背景:
项目需要对一批接口进行压测,要求是接口的QPS(Quest Per Second 每秒请求数) 达到 6 万以上
由于楼主一直使用的压力测试工具是 jmeter,但是 jmeter 单台电脑无法达到 6 万的 QPS,于是使用网传比较好用的其他性能工具进行压测比较,选出一款符合要求的工具进行压测。
压测机器:Linux 4 核 8G
由于不同的性能工具压测时消耗的系统资源不一样,防止系统资源造成的干扰,测试时服务器只运行压测工具,且非本机压本机。
示例接口,post 请求,请求 body 可为空
POST https://api.midukanshu.com/logstash/userbehavior/report
返回:
{"code":0,"message":"成功","currentTime":1543386393,"data":[]}
一、 Wrk
wrk 是一款现代化的 HTTP 性能测试工具,即使运行在单核 CPU 上也能产生显著的压力。最大的优点是它支持多线程,这样更容易发挥多核 CPU 的能力,从而更容易测试出系统的极限能力。
安装
git clone https://github.com/wg/wrk.git
cd wrk/
make
查看版本
./wrk -v
参数说明
-c:总的连接数(每个线程处理的连接数=总连接数/线程数)
-d:测试的持续时间,如2s(2second),2m(2minute),2h(hour),默认为s
-t:需要执行的线程总数,默认为2,一般线程数不宜过多. 核数的2到4倍足够了. 多了反而因为线程切换过多造成效率降低
-s:执行Lua脚本,这里写lua脚本的路径和名称,后面会给出案例
-H:需要添加的头信息,注意header的语法,举例,-H “token: abcdef”
—timeout:超时的时间
—latency:显示延迟统计信息
返回结果
Latency:响应时间
Req/Sec:每个线程每秒钟的执行的连接数
Avg:平均
Max:最大
Stdev:标准差
+/- Stdev: 正负一个标准差占比
Requests/sec:每秒请求数(也就是QPS),等于总请求数/测试总耗时
Latency Distribution,如果命名中添加了—latency就会出现相关信息
运行
./wrk -t 5 -c 300 -d 60 --latency https://api.midukanshu.com/logstash/userbehavior/create
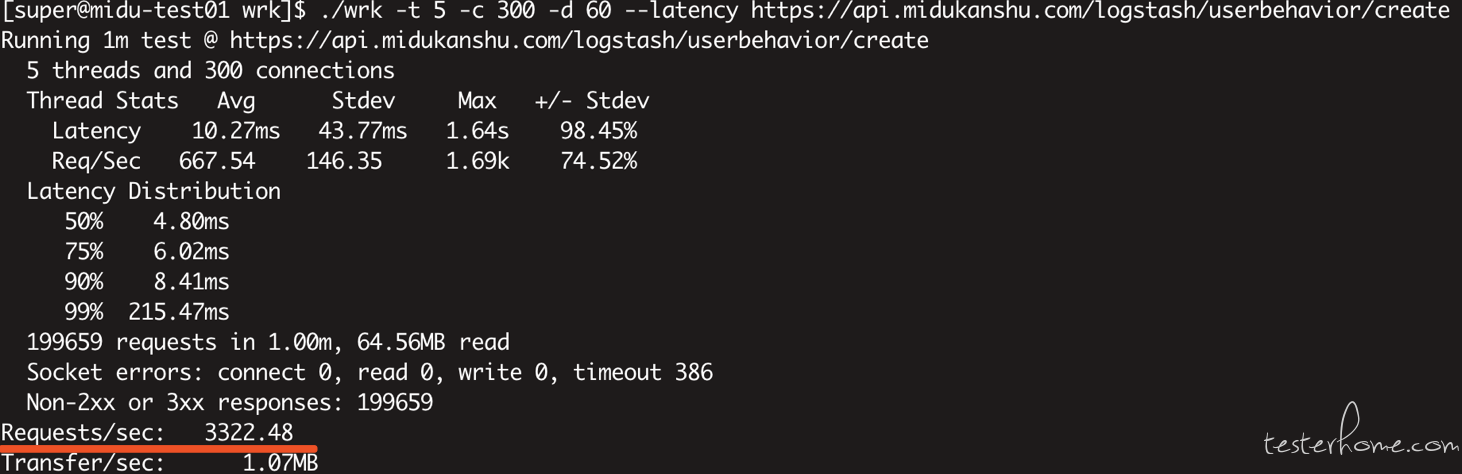
300 个连接数跑 60 秒:Request/sec(每秒请求数):3322.48
./wrk -t 5 -c 500 -d 60 --latency https://api.midukanshu.com/logstash/userbehavior/create
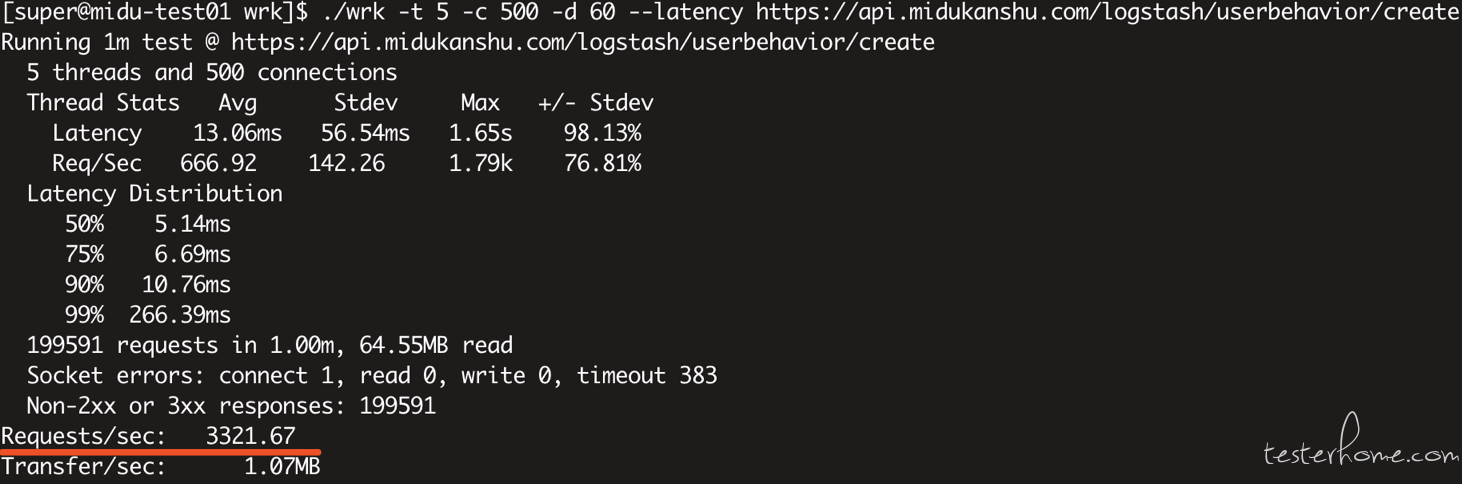
500 个连接数跑 60 秒:Request/sec(每秒请求数):3321.67
可见连接数从 300 加到 500,QPS 没有明显变化,就没有再往上加的必要了,再加也只会花更多的时间去坐线程的切换,QPS 不一定上升,而且 300 个连接数时 CPU 已经跑满,后面会有截图说明
如果 post 请求的 body 不为空则指定 lua 文件进行读取,示例如下:
./wrk -t 5 -c 300 -d 60 --script=post.lua --latency https://api.midukanshu.com/logstash/userbehavior/create
post.lua 文件内容
wrk.method = "POST"
wrk.body = ""
wrk.headers["Content-Type"] = "application/x-www-form-urlencoded"
二、 Apache Benchmark
Apache Benchmark 简称 ab,是 apache 自带的压力测试工具
安装:
sudo yum install httpd-tools
查看版本:
ab -V

参数说明
-n 表示请求总数(与-t参数可任选其一)
-c 表示并发数
-t 标识请求时间
-p:模拟post请求,文件格式为gid=2&status=1,配合-T使用
-T:post数据所使用的Content-Type头信息,如-T 'application/x-www-form-urlencoded'
返回结果
Server Software: nginx/1.13.6 #测试服务器的名字
Server Hostname: api.midukanshu.com #请求的URL主机名
Server Port: 443 #web服务器监听的端口
Document Path: /logstash/userbehavior/create #请求的URL中的根绝对路径
Document Length: 0 bytes #HTTP响应数据的正文长度
Concurrency Level: 300 # 并发用户数,这是我们设置的参数之一
Time taken for tests: 22.895 seconds #所有这些请求被处理完成所花费的总时间
Complete requests: 50000 # 总请求数量,这是我们设置的参数之一
Failed requests: 99 # 表示失败的请求数量,这里的失败是指请求在连接服务器、发送数据等环节发生异常,以及无响应后超时的情况
Write errors: 0
Total transferred: 96200 bytes #所有请求的响应数据长度总和。包括每个HTTP响应数据的头信息和正文数据的长度
HTML transferred: 79900 bytes # 所有请求的响应数据中正文数据的总和,也就是减去了Total transferred中HTTP响应数据中的头信息的长度
Requests per second: 2183.91 [#/sec] (mean) #吞吐率,计算公式:Complete requests/Time taken for tests 总请求数/处理完成这些请求数所花费的时间
Time per request: 137.368 [ms] (mean) # 用户平均请求等待时间,计算公式:Time token for tests/(Complete requests/Concurrency Level)。处理完成所有请求数所花费的时间/(总请求数/并发用户数)
Time per request: 0.458 [ms] (mean, across all concurrent requests) #服务器平均请求等待时间,计算公式:Time taken for tests/Complete requests,正好是吞吐率的倒数。也可以这么统计:Time per request/Concurrency Level
Transfer rate: 652.50 [Kbytes/sec] received #表示这些请求在单位时间内从服务器获取的数据长度,计算公式:Total trnasferred/ Time taken for tests,这个统计很好的说明服务器的处理能力达到极限时,其出口宽带的需求量。
运行
ab -c 300 -t 60 https://api.midukanshu.com/logstash/userbehavior/create
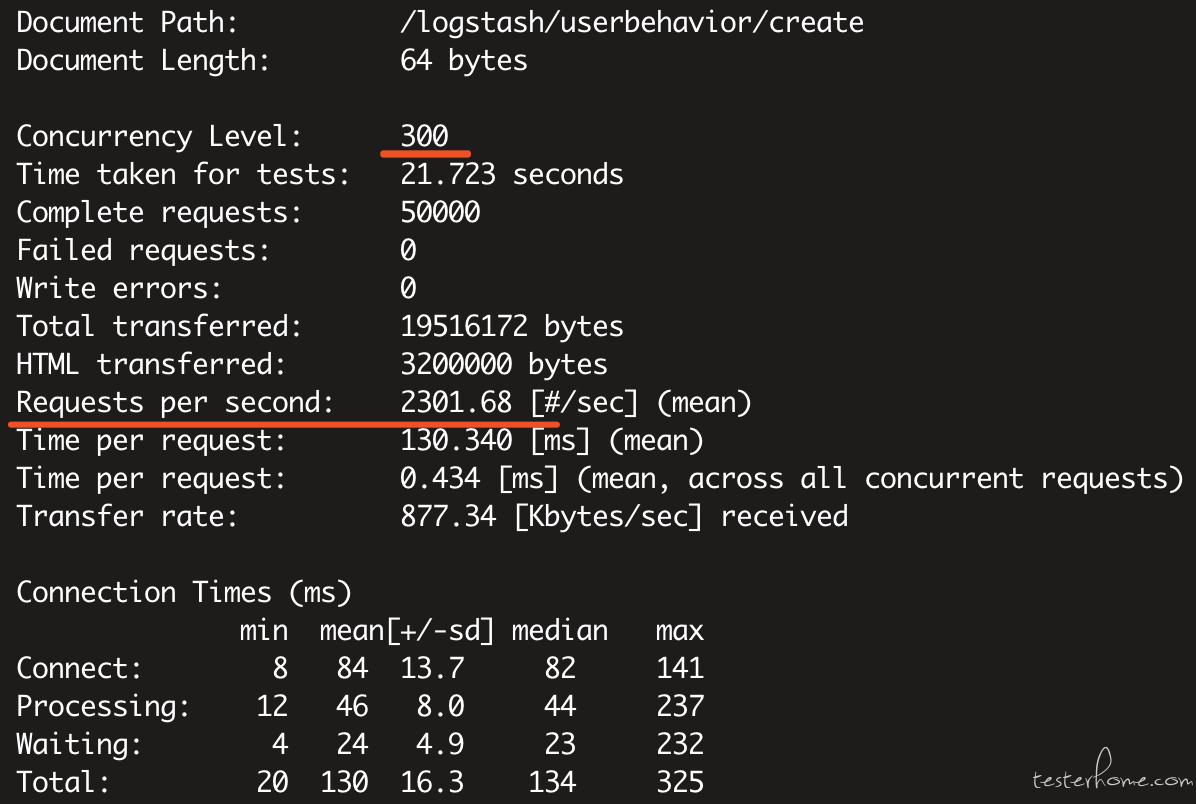
300 线程跑 60 秒:Requests per second=2301.68
ab -c 500 -t 60 https://api.midukanshu.com/logstash/userbehavior/create
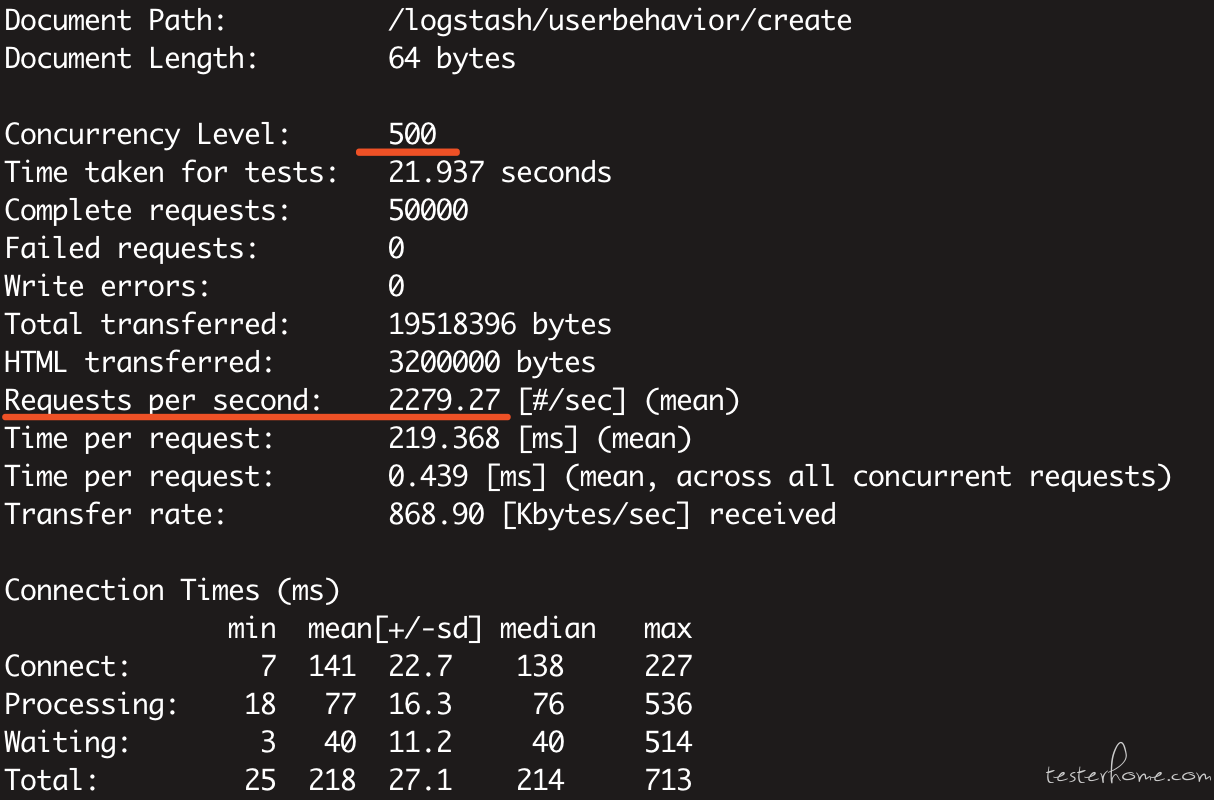
500 线程跑 60 秒:Requests per second=2279.27
可见线程数加到 500,还不如 300 的了,所以有时候线程数不是加的越高越好,更根据服务器的配置,CPU,IO,带宽等的消耗设置合理的线程数
细心的读者可能看出,我虽然设置了-t 参数为 60s,但实际只运行了 20 多秒,因为 ab 跑满 50000 个 request 就自己停了,想跑够 60s 可以使用-n 参数
如果 post 请求的 body 不为空则指定文件进行读取,示例如下:
ab -n 100 -c 10 -p 'post.txt' -T 'application/x-www-form-urlencoded' 'http://test.api.com/ttk/auth/info/'
post.txt 文件内容
devices=4&status=1
三、 Locust
Locust 是一个 Python 编写的分布式的性能测试工具
安装
安装 python pip
sudo yum -y install python-pip
通过 Python 自带的 pip 安装 locust
pip install locustio
查看版本:
locust –version

参数说明
--host指定被测试的主机,采用以格式:http://192.168.21.25
-f指定运行 Locust 性能测试文件,默认为: locustfile.py
–-no-web no-web 模式运行测试,需要 -c 和 -r 配合使用
-c指定并发用户数,作用于 –no-web 模式。
-r指定每秒启动的用户数,作用于 –no-web 模式。
-t设置运行时间, 例如: (300s, 20m, 3h, 1h30m). 作用于 –no-web 模式。
返回结果
Name:请求方式,请求路径;
reqs:当前请求的数量;
fails:当前请求失败的数量;
Avg:所有请求的平均响应时间,毫秒;
Min:请求的最小的服务器响应时间,毫秒;
Max:请求的最大服务器响应时间,毫秒;
Median:中间值,单位毫秒;
req/s:每秒钟请求的个数。
Total:各接口的汇总信息
运行:
Locust_demo.py 文件内容
# coding=utf-8
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
@task(1)
def profile(self):
self.client.post("/logstash/userbehavior/report", {})
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 0
max_wait = 0
locust -f locust_demo.py --host=https://api.midukanshu.com --no-web -c 300 -t 60s
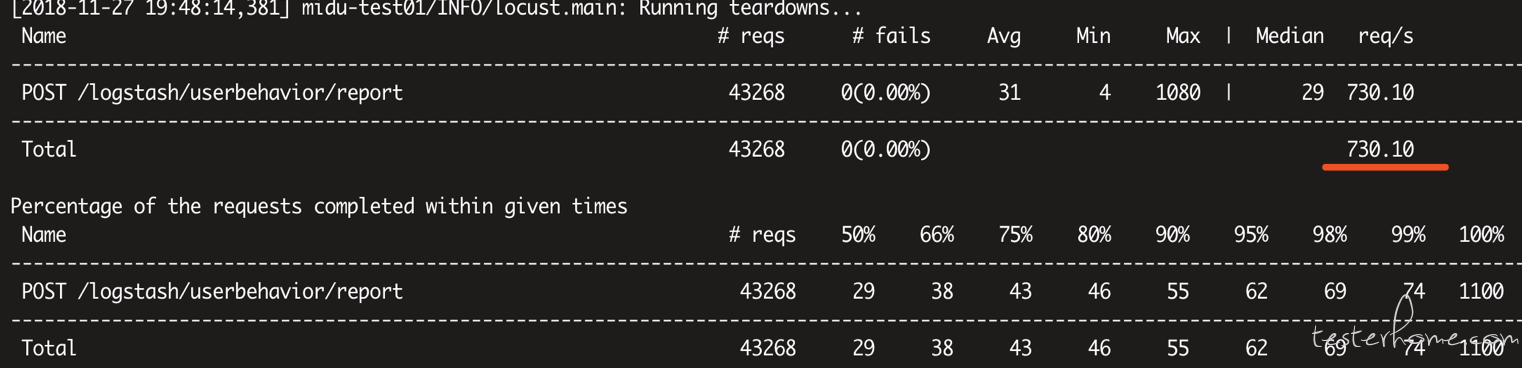
300 线程跑 60 秒:Req/s=730.10
locust -f locust_demo.py --host=https://api.midukanshu.com --no-web -c 500 -t 60s
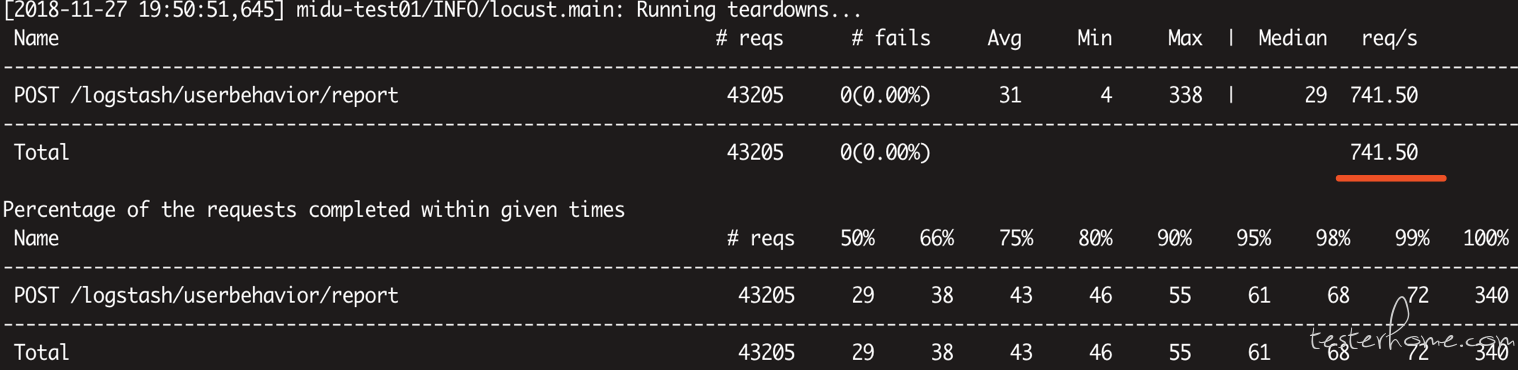
500 线程跑 60 秒:Req/s=741.50
四、 Jmeter
Apache JMeter 是 Apache 组织开发的基于 Java 的压力测试工具
安装
安装 jdk:yum -y list java
yum install -y java-1.8.0-openjdk-devel.x86_64
配置 Java 环境变量后执行 java -version

下载:apache-jmeter-3.2.tgz
然后解压到当前传的目录
tar zxvf apache-jmeter-3.2.tgz jmeter
查看版本:
见 jmeter 主目录
参数说明:
-n : 非GUI 模式执行JMeter
-t : 执行测试文件所在的位置及文件名
-r : 远程将所有agent启动,用在分布式测试场景下,不是分布式测试只是单点就不需要-r
-l : 指定生成测试结果的保存文件, jtl 文件格式
-e : 测试结束后,生成测试报告
-o : 指定测试报告的存放位置
返回结果:
Avg:所有请求的平均响应时间,毫秒;
Min:请求的最小的服务器响应时间,毫秒;
Max:请求的最大服务器响应时间,毫秒;
Err:请求错误个数,错误百分率;
Active:激活的线程数,当Active=0,则说明运行中的线程数为0,则压测结束。
Started:启动的线程数
Finished:完成的线程数
运行脚本:
./jmeter.sh -n -t ./jmx/userbehavior_report.jmx
300 个线程跑 60 秒:
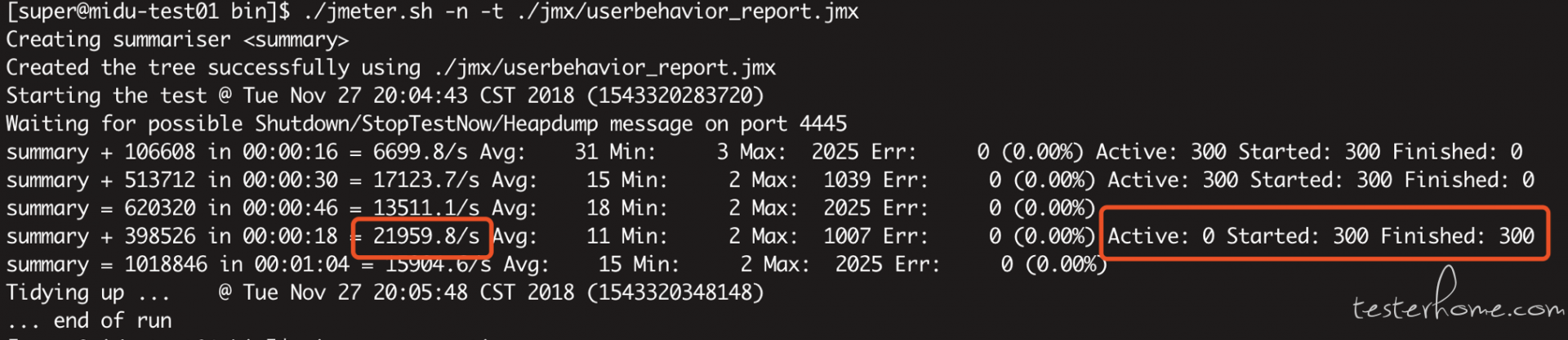
Summary + 398526 in 00:00:18 =21959.8/s
Summary = 1018846 in 00:01:04 =15904.6/s
Summary =表示总共运行 1 分 04 秒,请求了 1018846 个接口,这 1 分 04 秒内的 QPS=15904.6/s
Summary + 表示统计最近 18 秒,请求了 398526 个接口,即 00:00:46 到 00:01:04 期间的 18 秒,QPS=21959.8/s
500 个线程跑 60 秒:
到这差不多了,500 线程跑出来也没 300 的 QPS 高,就不放图了
总结:
300 线程跑 60 秒, 对比各压测工具的 QPS:
Wrk=3322.48/s
Ab=2301.68/s
Locust= 730.10/s
Jmeter=21959.8/s
我曾以为的压测结果是:wrk > ab > locust > jmeter
实际结果是:jmeter > wrk > ab > locust
五、资源消耗对比
Top 参数解释:
cpu状态
6.7% us — 用户空间占用CPU的百分比。
0.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
92.9% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
内存状态
8306544k total — 物理内存总量(8GB)
7775876k used — 使用中的内存总量(7.7GB)
530668k free — 空闲内存总量(530M)
79236k buffers — 缓存的内存量 (79M)
各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
在 top 基本视图中,按键盘数字 “1”,可监控每个逻辑 CPU 的状况:
可看出压测服务器有 4 个逻辑 CPU
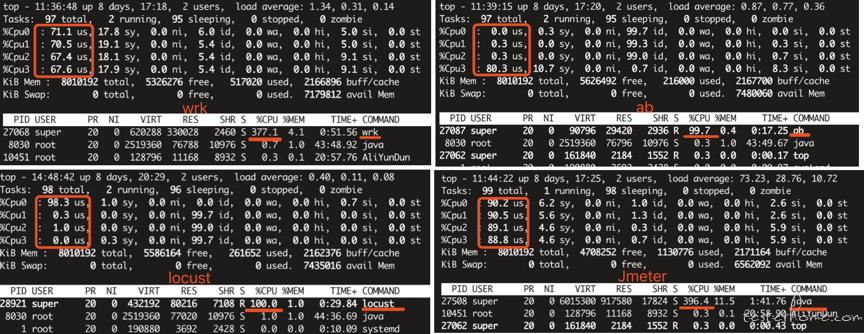
300 线程跑 60 秒 CPU 消耗如图:
Wrk=377.1%
Ab=99.7%
Locust= 100%
Jmeter=396.4%
如果服务器是多核 CPU 可能在下方看到有些进程 CPU 占用超过 100%,这种一般是该进程使用了多核。
可以看出 wrk 和 jmeter 都超过 100%,且 jmeter 的 396/4=99%,即使用了服务器 99% 的性能,
在压力测试过程中,最好时刻留意哪些资源成为了瓶颈,比如:CPU 是不是跑满了,IO 是不是跑满了
查看 0.0 wa 这里,IO 等待所占用的 CPU 时间的百分比,高过 30% 时 IO 压力高。
比较结果:
| 工具 | wrk | ab | locust | jmeter |
|---|---|---|---|---|
| 安装 | 简单 | 简单 | 依赖 python | 依赖 jdk |
| 场景压测 | 不支持 | 不支持 | 支持 | 支持 |
| UI 界面 | 无 | 无 | 有 | 有 |
| 脚本录制 | 无 | 无 | 无 | 利用本地 ProxyServer 或 badboy |
| 资源监控 | 无 | 无 | 无 | 通过 JMeterPlugins 插件和 ServerAgent 实现 |
| 报告分析 | 无 | 无 | 无 | 生成 HTML 报告 |
虽然 jmeter 提供 UI 界面,但是其压测脚本也依赖 UI 界面,导致其无法在 Linux 服务器上直接编辑写脚本,只有编写好脚本后再传到 Linux 服务器。
关于对于压测工具的选择
如果你想做场景的压测,而不是单个接口的压测
可使用 jmeter 或 locust,支持接口串联,接口 body 参数化,思考时间等复杂场景
如果你压测要求的并发比较高,需要使用分布式压测
可使用 jmeter 或 locust
如果你关注接口的返回,多维度压测报告统计
jmeter,jmeter,jmeter
如果想尽快编写接口,只关注接口的发送,造成的 QPS 和错误率
可使用 wrk 或 ab
实践中也可以选择自己熟悉的压测工具
由于单台 4 核 8G 服务器对待测接口最高能造成 2 万的 QPS,还是距离我需要的 6 万还有一定距离,这时候可以使用 Jmeter 的分布式压测
当然还有更多我还没了解到的优秀压测工具,压测结果存在一定局限,仅供参考
欢迎交流指正,感谢阅读。



 ,但是看 CPU 占用-rate=10000 的时候差不多 270%,报告出不来,最终的 QPS 不知道我就没继续压了,看得出性能还是可以的。
,但是看 CPU 占用-rate=10000 的时候差不多 270%,报告出不来,最终的 QPS 不知道我就没继续压了,看得出性能还是可以的。