-
测试工作重复枯燥,必须成为测开才能避免? at December 28, 2020
工作两年半,目前的状态也是每天点点点之外,在接口平台录入自动化用例。接口平台是组内 QA 自己写的,工作中唯一敲代码的时候就是自己扩展接口平台的功能。不过平时也会 review 一下开发的代码,有时候也能在代码层面就发现他写错了,偶尔会参加技术评审。感觉能获得别人认可的时候会有成就感,而不是在别人眼里自己只会点点点,但是每天重复劳动,也是很疲惫吧,感觉成长不是很大。
-
如何统计 Python Web 项目在集成测试阶段的增量代码覆盖率 at January 20, 2020
感谢,我目前还处于调研阶段,不太确定可行的路径是怎样的,发这个帖子主要是为了咨询一下大家可行的方案,或者做过相关事情的经验等

-
如何统计 Python Web 项目在集成测试阶段的增量代码覆盖率 at January 19, 2020
感谢,这个文档我正在看。
-
如何统计 Python Web 项目在集成测试阶段的增量代码覆盖率 at January 19, 2020
真的没有大佬做过 Python 项目集成测试阶段增量代码覆盖率相关研究的吗

-
如何统计 Python Web 项目在集成测试阶段的增量代码覆盖率 at January 17, 2020
大概浏览了一遍社区关于代码覆盖率的帖子,90% 都是基于 JaCoCo 做的二次开发,跪了。

-
四年来的测试之路,让我对互联网越来越厌倦 at January 17, 2020
ok,是我理解错了,别这么激动
-
四年来的测试之路,让我对互联网越来越厌倦 at January 17, 2020
大学辍学了?有点上头啊
-
2019,我 survive 的一年。 at January 16, 2020
同 18 年毕业,同在杭州,不过你是北上去北京,我是南下来深圳了哈哈,HK 确实蛮累的,庆幸我没去。
-
四年来的测试之路,让我对互联网越来越厌倦 at January 16, 2020
96 年 4 年,我 95 年才一年半

-
Charles 和 Postman 分别是什么? at September 18, 2019
一个支持 mac,一个不支持 mac😝
-
TesterHome 性能测试 workshop 杭州站 at May 11, 2019
前排留名混眼熟

-
[已开源] EasyUseCase 一款脑图转化 Excel 测试用例工具 (1.4GUI 版本升级) at March 07, 2019
感觉很不错的样子
-
[合肥] 华米科技 招聘测试开发工程师!! at January 30, 2019
-
测试开发第八期_shell 必备技能实战_20190120 at January 20, 2019
netstat -ntp | grep 22 | sort | uniq -c | wc -l
-
测试开发第八期_shell 必备技能实战_20190120 at January 20, 2019
作业 3:
awk '{print $1}' /tmp/nginx.log | sort | uniq -c | sort -r | head -1
-
准备好 STF 的前置环境以后,安装 STF 报错 at January 14, 2019
看上面的回复
-
准备好 STF 的前置环境以后,安装 STF 报错 at January 11, 2019
现在已经没问题了,搭建完成了
-
准备好 STF 的前置环境以后,安装 STF 报错 at January 10, 2019
我瞅瞅,谢啦
-
想请教一下基于大数据的测试有没有什么好方法 at January 10, 2019
凭空造数据是条死路啊,我们也尝试了很多,然后又没有真实数据,只能去客户现场测,压力很大,也想有大佬来指导一下
-
想请教一下基于大数据的测试有没有什么好方法 at January 10, 2019
对,你说的这个情况也考虑过,现在我们就是都不能保证计算后的数据是否正确,没有目标数据。然后就是 diff 前后数据只能筛选哪些明显异常或者在业务规则范围内不太应该出现的数据,可以与之前的数据对比来判断算法修改后的效果,但是感觉也作用不大的样子,所以整个测试组都很迷茫
-
想请教一下基于大数据的测试有没有什么好方法 at January 10, 2019
自己造的数据,造什么样的数据得看业务规则是什么样的,数据之间关联性很强,所以导致数据造不完整
-
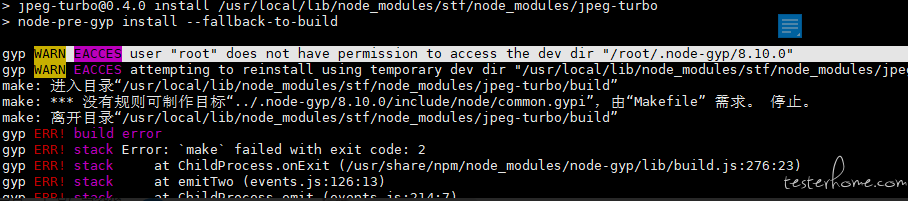
准备好 STF 的前置环境以后,安装 STF 报错 at January 10, 2019
自己答一下吧,出现报错的原因是上面还有一行警告说权限不够
还有 root 权限不够的吗,有点懵逼
然后执行 sudo npm install -g stf --unsafe-perm 这个命令安装成功了
-
想请教一下基于大数据的测试有没有什么好方法 at January 09, 2019
场景就是数据采集 - 清洗 - 计算 - 导出这个流程,需求就是验证计算这一步,开发跑出来的数据经过计算后到底对不对
-
想请教一下基于大数据的测试有没有什么好方法 at January 09, 2019
数据监控这块也提到了,我们的东西给客户以后完全没有控制权,很尴尬呀