通用技术 数据分析 R 语言之基础图形绘制入门
答应小 A 的文章, 拖了很久. 所以今天赶紧补上了.
R 简介
首先自己去官网下载 R 和 R-Studio, R 语言是什么, 我就不科普了. 粗浅的理解就是科学计算 + 绘图工具
R-Studio 是个简单的 IDE. 可用于基础的调试学习.
RScript 可以执行 R 脚本. 支持参数传递. 自己写的脚本有时候需要放到 jenkins 去跑, 就需要这个工具.
R 可以直接进入交互命令行. 一般在 linux 下调试用.
语法基本还是老式的 C 风格. R 继承自 S 语言.
读取数据
R 语言可以读取大部分的数据格式, 比如数据库, 文件 hadoop 的 HDFS 等.还包括其他的数据分析工具, 比如 IBM 的 SPSS 等等.
R 的读取输入的功能基本都在于 read.* 系列的函数. 最常用的是 read.csv 和 read.table. 因为其他格式数据基本都可以转换到这两个格式上.
我以 Testin 网站上公布的他们拥有的所有机型列表数据作为分析演示的数据.

首先读取数据
devices=read.csv("testin_devices.csv")
此时 devices 就是一个变量, 他表示一个行列数据, 类似于数据库中的数据表的概念.
他的 devices$ 品牌 表示品牌这一列的数据
R 语言的运算基于行列运算, 比如 devices$count=1 表示把所有的 count 那一列的数据全部变成 1.
正是这种计算方式导致了 R 的代码中很少看到 for 循环和 if 判断
基础绘图
可以直接使用 plot 绘图
plot(devices$品牌)
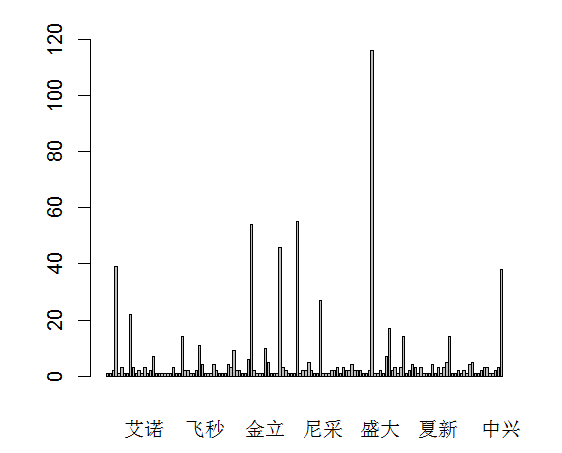
数据太多,看不到细节的数据. 把结果输出到一个很大的 png 图形中
png("4.png", width=12000, height=1200)
plot(devices$品牌)
dev.off()
这样的结果看起来也很费劲. 所以我们继续优化.
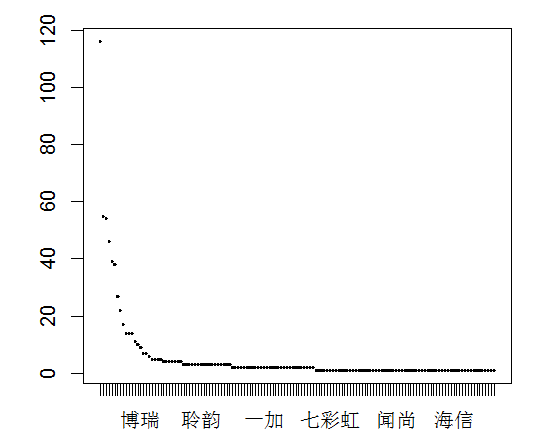
按照从大到小的顺序进行排列岂不是更好.
之前使用 plot 函数的时候, 会自动统计各个品牌的分布情况. 现在是我们要自己去排序
所以需要自己先计算每个品牌的总设备类型数
devices2=aggregate(count~品牌, devices, sum)
#然后根据count的结果, 进行反向的排序. 也就是高的在前, 低的在后
devices2 = transform(devices2, 品牌=reorder(品牌, -count))
#重新绘图
plot(devices2$品牌, devices2$count)
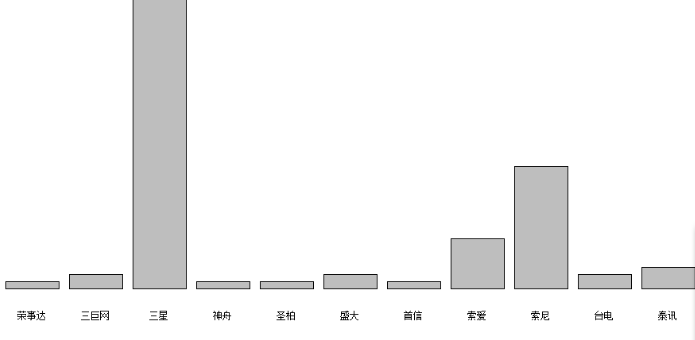
只看前二十名
devices4=devices3[rev(order(devices3$count))[1:20],]
plot(devices4$品牌, devices4$count)
这个时候会发现默认的 plot lines 很不人性化, 不够智能.
更好的 ggplot 绘图体系
这几年新的 ggplot2 库逐渐普及, 他可以更简单更友好的绘制图形.
所以我现在基本都使用 ggplot2 了
ggplot2 有自己的绘图理念, 他认为所有的绘图函数都应该可以通过 + 连接起来.
类似于函数式编程或者 bash 的管道概念.
#创建数据
g=ggplot(data=devices4, aes(品牌, count))
g+geom_bar(stat="identity")
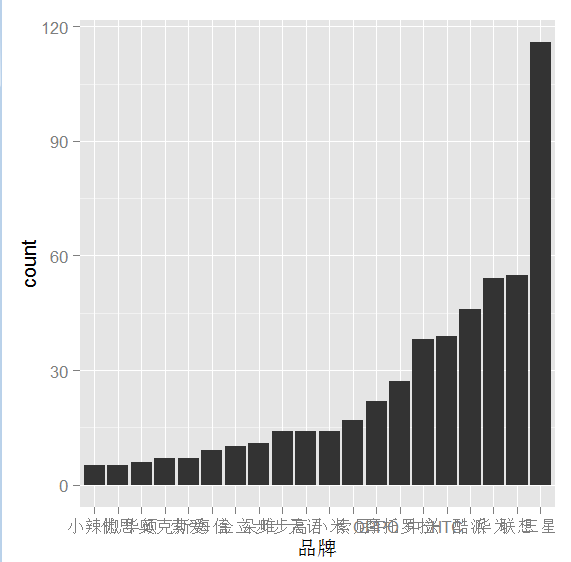
切换下坐标方式, 实现更好的显示所有的品牌名字
g+geom_bar(stat="identity")+coord_flip()
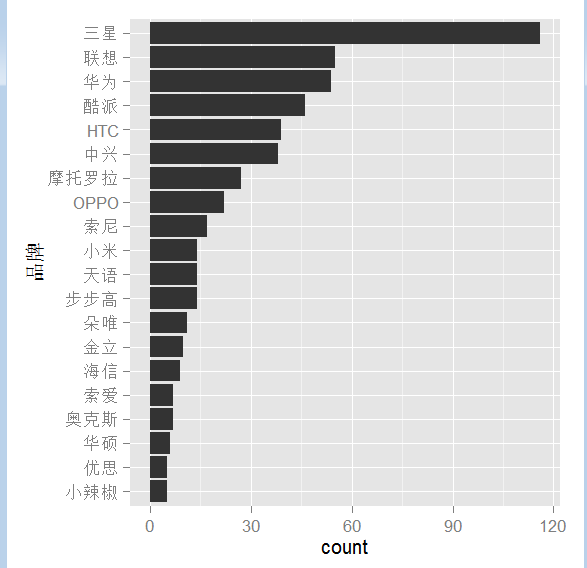
调整下颜色
g+geom_bar(stat="identity", color="blue", fill="white")+coord_flip()

# 标记数字
g+geom_bar(stat="identity", color="blue", fill="white")+coord_flip()+geom_text(label=devices4$count, size=3, hjust=1.2)

参考资料
R 语言与网站分析
R 数据可视化手册
R 语言实战
待续
- 网络图的画法
- 机器学习算法在测试中的应用