背景
对于大数据测试,验证数据的正确性,一直没有一个好的切入点,画了个思维导图抛砖引玉,请教一下大佬们。
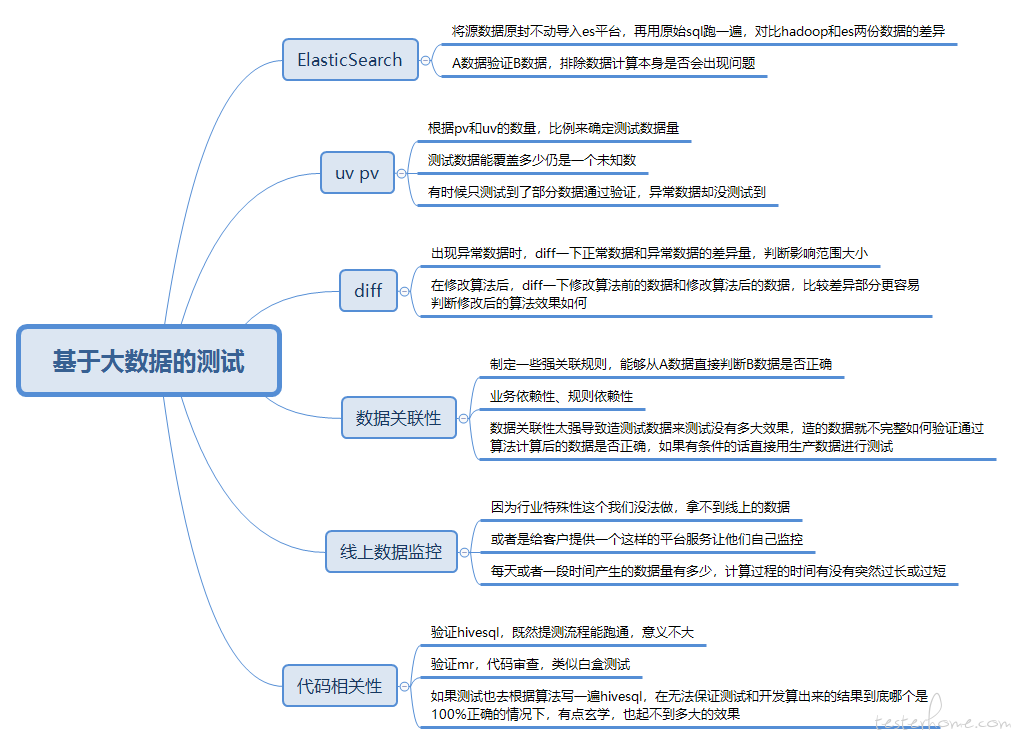
如图
我也想知道,我现在都是代码审查,查看 sql 逻辑,自己再写 sql 分段验证。主要是要熟悉业务数据
同求啊,我现在只是造数据,根据清洗规则,看结果,
不用测,上线真实数据验证,错误快速重跑即可,开发就能搞定。测试来做工作量巨大属浪费时间
什么样的需求,什么样的场景,得先说说吧
你自己造的数据肯定是完整的啊,自己造的数据我们都是可控的啊,json,xml 都是类似这样的结构,,然后看清洗,如果清洗都不对,计算肯定不对啊
这个应该有两个方向来看,一种是知道目标数据是啥,来对比;一种是不知道目标数据是啥,但是知道应该肯定没有哪一类数据,包含不应该存在的数据的量占比有多大,与之前的结果作对比,可以了解到这次算法结果是不是有提升吧?
留个名,有大公司的来指导一下么?
数据筛选的简单原则?
凭空造数据是条死路吧。泛化很难保证的,还不如用爬虫之类的还稍微靠谱点。或者 GAN 之类的?
对,你说的这个情况也考虑过,现在我们就是都不能保证计算后的数据是否正确,没有目标数据。然后就是 diff 前后数据只能筛选哪些明显异常或者在业务规则范围内不太应该出现的数据,可以与之前的数据对比来判断算法修改后的效果,但是感觉也作用不大的样子,所以整个测试组都很迷茫

先收藏,等行业大佬出现或自己琢磨出点东西再回头看
1.造数据验证代码执行符合设计逻辑
2.已标注数据集(可以根据不同侧重多做几个),第一步测试完,上测试集群跑测试标注数据集,比对修改前结果。(这部分开发测试做都 ok)
数据准确性是个难题,模拟数据与预期结果这一关目前没看到有什么好的解决方案~ 更何况还有数据量的区别。
哪怕有线上数据,也很难保证预期结果的完整性。