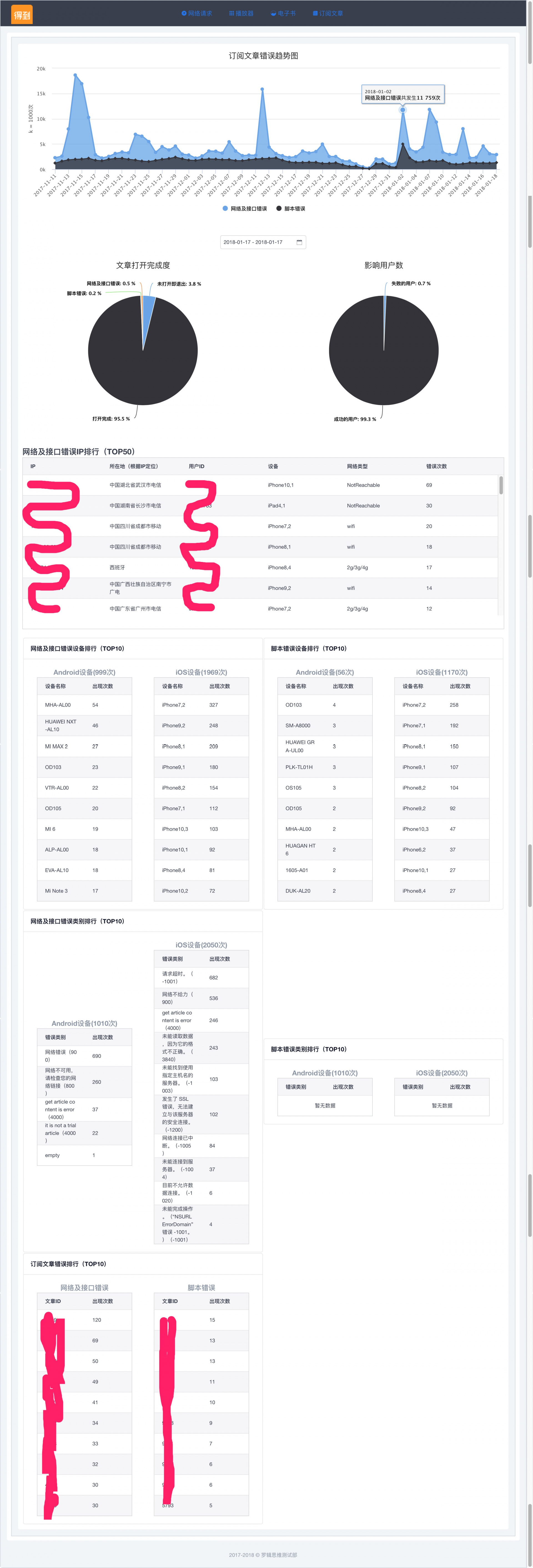
新手区 线上质量监控
背景
为了监控线上环境核心服务的错误率、影响用户量、错误原因并且可以拿到一些兼容性的数据。
如我们得到 App 的订阅文章,经常有用户反馈打不开。但因为涉及到三端,Android/iOS 去请求服务端获取数据,然后由 H5 渲染文章页。问题不容易定位。
目前刚开始做,规划中以后要统计所有网络请求、播放器、电子书、订阅文章等核心服务的线上监控,目前只做了订阅文章的,还是 demo 阶段。
数据来源:Android、iOS 和 H5 的用户埋点数据。
除了埋点中的一些核心字段,如设备、用户、网络、文章数据等,还增加了几个特殊字段。
1. 当step = -1时,此时因为网络差等原因,并没有等到接口回调,用户自行返回;
2. 当step = 0时,此时调用接口失败或者网络请求失败等原因,记录有server_code及server_msg信息;
3. 当step = 2时,此时页面已经正常打开,前端资源加载或者执行失败,记录有page_code及page_msg信息;
4. 当step = 3时,如果存在page_error字段存在,则说明在用户操作时,js有报错;若不存在,则表明无错误发生。
用到的一些技术:
埋点数据会上报到数据组的kafka集群,然后我这边单独部署的elk会去消费kafka,拿到订阅文章的埋点日志。
flask每天定时去elasticsearch读取前一天的数据,存储到mysql。
前端由Vue2 + highcharts做报表统计。
后端的代码不好脱敏,不会开放代码。前端 vue2 的部分会放出来,地址在最下面。
ELK
使用的版本:
elasticsearch-5.6.2
kibana-5.6.2-linux-x86_64
logstash-2.4.1
安装部署略过了,只说下如何配置
elasticsearch
服务的配置文件在 config/elasticsearch.yml,我只改了 network.host 字段,改成你要绑定的 ip,端口默认 9200。
性能优化更改 config/jvm.options
logstash
创建一个配置文件,比如就叫 kafka_maidian_log.conf,配置如下
input {
kafka {
zk_connect => "xxx,xxx,xxx,xxx/kafka" # kafka集群所有机器的ip + port
topic_id => "maidian_log" # kafka埋点日志的topic id
group_id => "logstash"
}
}
# 过滤器,统计错误的埋点日志名称以dev开头,如果不是则drop
filter {
if "dev" not in [ev] {
drop {}
}
date {
match => [ "timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output {
elasticsearch {
hosts => ["xxx:9200"] # elasticsearch的ip + port
index => "dedao_log-%{+YYYY.MM.dd}" # elasticsearch的索引名,按天
}
}
然后执行./bin/logstash -f kafka_dedao_log.conf 启动,现在筛选的埋点日志就已经开始往 elasticsearch 存储了。
kibana
配置文件在 config/kibana.yml,修改 elasticsearch.url 字段,改成http://elasticsearchip的 + port
Flask 后端
定时去读取 elasticsearch(一天一次),拿到想要的数据保存 mysql。
查询 elasticsearch 的部分核心代码
连接 elasticsearch
# !/usr/bin/env python
# coding=utf-8
from elasticsearch import Elasticsearch
_ES = Elasticsearch([{'host': 'elasticsearch的ip', 'port': 9200}])
查询 elasticsearch
def __init__(self):
self._today = (datetime.date.today() - datetime.timedelta(days=1)).strftime('%Y.%m.%d')
self.index = "dedao_log-" + self._today
def get_step(self, step):
"""
失败的次数
-1:用户退出
0:接口请求失败或网络失败
2:JS加载失败
:param step:
:return:
"""
_query_all = {
'size': 10000,
'query': {
'match': {
"step": step
}
}
}
result = _ES.search(index=self.index, body=_query_all, request_timeout=1200)
return result['hits']['total']
如果读取 elasticsearch 的 size 特别大,容易失败,所以我设置的最高 10000 条,如果超过了,则可以用 elasticsearch 的分页查询。
def get_subscription_fail_devices(self, step):
"""
拿到失败的设备和每个设备失败的次数
:return:
"""
_query_all = {
'size': 10000,
'query': {
'match': {
"step": step
}
}
}
# 搜索,并拿到scroll分页id
search_result = _ES.search(index=self.index, body=_query_all, scroll="1h", request_timeout=1200)
results = []
results.append(search_result['hits']['hits'])
# 如果search返回大于10000条,说明还有下一页,然后用scroll继续查询后几页的数据
if len(search_result['hits']['hits']) >= 10000:
scroll_result = _ES.scroll(scroll_id=search_result['_scroll_id'])
results.append(scroll_result['hits']['hits'])
scroll_id = search_result['_scroll_id']
results = self.get_scroll_results(scroll_id, len(scroll_result['hits']['hits']), results)
定时任务的部分核心代码
拿到 elasticsearch 的数据,存储 mysql
def api_fail_devices():
"""
定时查询ES,订阅文章接口失败的设备和次数
然后保存mysql
:return:
"""
sub = ES_Subscription()
today = datetime.date.today() - datetime.timedelta(days=1)
# 先查询数据是否已存在
result = Subscription_Api_Fail_Devices.query.filter_by(index_date=today).all()
if len(result) == 0:
# 查询elasticsearch
devices_nums = sub.get_subscription_fail_devices("0")
for k,v in devices_nums[0].items():
article = Subscription_Api_Fail_Devices(k, v, 'iOS', today, time.strftime("%Y-%m-%d %H:%M:%S"))
db_session.add(article)
for k,v in devices_nums[1].items():
article = Subscription_Api_Fail_Devices(k, v, 'Android', today, time.strftime("%Y-%m-%d %H:%M:%S"))
db_session.add(article)
db_session.commit()
db_session.close()
定时任务初始化配置代码。包括要执行的 job,以及需要把定时任务持久存储到 MongoDB。
class Config(object):
JOBS = [
{
'id': 'api_fail_devices',
'func': api_fail_devices,
'args': '',
'trigger': {
'type': 'cron',
'hour': '1'
}
}
]
SCHEDULER_JOBSTORES = {
'default': MongoDBJobStore(host='MongoDB的ip', port=27017, database='test')
}
SCHEDULER_EXECUTORS = {
'default': {'type': 'threadpool', 'max_workers': 100}
}
SCHEDULER_JOB_DEFAULTS = {
'coalesce': False,
'max_instances': 10
}
SCHEDULER_API_ENABLED = True
app.py 里加载定时任务执行器
app = Flask(__name__)
app.config.from_object(Config())
scheduler = APScheduler()
scheduler.init_app(app)
scheduler.start()
Vue2 前端
这块就不多做介绍了,主要用的 Vue.js 2 + vue-router + webpack2 + iView 2 + highcharts
然后用的一个叫 iview 的组件库,非常棒,写页面 so easy,地址:https://www.iviewui.com/docs/guide/install
报表主要用的 highcharts,地址:https://www.hcharts.cn/demo/highcharts
github 地址:https://github.com/xiaoluosun/vue-monitor
安装依赖
npm install
开发环境启动
// 第一次启动用,用来创建index.html
npm run init
启动
npm run dev
生产环境编译
npm run build
最后放张预览图