-
这几天很火的套路招聘图片…… at 2019年04月18日
厉害,第 2 题你的做法开发效率要高太多了

-
有谁做过 kafka 的压力测试 at 2019年01月08日
求分享经验:)
-
求一款轻量级的性能监控工具 at 2018年09月12日
可以试试 PMM,拉个 docker 镜像就能跑,也不用配一堆东西,常见的数据库和服务器监控的功能大致都有,监控服务器集群挺方便
https://www.percona.com/software/database-tools/percona-monitoring-and-management
-
压力测试遇上了一个奇怪的问题,请有经验的兄弟们帮忙看下。 at 2018年08月30日
后续楼主有没有得出结论?既然是测试接口应该很好搞。
一些排查原则
- 不管什么问题,首先怀疑是客户端的问题
- 排查顺序通常是:自己的脚本、设置、机器资源、网络带宽和设置、工具/框架选型本身
- 工具是 Locust 的跳过前 2 点,直接怀疑是它本身有问题,马上用另一款更高效的工具,类似的设置做对比。
这里不提服务端,因为我猜到这步就能结束了。
一个小实验
楼主如果有空可以写这么个简单的接口对比下各种测试工具:
- 从收到第 1 个请求开始,前 100 秒正常响应,比如什么也不做,sleep 10*毫秒* 返回
- 第 100 秒~第 200 秒,sleep 50*秒* 返回,没看错是 50 秒
- 之后又是 100 秒的正常响应,再接 100 秒 50 秒响应,如此反复
这就是识别 coordinated omission(CO)问题的典型方法,然后你看看各种工具的各个百分位数的统计结果,有多少能让你简单地发现这么明显的问题的,结果很可能会吓一跳。
除非你一下子就找到了某 2 款,通常不管开源还是商业还是自研都全军覆没。
(如果用这个作为首要选型标准,你就会像我一样把 JMeter、nGrinder、Locust、ab、siege 等等统统淘汰了

-
mysql 亿级数据优化 at 2018年08月29日
这不是反讽吧?
 都是常见的开发规范,能不能落实得好是另一回事……
都是常见的开发规范,能不能落实得好是另一回事…… -
一把性能基线测试瑞士军刀,wrk 性能测试工具 at 2018年08月27日
http_load 06 年的过时东西了就别提了吧……
ab 不推荐,content-length 长度变了也当成错误,而且单线程是个瓶颈,用 nginx-status 页面做测试,客户端找台 8 核以上的服务器,跑一下就知道和 wrk 差距有多大了。
小工具推荐 wrk2,https://github.com/giltene/wrk2,是 wrk 的分支。推荐看看作者 Gil Tene 在 readme 里写的关于如何正确测量响应时间,推荐搜一下作者讲 coordinated omission(CO)的 2 个 youtube 视频。
wrk 也可用,性能也更好些。建议跟 wrk2 对照,毕竟 CO 是个大坑,全世界绝大部分压测工具都掉坑里。
locust 不推荐,一是作者看上去不知道自己在做什么,二是框架性能和报告功能都极差,有这功夫填坑不如找个更正经的框架二次开发。
ngrinder 不推荐,往往是只做过 demo 的人才吹它的开箱即用。github 上 2 年多没更新了,跟死了差不多。
taurus + jmeter 组合现在很流行,算是可用,但小心 CO 问题。它的命令行报告生成的网页里,首页的响应时间百分位数统计不一定可靠,注意点开看菜单里的各种 overtime 图表。坑踩得少的人很容易用它骗自己接口的响应时间没问题。现在项目里已经基本抛弃它了。
愿意封装和写代码的话推荐 Gatling。动手封装前最好搜一下一篇貌似叫 close workload model vs open workload model 之类的论文,06 年的。Gatling 要用 open workload model,也就是指定 RPS 然后它每秒新建这么多连接,才能避免 CO 问题。
-
[踩坑总结] nf_conntrack: table full, dropping packet [新] at 2018年08月25日
我不懂网络也不懂内核,以上都是我编的,我实在编不下去了……
-
[踩坑总结] nf_conntrack: table full, dropping packet [旧] at 2018年08月24日
我不懂网络也不懂内核,以上都是我编的,我实在编不下去了……
PS: 这个好久之前发的了,鄙视一下转载不写出处的行为:http://blog.51cto.com/wujingfeng/2096885,页面也找不到举报按钮……
旧文章会过时,也可能作者写的时候理解是错的,对某一块不熟悉的人看了转载的日期比较新,也许就信了,然后掉坑里。中文网络上充斥着这种转来转去的文章,有些十几二十年前出现、从一开始就错误的东西到现在还阴魂不散,我也经常被坑。
这大环境对新人极度不友好,不习惯用 Google 的掉进去就爬不出来了,然后恶性循环。 -
关于 jmeter 性能测试的 局限性 at 2018年03月23日
兄弟你的脚本还不如现成的工具呢,一来
requests库是同步的,二来 cpython 有 GIL,多线程有点鸡肋,虽然对这种主要耗时在 I/O 的场景影响不大,但以 python 的性能,最终还是达不到 jmeter、gatling、ab、wrk 的效果。至于 jmeter 是 BIO 的,这个我一直以为是搞性能的人的常识呢……
如果有资源,更高压力可以通过多开实例或增加客户端机器达到,但未必会得到你想要的结果。在服务器或后台服务被压死之前,考虑一下请求根本到不了服务的情况:负载均衡/反代/网关/waf 掐掉连接,netfilter 哈希表用光弃掉 IP 包,请求在 tcp 监听队列、接收队列排队直到超时,连接数限制,文件描述符限制,然后 spring cloud 或 tomcat 各种配置限制……
响应时间增加就是在排队,继续增加压力基本上只能看到计算出的响应时间越来越长,因为队列越来越长,后到的请求排了很久的队,最终看到的错误多半是连接超时或响应超时。
其实不需要真的搞挂什么,只要业务给出这场景能接受的最大响应时间(或 99%,99.9% 之类)是多少,达到这个数的时候就是极限了。之后还有余量那是用来扛突发情况的,对用户来说不管挂不挂都是不可用了,在某些行业慢几毫秒可能已经出事了。
-
在大疆做测试开发是一种什么体验? at 2018年03月06日
请问招专职性能测试不?
学历除了本科有没有硬性要求专业和学校?
-
nGrinder - Groovy 脚本指南 at 2018年03月05日
选型参考:
优点:
- 无需安装、跨平台:总共就 controller、agent、monitor 3 个 jar 包。
- 开箱即用,web UI 比较友好,测最简单的 GET 请求上手门槛低。
- 有简单的可视化报告。
- 有简单的资源监控。
- 有简单的脚本管理功能,整合了 SVN。
- 容易扩容:只需要把 agent 放到压测机器,monitor 放到被测服务器。
缺点:
- 发送请求
- 首页只支持 GET,POST 需要新建脚本然后创建测试。
- 脚本管理
- 脚本文件、目录没法重命名,没法移动,只能删掉重新建一份,或通过 SVN 操作。
- 如果多个脚本使用同样的库和资源文件,UI 里不好搞(除非全塞同一个目录下),需要建完整的 Maven 工程。
- 报告
- 1 个测试脚本里调多个接口时,报告里看不出这些接口分别是什么、响应时间和 TPS 分别多少。
- 1 个测试脚本里调多个接口时,只要某个测试方法成功,即使其他方法抛异常也不会反映在报告的错误数里,要看 log 才能发现。
- 脚本里可以定义多个事务,但详细报告里只有总体情况,想看各个事务的数据只能下载 CSV 自己写程序解析。
- 响应时间没有按百分位数的统计,需要二次开发。
- 服务器资源监控收集的数据较少,需要二次开发。
- 想改默认脚本模板很麻烦,需要改源码然后重新打包。
总结:
如果非专职做性能测试的人,如开发/运维/业务测试希望有一个简单的工具来定位问题,而且项目用 HTTP 协议、没有很麻烦的鉴权、签名、加密等限制、GET 请求又足够多,nGrinder 可以用。易用性至少跟 PTS、WeTest 一个水平,nGrinder 要写代码的场景这 2 个平台或者其他工具多半同样要写。
专职的话它肯定不是首选,开发起来不够快,定位问题也不够方便,有其他更合适的选择。
我不懂 Groovy,以上全是我编的,我实在编不下去了……
-
nGrinder 改造 - 在详细报告里增加更多统计项 at 2018年03月02日
-
JMeter4.0 变化-迎接 java9 at 2018年03月01日
感觉最大的变化就是现在打开界面飞快
-
性能测试工具 nGrinder 项目剖析及二次开发 at 2018年02月28日
请问这些修改有提 pull request 吗?每个人一处处改还是挺麻烦的,版本更新了又得改一次
-
JMeter 实时监控仪表板配置 (Grafana + InfluxDB) at 2018年02月28日
你找个接口试试?debug sampler 的逻辑也许不一样
-
JMeter4.0 变化-迎接 java9 at 2018年02月27日
JSON assertion 终于标准化了,可以少装一个插件
-
JMeter 实时监控仪表板配置 (Grafana + InfluxDB) at 2018年02月23日
influxdb 那个 web 控制台很早就没有了,直接上服务器查

-
Jmeter 请求参数中包含 MD5 加密的密码 at 2018年02月11日
md5 函数在插件里,搜 jmeter-plugins 网站,有个插件叫 custom jmeter functions
-
测试开发之路 -- 请不要打着人工智能的旗号在测试圈子骗人 at 2018年02月11日
因为有很多人的熟悉就是熟悉长矛大刀弓箭嘛,别人都开高达了
-
Locust 源码阅读及特点思考 (三) at 2018年02月05日
我也是在项目里踩过 locust 的坑,确实是皇帝的新装。
真正的问题还不是上面那些,而是这种单线程使用 event loop 的架构不太适合做压测,除非资源消耗非常低。
当单个核跑到 90%+ 或 100%,event loop 会受影响,这程序记录的响应时间就完全不可信。
我是写完脚本压完才发现响应时间一看就完全不可信,用静态页对比一下,其他工具得出的响应时间<10ms,locust 居然得出 300+ms……
而且它占用资源非常多,这边的服务器是 4 核虚拟机,用 20 以上的 vuser 跑,cpu 单核就到 90%+ 了,结果完全不能看。
而且 locust 的作者在性能方面也不专业,不只一个人提过 issue 说 locust 的性能问题了,他们都认为没问题。我把测试结果提 issue,人家直接关了。
后来用回 jmeter 重做了一遍,白白浪费几天时间,坑死了。
-
JMeter 实时监控仪表板配置 (Grafana + InfluxDB) at 2018年01月16日
不好意思很少上论坛,现在才看到,估计早就解决了吧:P
如果没错误,Error info 是没有数据的。面板上如果显示不正常可以去 influxdb 里查一下数据。查一下有没有
statut为ko的记录。pct 95 那图表没数据的话看看 db 里有没有叫做
pct95.0的列。在 JMeter 的 Backend Listener 里有个 percentiles 字段,我是设成 50;90;95;99 ,截图里有。这里写了多少,db 里就会有名为pctXX.X的列。如果你删了 95 就不会有那列。 -
JMeter 实时监控仪表板配置 (Grafana + InfluxDB) at 2017年12月22日
抱歉现在才看到,导入应该能看到 3 个选项,数据源选你自己的 db,然后指定表名和发送间隔(在 JMeter 里默认是 jmeter 和 5 秒,都按默认就不用改这 2 个)。
如果发现 bug 或有改进的建议欢迎随时告诉我。:)
以上全是我编的,我实在编不下去了……
-
ApiTestEngine (2) 探索优雅的测试用例描述方式 at 2017年10月12日
你们是用现成的工具/框架还是自己造轮子?
换工具这种事超级烦,之前的脚本不通用: (
项目里已经用过 jmeter、gatling、locust,没一个满意,浪费不少时间,被老大骂很多次了……应付临时任务还是 jmeter 最适合,无论效率还是性能有空准备看看 taurus,如果它的 yaml 用例格式比较合理就模仿一下,以后让新工具支持解析这种文件就不用那么烦了……
-
ApiTestEngine (2) 探索优雅的测试用例描述方式 at 2017年10月11日
大概知道上面是怎么回事了,似乎跟自己发请求自己监控有关,虽然电脑明明还有不少资源
用了 master/slave 就正常多了,对很快的请求这是不能接受的,10 倍时间……好在那种接口通常 ab 或 wrk 就够用
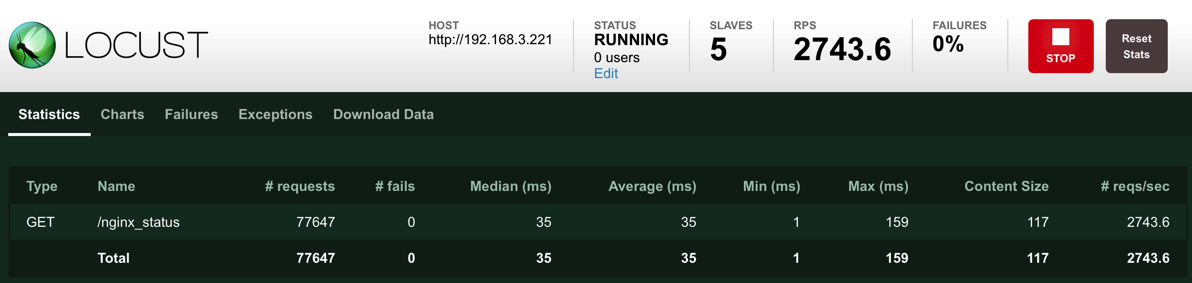
有空再翻翻源码看看怎么回事,另外那个 hatch rate 和 number of user 的设置跟实际的上限和增长率的关系也是个迷……
-
ApiTestEngine (2) 探索优雅的测试用例描述方式 at 2017年10月11日
今天遇到了,看见 locust 里每个接口的平均响应时间都很整齐的 1 秒多,拿 nginx_status 页面试了一下,其他工具报告平均 4ms,locust 竟然报 300ms,结果完全没法信了
总之先提个 issue……,也给准备入坑的人看看这夸张的数字……
https://github.com/locustio/locust/issues/663
再来个真正的接口的例子,jmeter 200 线程 vs locust 200 协程
之前用 locust 做了两个项目都没有这么离谱,返回的数字都是比较合理的,今天不清楚什么情况……

