-
大家股市挣钱了没 at 2024年10月08日
0.01 个小目标

-
playwright 中使用 xpath 定位元素遇到的奇怪问题 at 2024年06月22日
不是万不得已,就放弃 xpath 定位吧,你这写法没有任何可读性啊
-
pytest+request+allure 接口自动化框架搭建分享 at 2024年05月27日
我之前也是通过录制来生成 api case,然后根据需要改改就成,之前分享过,跟这位楼主的标题都极度相似哈
-
UI 自动化基于 playwright 开发的框架,playwright 的 1.33.0 版本是可以正常运行。但是 playwright 版本升级后(最新版 1.43.0),框架无法运行 at 2024年05月18日
pip 升级 playwright 后,没有执行 playwright install 升级浏览器吧?这样可能会导致你描述的问题。
-
playwright 在 Centos 的安装和问题处理 at 2024年05月10日
不错。
我遇到这样问题的话,大概率是直接换到 ubuntu,或者在 centos 上用 docker 跑 playwright
你这样处理,后续随着 playwright 的升级,没准还会碰到其它问题 -
一个 UI 自动化问题咨询 at 2024年05月09日
我估计最大的可能是浏览器驱动与浏览器版本不完全匹配。
对于 selenium 来说,有时驱动版本落后一点也能用,但如果落后太多就会出现各种幺蛾子现象,建议始终保持最新,或者禁掉浏览器的自动升级,省的出现兼容性问题。 -
其实还没有,只能说生活简单,暂时还有的花
-
每家产品的登录逻辑都是不同的,没法通用。
楼上回答的已经很好,请参考,通常是根据登录接口的返回,再往 session 的 header 写入一个或两个字段。 -
抱歉,没有专门搞过 ios
之前更多的时间是搞反病毒,HIPS,系统备份还原等客户端,后来搞过一年多的 Android,最近六七年是在搞 SaaS 系统。 -
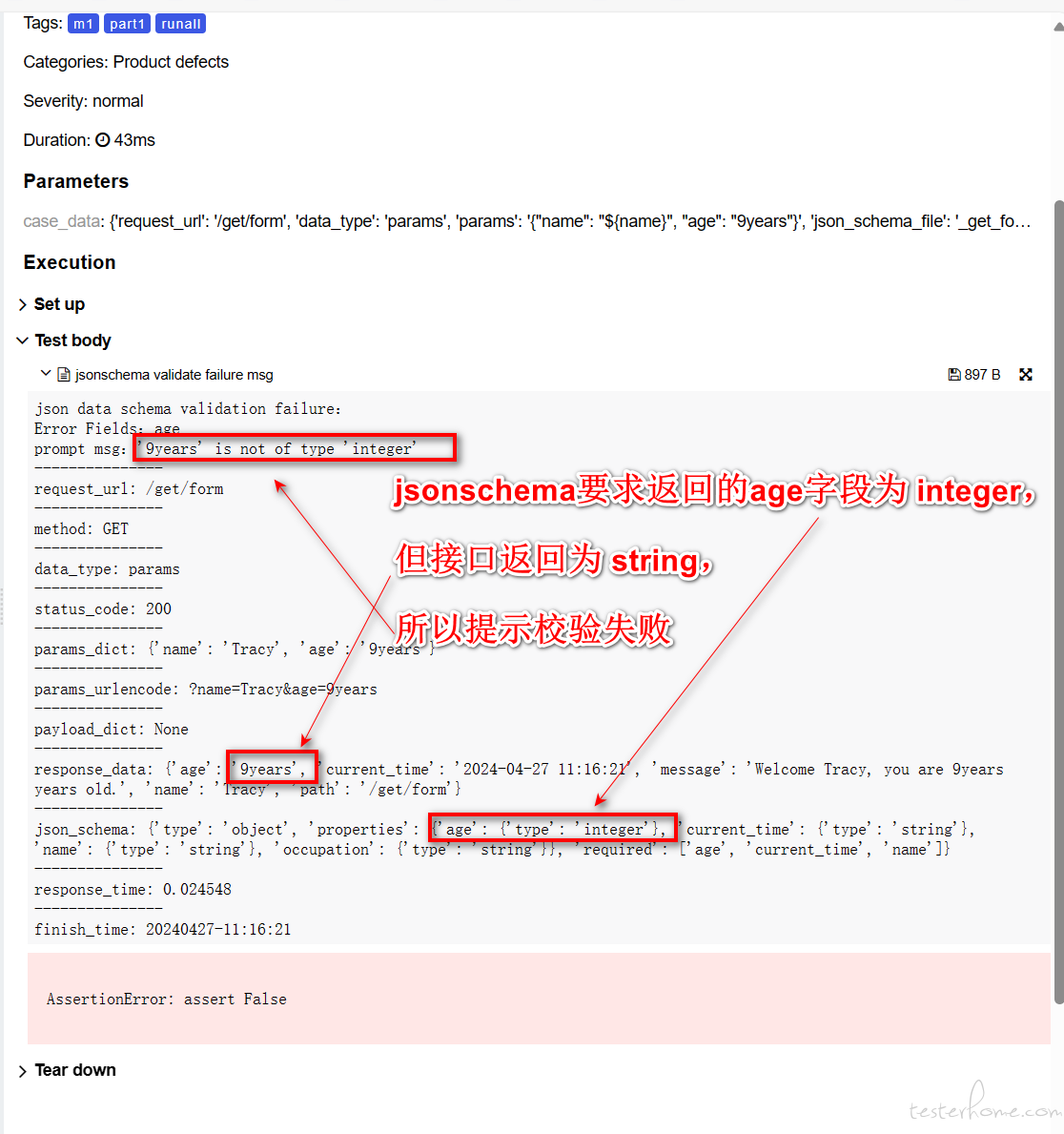
python 做接口测试时,如何在 pyhtml 报告中为每个用例贴上请求 url 和请求参数,结果信息 at 2024年04月27日
我之前写的框架 https://testerhome.com/topics/39660 ,可以在报告中展示这些, 请看截图
-
再补充下我为何选择用 csv 来存用例,而不是用 json,yaml 和 Excel?
这首先排除的是 Excel,不是纯文本,不方便做版本比较。yaml 和 json 方式不大方便组织用例顺序,对于有相互依赖的尤其不便。另外插入删除,批量编辑也不便,综合比较下来还是觉得 csv 最方便,一目了然。 -
嗯,这是我大约三年前写的,胜在简单易用,效率高,运行速度快,查看结果比较方便。基本上略有 python 基础的小伙伴,用不了一个小时,就能掌握可自行写新模块的接口自动化 cases 了。
-
非也,非也,我没在长亭呆过
-
【远程办公】Bifrost 招聘⾼级测试⼯程师 at 2024年04月26日
从这待遇上看,行情确实很惨淡啊
-
基于 Pytest+Requests+Allure 实现接口自动化测试 at 2024年04月25日
你这显然是 allure 没有安装配置号好
-
【北京】快手 - 商业化技术部 招聘 测试开发工程师(面试快) at 2024年04月18日
必然会啊
-
UI 自动化测试平台 at 2024年04月02日
这样的 UI 自动化平台见过一些,但说到好用的是一个都没有,还是自己撸代码来的方便。
-
【北京】快手 - 商业化技术部 招聘 测试开发工程师(面试快) at 2024年03月29日
JD 要求真不高
-
【UI 自动化】Playwright 中元素定位问题 at 2024年03月29日
看你代码是正常的,没按预期工作应该还是定位不精确的问题,看你截图定位在了一个看不见的元素。
可以在这里打个断点,进入交互模式,先确定所在的 iframe,再遍历所有的 checkbox, 可以用target_frame.locator('#isCheck').highlight()来高亮显示定位的元素,如果还定位不到就改方法。有个似乎更方便的办法是在执行到 page.pause() 时,用自带的 inspector 来帮忙
-
burpsuite+xray 实现联动测试 at 2024年03月28日
xray 是长亭的产品,当前并没有开源
-
burpsuite+xray 实现联动测试 at 2024年03月26日
这相当于浏览器的请求先到 burpsuite,再到 xray,再到目标服务器
-
经历人生第一次被裁,15+ 年的测试经验,有招测试的或者管理的吗? at 2024年03月26日
你才 15+ ,我 19+ 呢
-
【UI 自动化】Playwright 中元素定位问题 at 2024年03月26日
你代码的最后一行,target_frame.locator('#isCheck') 大概率是匹配到了多个元素,其中第一个还是隐藏的,所以操作不了。 可以尝试在这一行之前,print(target_frame.locator('#isCheck').count()) 检查下匹配的元素个数来确认下。 另外如果只匹配可见的元素,可以这么来匹配 target_frame.locator('#isCheck:visible') 加一个 ":visible"
-
好奇。国产数据库的底层是基于什么开源架构或标准或协议去实现? at 2024年03月14日
当然不是,有很多种不同类型的 DB
-
【UI 自动化】Playwright 中元素定位问题 at 2024年03月14日
看截图, .locator('#isCheck') 匹配的第一个元素是隐藏的,不是你想要的那个复选框,所以问题还是你的定位有为题。