-
谁用过 Nessus 里面的 web 程序扫描插件,如果 web 系统有 token 应该怎么配置呢 at 2022年06月01日
-
一些 bug 定性,大家怎么看 at 2022年06月01日
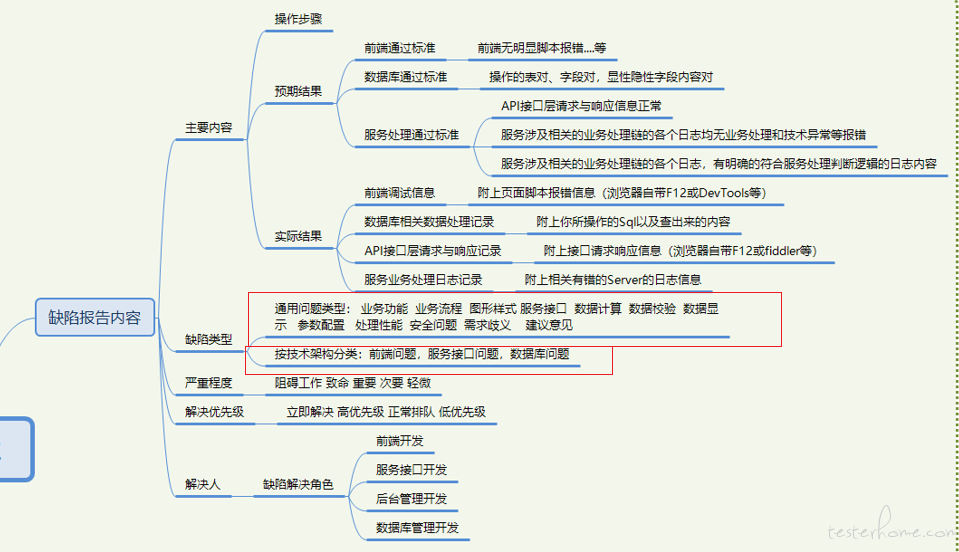
bug 定性,就是缺陷类型。
分的维度:
1 业务维度
业务维度带来的缺陷类型可能有,业务功能,业务流程,
2 技术实现维度
可能有 前端问题 接口问题,服务问题,数据库问题 这是大类 可以把各个大类 比如前端问题再细化。比如前端 界面样式问题,前端脚本问题等等等等自己根据实际统计缺陷的需求 或公司实际项目情况酌情增减, 多了没好处,少了统计不细。
-
功能性测试用例设计方法深入理解 at 2022年05月31日
分层看数据流。夹板思路看数据流。
前端 提交表单 是一种对 server 的输入 展示查询页面是对前端的一种输出。角度不同,输入输出是会互换的。接口层面 就是提交的入参 是输入,它的输出,最近的输出就是接口的返回,较远的输出可以是落地的数据。这种就是广义的输出数据流。狭义一点的,就是 DB 里的一些不面向业务处理的字段 或接口里不面向业务处理的参数,这些是非业务处理的,一般我们较多关注业务处理的参数或 DB 字段,那么狭义的就是 哪些隐性参数 或 落地字段 是面向技术处理的判断字段。
另一种,就是 接口承载的 server 对象的,服务处理 log ,可以认为是接口的一种输出,因为它体现接口服务的内部处理逻辑,和技术处理异常。 可以当做接口的输出来做检查。
所以,不同夹板线下,的输入 输出 是可大 可小 可远 可近的,看你具体测试点 是关注前端交互 还是接口 还是服务处理逻辑 还是落地数据。 当然 全部大夹板的话,一个提交表单的输入 就是你提交的表单内容,输出可以是接口的返回,输出可以是 server 的 log ,可以是落地的 DB。按从前端 server DB 把处理串联起来来看的话,就是这些。
-
功能性测试用例设计方法深入理解 at 2022年05月31日
分层 分类写。聚焦点要原子性。
一 业务维度 就是经典的我图里的三层 纯按黑盒用例设计方法的一种分层思路。
二 技术实现维度 就是任何业务系统,实际都是三层,前端 服务 数据库这种可以拿 testlink 或支持分类树写的都可以写成。 但不必拘泥于此。
实际建议 tesklink 的写清整理好,各层的业务规则,技术处理规则就好,实际按上面写,挺复杂的,如果思路分不清 摘不清 放不明白地方的话,你也写不好,这是时间淬炼下的功力,体验领会精髓,再慢慢写,慢慢改进吧,最终才会锻炼出很清晰的分层原则的。实际,建议拿 xmind 脑图写,也能达到分层 分类 还能体现业务时序 或 服务处理时序 数据流时序 上的,而且比较直观 各层 title 命名好,每小节 也能很清晰的体现该层的测试目的,业务技术规则 时序 各层的要求。
-
接口测试、自动化有必要去数据库捞数据校验么 at 2021年09月10日
看公司的接口测试是前置执行,有专一独立接口测试人员从接口开发完毕就介入第一轮接口测试,产生第一轮基线脚本。
然后前端开发联调结束后,第二轮接口脚本修正。然后业务手工测试人员介入进行全面的系统业务测试,这期间在和手工业务测试人员和接口开发接洽,第三轮接口脚本修正。
这是我个人设计的比较好的,全周期专人接口测试模式,最终接口脚本框架,是有原子性的基线脚本。和一定场景度的场景脚本两大模式。同时如果公司手工业务测试人员推广的好,有一定接口脚本自组装能力,可以用专人接口人员的接口脚本进行自我业务的复杂接口场景的场景化脚本组装。这样就打通了 纯接口脚本人员和业务测试的边界,更好的把握纯接口问题和业务方面的接口上的业务实现规则问题。还是接口测试,如果不是上边的模式,就比较难办,会带来许多风险。
比如这个专业或不专职的接口测试,是完全滞后的在业务系统测试完,才独立去理解业务理解服务接口,整了一套。可能这种就是纯接口测试,完全相信手工业务测试是没问题或少量问题的。这样就比较麻烦,因为手工系统业务测试,又取决于这个手工业务测试人员的能力和测试水平能否完全测全服务端的接口问题,就比如数据的落地校验,是否在手工业务测试做了强检查强校验,完全熟知页面 -- 服务接口 -- 数据库表字段 的变化。这个各个公司的业务测试要求又不尽相同,笔者面试过程发现,许多无论是外包还是独立产品独立项目的公司,那真是千差万别,手工业务测试的套路和系统性规则性都完全不一致,外包好的给你数据库堡垒机去查,有的测试完全不熟悉业务表结构关联和字段与服务接口 前端界面的对应关系,可能只是依靠管理后台类的工具去验证前端的数据表单提交类接口。好点的独立产品项目型公司,就给足权限,自己反映射生成表拓扑结构图,各类数据表权限都给足。且该公司测试经理,有强要求关注 界面 接口 库的三者字段一致性。这种后期开展第一模式的接口测试就比较好。所以这是一个,公司测试流程和对接口测试理解的一个流程性问题,阶段性问题,如果是第一模式,就可避免许多接口测试上的理解偏差。
第一模式下,业务手工测试 做到了 前端界面 服务接口 数据库表字段的强认证 关注,强校验,也可以后期第二轮 第三轮测试阶段中,和专职的接口人员沟通交流,来确保落地数据库验证的。
如果你非要做到剥离数据库验证,那么请先保证你们公司的业务手工系统测试人员,可以和你友好的交流 三端数据验证问题,和他确实保证所有业务的落地数据 提交类 查询类 都和数据库表关联查询验证过,完全熟知各种有服务接口交互的表查询。并可和接口专职人员指导交流和沟通。但实际上,很多公司是第二模式,没办法做到业务手工测试后的质量,这时候又是个只做专职接口的,可能就只是做做接口返回认证,但这是有风险的,接口是会欺骗你的,操作错相似表或字段的。所以,我的建议是 如果是第一接口测试流程模式 且手工业务测试人员可以和服务接口人员一起参与接口测试的,可能越前期是需要数据库认证的,磨合好了后,接口的数据验证可以依赖接口返回验证了,再想办法剥离数据库验证。
如果,是第二接口测试流程的,比较麻烦,如果接口测试人员 对接口场景和业务更敏感,建议带上数据库验证,然后推广第一种测试流程。 -
请教个问题,例如 google 的浏览器,是如何进行自动化测试的。 at 2021年03月19日
@tester-yu
Puppeteer 了解一下。google 亲儿子。 -
功能性测试用例设计方法深入理解 at 2020年05月13日
大体上 只要是 符合 或者你能分为三层架构的系统 前端 服务 数据 都可以分层写。
针对不同测试层 比如 前端 我图上也列了 你的前端的测试对象 如果是重点测试业务流转组合 那实体物理对象 就是 页面 各个功能性页面 或弹窗 都可以 比如 注册页 登录页 支付页 或 登录弹窗 他们会形成业务流组合 你就把 这些物理页面对象 设计个流程组合即可。比如 今天还没有登录弹窗 后天加两个登录弹窗 只需要在 业务流测试层 加个登录弹窗的组合流程 覆盖到相关业务流组合。具体的操作交互层,就写到单独一层,这一层主要是放,或模拟客户前端操作行为对页面控件带来的组合,主要是测前端 Js 实现的问题。 比如 注册页面 那么多输入项 和 输出项的组合操作逻辑 就用因果判断 进行组合就可以了,具体的物理对象 是各个页面控件 但不涉及具体控件的输入内容,具体的输入内容 是放在 数据层的。 这一层主要是放 操作模拟组合。 比如操作序列,什么都不填,直接提交表单,看页面 js 和服务接口是如何控制的。
最后 就是 等价边界 注册页面的具体输入内容。 这一层就是放 我们测试最熟悉的 等价边界值 那些个东西。
这样就拆开和低耦合了啊,每一层的 测试内容不同 测试对象属性不同 就决定了这一层是可以单独设计和维护的了呗。
-
功能性测试用例设计方法深入理解 at 2020年05月07日
1 点 线 面 的理解还算可以吧。 就是让你分的清 当前的测试对象 当前的测试层次 当前自己在测什么 可以测出什么问题。
测试对象的属性 决定了测试的类型 决定了可以测出的缺陷类型。 好比我举例的 由上往下 业务场景层(对象是页面)
操作交互层(对象是页面控件 各种元素) 数据出入层(对象是 具备输入性质的各种数据 可以是页面的 可以是接口的 也可以是数据库的)场景层 有场景层的 业务组合问题 页面控制流转问题
操作交互层 有控件 和元素 之间的各种前端 JS 脚本控制业务逻辑 交互逻辑 业务规则的限制问题
数据出入层 有具体的问题 但要看数据是哪一层的数据 产生了什么交互 比如前端的 JS 校验 规则控制问题 这些都是纯前端的 js 问题。 到接口了 提交前端表单了 有接口的输入限制问题 和服务校验返回控制问题 到数据库了 有数据落地的正确啊 位数啊等等问题。就是让你建立起 分类 分层 有层次 有系统性理解 测试。 当前我是测业务组合 还是测前端交互 还是测接口 还是测落地数据。
要分的清,拎得清。 不要混为一谈,要对这个数据的整个处理流转的细节梳理清楚,前端干啥了 服务接口干啥了 落地数据干啥了,分层次 分流程 分门别类的 去检查各自的 ” 输出” 输出就是检查上一个节点输入正确的 “预期结果” 分层的测完一整套 每一层的输入 输出 很明确。 用例写的也会有层次感 ,好摘的开,以后也好维护。 比如 你判断准确了 就是前端 Js 没做输入规则业务规则控制,那么在用例的 前端输入 这一块 你只需要改这一块就行了,如果发现是,构造绕过接口了,接口的输出 落地数据产生了非法数据,那么就是接口层没对前端提交的数据做出一些校验,这个问题在用例维护里只需要改 接口输入 这一块 就够了。这种 业务思维 加 技术实现分层思维 不断的找类 找层次 找输入输出的思维 你要不断加强 强化 然后就会越做越顺,看问题就越会有努力的方向,问题类型缺陷类型就会越定位越准确,直接找到解决的开发角色。提高缺陷解决效率。 这个前提就是用例设计的好坏来决定的。
2 减少组合 具体思维 你可以参考 判定表因果图法 相关的理论讲解里的 如何去掉重复的 列 的方法,有具体业务规则 可以去掉,
具体的逻辑规则限制,可以去掉,和其他许多 技术限制 比如数据类型 大小限制 导致一些数据根本不可能产生。 就这样去掉。
或者 你看 图例 用例设计参考文件里的 业务需求 和技术实现 里有什么 可以去重的条件拿来去掉重复。3 好的用例 就是 我图里 列的 “满足特性” 你写的用例 具备了这些特性 就基本上 合格了、
-
感觉这里堕落了 at 2020年04月01日
老用户之一,当初我也挺活跃,现在主要是照顾家庭和在准备转行的事情……
Me too 了 。哈哈,一起一起。 我还鼓捣过你的 github 项目。 -
httpclient 处理多用户同时在线 at 2020年03月30日
@Fhaohaizi 你搬家呢?
还是 下来了 有时间创作了
-
陪产假这些天我买的硬件装备 at 2020年03月27日
@codeskyblue 我怀疑你在 “直播带货”,可是我没有证据
-
一起聊聊到到底什么是 bug?是不符合需求?还是用户体验? at 2020年03月26日
https://testerhome.com/articles/16966
@frzyq可看看 这个 缺陷类型 的分类 要清楚 有什么样的缺陷。 这样做缺陷统计分析 缺陷分布柱状图 就可以兑当前系统 软件 或 服务 质量做出评估。
角度 维度不同 分类也不同 我文中有分析。主要是 技术实现类缺陷 业务需求类缺陷。 这是一个维度
可以再上边两个维度上 往里塞。技术实现类的 可以按 三层结构 前端 服务 数据库 来分别界定各自层级结构下的缺陷。 如上 缺陷分类好了 柱状分布图 更能真实反映 软件质量。
比如 前端 下的 子缺陷问题类型 问题多了 说明当前 前端开发人员 实现质量不高。
服务 接口 类的问题多说明 服务接口开发人员 逻辑问题多 接口问题多 实现质量不高。
数据类的 多了 说明 服务 问题多 质量不高。
你可以 在三层下 细分问题类型 这样越做越细 你对 缺陷定义的越准确 说明你对 缺陷的理解越深 对当前系统技术实现的细节 理解的越深 脑子里有层次感 有系统感
就像一个 机械表 它内部的运行机理 组成构成 都 透明的 如庖丁解牛, 十分清晰.哦 另一个 层面 就是 你要对 缺陷问题 赋予 重要程度 是什么程度的缺陷 阻碍 致命 重要 次要 轻微。
比如 致命 的 数据 尤其是 落地数据类的 错误 比如 订单 钱包 里的某个字段 错了 那肯定是致命的。你说的那个 应该是 次要 有解决处理办法 属于 运营人员配置错误 导致的前端 用户问题。 这个应该加强 对运营后台的培训 或 逻辑限制 防止他们用错。
-
JMeter - 创建可重用和模块化的测试脚本 at 2020年03月26日
-
JMeter - 用好测试片段 Test Fragment 创建可重用和模块化的测试脚本 at 2020年03月26日
用好 jmter 的这几个概念 就可以做到 分层 分类 各层之间耦合度低
我们内部 约定了个 用 Jmter 的目录规范 主要就是 步骤 用例 和 场景
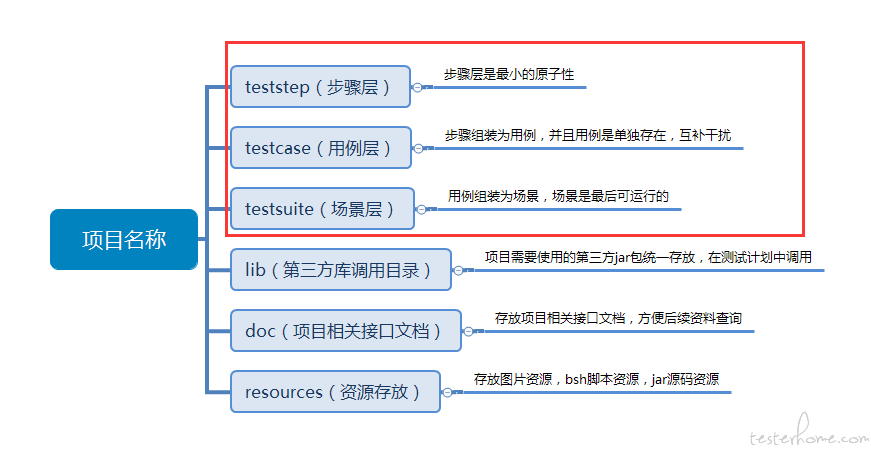
按照此约定 该去哪层写的去哪层写 核心和基线是 step 和 case 层 场景只是做调度和组装 。
步骤 step 是最原子性的
步骤层举例Tips:1、步骤层里面互不依赖,如果模块很多可根据模块名创建文件夹来分类保存。
2、步骤层的测试计划命名为步骤,通过 Test Fragment 这样的测试片段来进行包含。(建议 Test Fragment 名称和整个步骤的 jmx 文件名称保持一致,方便查询)。
3、步骤层根据具体业务需求来切分,可以是单独一个 sampler 或者多个 sampler 组合,而且一般会使用事物控制器包含。(如果 sampler 里面的变量需要传递使用 vars.get 方法获取,里面有变量需要提取也是同步进行)。
4、为了接口测试严谨性,一般步骤层,会跟随 sampler 绑定这个接口的必填参数测试的简单控制器,方便阅读。(必填参数测试:缺失必填参数后,接口返回值是否正确)。
用例层举例
Tips:1、用例层里面只调用步骤层来进行组装,不添加任何 sampler。
2、用例层一般会使用 Parameterized Controller 插件来对步骤层进行参数传递,一般需要和步骤层绑定。如果需要再获取上级参数传递可写为变量
3、用例是独立存在的,用事物控制器进行包含,由于 JMeter 本身的特性,需要在场景层中组合的话,也只能存放为 Test Fragment 给与调用。
4、用例名称中,事物控制器,测试片段,jmx 文件名称尽量保持一致,方便查找。
场景层举例
Tips:1、场景层是由线程组通过 Include Controller 调用 Test Fragment 的测试用例来直接运行的 jmx 文件,也是最后输出的报告展示结果。
2、所有用例都需要使用的变量可以在场景层存放,比如用户账户数据,数据账户密码,APPID,AppSecret 等,如果不需要在场景层使用可以在用例层进行传值覆盖。
3、场景层中的用例没有依赖关系,可以顺序或者乱序组合,互不干扰。
-
ui 自动化需要做数据准确性验证吗? at 2020年03月20日
总体来说 是要对数据进行验证的。
绝对而言 如果 软件工程质量好的话 我意思是 比如 你们的业务测试质量很高, 那么 我们所做的 UI 自动化 就是个 分层测试的概念
尽量把问题 集中到 UI 界面上 而不去关注接口 或 数据库数据的 验证。 或者 前提面向 UI 自动化 初始化或构建好了 UI 页面场景依赖的数据, 重度把问题集中到对 UI 界面的 验证上来。 这种情景 就不太需要 对接口或数据库数据验证。另一种 情况 就是相对的, 比如 你们的业务测试质量不高 一些接口 或 数据落地验证 不准确。 那么你可能 就需要 对 页面接口返回的数据 或 响应 做一些面向业务规则的断言 或者需要访问数据库 对如表单提交类的 做落地数据断言。 这就有点违背 UI 是一种分层测试的概念 战线扯的有点长了, 但没办法 国内或大多数全球企业 都是这样。
所以 业务测试是基石 , UI 自动化 是辅助 不要为了 UI 自动化而自动化 前提是你业务测试质量标准到了你要明确 你 UI 自动化要解决的是 哪个端的问题 要重度面向 UI 适配 系统碎片化兼容 和前端问题 来精准。 否则就 会有点扯的长 做了业务测试验证的活。
-
性能测试这个行业里有哪些做的比较好的专家 at 2020年03月20日
性能测试 面很大啊 你这个问法不具体 指代不明 个人理解有以下性能维度
一 服务性能测试
啥是黑盒性能,就是指 以业务处理性能为指标的 性能测试 比如 lr 或 jmeter 通过接口 对整个业务服务系统 试行压力 等各类型的测试,关注的是 业务处理指标 如 每秒事务数。 可以不关注被压测服务系统的中间件 服务组件的性能,如 tomcat nginx 啊 等,此类测试主要是 业务性能测试人员做 市面上大多数搞性能测试的 此类居多 。
那么 这类可以归为 面向业务处理性能的 性能测试。 关注指标 有
1.1 业务处理性能 或者说 把这类 归为 服务性能测试工程师 或者 我把他定义为 黑盒性能测试 重度面向业务处理性能(捎带着监控了服务中间件)
1.2 服务组件 中间件性能 这种 如果 上一步 1.1 面向黑盒的指标通过的话 就可以重度分析 组件和中间件性能指标了 用专业的运维分析工具 分析定位
比如 目前流行的 grafana 或 zabbix 这类 都算
1.3 数据库 DBA 类的 性能调优 SQL 优化 本来是可以归到 1.2 的 但实际 目前处理这类优化的角色 一般都是 DBA 在做二 前端性能测试
2.1 传统的 前端 web h5 性能调优 比如 devtools 谷歌 yslow 或 pagespeed 前端性能调优标准来 也可以把 APP 里的 H5 啊 这类的归此
2.2 APP 类的 native 类的 APP 的 性能调优 ios android 前端类的三 一般是运维工程师做的 硬件性能测试 和 服务组件性能测试
2.1 服务器硬件上架前的 硬件上架标准测试 主要对硬件 cpu mem IO 等做硬件压测 有各类专业工具
2.2 部署服务组件 中间件 的上架标准测试 主要对 nginx tomcat 等 做 性能压测 也有各类压测工具命令行 或 其他工具平台
这类 基本 不关注业务处理性能指标 关注 比如 cpu mem IO 的一些硬件资源处理性能 或者 是 中间件 类的 处理性能 和业务无关的 处理性能四 最后 可能就是 纯白盒性能了 直接阿里多隆 级别的 直接看代码 调优性能
-
JMeter - 用好测试片段 Test Fragment 创建可重用和模块化的测试脚本 at 2020年03月20日
https://testerhome.com/articles/18485
看这篇,你就明白了。 -
测试用例很基础,但是否真的重要? at 2020年03月04日
-
接口之间耦合关系比较强的话怎么组织 JMeter 脚本可以有效减少后期不断迭代带来的脚本维护工作量? at 2019年08月05日
@CelebrateMeaningless https://testerhome.com/articles/17038
https://testerhome.com/articles/18485
https://testerhome.com/articles/18525用好 jmter 的这几个概念 就可以做到 分层 分类 各层之间耦合度低
我们内部 约定了个 用 Jmter 的目录规范 主要就是 步骤 用例 和 场景
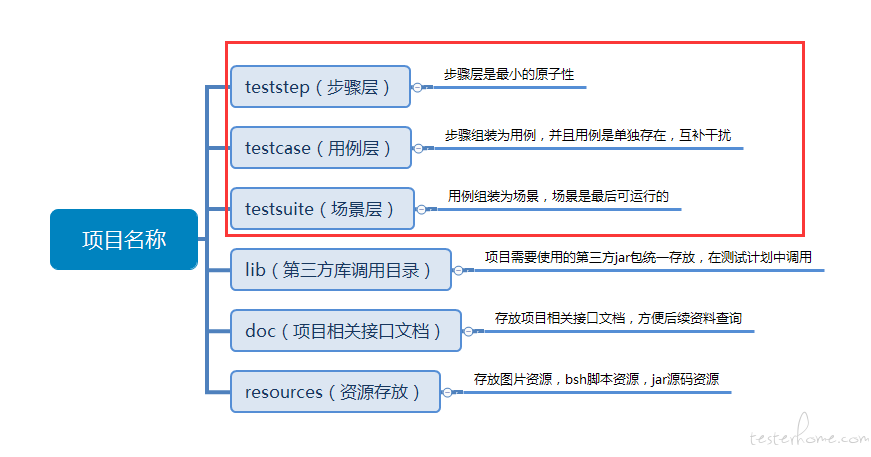
按照此约定 该去哪层写的去哪层写 核心和基线是 step 和 case 层 场景只是做调度和组装 。
步骤 step 是最原子性的
步骤层举例Tips:1、步骤层里面互不依赖,如果模块很多可根据模块名创建文件夹来分类保存。
2、步骤层的测试计划命名为步骤,通过 Test Fragment 这样的测试片段来进行包含。(建议 Test Fragment 名称和整个步骤的 jmx 文件名称保持一致,方便查询)。
3、步骤层根据具体业务需求来切分,可以是单独一个 sampler 或者多个 sampler 组合,而且一般会使用事物控制器包含。(如果 sampler 里面的变量需要传递使用 vars.get 方法获取,里面有变量需要提取也是同步进行)。
4、为了接口测试严谨性,一般步骤层,会跟随 sampler 绑定这个接口的必填参数测试的简单控制器,方便阅读。(必填参数测试:缺失必填参数后,接口返回值是否正确)。
用例层举例
Tips:1、用例层里面只调用步骤层来进行组装,不添加任何 sampler。
2、用例层一般会使用 Parameterized Controller 插件来对步骤层进行参数传递,一般需要和步骤层绑定。如果需要再获取上级参数传递可写为变量
3、用例是独立存在的,用事物控制器进行包含,由于 JMeter 本身的特性,需要在场景层中组合的话,也只能存放为 Test Fragment 给与调用。
4、用例名称中,事物控制器,测试片段,jmx 文件名称尽量保持一致,方便查找。
场景层举例
Tips:1、场景层是由线程组通过 Include Controller 调用 Test Fragment 的测试用例来直接运行的 jmx 文件,也是最后输出的报告展示结果。
2、所有用例都需要使用的变量可以在场景层存放,比如用户账户数据,数据账户密码,APPID,AppSecret 等,如果不需要在场景层使用可以在用例层进行传值覆盖。
3、场景层中的用例没有依赖关系,可以顺序或者乱序组合,互不干扰。
-
功能性测试用例设计方法深入理解 at 2019年07月25日
图中 “用例分层” 和 “用例设计共性步骤” 再好好看看。
先把需要被测试设计的 “测试对象” 找明白喽。
啥是狭义的 “业务流” 就好比 A 注册 B 登录 C 搜商品 D 下订单 E 支付 A B C D E 就是业务流 不同的组合序列就是业务流了。 他的逻辑对象 就是 你们平台的 各种大类 “功能” 他的物理承载对象 就是 各种 功能页面 比如 注册页面 下订单页面 支付页面等。
啥是狭义的 “操作流” 就是 站在用户角度 去做交互体验测试 就是在某个具体的 功能性页面 做页面操作的序列 比如 注册页面
用户要操作 各种 输入行控件 和 各种展示型控件 他们之间有逻辑 和 业务规则制约关系 和交互效果要求 这些都是逻辑对象关系 所以 把一个页面中的输入型提取出来 比如测试 注册输入控件 就是 账号 密码 确认密码 邮箱 手机 这些就是 物理操作对象 找到了他们 才可以用 因果 判定表法 去设计组合序列。啥事狭义的数据流 就是 具体的输入型控件或数据 他们找到了 比如 注册 就要根据业务规则 和各种逻辑限制关系 去用 等价和边界值了
所以 图中的概念 是具体分层到某一个层内 一个概念内 是狭义的 但广义上来看 这些方法 是可以在其他层通用的 所以不要玩死这些设计方法。
所以 共性的步骤 都是 找测试对象 和 设计组合序列 然后等价边界设计取值策略 你先要看的请 你的测试目标是啥 你目前处在哪个层在测试 然后分别用好测试用例设计方法。
以上都是 站在 比较通用的 黑盒设计策略 从功能来展开 属于比较常用的业务测试方法
实际 还要站在 系统技术实现层 来继续优化深入用例 比如 要站在 三层结果 前端 服务 和 数据 从系统大的这些层 去再优化用例。
弄清 服务处理流 和 数据流 做到 全生命周期性的系统测试设计。 -
TesterHome 专栏功能小范围测试啦! at 2019年06月04日
-
TesterHome 专栏功能小范围测试啦! at 2019年06月04日
-
教您完美 win10 安装 Appium1.7.2 支持 win 客户端自动化 at 2019年05月05日
https://github.com/appium/appium/issues/12269#issuecomment-489378179
升级 appium-doctor 到 1.10.0
系统环境变量 PATH 添加 bundletool.jar 存放路径 如: D:\Android\android-sdk\bundle-tools
系统环境变量 PATHEXT 追加 ;.JAR 即可 -
Jmeter 的性能监控框架搭建记录 (Grafana+Influxdb+Telegraf) at 2019年04月18日
配置 Jmeter BackendListerer 沒配对 influbdb 对应的记录 db=jmeter 的库 就没这些
-
乐信集团 (原分期乐) 招人啦,各位大大们快到碗里来 at 2019年04月16日