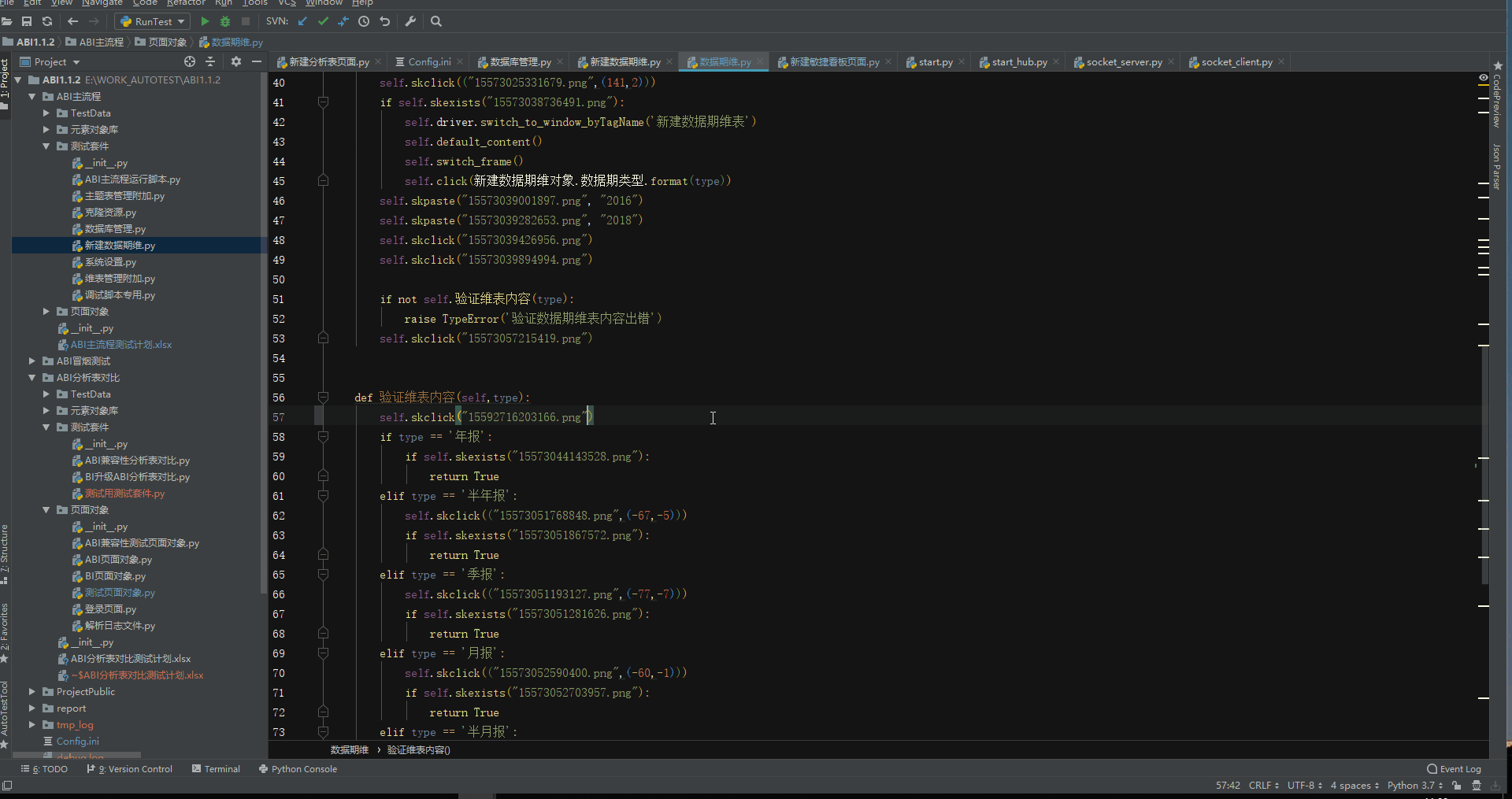
下图中用红框框出来的就是插件的功能,绿框里面是项目的结构目录,黄框里面是脚本代码,里面使用的方法既有图片识别的,还有 selenium 的。
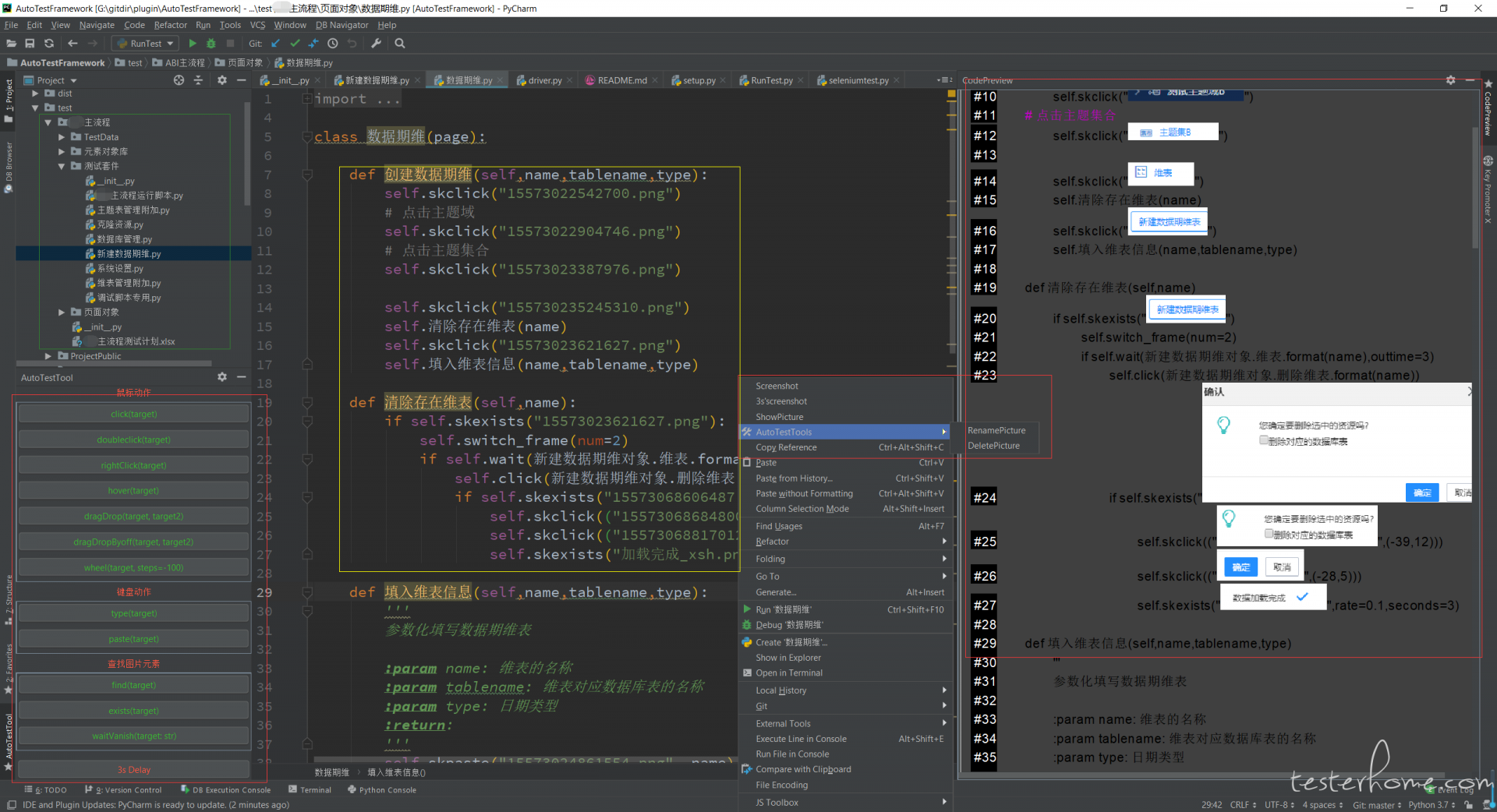
下面是一些插件操作的演示动图

框架运行原理
可另存下来之后看大图

解决自动化测试中遇到的问题
数据驱动
关于数据驱动的说法网上有很多,我觉得这样做的好处在于,当有新的情况出现的时候,只需要配置参数文件,不用动代码。
需要对 unittest 做一点修改,就能支持参数化了。后面的测试类继承 ParametrizedTestCase 就能传递参数进去了。
要实现参数化需要考虑的事件有:参数文件应该是什么格式,里面的数据怎么存放,怎么将参数传递到相应的测试类,测试类里面怎么方便的使用参数。
我的方法是,用 excel 文件储存参数,然后利用模块测试计划配置文件将测试套件与参数文件联系起来,框架运行中会读取参数文件里面的数据,将数据转变为字典格式的数据传递到测试套件中,最后在测试套件脚本中使用参数。
unittest 实现添加参数代码
class ParametrizedTestCase(unittest.TestCase):
""" TestCase classes that want to be parametrized should
inherit from this class.
"""
def __init__(self, methodName='runTest', param=None):
super(ParametrizedTestCase, self).__init__(methodName)
self.param = param
@staticmethod
def parametrize(param, classname, functionname=None):
""" Create a suite containing all tests taken from the given
subclass, passing them the parameter 'param'.
"""
testloader = unittest.TestLoader()
suite = unittest.TestSuite()
testnames = testloader.getTestCaseNames(classname)
for name in testnames:
if not functionname:
suite.addTest(classname(name, param=param))
else:
# 这里可以实现,不同的testcase获取不同的参数
if name == functionname:
suite.addTest(classname(name, param=param))
return suite
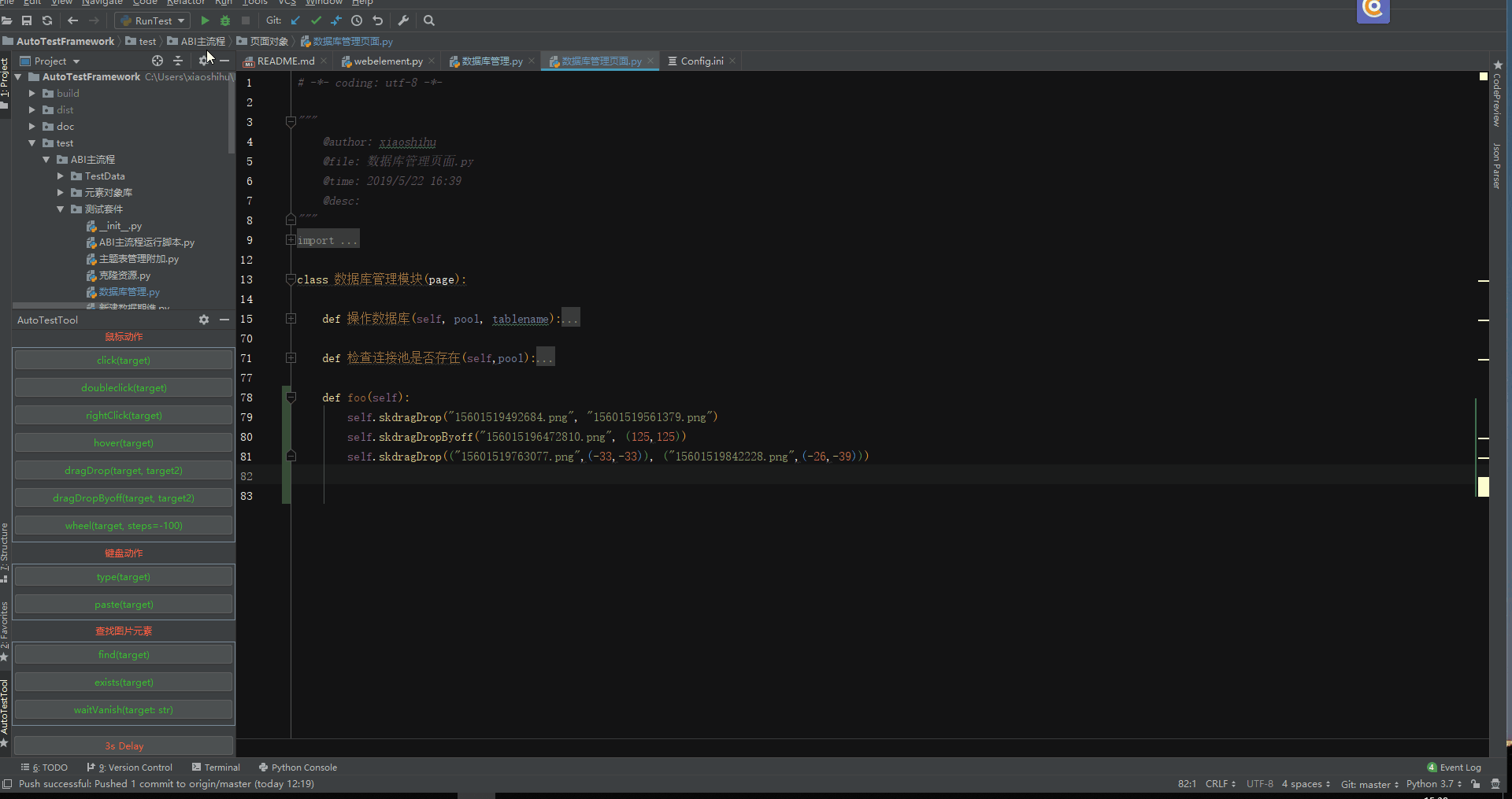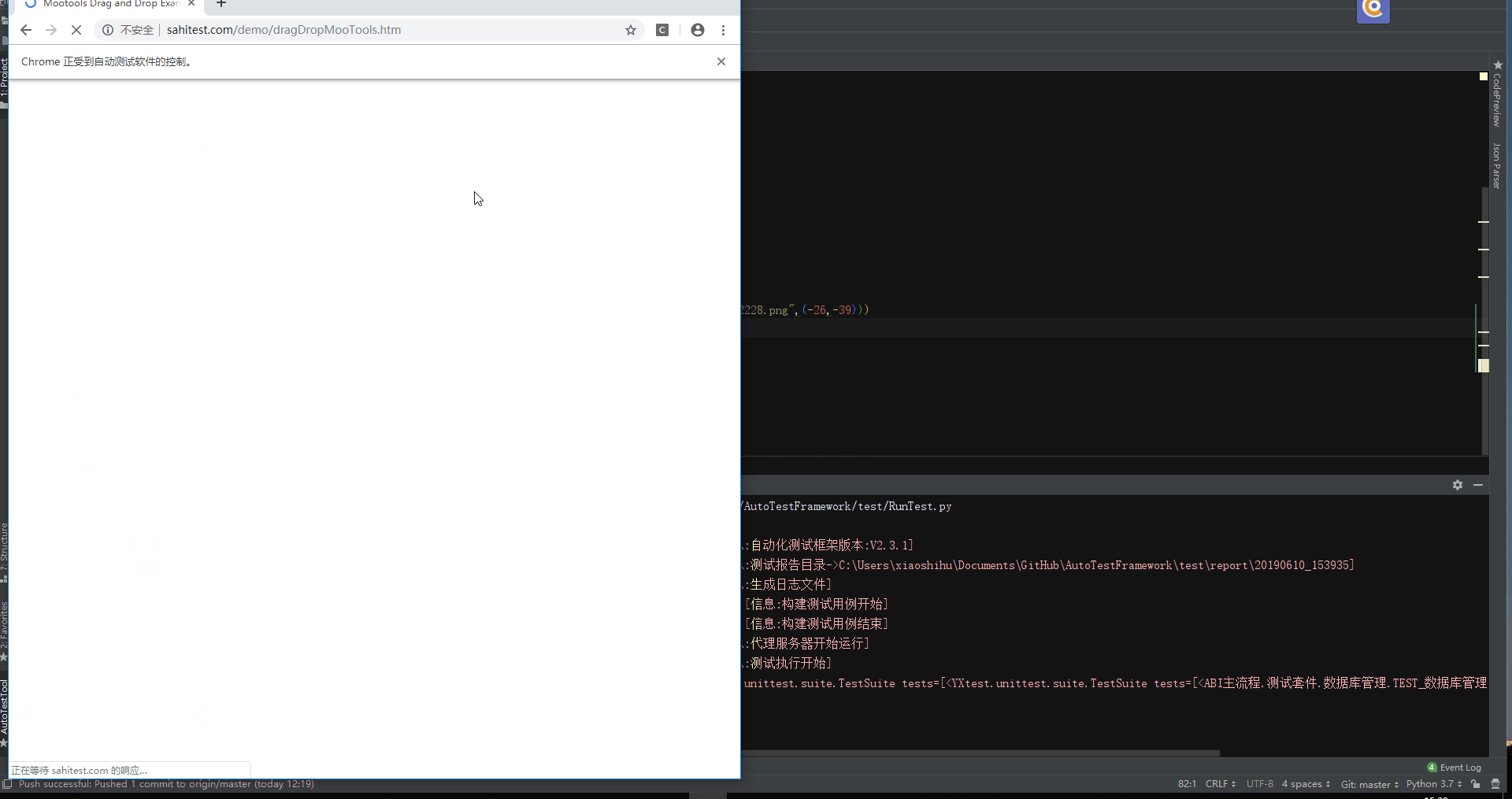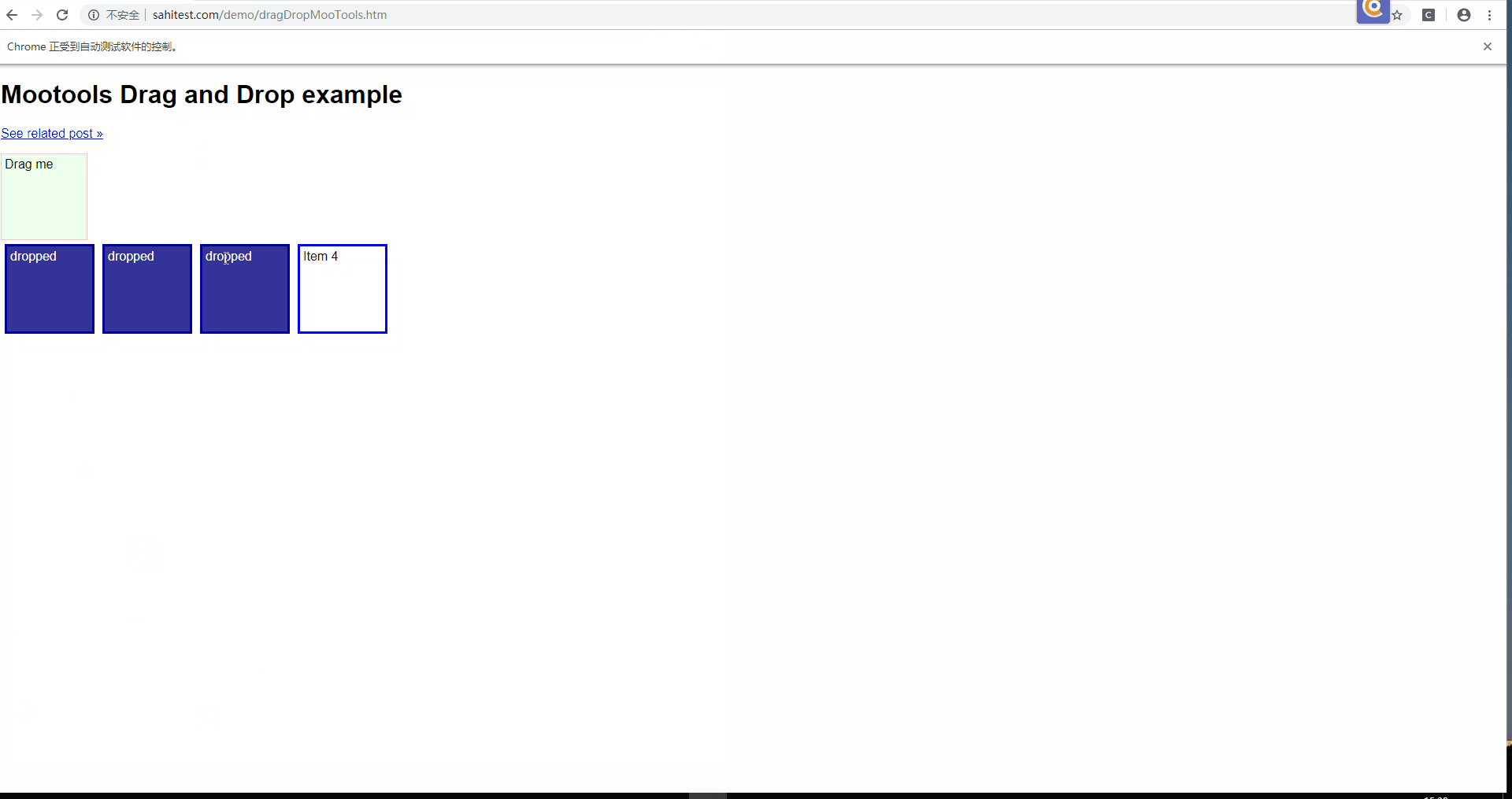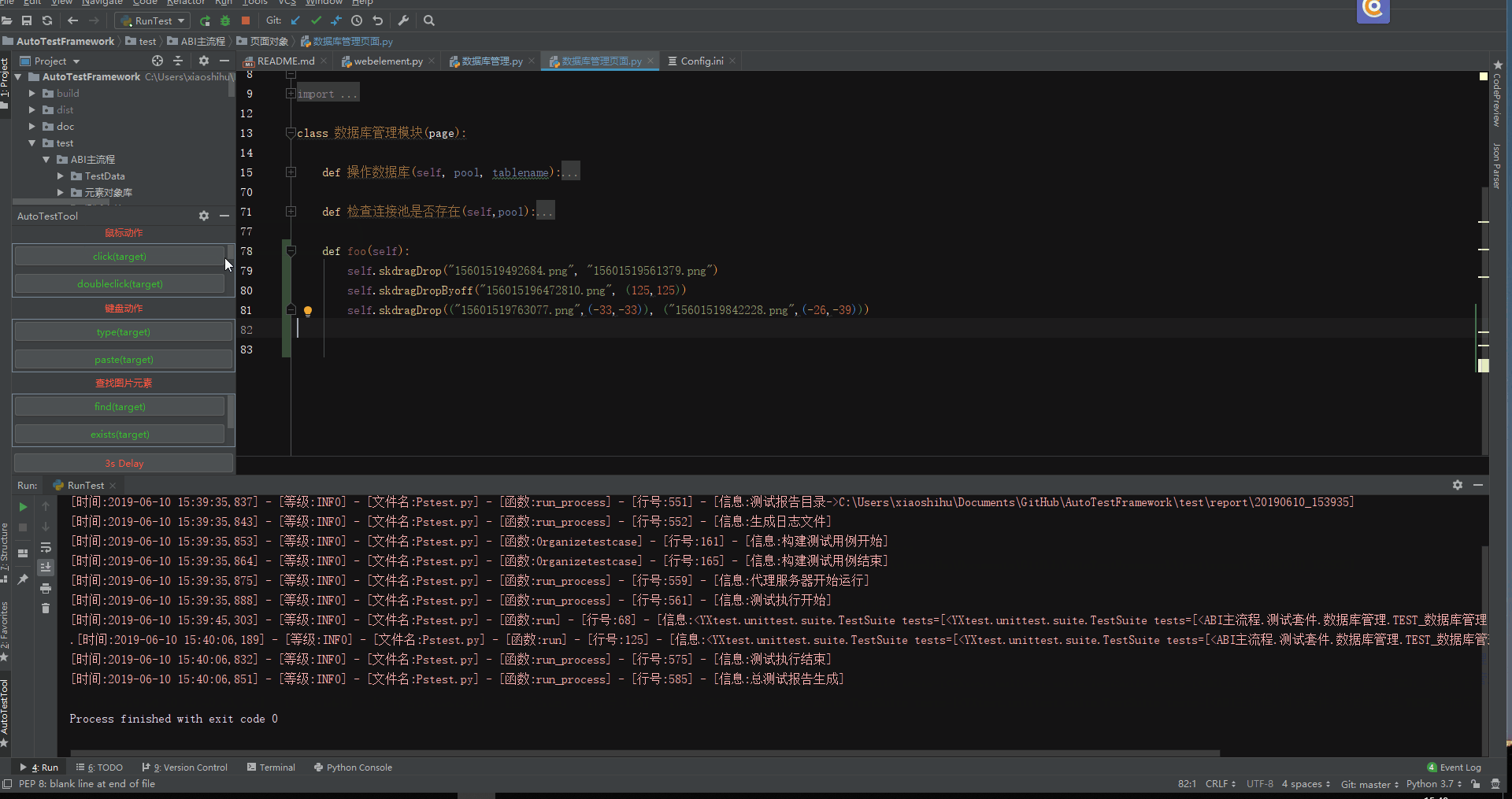
参数文件截图

从图片上可以看到,脚本需要在多个环境下运行,这种情况就比较适合参数化,将链接环境的数据实现参数化,还可以添加控制开关,后面的是否执行列就能控制这条参数是否执行,需要注意的是一个测试套件只接受一条参数(就是一行数据),如果同时传递多条参数,就会产生多个测试套件,这些测试套件可以并发执行(在我的框架中每个测试套件都在单独的进程里面运行)。
下面来说一下参数怎么在测试脚本里面里面使用,下图为模块测试计划的配置文件(指定一个模块中需要运行哪些测试套件里面的哪些测试类里面的哪些测试方法),在这个测试计划配置文件中将参数文件与测试类关联起来,最终参数传递进去之后会是什么样子呢?为参数文件中这行数据与列标题组成的字典,具体看下面代码块的例子。
模块测试计划配置文件截图

参数化示例代码
class TEST_01_ABI基准环境分析表数据抓取(TestCaseMore):
def test_01_获取ABI数据(self):
self.ABI页面 = ABI页面对象(None, None)
# self.param['abi基准环境']就是取这行 abi基准环境 列的数据
self.ABI页面.基准环境并发执行(self.param['abi基准环境'], self.param, False)
class TEST_02_ABI测试环境分析表数据抓取(TestCaseMore):
def test_01_获取ABI数据(self):
self.ABI页面 = ABI页面对象(None, None)
self.ABI页面.测试环境并发执行(self.param['abi测试环境'], self.param, False)
参数化框架里面的实现
# 获取参数文件的绝对路径,参数文件固定放在模块的某一个文件夹下面
data_path = os.path.join(self.project_path, modulename, "TestData", datafile)
try:
# 转换参数文件里面的数据结构,变成每行数据组成字典的列表
data = Public.inputDataDel(data_path)
except:
self.logger.error('读取参数数据文件出错:{}'.format(traceback.format_exc()))
raise
for i in data:
if i['是否执行'] == 'y' or i['是否执行'] == 'Y':
suite_param = unittest.TestSuite()
# 将参数传递到测试套件,这个位置是关键点
addtest_str = "suite_param.addTest(YXtest.testcasemore.testcasemore.TestCaseMore.parametrize(" + "i," + classname + "," + "'" + funname + "'" + "))"
try:
eval(addtest_str)
yield self.manager.Task(suite_param, parent_task, child_task, serialnum)
except:
self.logger.error(
'添加测试用例失败->{}\n错误信息:{}'.format(addtest_str, traceback.format_exc()))
raise
测试套件之间复杂的关系
先说一下框架里面怎么组织测试用例运行:

从上图可以看出,是一个很明显的生产者 -- 消费者模式,主进程生成任务队列,然后再生成进程池,再将任务队列里面的任务添加到进程池中运行,子进程通过进程间共享的队列将运行结果传递回主进程。
这个图里面假设了很简单的一种依赖关系,就是测试套件 1 和 2 是并发执行的,表示这两个测试套件无任何关系,测试套件任务 3 依赖与测试套件任务 2 ,只有测试套件任务 2 成功执行之后,才能执行测试任务 3 ,如果测试套件任务 2 失败,3 会直接设置为跳过状态,同理,后面依赖于 3 的任务也将全部跳过。
1、测试套件并发执行
测试套件并发执行并不指的是一定要并行的运行多个测试用例,而是指可以同时运行多个测试套件,这几个测试套件之间没有任何的依赖关系,其中一个出异常或者失败了,不会影响其他的测试套件,从上面的流程图的测试套件任务 2 和 3 演示了这种关系。
2、测试套件之间的依赖
上面的流程图仅仅演示了测试套件之间很简单的依赖关系,在实际工作中我们可能会遇到很复杂的依赖关系,如下图所示:
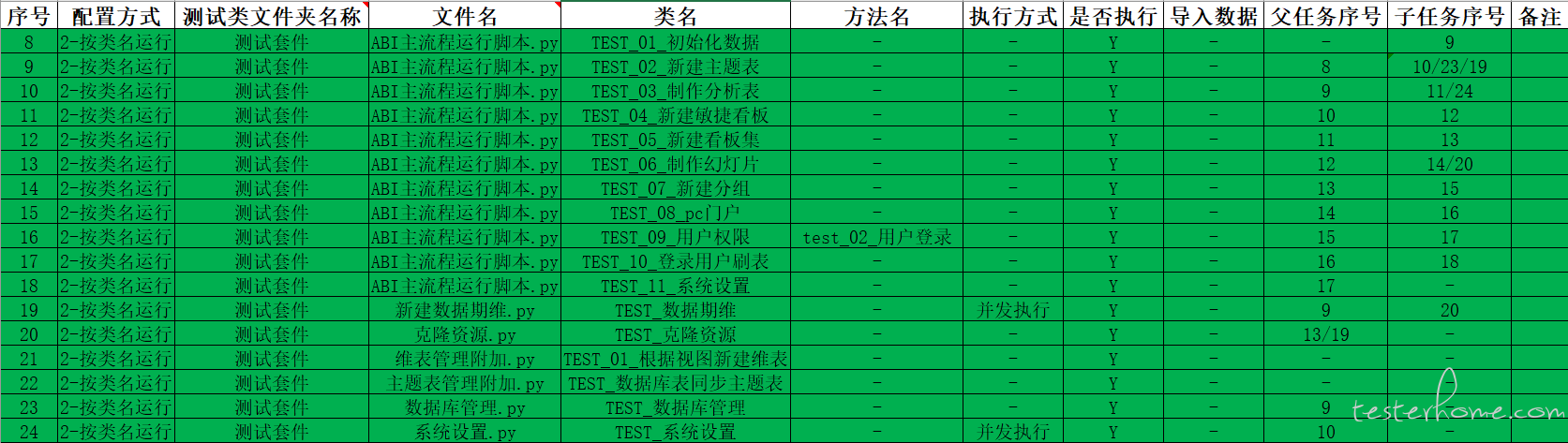
上图里面的运行顺序,我用一张流程图来解释:

从图上可以看出,任务的流程是一个网状的结构,一个节点可以有多个父节点和多个子节点。为什么会有多个 19 号任务和多个 24 号任务?可以从上面的配置文件中看到,配置了按类运行,后面又配置了并发运行,这样配置会将测试类中的每个测试方法都组织成一个单独的测试套件,所以, 19 号和 24 号就变成了多个测试套件,这些测试套件并发运行。
一条执行链上的只要当中一个节点出错了,后面的节点就都会跳过,这样就解决了较复杂的依赖关系。
task 类
from multiprocessing.managers import SyncManager
from typing import List
class MyManager(SyncManager):
pass
def getManager():
m = MyManager()
m.start()
return m
class Task(object):
def __init__(self, suite, parent: List, child: List, serialnum):
'''
这个任务将测试套件包装了一下,有点像一个链条上面的节点,指定了父节点和子节点,只不过这些节点
可能不仅仅只有一个
:param suite: 测试套件
:param parent: 父节点
:param child: 子节点
:param serialnum: 测试套件的编号,就是第一列的序列号
'''
self.parent = parent
self.child = child
self.serialnum = serialnum
self.suite = suite
self.result = None
# 设置当前的对象的运行状态
def setresult(self, result):
self.result = result
def getresult(self):
return self.result
def getserialnum(self):
return self.serialnum
def getparent(self):
return self.parent
def getchild(self):
return self.child
def getsuite(self):
return self.suite
def __repr__(self):
return 'serialnum:{},parent:{},child:{},result:{}'.format(self.serialnum, self.parent, self.child, self.result)
# 注册之后,再生成该类的实例能在多个进程里面传递
MyManager.register('Task', Task)
3、测试套件里面测试方法之间的依赖关系
同一个测试类里面有多个测试方法,在 unittest 里面,测试方法之间不做处理的话是没有关系的,除非手动加上 skip 相关的函数,我修改了 unittest 的源码(所以将 unittest 拿到了框架里面),让同一个测试类里面的方法默认是相互依赖的,运行顺序就是方法名称的排序,如果中间有一个测试方法出错了,后面的方法会跳过,问题来了,如果我不想要这些方法依赖怎么办?还记得上面的类并发运行的设置吗,还有就是,不相关的测试方法可以分成多个测试类来写。
ajax 请求的问题
ajax 请求严重影响了脚本的稳定性,除了 ajax 请求前端的卡顿也会影响脚本的运行,而且每次的运行环境不可控,所以必须要动态处理这类问题,这类问题可以分类
等待元素出现
由于 ajax 请求的响应时间不固定,有可能在操作某一个网页元素的出现两种情况,
- 元素没有加载出来,不在 DOM 结构里面,这种情况会报找不到元素的异常
- 元素不可见,在 DOM 结构里面,如果对元素进行了操作(如点击),会报元素不可点击的操作
- 第一种情况可以设置 seleniun 的隐式等待时间,一般都能比较方便的解决,第二种情况需要自己判断元素是否可见,我采用的是判断元素的大小是否不为 0 ,也可以使用 webelement 类自带的
is_display()方法去判断,还要看前端是否遵守规范
元素可以操作,操作之后没有任何反应
一般遇到这种问题就没辙了,元素可见,可点击,但是页面上其他位置还没完全加载出来,点击这个元素之后一点反应都没有,下一步操作就会报错,为了解决这种问题我也找了很多方法,有尝试使用 JavaScript 去判断 xhr 请求数量是否为 0,但是这个东西也跟前端有关系,如果前端使用了某一个前端框架的方法发送 xhr 请求,一般前端框架里面都会使用一个全局变量保存还未响应 xhr 请求的数量,这个时候就可以利用 selenium 执行一段 JavaScript 代码检查这个变量的值,但是,我们公司前端发送 xhr 请求的方法好像是自己写的(看着那一坨 JavaScript 代码真的觉得头晕目眩恶心),没有在里面找到什么可以利用的东西,最后想出了使用 http 代理监听 xhr 请求的办法,这个时候判断 xhr 请求都已经完成就很简单了。
下面给出两种解决方法的代码
- 下面这段代码(出至这里)可以解决使用 JQuery,Angular 发送 xhr 请求的问题,但是有一个点需要注意,xhr 请求有可能是一个接一个发送的,如果运气不好,有可能在你使用的刚好所有的 xhr 都响应完了,然后立马又发送了 xhr 请求
public class JSWaiter {
private static WebDriver jsWaitDriver;
private static WebDriverWait jsWait;
private static JavascriptExecutor jsExec;
//Get the driver
public static void setDriver (WebDriver driver) {
jsWaitDriver = driver;
jsWait = new WebDriverWait(jsWaitDriver, 10);
jsExec = (JavascriptExecutor) jsWaitDriver;
}
private void ajaxComplete() {
jsExec.executeScript("var callback = arguments[arguments.length - 1];"
+ "var xhr = new XMLHttpRequest();" + "xhr.open('GET', '/Ajax_call', true);"
+ "xhr.onreadystatechange = function() {" + " if (xhr.readyState == 4) {"
+ " callback(xhr.responseText);" + " }" + "};" + "xhr.send();");
}
private void waitForJQueryLoad() {
try {
ExpectedCondition<Boolean> jQueryLoad = driver -> ((Long) ((JavascriptExecutor) this.driver)
.executeScript("return jQuery.active") == 0);
boolean jqueryReady = (Boolean) jsExec.executeScript("return jQuery.active==0");
if (!jqueryReady) {
jsWait.until(jQueryLoad);
}
} catch (WebDriverException ignored) {
}
}
private void waitForAngularLoad() {
String angularReadyScript = "return angular.element(document).injector().get('$http').pendingRequests.length === 0";
angularLoads(angularReadyScript);
}
private void waitUntilJSReady() {
try {
ExpectedCondition<Boolean> jsLoad = driver -> ((JavascriptExecutor) this.driver)
.executeScript("return document.readyState").toString().equals("complete");
boolean jsReady = jsExec.executeScript("return document.readyState").toString().equals("complete");
if (!jsReady) {
jsWait.until(jsLoad);
}
} catch (WebDriverException ignored) {
}
}
private void waitUntilJQueryReady() {
Boolean jQueryDefined = (Boolean) jsExec.executeScript("return typeof jQuery != 'undefined'");
if (jQueryDefined) {
poll(20);
waitForJQueryLoad();
poll(20);
}
}
public void waitUntilAngularReady() {
try {
Boolean angularUnDefined = (Boolean) jsExec.executeScript("return window.angular === undefined");
if (!angularUnDefined) {
Boolean angularInjectorUnDefined = (Boolean) jsExec.executeScript("return angular.element(document).injector() === undefined");
if (!angularInjectorUnDefined) {
poll(20);
waitForAngularLoad();
poll(20);
}
}
} catch (WebDriverException ignored) {
}
}
public void waitUntilAngular5Ready() {
try {
Object angular5Check = jsExec.executeScript("return getAllAngularRootElements()[0].attributes['ng-version']");
if (angular5Check != null) {
Boolean angularPageLoaded = (Boolean) jsExec.executeScript("return window.getAllAngularTestabilities().findIndex(x=>!x.isStable()) === -1");
if (!angularPageLoaded) {
poll(20);
waitForAngular5Load();
poll(20);
}
}
} catch (WebDriverException ignored) {
}
}
private void waitForAngular5Load() {
String angularReadyScript = "return window.getAllAngularTestabilities().findIndex(x=>!x.isStable()) === -1";
angularLoads(angularReadyScript);
}
private void angularLoads(String angularReadyScript) {
try {
ExpectedCondition<Boolean> angularLoad = driver -> Boolean.valueOf(((JavascriptExecutor) driver)
.executeScript(angularReadyScript).toString());
boolean angularReady = Boolean.valueOf(jsExec.executeScript(angularReadyScript).toString());
if (!angularReady) {
jsWait.until(angularLoad);
}
} catch (WebDriverException ignored) {
}
}
public void waitAllRequest() {
waitUntilJSReady();
ajaxComplete();
waitUntilJQueryReady();
waitUntilAngularReady();
waitUntilAngular5Ready();
}
/**
* Method to make sure a specific element has loaded on the page
*
* @param by
* @param expected
*/
public void waitForElementAreComplete(By by, int expected) {
ExpectedCondition<Boolean> angularLoad = driver -> {
int loadingElements = this.driver.findElements(by).size();
return loadingElements >= expected;
};
jsWait.until(angularLoad);
}
/**
* Waits for the elements animation to be completed
* @param css
*/
public void waitForAnimationToComplete(String css) {
ExpectedCondition<Boolean> angularLoad = driver -> {
int loadingElements = this.driver.findElements(By.cssSelector(css)).size();
return loadingElements == 0;
};
jsWait.until(angularLoad);
}
private void poll(long milis) {
try {
Thread.sleep(milis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- 下面这段代码是我自己写的一个 http 请求代理,在这篇文章的基础上修改的
import asyncio
import threading
import time
import logging
import requests
from aiohttp import web, ClientSession
from aiohttp.log import web_logger, access_logger, client_logger, internal_logger, server_logger, ws_logger
try:
from .log.logger import logger
except Exception as e:
logger = None
bad_headers = (
"accept-encoding", "content-encoding", "transfer-encoding", "content-length", "proxy-connection", "connection",
"host")
# 用来判断异步请求和http请求已经完成
xhr_record_time = 0
http_record_time = 0
xhr_count = 0
http_count = 0
# 控制代理服务器的关闭
proxy_sig = 'run'
proxy_ip = '127.0.0.1'
proxy_port = '8889'
query_port = '8899'
proxy_site = f'{proxy_ip}:{proxy_port}'
query_site = f'{proxy_ip}:{query_port}'
class Request():
def __init__(self, request, xhr):
self.request = request
self.xhr = xhr
def headle_headers(headers):
h = {}
for name, value in headers.items():
if name.lower() not in bad_headers:
h[name] = value
# h['Connection'] = "close"
return h
# 阻止错误日志出现
def setlog():
web_logger.setLevel(logging.CRITICAL)
access_logger.setLevel(logging.CRITICAL)
client_logger.setLevel(logging.CRITICAL)
internal_logger.setLevel(logging.CRITICAL)
server_logger.setLevel(logging.CRITICAL)
ws_logger.setLevel(logging.CRITICAL)
class ProxyThread(threading.Thread):
'''代理服务器'''
def __init__(self, logger=None, port=None):
threading.Thread.__init__(self)
self.logger = logger
self.port = port
async def getresp(self, Request, method, url, headers, data):
global http_count
global xhr_count
global xhr_record_time
global http_record_time
async with ClientSession(loop=self.loop) as session:
try:
# 如果需要代理https请求,需要设置ssl之类的代理服务器
async with session.request(method, url, headers=headers, data=data, allow_redirects=False) as resp:
body = await resp.read()
headers = headle_headers(resp.headers)
response = web.Response(body=body, status=resp.status, reason=resp.reason, headers=headers)
except:
if Request.xhr:
xhr_count -= 1
xhr_record_time = time.time()
http_count -= 1
http_record_time = time.time()
return web.Response()
if Request.xhr:
xhr_count -= 1
xhr_record_time = time.time()
http_count -= 1
http_record_time = time.time()
return response
async def factory(self, app, handler):
async def transfer(request):
global http_count
global xhr_count
method = request.method
url = str(request.url)
# 阻止本地请求,不然会出现无限循环请求自己
if logger:
logger.debug(f'send=>{url}')
if proxy_site in url:
return
xhr = None
headers = headle_headers(request.headers)
http_count += 1
# FIXME: 2019/5/30 有可能前端xhr请求头会有变化
if headers.get('X_REQUESTED_WITH', None) or headers.get('X-Requested-With', None):
xhr = 'xhr'
xhr_count += 1
data = await request.read()
res = await self.getresp(Request(request, xhr), method, url, headers, data)
if logger:
logger.debug(f'receive<={url},status={res.status}')
return res
# 返回一个协程函数
return transfer
async def init(self):
setlog()
# FIXME: 2019/5/30 需要自己设置request body的大小
app = web.Application(middlewares=[self.factory],client_max_size=1024**3)
self.runner = web.AppRunner(app, access_log=None)
await self.runner.setup()
self.site = web.TCPSite(self.runner, 'localhost', self.port)
await self.site.start()
async def check(self):
while True:
if proxy_sig == 'stop':
await self.stopthread()
break
await asyncio.sleep(1)
def run(self):
new_loop = asyncio.new_event_loop()
asyncio.set_event_loop(new_loop)
self.loop = asyncio.get_event_loop()
self.loop.create_task(self.init())
self.loop.create_task(self.check())
# 下面的语句会使程序阻塞,进入到事件循环中
self.loop.run_forever()
async def stopthread(self):
await self.site.stop()
await self.runner.shutdown()
await self.runner.cleanup()
await self.loop.shutdown_asyncgens()
self.loop.call_soon_threadsafe(self.loop.stop)
class ServerThread(ProxyThread):
'''查询服务器'''
@staticmethod
async def get_xhrcount(request):
return web.Response(text=str(xhr_count))
@staticmethod
async def get_xhrtime(request):
return web.Response(text=str(xhr_record_time))
@staticmethod
async def get_httpcount(request):
return web.Response(text=str(http_count))
@staticmethod
async def get_httptime(request):
return web.Response(text=str(http_record_time))
async def init(self):
setlog()
app = web.Application()
# 添加视图函数
# 访问地址 http://127.0.0.1:8899/xhr ...
app.router.add_get("/xhr", self.get_xhrcount)
app.router.add_get("/xhrtime", self.get_xhrtime)
app.router.add_get("/http", self.get_httpcount)
app.router.add_get("/httptime", self.get_httptime)
self.runner = web.AppRunner(app)
await self.runner.setup()
self.site = web.TCPSite(self.runner, 'localhost', self.port)
await self.site.start()
# 开启代理服务器和查询全局变量的服务器
def startProxy():
proxythread = ProxyThread(port=proxy_port)
proxythread.start()
serverthread = ServerThread(port=query_port)
serverthread.start()
return proxythread, serverthread
# 关闭两个服务器
def stopProxy():
global proxy_sig
proxy_sig = 'stop'
time.sleep(3)
def getxhrcount():
r = requests.get(f'http://{query_site}/xhr')
if r.status_code == 200:
return float(r.text)
else:
raise ConnectionError(f"访问链接 http://{query_site}/xhr 出错")
def getxhrtime():
r = requests.get(f'http://{query_site}/xhrtime')
if r.status_code == 200:
return float(r.text)
else:
raise ConnectionError(f"访问链接 http://{query_site}/xhrtime 出错")
def gethttpcount():
r = requests.get(f'http://{query_site}/http')
if r.status_code == 200:
return float(r.text)
else:
raise ConnectionError(f"访问链接 http://{query_site}/http 出错")
def gethttptime():
r = requests.get(f'http://{query_site}/httptime')
if r.status_code == 200:
return float(r.text)
else:
raise ConnectionError(f"访问链接 http://{query_site}/httptime 出错")
# 对 xhr 数量进行了两次判断,就是为了防止之前说的那种情况
def wait_xhr_complete(outtime=30, logger=None, ):
start = time.time()
while True:
xhrnum = getxhrcount()
oldtime = getxhrtime()
time.sleep(0.2)
newxhrnum = getxhrcount()
newtime = getxhrtime()
if xhrnum == 0 and newxhrnum == 0 and oldtime == newtime:
if logger:
logger.debug(f'xhr请求最后的响应时间戳为:{newtime}')
return True
else:
if time.time() - start > outtime:
if logger:
logger.warning(f'等待xhr请求响应超时,超时时间为{outtime}s')
return False
time.sleep(0.5)
if __name__ == "__main__":
thread = ProxyThread(port=proxy_port)
thread.start()
thread2 = ServerThread(port=query_port)
thread2.start()
time.sleep(2)
old = time.time()
while True:
# print('全局变量', record_time)
time.sleep(1)
print('xhr数量:', getxhrcount())
print('xhr时间:', getxhrtime())
print('http数量:', gethttpcount())
print('http时间:', gethttptime())
if time.time() - old > 1000:
proxy_sig = 'stop'
time.sleep(2)
# thread.stop()
print('关闭线程')
break
测试用例重跑
为什么需要测试用例重跑?在什么情况下测试用例需要重跑?这一切都与脚本的稳定性有关,脚本的稳定性不仅仅跟脚本自身相关,也会受到运行环境的影响,并且如果前端质量不高,出现一些莫名其妙的问题,而且你无法复现(你都没法复现,别人是不可能承认是 bug),这些情况相互作用在一起,出现的情况就是,每一次脚本出错的位置都不一样,搞的头都是大的,于是就想出了这个方法,只要脚本中出现了异常,就对测试用例进行重跑。
接下来说说重跑的粒度,我认为有三个粒度,从小到大是测试方法,测试类,整个测试流程,我的框架目前测试类重跑还没有实现,如果实现了这些重跑,脚本出现异常之后,会首先进行当前运行的测试方法进行重跑,如果在重跑的这些次数中没有一次通过,测试类再进行重跑,还是一次没通过,再整个流程进行重跑,如果是运行环境导致的问题,一般在这么多重跑后是能通过的,但是测试报告就需要好好考虑怎么写的,我的做法是,测试报告中只体现最后一次重跑的结果,但是保留重跑之前出错的页面截图,重跑出错的信息打印在日志中。
2019/06/13 更新,上面这段话有问题,有意义的重跑只有测试方法重跑和测试套件重跑,这两天本来是想实现类重跑,在做的过程中发现了之前的思路有问题,之前想实现类重跑是因为,有些测试方法使用了setUpClass()/tearDownClass() 如果仅仅进行方法重跑,页面接不上,重跑就会出错,正确的做法是,在 TestCase 需要重跑的时候,根据其使用的初始化方法来判断怎么进行重跑,setUpClass()/tearDownClass() 与 setUp()/tearDown() 的处理方式不一样,同时也要求,不能同时使用这两种初始化方法。
setUp()/tearDown() 的处理方式:只要测试方法出错了,清理掉运行的信息,然后重新运行测试方法
setUpClass()/tearDownClass() 的处理方式:这个就麻烦一些,因为使用这种初始化的方法可能操作页面是接着之前运行的测试方法,想要对这个测试方法进行重跑,就需要重跑所有前面已经运行了的测试方法,下面的 TestSuite 里的代码已经更新了,实现了我说的这种方式
这些重跑是怎么实现的?整个流程重跑实现起来比较简单,只需要对这次运行的最后的结果进行判断,里面只要有出错的信息,对整个流程重跑即可;测试方法重跑,我是修改了 unittest 的源码实现的,主要的思路还是控制 result (受这篇文章启发),需要注意的是,这里的 result 是 htmlreport 中修改过的 result,我又在里面添加了测试用例跳过的一些东西。
_TestResult 类
TestResult = unittest.TestResult
class _TestResult(TestResult):
# note: _TestResult is a pure representation of results.
# It lacks the output and reporting ability compares to unittest._TextTestResult.
def __init__(self, verbosity=1, skipped_count=0):
super().__init__()
self.stdout0 = None
self.stderr0 = None
self.success_count = 0
# 添加跳过统计
self.skipped_count = skipped_count
self.failure_count = 0
self.error_count = 0
self.verbosity = verbosity
self.result = []
self.subtestlist = []
def startTest(self, test):
TestResult.startTest(self, test)
# just one buffer for both stdout and stderr
self.outputBuffer = io.StringIO()
stdout_redirector.fp = self.outputBuffer
stderr_redirector.fp = self.outputBuffer
self.stdout0 = sys.stdout
self.stderr0 = sys.stderr
sys.stdout = stdout_redirector
sys.stderr = stderr_redirector
def complete_output(self):
"""
Disconnect output redirection and return buffer.
Safe to call multiple times.
"""
if self.stdout0:
sys.stdout = self.stdout0
sys.stderr = self.stderr0
self.stdout0 = None
self.stderr0 = None
return self.outputBuffer.getvalue()
def stopTest(self, test):
# Usually one of addSuccess, addError or addFailure would have been called.
# But there are some path in unittest that would bypass this.
# We must disconnect stdout in stopTest(), which is guaranteed to be called.
self.complete_output()
def addSuccess(self, test):
if test not in self.subtestlist:
self.success_count += 1
TestResult.addSuccess(self, test)
output = self.complete_output()
self.result.append((0, test, output, ''))
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
# 新增加跳过的计数函数
def addSkip(self, test, reason):
self.skipped_count += 1
TestResult.addSkip(self, test, reason)
output = self.complete_output()
self.result.append((3, test, '', reason))
if self.verbosity > 1:
sys.stderr.write('skip ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('S')
def addError(self, test, err):
self.error_count += 1
TestResult.addError(self, test, err)
_, _exc_str = self.errors[-1]
output = self.complete_output()
self.result.append((2, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('E ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('E')
def addFailure(self, test, err):
self.failure_count += 1
TestResult.addFailure(self, test, err)
_, _exc_str = self.failures[-1]
output = self.complete_output()
self.result.append((1, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
def addSubTest(self, test, subtest, err):
if err is not None:
if getattr(self, 'failfast', False):
self.stop()
if issubclass(err[0], test.failureException):
self.failure_count += 1
errors = self.failures
errors.append((subtest, self._exc_info_to_string(err, subtest)))
output = self.complete_output()
self.result.append((1, test, output + '\nSubTestCase Failed:\n' + str(subtest),
self._exc_info_to_string(err, subtest)))
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(subtest))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
else:
self.error_count += 1
errors = self.errors
errors.append((subtest, self._exc_info_to_string(err, subtest)))
output = self.complete_output()
self.result.append(
(2, test, output + '\nSubTestCase Error:\n' + str(subtest), self._exc_info_to_string(err, subtest)))
if self.verbosity > 1:
sys.stderr.write('E ')
sys.stderr.write(str(subtest))
sys.stderr.write('\n')
else:
sys.stderr.write('E')
self._mirrorOutput = True
else:
self.subtestlist.append(subtest)
self.subtestlist.append(test)
self.success_count += 1
output = self.complete_output()
self.result.append((0, test, output + '\nSubTestCase Pass:\n' + str(subtest), ''))
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(subtest))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
unittest.suite.TestSuite.run()
def run(self, result, class_backroll=0, logger=None, debug=False):
'''
测试套件的运行方法
:param result: 运行结果对象
:param class_backroll: 测试方法重跑次数
:param logger: 日志对象
:return: 运行结果
'''
topLevel = False
# 获取的 result 的 属性 _testRunEntered 的值,默认返回的是false
if getattr(result, '_testRunEntered', False) is False:
result._testRunEntered = topLevel = True
setupclass_sig = 0
testlist = []
teardown = True
# 将内层嵌套的 testsuite 利用迭代器取出来
for index, test in enumerate(self):
if result.shouldStop:
break
# 利用对象是否还能迭代来判断是 TestSuite 还是 TestCase
if _isnotsuite(test):
# 这个记录的就是当前方法的重跑次数
count = 0
# 保存完成的任务队列
if not index:
testlist = copy.deepcopy(self._tests)
index_copy = 0
while True:
if not result.skipped_count:
self._tearDownPreviousClass(test, result)
self._handleModuleFixture(test, result)
# 执行初始化函数,一个类里面的执行过一次之后,就不会再次的执行,会将执行过的类的名称保存到result里面去
setupclass_cres = self._handleClassSetUp(test, result)
# 因为类方法只会被运行一次,
if setupclass_cres == 'NotClassConFunc':
# 进来了就说明在用例中未使用
setupclass_sig += 1
if Config.keepwindows() == 'True':
try:
getattr(test.__class__, 'savedriver')()
except:
pass
result._previousTestClass = test.__class__
if (getattr(test.__class__, '_classSetupFailed', False) or
getattr(result, '_moduleSetUpFailed', False)):
continue
if not debug:
# 关键点,最后这里的参数会传递到测试方法
test(result, logger=logger)
else:
test.debug()
if result.error_count and class_backroll and count == class_backroll:
result.skipped_count += 1
if not result.error_count or count == class_backroll or result.skipped_count:
if setupclass_sig:
if self._cleanup:
self._removeTestAtIndex(index)
if (count == class_backroll or result.skipped_count) and Config.keepwindows() == 'True':
teardown = False
break
else:
if index == index_copy - 1 or not index_copy:
if self._cleanup:
self._removeTestAtIndex(index)
if (count == class_backroll or result.skipped_count) and Config.keepwindows() == 'True':
teardown = False
break
else:
test = testlist[index_copy]
index_copy += 1
else:
# 单纯的测试方法重跑
if setupclass_sig:
# 这里对运行标志进行了重置,目的是,让类的初始化方法进行重跑
result._previousTestClass = None
if logger:
error_information_list = []
for error_func, error_inf in result.errors:
param = error_func.param
if param:
param = json.dumps(param, ensure_ascii=False)
error_information = error_inf + '---测试用例:' + error_func._testMethodName + '\n' + '---测试用例参数:' + param
else:
error_information = error_inf + '---测试用例:' + error_func._testMethodName + '\n' + '---测试用例参数:None'
error_information_list.append(error_information)
print_error = '\n'.join(error_information_list)
logger.warning('测试用例失败信息:{}'.format(print_error))
# 对运行标志进行重置
result.error_count -= 1
del result.errors[-1]
del result.result[-1]
result.testsRun -= 1
count += 1
else:
if not index_copy:
for i in range(index + 1):
del result.result[-1]
for i in range(index):
result.testsRun -= 1
result.success_count -= 1
else:
for i in range(index_copy):
del result.result[-1]
for i in range(index_copy - 1):
result.testsRun -= 1
result.success_count -= 1
index_copy = 0
result._previousTestClass = None
test = testlist[index_copy]
if logger:
error_information_list = []
for error_func, error_inf in result.errors:
param = error_func.param
if param:
param = json.dumps(param, ensure_ascii=False)
error_information = error_inf + '---测试用例:' + error_func._testMethodName + '\n' + '---测试用例参数:' + param
else:
error_information = error_inf + '---测试用例:' + error_func._testMethodName + '\n' + '---测试用例参数:None'
error_information_list.append(error_information)
print_error = '\n'.join(error_information_list)
logger.warning('测试用例失败信息:{}'.format(print_error))
# 对运行标志进行重置
result.error_count -= 1
del result.errors[-1]
count += 1
index_copy += 1
else:
if not debug:
test(result, class_backroll, logger=logger)
else:
test.debug()
if self._cleanup:
self._removeTestAtIndex(index)
if topLevel and teardown:
self._tearDownPreviousClass(None, result)
self._handleModuleTearDown(result)
result._testRunEntered = False
return result
unittest.case.TestCase.run()
def run(self, result=None,class_backroll = 0,logger = None):
'''
测试方法的运行函数
:param result: 运行结果对象
:param class_backroll: 重跑次数
:param logger: 日志对象
:return: 运行结果
'''
orig_result = result
if result is None:
result = self.defaultTestResult()
startTestRun = getattr(result, 'startTestRun', None)
if startTestRun is not None:
startTestRun()
# 自己添加一个方便后面判断的标志
self._resultForDoCleanups = result
# 添加运行次数的统计,并且设置输出流
result.startTest(self)
# 获取case方法的函数对象
testMethod = getattr(self, self._testMethodName)
if (getattr(self.__class__, "__unittest_skip__", False) or
getattr(testMethod, "__unittest_skip__", False)):
# If the class or method was skipped.
try:
skip_why = (getattr(self.__class__, '__unittest_skip_why__', '')
or getattr(testMethod, '__unittest_skip_why__', ''))
self._addSkip(result, self, skip_why)
finally:
result.stopTest(self)
return
try:
# 直接影响到这里,让后面的测试用例都直接跳过。
if result.skipped_count or result.error_count:
try:
try:
skip_why = 'Skiped because {}--{} wrong!'.format(result.errors[0][0].__class__,result.errors[0][0]._testMethodName)
except IndexError:
skip_why = '由于依赖测试用例执行错误,跳过执行!'
self._addSkip(result, self, skip_why)
finally:
result.stopTest(self)
return
except:
pass
expecting_failure_method = getattr(testMethod,
"__unittest_expecting_failure__", False)
expecting_failure_class = getattr(self,
"__unittest_expecting_failure__", False)
expecting_failure = expecting_failure_class or expecting_failure_method
outcome = _Outcome(result)
try:
self._outcome = outcome
testcase = self
self.setUp()
if outcome.success:
outcome.expecting_failure = expecting_failure
# 保留上下文管理器
with outcome.testPartExecutor(self, isTest=True):
testMethod()
outcome.expecting_failure = False
try:
# 与保留出错页面有关
self.savedriver()
except:
pass
self.doCleanups()
# 这里是添加结果标志的位置,分别是跳过,报错,失败,成功
for test, reason in outcome.skipped:
self._addSkip(result, test, reason)
self.tearDown()
self._feedErrorsToResult(result, outcome.errors)
if outcome.success:
if expecting_failure:
if outcome.expectedFailure:
self._addExpectedFailure(result, outcome.expectedFailure)
else:
self._addUnexpectedSuccess(result)
else:
result.addSuccess(self)
self.tearDown()
return result
finally:
result.stopTest(self)
if orig_result is None:
stopTestRun = getattr(result, 'stopTestRun', None)
if stopTestRun is not None:
stopTestRun()
# explicitly break reference cycles:
# outcome.errors -> frame -> outcome -> outcome.errors
# outcome.expectedFailure -> frame -> outcome -> outcome.expectedFailure
outcome.errors.clear()
outcome.expectedFailure = None
# clear the outcome, no more needed
self._outcome = None
保留出错的页面
在脚本运行的过程中,如果出现了异常,程序停止了,但是有时候浏览器关闭,但是有时候浏览器又不关闭,不知道你们有没有注意到。
但是有时候又想看看出错的页面,分析一下出错的原因,所以就出现了这个需求,保留所有出错的浏览器页面,重跑的也需要保留,并且可以通过配置文件来控制浏览器出错页面是否关闭。
首先我们来看个例子
import unittest
from selenium import webdriver
# 这个测试类运行之后浏览器会关闭
class foo(unittest.TestCase):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.driver.get('https://cn.bing.com/?scope=web&FORM=QBRE')
def test_01(self):
print('fff')
# 这个测试类运行完毕之后,浏览器不会关闭
class foo_2(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
cls.driver = webdriver.Chrome()
cls.driver.get('https://cn.bing.com/?scope=web&FORM=QBRE')
def test_01(self):
print('fff')
if __name__ == '__main__':
unittest.main()
浏览器的关闭与 python 自己的垃圾回收机制有关,上面的第一个例子在程序运行完毕之后,self.driver 变量被回收,因为 self.driver 变量是属于 self 这个示例的,实例被回收之后,实例的所有变量都会被回收,而 cls.driver 变量属于 foo_2 这个类(其实这里面是怎么在运行我也不清楚,反正浏览器对象使用类变量引用之后,在程序结束之后不会被关闭),其实里面有一个问题,你之前不是用测试用例重跑吗?每次这个类的变量都会指向一个新的浏览器对象,你是怎么将所有重跑出错的页面保存下来的?下面给出代码,其实就是每次这个测试方法运行失败之后,用另外一个类变量引用浏览器对象即可。
class TestCaseMore(ParametrizedTestCase):
# 为了保存窗口,将setUp方法变为了非绑定方法
@classmethod
def setUp(cls):
pass
@classmethod
def tearDown(cls):
pass
@classmethod
def savedriver(cls):
if Config.keepwindows() == 'True':
# 关键点,动态生成一个唯的类变量来引用浏览器对象
exec('cls.driver{} = cls.driver'.format(int(round(time.time() * 1000))))
关于 Pycharm 插件开发
顺便说一下 Pycharm 的插件开发吧,为了做这个插件,看了两天 java,其实最关键的是 intellij 插件开发的资料不多,而且大部分都是英文的,我这里分享一点国内的资料(看这里,还有这个(这个写的真不错,可以好好看看))
为什么要开发一个 Pycharm 插件?效果上面的图片中有展示,基本上可以和 sikuli IDE 媲美,当然别人的 IDE 中还有图片匹配功能,我觉得这个功能没那么重要,就懒得做了,最最重要的功能点是不用自己直接去操作图片,编写脚本的人不用关心图片存放在哪里,不用关心图片的名称等等,还有就是,写代码里面夹在图片看起来难道不是十分的别扭?图片用其他的窗口预览出来即可。
关于自动化的疑问
为毛我觉得公司的自动化工作一直开展不起来,自动化真的有用?我怎么觉得公司的任何事都与我无关,我怎么感觉我一直在瞎折腾?你们做这份工作对公司真的有价值?是我的搞法不对?
想做的事
目前想做的还有一件事,就是自动化测试管理平台,想要达到的目的:1.实现测试环境自动化部署(这部分可以与 Jenkins 集成起来用),测试环境管理;2.实现自动运行的自动化测试用例监控与控制;3.调度自动化测试任务,控制分布式测试机器;4.集成性能测试。
自动化测试框架与 Jenkins 集成使用之前已经做过了,但是无法控制运行的自动化测试用例,之前写了一个简单的 python 脚本,放在 Jenkins 服务器上,自动构建完成之后使用 Jenkins 提供的插件远程部署,部署完成之后调用 python 脚本,脚本里面使用了 ssh 的相关模块,远程调用测试机,运行相关的自动化测试用例,然后框架集成了邮件模块,可以在运行完毕之后自动发送测试报告。
但是上面的做法太简陋了,中间要是出点什么问题就没办法了,现在的想法是使用 flask 这类 web 框架,然后集成 Ansible 模块,再根据需求写点功能,实现一个 wbe 页面的管理平台。