还是上次的问题https://testerhome.com/topics/43220DB 的连接池满导致的内存暴涨。但是实际上这个病症却存在这千丝万缕的问题。比如说,,上次其实已经确定到了是
1、到底现有的配置多少并发会导致 db 连接池打满?
2、db 连接池打满是什么样子?
3、我已经配置了弹性伸缩,也就是内存达到 80% 就应该要新启动一个实例,一起扛流量,为什么没有效果?
4、为什么没有出现故障转移?内存打满了,按道理应该转移到新的实例
5、如果流量真的大,配置实在撑不下怎么处理?
反正很多问题,总感觉搞研发的就像医生,遇到一个病例就需要去根据数据去分析病因,只有这样才能从根本上治愈。而如果只是片面的经验有时候可能不准,所以这是我不太相信中医的原因。
要想排查和解决这些问题,必须要能复现问题。最简单的就是把 db 的连接池调低,我设置 20。
然后压测。压测配置可以借鉴https://testerhome.com/topics/43010。
顺便介绍下我的服务配置:
部署是用云的 K8S
NiMail.cn 的 A 业务接口服务 0.3 cpu 0.5G
NiMail.cn 的 B 关联服务(A 需要调用 B 去查询数据)0.3cpu 0.5G
mysql(4c 8G)压测没有压力,也就是链接并没有全部进来
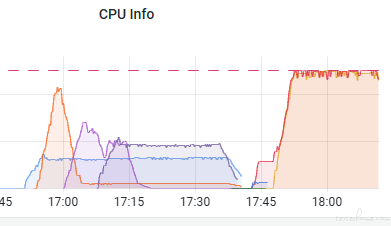
压测发现,只要一跑,内存就会爆炸。B 服务打日志发现,mysql 的链接状态是跑满,等待数量爆涨,sql 语句耗时大部分都很长 十几秒 上百秒;
B 服务长时间没有响应,导致 A 服务也内存上涨。这个现象可以解释上述问题 2 的情况。估计大部分系统都是这样的,当然如果设置了超时就会出现大量报错,下面会提到。
从服务伸缩看,确实会新起一个示例,但是并没有走新实例。也就是新的实例没有接收到流量。。。
通过各种分析,最终能够确定:K8S 的 service 只是类似 dns 效果,对于长连接来说没有负载均衡和故障转移功能支持。所以要能实现上述问题的 3、4,必须得改。于是我改造了下,策略是,负载均衡和故障转移我这边中间件实现,然后 service 改成 service headless 可以获取多个 pod ip。然后定时去检测 IP,中间件实现故障转移。改动是有点大,反正是自己的项目,随便折腾了。
继续压测发现,一个 pod 打满内存,新起一个新 pod,然后马上又打满,又新起来一个 pod 。。。其实这个现象是正常的了,至少 3、4 的问题是解决了。
那到 1 的问题了,到底配置多少并发才能打满呢?我就按这样的数据跑,从 5 个并发开始,每次叠加 5 个,最终感觉差不多是 20 左右,也就对应 db 的连接数。其实这里应该要看业务,我这个是直接查 db,所以每个请求都会 sql 查询,有些有缓存的那就会大很多很多,这里是经验哦,有些业务复杂,各种 SQL,那这样会低。最终还是要归于业务。这样我就调到 400,然后启动 2 个 pod,也就是一起 800,直接压,然后看数据
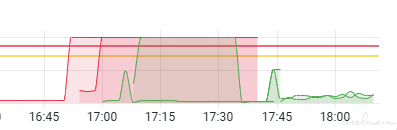
跑到 1000 也是正常的,资源没有起来,两个资源都很稳定和占用较低。查看接口的错误率是 0.4%,应该是比较符合要求了。
还有一个是问题 5,如果流量真的大了,怎么处理。这个问题我还没解决,但是看别人说是限流、设置超时时间。超时时间我也在 A 的中间件中进行配置,但是当流量大的时候发现大量的超时报错,接口失败率非常高,而且 sql 的执行还是有很多耗时挂在那。感觉不是很理想,应该还是要在 SQL 那边也配置查询超时时间,直接退出掉。目前这个实践还没有搞完,这一轮下来东西太多了。限流的话也还没做,因为感觉要找一个好的策略,比如页面刷新可能有 3 个请求,如果限流限制其中的一个,剩下两个只要其一被限制了页面功能一样用不了,一样影响全部用户。最好的策略是影响部分用户,而另外一部分可以使用。
慢慢摸索吧!

 很好的实践
很好的实践