-
请教各位大佬一些关于 sql 层性能保障的问题 at 2022年04月11日
建立重要 get 接口的性能基线?
-
外部调用 jmeter,如何得知 jmeter 执行结果后,再次执行 jmeter at 2022年03月29日
用 teardown 线程组,第一次执行完毕后打标
-
关于 jmeter 压测时出现报错,导致吞吐量变大的疑问 at 2022年03月23日
我感觉跟 error 关系不大,因为错误率才 0.04%,并且 TPS 图中并没隐藏 fail 绿线,只是数量太少显示不明显。
从聚合报告的 TPS、平均响应时间、sample 数量来算,你这次压测顶多执行 1 分多钟,但 TPS 图却显示 12 分钟,我很怀疑上下两张图不是同一次压测产出。
-
数据为什么会走丢了呢? at 2022年03月16日
学习了!
当发生 TCP 堵塞时,数据会先存在接收方的接收缓存区中,这时如果 TCP 连接断开竟然会导致缓存区数据丢失。
至于数据丢失的原因,应该是 TCP 连接断开时,接收方的 socket 套接字(存放 TCP4 元组、程序信息)也会被注销,导致缓存数据不知道该被发往哪个程序。 -
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at 2021年12月01日

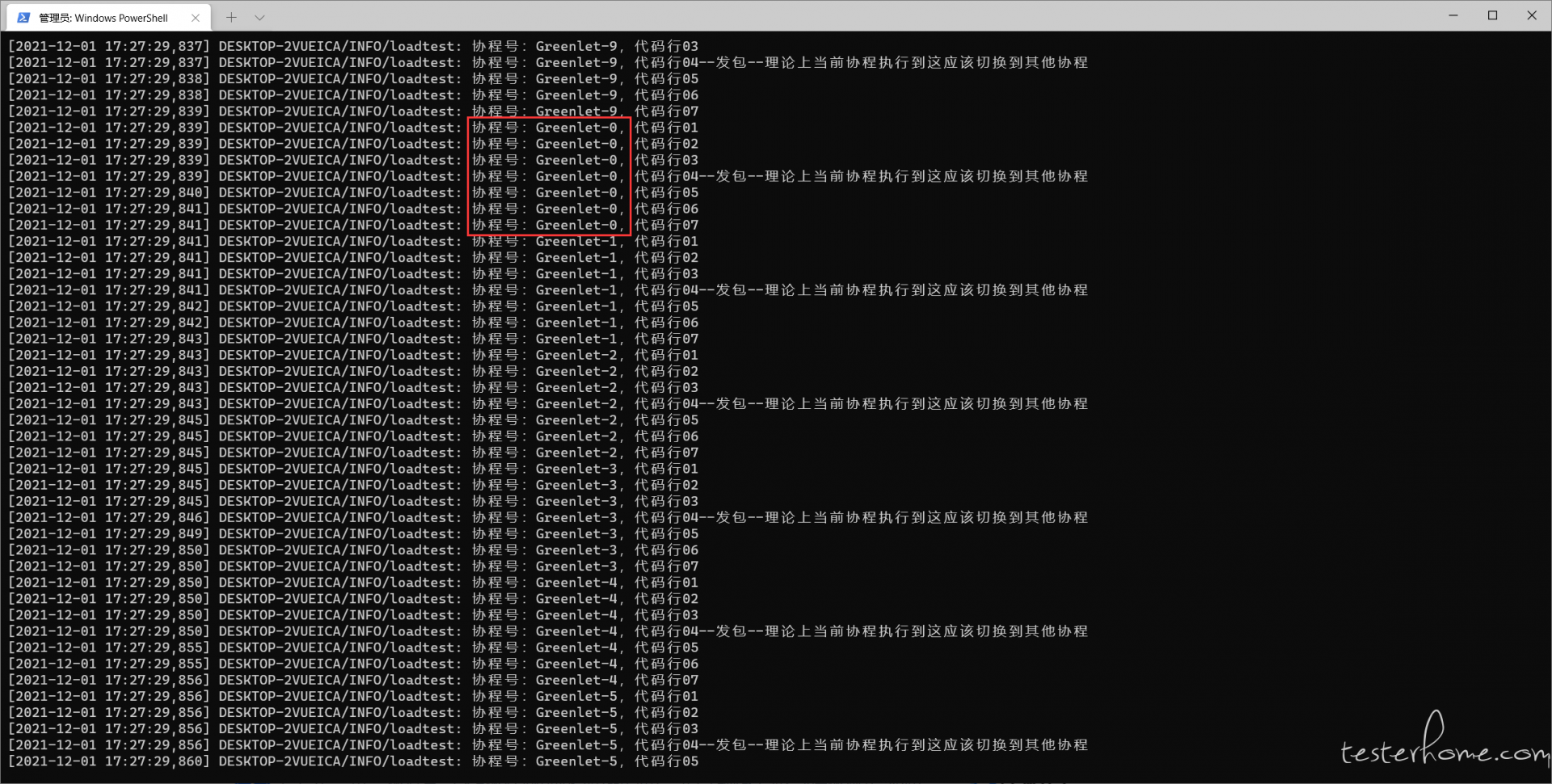
应该是被测协议不支持协程,代码执行到发包时不会切换到其他协程执行,感谢各位
-
想学性能,不知道如何挑选 at 2021年12月01日
真贵,自学不挺好的
-
压测服务达到瓶颈以后,继续增加并发用户数,并发请求不再增加吗? at 2021年11月25日
因为响应时间增加了啊,看你上图应该是后台服务的负载处理能力达到上限了
-
locust+boomer 都能正常启动,但无法工作( You are running in distributed mode but have no worker servers connected.) at 2021年11月24日
的确是版本问题,换成 1.6.0 正常运行,感谢
-
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at 2021年11月16日
是的,但感觉并发数会受限于负载机 CPU 核数(进程间切换消耗大),且无法真正用到协程
-
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at 2021年11月15日
另外您提到的将压测端换成 boomer,我也想过,但目前协议还不支持 GO 语言。
-
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at 2021年11月15日
感谢您的回复。
我也做了一些排查,目前倾向怀疑是 locust 对自定义协议支持有 bug,或我的用法有问题,但没办法真正确认。【排查内容】
1、同样的环境下与 JMeter 比对,JMeter 多线程生成的负载远高于单进程多协程的 locust;
2、协议支持 Python 和 Java 对接,不论是 Python 直接对接,还是通过 Jpype 引入 jar 包,然后用 locust 发包,结果一致;
3、task 换成 http 协议,甚至直接 sleep(),Number of Users 参数均正常生效;
4、监控负载机(40 核)和服务器资源(48 核),运行状态下,内存和每一个核心都是比较空闲的状态;
5、多进程分布式执行,虽然负载翻倍,但并发数受限于负载机 CPU 核数,且无法真正用到 locust 的协程。我现在想打印出压测过程中每个协程的具体操作,但不太熟悉协程,暂时还无从下手。
-
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at 2021年11月15日
没有设置 wait_time
-
测试平台之接口测试 at 2020年08月24日
什么是 BTest 模板啊
-
想请教一下基于大数据的测试有没有什么好方法 at 2019年07月17日
先收藏,等行业大佬出现或自己琢磨出点东西再回头看