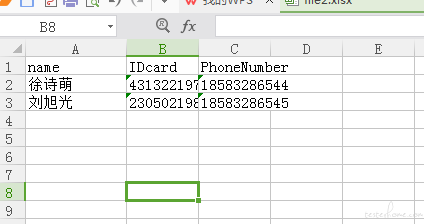
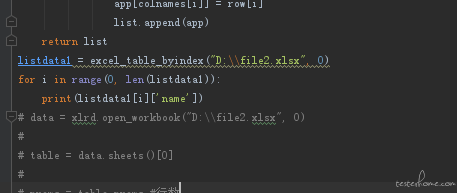
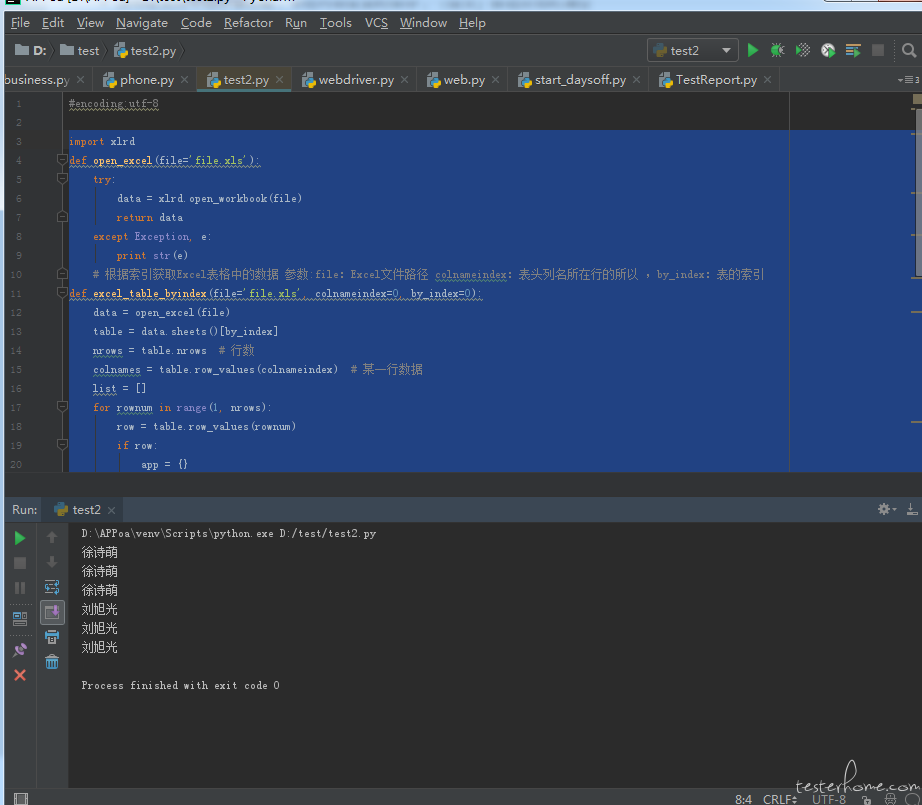
Appium APPIUM+python 用 excel 自动读取数据的总是重复读取好几行,有大佬来看看吗
import xlrd
def open_excel(file='file.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception, e:
print str(e)
# 根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_index:表的索引
def excel_table_byindex(file='file.xls', colnameindex=0, by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows # 行数
colnames = table.row_values(colnameindex) # 某一行数据
list = []
for rownum in range(1, nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
listdata1 = excel_table_byindex("D:\\file2.xlsx", 0)
for i in range(0, len(listdata1)):
print(listdata1[i]['name'])