废话不多说,直接来!
由于时间问题我也只是创建了一个 10W 长度的数组,但是效果应该可以被显而易见。
第一种:
in 关键字,其实 Python 是很推荐大家使用 in 关键字来检索包含这种关系的,在字符串中,list 中检索都很方便,但是如果用来去重,效率就很捉急了。


10W 数据用了一分钟,我要炸了。。。
其实还有很多种类似的手段,都是去直接操作 list 去重,这里就不一一例举了。
第二种:
itertools 分组的方式

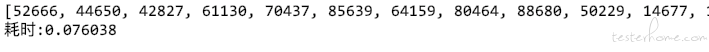
这效率,谁说 Python 效率差来着
第三种:
其实还有一种是通过 set 的方式

效率也是非常非常高的,但是我展示以下方式是想表达
在实际编程中应该尽量少的操作 list,而去操作 dict 或者 set 这种数据结构,在效率上是质的改变

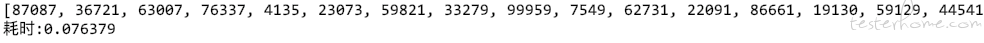
这种通过 dict 属性报错的特性能够很高效率的索引出来,这种方式在 JS 中也是适用的,只是 js 是以 undefined 的结果表达而不是 KeyError 的报错。
真的非常青睐 dict 这种数据结构了。
----------------------更新一波
修改了一下,更新了第三种的实现


速度竟然比 set 快,且不打乱原有顺序,看来之前还是想太多。。。