-
记录一下我的裸辞面试(更新第七天) at 2022年06月08日
用 excel 写的用例,从 swagger 上自动获取的,使用 unittest 读取,并写好对应请求方法的处理类,根据字段执行请求。请求只看是否为 200,如果是就通过,否就显示报错详情。最后在 HTMLTestRunner 上显示报告。就是这样的。我目前也打算把断言加到用例里,要不确实有点不太严谨。
-
记录一下我的裸辞面试(更新第七天) at 2022年06月08日
哈哈,也还有 3 天的骑驴找马时间呢哈哈。
-
记录一下我的裸辞面试(更新第七天) at 2022年06月08日
也干了不短的时间了,各方面有些寒心,觉得没必要待了。
-
记录一下我的裸辞面试(更新第七天) at 2022年06月08日
现在明白自己等级了,不过我想多准备一下,争取面中级点的,先把大佬说的这些给找补了。
-
记录一下我的裸辞面试(更新第七天) at 2022年06月08日
嗯,好的,谢谢了。
-
记录一下我的裸辞面试(更新第七天) at 2022年06月08日
谢谢兄弟指点,之后得多注意一下。
-
请推荐【让你拍手称赞的帖子】- 已结束 at 2022年06月07日
推荐恒捷的(接口测试的一些感悟):https://testerhome.com/topics/3701
推荐理由:大佬技术全面且扎实,我选个影响力大点的文章推荐。 -
从零开始搞测试平台 at 2022年05月31日
哦,我好像点成发布了,麻烦删除一下吧
-
从零开始搞测试平台 at 2022年05月31日

还是草稿呢呀,你们已经开始审核了吗 -
现在是消费降级了吗? at 2022年05月24日
这是啥呀?变值钱了?
-
测试基础 10 问 - 上 at 2022年05月23日
顺便问下大佬提到的:"解决痛点、横向拉通",大佬能举一个例子吗?这两种我平时接触不太到。
-
测试基础 10 问 - 上 at 2022年05月23日
大佬一席话,受益匪浅,感谢大佬。
-
测试基础 10 问 - 上 at 2022年05月22日
然后想跟大佬谈论一下有关测试学习开发技术应该到何种程度的问题。
测试学习开发技术,我觉得如果测试都要了解的话,那无疑对于测试点设计的全面性有显著加成。
首先从宽度来讲肯定是多多益善。
比如我们项目用后端是 spring boot 前台是 vue。
我能用 spring boot 写一些接口之后,我开始比较完全的理解了接口倒底是个什么。
前端知识也是,学了 HTML 和 JS 之后,对于一些前端页面甚至能猜到他们是怎么写,并且有缓存问题也不再去找 cookie,而是先去浏览器的存储里面查看。可一般应该学到什么程度比较好呢?
可真要学话,不论前端后端哪一块知识,都是挺多的,都学进去我觉得付出的成本有点多。
从我个人体验来看,真要说对我测试有帮助的话就是学了基础之后(能搞个 demo),
开始对开发做的这些东西有一个明确的概念,不再是像之前那样模模糊糊了。
后面继续的学习,可能对我做测试平台有用,但是对于丰富我的测试点,我觉得没那么大用了。所以总的来说测试学习开发知识我认为应该是广度,明显大于深度比较合适。
不知大佬是什么看法呢? -
测试基础 10 问 - 上 at 2022年05月22日
"例如,当你了解了 redis 的技术实现,你在设计用例时,就会考虑到数据持久化、数据时效性、数据透传等等场景。"
这句有点一语惊醒梦中人的感觉,我们也用 redis,但是我却没想过要去按照 redis 的特性测试。
我觉得根本可能在于对相关知识的缺乏。
大佬有意愿去整一个这种开发使用工具(比如 redis),及工具对应的测试点的文章吗?
这样可能帮助坛友们对于自己日常工作的测试点进行一个查漏补缺。
当然大佬一般比较忙应该,光看这一篇也很有帮助了,感谢大佬分享。 -
如何判断 app 里的页面是原生的还是 H5 的? at 2022年05月10日
OK,试了一下,挺明白的,谢谢大佬。
-
locust 压测脚本如何进行合理的参数化? at 2022年05月01日
OK,谢谢仁兄指点了。
-
记一次测试开发面试题 at 2022年04月29日
能抗到第二轮挺牛了,我笔记只能写算法题。问下笔试的第二题:
2.双 11 做一个抽奖活动的功能。①抽奖核心抽奖算法功能在前台做,中台负责相关数据存储。 ②前台只做数据展示,中台负责核心抽奖算法。
①:以上两种各有什么缺点
②:如果是你,你该如何设计
该如何回答。 -
locust 压测脚本如何进行合理的参数化? at 2022年04月29日
好的好的,你后面说的两个方法(一个文件里写 70 个@task,和分写 70 个文件),我感觉都比我的有可行性,感谢大佬。
然后我参数化的目的其实就是想少写点代码,直接通过 excel 读取再分别执行就完事了,这样一接口就写一个方法的话,等于我又没有参数化了。大佬对于将这些接口批量的读取并执行有啥心得吗? -
locust 压测脚本如何进行合理的参数化? at 2022年04月29日
我之前就是看的大佬博客学的 locust,没想到是大佬亲自上场指点,感谢大佬。然后顺便问下我对 excel 的读取方法从 onstart 里面取出来放到了 task 里运行之后:
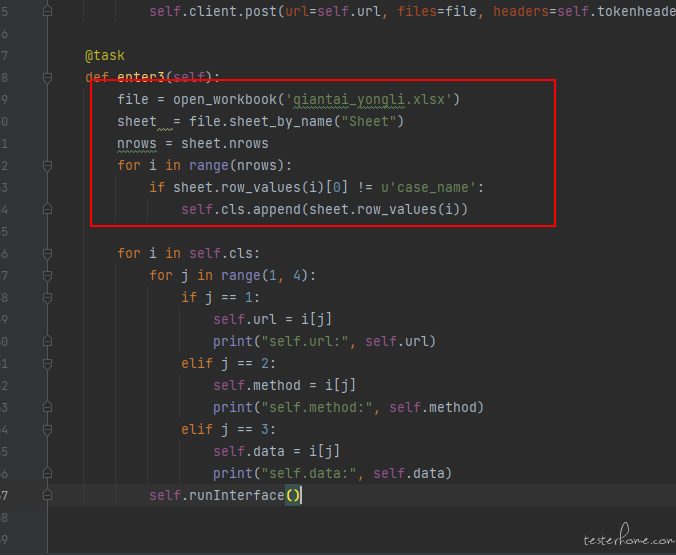
还是跟之前一样是一个一个接口的请求,问下大佬是如何做的参数化呢? -
locust 压测脚本如何进行合理的参数化? at 2022年04月28日
对对对,是这样,那这样就等同于如同上面大佬所说的参数化的姿势有问题。现在我设置了 70 并发,实际执行效果还是一个一个执行,那可能就是如同你前面说的,N 个接口逐步请求,所以无法达成并发的效果。
-
locust 的用例如何设置只请求一次 token? at 2022年04月26日
哦哦,这样是种方法,确实就是请求了一次,可是这样就变成每次都要从文件里读了,还能再优化吗?不过读文件肯定比网络请求稳定,大佬这种方法已经算给我的脚本升级了。
-
使用 locust 进行接口请求时,如何判断它真的进行了请求? at 2022年04月25日
原来如此,感谢大佬的讲解。
-
Easy-Locust 自动生成 locust 脚本 at 2022年04月24日
大佬,能弱弱的问一下你这个项目该如何启动吗?
-
使用 locust 进行接口请求时,如何判断它真的进行了请求? at 2022年04月24日
我通过去数据库查新增数据数也看出请求成功了,但是原理没理解,大佬说完明白了,感谢指点
-
request 发送表单时该使用何种数据格式? at 2022年04月20日
顺便说下表格里面的数据是怎么转换成 request.post 中要求的字典的。
我表格里的数据是这样:
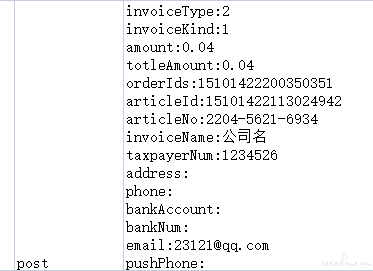
将其转换为字典使用的语句是:
self.data = eval(self.data)
但是转换不成功,一番探索后发现将表格中的数据修改成如下格式即可以顺利转换(空白内容也要加引号):
