
测试开发之路 AI 提效:编写性能测试的 skills 实战
skill 概览
我们先看一下这个 skill 的目录结构:
.codebuddy/skills/perf-test/
├── assets/ # 测试数据文件
│ ├── apps.json # 应用数据
│ ├── perf_docs_list.jsonl # 文档列表(压测用)
│ ├── shared_kbs.json # 共享知识库数据
│ ├── spaces.json # 空间数据
│ └── test_full.json # 完整测试数据
├── references/ # 参考文档
│ ├── api-notes.md # API 接口说明
│ └── locust-cookbook.md # Locust 使用手册
├── scripts/ # 脚本文件
│ ├── common/ # 公共工具模块
│ │ ├── __init__.py
│ │ ├── asset_store.py # 资产存储管理
│ │ ├── batch_runner.py # 批量执行器
│ │ └── cli_utils.py # 命令行工具
│ ├── add_users_to_space.py # 添加用户到空间
│ ├── create_apps.py # 批量创建应用
│ ├── create_shared_kbs.py # 批量创建共享知识库
│ ├── create_spaces.py # 批量创建空间
│ ├── create_users.py # 批量创建用户
│ ├── gen_doc_variants.py # 生成文档变体
│ ├── locust_create_users_and_join_space.py # 压测:创建用户并加入空间
│ ├── locust_describe_space_list_perf.py # 压测:查询空间列表
│ ├── locust_list_app_perf.py # 压测:查询应用列表
│ └── locust_list_shared_knowledge_perf.py # 压测:查询共享知识库列表
└── SKILL.md # Skill 说明文档
- SKILL.md : 整个 skill 的提示词,用来指导 skill 执行,一般来说要把 skill 详细的工作流定义在里面
- scripts 目录:为 skill 准备的脚本,因为我们不能每次都让大模型自由发挥,通过与大模型进行历史对话,我们有过多次比较靠谱的执行方案。所以我们需要让大模型把当时靠谱的方案落地成脚本,这样以后重复执行的时候,就可以稳定且正确的执行,这一步至关重要。
- references 目录:执行任务的参考文件,SKILL.md 主要定义工作流,而如果需要他动态生成一些代码,文档,或者执行具体任务,则需要到这个目录下的文件进行参考。可以说这个目录下的文件是执行任务的具体的手册, 我通常叫它 cookbook,它同样至关重要。而在本案例中,我主要保存了编写 locust 脚本的手册。这个后面会给大家展开看。
- assets 目录:翻译成中文叫资产,其实就是保存 skill 运行时产生的临时和结果文件。
这个 skill 的第一个提示词:
我希望编写一个skill。 项目背景:在私有化项目中经常有在客户的要求下进行性能测试的需求。为了完成这个性能测试的需求,需要事先造一些数据进行准备。并且可能每个客户的需求不固定,所以我希望一个可以灵活按客户需求造数据并生成压测脚本的skill。
常用的造数据需求:
1. 工作空间:需要事先创建多个工作空间。支持指定账号
2. 应用:支持指定账号和某个或者某些空间,创造足够数量的应用。
3. 支持给定一个主账号,创建多个子账号。
4. 支持给定一个空间和这一些账号, 把账号拉进这个空间。 为了实现这样的需求, 我希望这个skill先创建一些原子性的脚本:
1. 创建工作空间的脚本,参数是账号信息,和空间的数量。 脚本要把创建的所有空间id记录在一个json文件中。
2. 创建应用的脚本。参数是账号信息,空间id和应用数量。
3. 创建用户的脚本,给定主账号信息和创建的用户数量,并且把用户的信息记录在一个json文件中
4. 创建把用户加入到空间的脚本,给定空间id和用户数组,执行的时候需要使用之前记录下来的空间id和用户id
为了执行批量创建用户和把用户加入到空间中。我们有两个接口,使用curl的调用方式如下:
curl -X POST https://341dev.adp-private.com/cgi/capi\ -H "Authorization: TC3-HMAC-SHA256 Credential=de1b1bde9fe44d3eab4e2fab59/2026-03-20/ihava/tc3_request, SignedHeaders=content-type;host;x-tc-action, Signature=e8201c8698dd634eb3c046a87e92995a2d29f35fae8f9abc684947c44806f188"\ -H "Content-Type: application/json; charset=utf-8"\ -H "Host: 341dev.adp-private.com" -H "X-TC-Action: AddUsersToSpace"\ -H "X-TC-Timestamp: 1773995396"\ -H "X-TC-Version: 2023-11-30"\ -H "X-TC-Region: ap-guangzhou"\ -d '{ "regionId": 1, "serviceType": "ihava", "cmd": "AddUsersToSpace", "data": { "Accounts": [ "bruce-2" ], "SpaceId": "default_space" } } '
curl -X POST https://341dev.adp-private.com/cgi/capi\ -H "Authorization: TC3-HMAC-SHA256 Credential=de1b1bde9fe44d3eab4e2fab59/2026-03-20/ihava/tc3_request, SignedHeaders=content-type;host;x-tc-action, Signature=9c80e4ff96d42673ba6b371d9b3db3686d73dcb27cbd7b65eeb024b93b82b2ef"\ -H "Content-Type: application/json; charset=utf-8"\ -H "Host: 341dev.adp-private.com" -H "X-TC-Action: AddUsers"\ -H "X-TC-Timestamp: 1773990975"\ -H "X-TC-Version: 2023-11-30"\ -H "X-TC-Region: ap-guangzhou"\ -d '{ "from": "", "token": "", "regionId": 1, "serviceType": "lke", "cmd": "AddUsers", "data": { "CName": "批量创建账号", "Pwd": "ezPrHWet3O483X0fJlz1m2MY7ly/gDZy1BAK5ukb6iK9muhNyLCk5jEdc2RrlLhxk9+dm12oNZwWr9XqGfMuXfHuwkvb0rUpYG7Brvvrfkj5Mqz0H4gHWeSvMKjfBD7EMFjCJoOkGrsFV5uFWDl69d1NqSWoCUcOWVuXfrzXf/lgHebAnyRAcsRj1BJfn7DsgZvP77B+rybeciJE/uVbKaJo38I8E2mxK6hMOmM2dJAbud3hams4mZHHFlcwH6mBfQUJZ0/lOp2soBQnrj/4MAxg2YPQ/QRt5lEzFKV4ota1+cXs5tREeHo1dz6/7rJpj78pClBBF/5QiHmLpU/71A==", "Account": "bruce-2" } } ' 我
希望你结合现有的代码,创建这四个脚本。后续使用上, 用户会说明要造什么要的数据,多少个空间,多少个应用等等信息,到时候你需要调用这些脚本来完成用户的需求
第一个提示词主要为压测做一些数据准备。因为我十分确定需要四个脚本来准备压测数据,所以直接让大模型先生成这四个脚本。而它产生的 SKILL.md 如下:
---
name: perf-data-prep
description: This skill should be used when users need to prepare private-deployment performance-test data by batch creating workspaces/apps/users and adding users into spaces with reusable atomic scripts and JSON asset chaining.
disable-model-invocation: false
---
# 私有化压测数据准备 Skill
## 使用时机
- 需要在私有化环境做压测前数据准备
- 需要按指定账号批量创建工作空间
- 需要按账号+空间批量创建应用
- 需要批量创建子账号并落盘用户信息
- 需要批量将账号加入指定空间
## 能力边界
- 本 skill 提供 4 个原子脚本,支持串行或按需组合调用
- 脚本结果会写入统一 JSON 资产文件,便于后续脚本复用
- 脚本内部复用仓库现有 `Service/API`,不手写签名或明文密钥
## 目录与脚本
- `scripts/create_spaces.py`:批量创建空间并记录 `SpaceId`
- `scripts/create_apps.py`:在指定空间批量创建应用
- `scripts/create_users.py`:批量创建用户并记录用户信息
- `scripts/add_users_to_space.py`:批量把用户加入空间
- `scripts/common/asset_store.py`:统一资产 JSON 读写
- `scripts/common/cli_utils.py`:命令行参数与输入解析
- `scripts/common/batch_runner.py`:批量执行、重试、节流
## 资产文件约定
默认资产文件可放在 skill 目录下(或通过参数覆盖):
- `spaces.json`
- `users.json`
- `apps.json`
统一结构(示例):
{
"run_id": "20260324_143501",
"spaces": [],
"users": [],
"apps": [],
"failed": []
}
## 推荐执行链路
1. 先建空间:`create_spaces.py`
2. 再建用户:`create_users.py`
3. 把用户加到空间:`add_users_to_space.py`
4. 在空间建应用:`create_apps.py`
## 调用示例
python3 .codebuddy/skills/perf-data-prep/scripts/create_spaces.py --account Master_Default --count 5 --output .codebuddy/skills/perf-data-prep/assets/spaces.json
python3 .codebuddy/skills/perf-data-prep/scripts/create_users.py --account Master_Default --count 20 --user-prefix perf_u --password-encrypted <加密密码串> --output .codebuddy/skills/perf-data-prep/assets/users.json
python3 .codebuddy/skills/perf-data-prep/scripts/add_users_to_space.py --account Master_Default --space-id <space_id> --users-file .codebuddy/skills/perf-data-prep/assets/users.json --output .codebuddy/skills/perf-data-prep/assets/membership.json
python3 .codebuddy/skills/perf-data-prep/scripts/create_apps.py --account Master_Default --space-ids <space_id1,space_id2> --count-per-space 30 --app-prefix perf_app --output .codebuddy/skills/perf-data-prep/assets/apps.json
## 参数设计原则
- 数量参数均为正整数
- 所有输入支持“命令行直传”和“从资产 JSON 读取”两种方式
- 支持 `--run-id` 以实现多批次可追踪
- 支持 `--retry`、`--interval` 控制重试与节流
## 故障处理
- 每次 API 调用均检查 `Response.Error`
- 失败项写入 `failed` 数组,不吞错
- 总结输出成功数/失败数/关键失败原因
## 安全要求
- 不在日志中输出明文密钥、密码
- 用户创建脚本仅接收外部传入密文密码串,不做明文加密
- 复用 `BaseApi.do_req_by_env` 做签名与环境路由
## 参考
- 详细接口备注见:`references/api-notes.md`
这里需要注意的是:
- 我当前正在我们的自动化测试项目中编写这个 skill,所以很多知识已经保存在项目中了。比如创建空间,应用的接口已经在项目中编写过,大模型通过检索可以自动检索到。 而我得提示词中给出的两个接口的调用方法,这是因为这两个接口还不存在于项目中,所以需要在提示词中给出。
这时我测试一下结果如何,当我用自然语言对大模型说,我需要创建 5 个工作空间的时候:
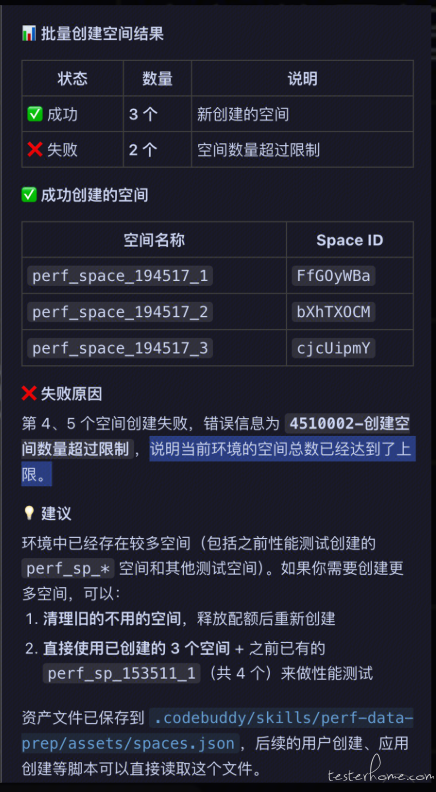
可以看到,效果还不错,报错后它还能告诉我错误原因。除了 skill.md 文件外,scripts 目录下也保存了多个 python 脚本,用来在以后随时能完成这样的需求。
我们接下来的工作是通过一次又一次的对话,完善这个 skill。比如在执行第 N 次对话的时候,我开始要他有能力动态生成不同场景的 locust 压测脚本。
第 N 次对话
现在私有化需求中,也有很多针对用户的临时的定制化需求, 需要临时组装脚本,并且要求一个脚本就包含了所有的依赖,不能依赖其他文件。 所以我希望你修改一下这个skills:
当用户说我要做性能测试的时候, 需要先说明是否需要做数据准备,如果用户没说, 你需要去询问。
当用户说组装一个性能测试脚本的时候,会说出自己的场景要求, 你需要现场编写一个locust脚本提供给客户。 并询问用户是否需要帮用户执行, 如果用户说需要,则用locust的headlees模式去运行。
为了能更准确的编写和拼装locust脚本,我希望你能先把一些常用的规范的接口调用和指标统计方式写成一个参考。 保存下来,这样后面可以更准确的参考编写locust脚本。 现在可以先参考 locust_standard_mode_perf.py 这里面有:
创建应用的接口(包含了重试)
上传文档并等待文档导入完成的接口
应用发布的接口
在用户端对话的方法
以上也都有相关指标的计算方法和上报到locust的方法。 我希望你能把这个脚本知识沉淀下来,保存在skill的文件里,用来以后进行参考。
好现在开始实现我的诉求吧。
上面的提示词就是希望大模型生成一个 references 目录下的 cookbook 了。 大家请仔细阅读一下这段提示词,从中我们可以看到在这样一个私有化的压测项目中,根据不同的用户,会有不同诉求的压测需求。 比如:
- 客户 A:我希望在有 500 个空间 1W 个用户的情况下压测查询应用和用户的接口。
- 客户 B:我希望压测智能体的知识问答对话场景,并统计 TTFT,吐字率等指标。
- 客户 C:我们的知识库非常庞大,我希望压测 2W 个知识库的情况,并上传 10w+ 的 PDF 文档。
- 客户 D:balbalbalbalba 等 N 多需求。
可以看到,在我们的项目中,压测场景是不固定的,不同的用户有不同的诉求。所以希望 skill 能动态的快速生成压测脚本给到用户场景下测试。这也是这段提示词的意义。 执行过后,大模型会生成一个初始的 cookbook 文件,而我们经过一轮轮优化和补充,目前我们的 cookbook 是这样的:
# Locust 压测脚本编写参考手册(Cookbook)
> 本文档从 `tool/pef_test/locust_standard_mode_perf.py` 中提取关键知识,用于指导编写**完全独立**的 ADP 私有化 Locust 压测脚本。
>
> **核心原则**:脚本必须一个文件包含所有依赖,不能 import 项目内其他模块。仅依赖 `pip install locust requests` 可安装的标准库。
---
## 目录
1. [脚本整体结构](#1-脚本整体结构)
2. [环境变量与常量配置](#2-环境变量与常量配置)
3. [基础设施层](#3-基础设施层)
- 3.1 TC3-HMAC-SHA256 签名
- 3.2 xxx API 调用封装(post_yun_api)
- 3.3 S3 V4 签名 + MinIO 上传
- 3.4 SSE 流式解析
4. [业务 API 层](#4-业务-api-层)
- 4.1 创建应用(带重试)
- 4.2 删除应用
- 4.3 获取存储凭证 + 上传文档到 MinIO
- 4.4 保存文档到知识库(SaveDoc)
- 4.5 等待文档导入完成
- 4.6 应用发布(创建发布 + 等待发布成功)
- 4.7 获取应用 AppKey
- 4.8 Chat SSE V2 对话(用户端)
- 4.9 查询应用列表(ListApp)
- 4.10 查询空间列表(DescribeSpaceList)
- 4.11 列举共享知识库(ListSharedKnowledge)
5. [指标统计与 Locust 上报](#5-指标统计与-locust-上报)
- 5.1 fire_success / fire_failure
- 5.2 TTFT(首 Token 延迟)
- 5.3 吐字率(tokens/s)
- 5.4 Token 统计(input/output/total)
6. [Locust User 编写模式](#6-locust-user-编写模式)
- 6.1 User 类基本结构
- 6.2 workflow 编排与步骤管理
- 6.3 步骤失败回填(backfill_skip_failures)
- 6.4 控制流异常处理
- 6.5 资源清理(finally + on_stop)
7. [运行方式](#7-运行方式)
8. [文件驱动数据压测(数据耗尽自动停止)](#8-文件驱动数据压测数据耗尽自动停止)
---
上面只给出了这个 cookbook 文件中,开头那部分的目录结构(因为源文件实在太大了,想要源文件的同学,可以在星球群里跟我要。)可以看到这里定义了各个指标的计算法方法,sse 协议的通信细节,接口鉴权,各个重要接口的调用 Demo,locust 压测的各种策略(6,7,8 条)。这些是 skill 动态生成 locust 脚本的关键信息,如果没有这些,让大模型每次自由发挥,那它天马行空的什么奇形怪状的脚本都能生成的出来。这样就不可控了。
经过 N 次调优后的 SKILL.md
---
name: perf-test
description: This skill should be used when users mention performance testing, stress testing, load testing, or benchmarking (性能测试、压测、压力测试). It covers the full workflow including data preparation (batch creating workspaces/apps/users), assembling Locust scripts, and running performance tests against private-deployment or cloud environments.
disable-model-invocation: false
---
# 私有化性能测试 Skill
## 使用时机
当用户提到以下任何一种场景时,加载本 skill:
- **性能测试**:用户说"做性能测试"、"压测"、"性能压测"等
- **数据准备**:需要在私有化环境做压测前数据准备(批量创建空间/应用/用户/加入空间)
- **组装压测脚本**:用户说"组装一个性能测试脚本"、"写一个 locust 脚本"、"编写压测脚本"等
---
## 流程入口判断(重要⚠️)
当用户触发本 skill 时,**必须先判断用户意图**,进入对应的流程:
### 入口 A:用户说"我要做性能测试" / "做压测"
> 用户只说了要做性能测试,但没有明确需要什么,此时需要先**询问确认**。
**执行步骤**:
1. **询问用户是否需要数据准备**(使用 `ask_followup_question` 工具):
- 提问:"您的性能测试需要做哪些准备工作?"
- 选项:
- "需要数据准备(批量创建空间/应用/用户等)"
- "需要组装一个压测脚本(locust 脚本)"
- "两者都需要(先数据准备,再组装脚本)"
- "我只是有个问题想咨询"
2. **根据用户回答分流**:
- 选择"数据准备" → 进入 **[流程 1:数据准备](#流程-1数据准备)**
- 选择"组装压测脚本" → 进入 **[流程 2:组装 Locust 脚本](#流程-2组装-locust-脚本)**
- 选择"两者都需要" → 先走流程 1,完成后走流程 2
- 选择"咨询" → 自由对话,参考本 skill 的知识回答
### 入口 B:用户说"组装一个性能测试脚本" / "写个压测脚本"
> 用户明确要求组装脚本。
**直接进入** → **[流程 2:组装 Locust 脚本](#流程-2组装-locust-脚本)**
### 入口 C:用户说"做数据准备" / "批量创建空间/应用/用户"
> 用户明确要求做数据准备。
**直接进入** → **[流程 1:数据准备](#流程-1数据准备)**
---
## 流程 1:数据准备
### 能力说明
- 提供 N 个原子脚本,支持串行或按需组合调用
- 脚本结果写入统一 JSON 资产文件,便于后续脚本复用
- 脚本内部复用仓库现有 `Service/API`,不手写签名或明文密钥
### 目录与脚本
- `scripts/create_spaces.py`:批量创建空间并记录 `SpaceId`
- `scripts/create_apps.py`:在指定空间批量创建应用
- `scripts/create_users.py`:批量创建用户并记录用户信息
- `scripts/add_users_to_space.py`:批量把用户加入空间
- `scripts/create_shared_kbs.py`:批量创建共享知识库,结果写入 `shared_kbs` 字段
- `scripts/gen_doc_variants.py`:从单个 docx 源文件多线程批量生成差异化变体,每份文档末尾插入唯一 UUID,文件名含序号+UUID 前缀
- `scripts/common/asset_store.py`:统一资产 JSON 读写
- `scripts/common/cli_utils.py`:命令行参数与输入解析
- `scripts/common/batch_runner.py`:批量执行、重试、节流
### 资产文件约定
默认资产文件可放在 skill 目录下(或通过参数覆盖):
- `spaces.json`、`users.json`、`apps.json`
统一结构(示例):
{
"run_id": "20260324_143501",
"spaces": [],
"users": [],
"apps": [],
"failed": []
}
### 推荐执行链路
1. 先建空间:`create_spaces.py`
2. 再建用户:`create_users.py`
3. 把用户加到空间:`add_users_to_space.py`
4. 在空间建应用:`create_apps.py`
5. 在空间批量建共享知识库:`create_shared_kbs.py`
### 调用示例
python3 .codebuddy/skills/perf-test/scripts/create_spaces.py --account Master_Default --count 5 --output .codebuddy/skills/perf-test/assets/spaces.json
python3 .codebuddy/skills/perf-test/scripts/create_users.py --account Master_Default --count 20 --user-prefix perf_u --password-encrypted <加密密码串> --output .codebuddy/skills/perf-test/assets/users.json
python3 .codebuddy/skills/perf-test/scripts/add_users_to_space.py --account Master_Default --space-id <space_id> --users-file .codebuddy/skills/perf-test/assets/users.json --output .codebuddy/skills/perf-test/assets/membership.json
python3 .codebuddy/skills/perf-test/scripts/create_apps.py --account Master_Default --space-ids <space_id1,space_id2> --count-per-space 30 --app-prefix perf_app --output .codebuddy/skills/perf-test/assets/apps.json
# 在默认空间批量创建 10 个共享知识库(主账号)
python3 .codebuddy/skills/perf-test/scripts/create_shared_kbs.py \
--count 10 \
--output .codebuddy/skills/perf-test/assets/shared_kbs.json
# 指定空间和账号
python3 .codebuddy/skills/perf-test/scripts/create_shared_kbs.py \
--account Master_Default \
--space-id <space_id> \
--count 20 \
--kb-prefix perf_kb \
--output .codebuddy/skills/perf-test/assets/shared_kbs.json
### 参数设计原则
- 数量参数均为正整数
- 所有输入支持"命令行直传"和"从资产 JSON 读取"两种方式
- 支持 `--run-id` 以实现多批次可追踪
- 支持 `--retry`、`--interval` 控制重试与节流
### 故障处理
- 每次 API 调用均检查 `Response.Error`
- 失败项写入 `failed` 数组,不吞错
- 总结输出成功数/失败数/关键失败原因
---
## 流程 2:组装 Locust 脚本
### 核心原则(重要⚠️)
1. **完全独立**:脚本必须一个文件包含所有依赖,**不能 import 项目内其他模块**
2. **最小依赖**:仅依赖 `pip install locust requests` 可安装的标准库
3. **环境变量驱动**:所有连接信息通过环境变量覆盖
4. **内置签名**:TC3-HMAC-SHA256 签名和 S3 V4 签名必须内嵌在脚本中
### 执行步骤
#### Step 1:收集用户需求
向用户了解以下信息(使用 `ask_followup_question` 工具):
**必须了解的信息**:
- **压测场景**:需要压测什么业务流程?
- 示例选项:标准模式全流程(创建应用→上传文档→发布→对话→清理)、纯对话压测、创建应用压测、文档上传压测、自定义场景等
- **目标环境**:私有化环境的 Host 地址、SecretId/SecretKey 等(可以后续通过环境变量传入)
**可选了解的信息**:
- 并发用户数、运行时长
- 是否需要特殊的指标统计
- 是否有特殊的业务参数
#### Step 2:参考 Cookbook 编写脚本
根据用户描述的场景,**参考 `references/locust-cookbook.md`** 中的代码片段和模式来编写独立 locust 脚本。
**编写规范**:
1. **文件头**:包含完整的文档字符串,说明场景、指标、依赖、运行方式、环境变量
2. **导入区**:标准库 + requests + locust(参考 cookbook 的导入清单)
3. **常量区**:所有可配置项通过 `os.getenv()` 读取,提供合理默认值
4. **基础设施层**:按需包含以下组件(从 cookbook 复制):
- `get_tc3_headers()`:调用xxx API 时必须包含
- `post_yun_api()`:调用xxx API 时必须包含
- `get_s3_v4_signature()` + `upload_file_to_minio()`:上传文档时必须包含
- `process_response_sse()`:SSE 对话时必须包含
5. **业务 API 层**:根据场景按需包含(从 cookbook 复制/裁剪)
6. **Locust 上报工具**:`fire_success()` + `fire_failure()` 必须包含
7. **Locust User 类**:参考 cookbook 的 workflow 编排模式
8. **文件驱动数据**:如果用户提到以下需求,**必须参考 cookbook 第 8 章**:
- "从文件读取数据"、"每个并发用不同数据"、"数据用完停止" → 使用 **8.2 Queue 消耗方案**(数据不重复,耗尽自动停)
- "数据可以重复"、"按时间跑"、"循环使用数据" → 使用 **8.6 循环读取方案**(`itertools.cycle` 或 `random.choice`,配合 `-t` 停止)
**脚本输出位置**:
- 优先复用 skill 内置脚本:`.codebuddy/skills/perf-test/scripts/`
- 如需定制场景,再保存到 `tool/pef_test/` 目录
**内置常用查询压测脚本(开箱即用)**:
- `locust_list_app_perf.py`:压测 `ListApp`(默认 `PageSize=15`),统计响应时间指标
- `locust_list_shared_knowledge_perf.py`:压测 `ListSharedKnowledge`(默认 `PageSize=15`),统计响应时间指标
- `locust_describe_space_list_perf.py`:压测 `DescribeSpaceList`(无分页参数),统计响应时间指标
**内置脚本运行示例**:
locust -f .codebuddy/skills/perf-test/scripts/locust_list_app_perf.py --headless -u 10 -r 2 -t 5m
locust -f .codebuddy/skills/perf-test/scripts/locust_list_shared_knowledge_perf.py --headless -u 10 -r 2 -t 5m
locust -f .codebuddy/skills/perf-test/scripts/locust_describe_space_list_perf.py --headless -u 10 -r 2 -t 5m
#### Step 3:询问是否执行
脚本编写完成后,**必须询问用户是否需要帮助执行**(使用 `ask_followup_question` 工具):
- 提问:"压测脚本已编写完成,是否需要我帮你执行?"
- 选项:
- "是,帮我执行(headless 模式)"
- "否,我自己执行"
#### Step 4:执行脚本(如果用户选择执行)
使用 locust **headless 模式**运行脚本:
# 基本执行(询问用户并发数和时长)
locust -f <脚本路径> --headless -u <并发用户数> -r <孵化率> -t <运行时长>
# 示例
locust -f tool/pef_test/locust_chat_only_perf.py --headless -u 5 -r 1 -t 5m
执行前需确认:
1. 环境变量是否已设置(ADP_HOST、ADP_SECRET_ID、ADP_SECRET_KEY 等)
2. 如果未设置,提示用户设置或使用默认值
3. 并发用户数(-u)和运行时长(-t)
---
## 指标统计规范
### 标准指标命名
| 指标名称 | 说明 | 单位 |
|---------|------|------|
| `0_workflow` | 总流程成功/失败 | ms |
| `1_create_app` | 创建应用 | ms |
| `2_upload_and_import_doc` | 文档上传并导入 | ms |
| `3_release_app` | 应用发布 | ms |
| `4_chat` | 对话 | ms |
| `4_chat_ttft` | 首 Token 延迟 | ms |
| `4_chat_tokens_per_second` | 吐字率 | tokens/s |
| `5_delete_app` | 清理应用 | ms |
### 命名规则
- 使用**数字前缀**表示步骤顺序(0_workflow 排最前)
- 失败分类使用下划线后缀:`4_chat_error_rate_limit`、`4_chat_error_question_sensitive`
---
## 安全要求
- 不在日志中输出明文密钥、密码
- 脚本中的默认 SecretId/SecretKey 仅用于开发调试,生产环境必须通过环境变量覆盖
- 用户创建脚本仅接收外部传入密文密码串,不做明文加密
- 数据准备脚本复用 `BaseApi.do_req_by_env` 做签名与环境路由
---
## 参考
- 详细接口备注见:`references/api-notes.md`
- Locust 脚本编写参考手册:`references/locust-cookbook.md`(⚠️ 编写压测脚本时必须参考此文档)
执行效果
当我要求它执行压测并给它相关的参数后, 它会自动执行,并且给出相对完备的报告,比如:
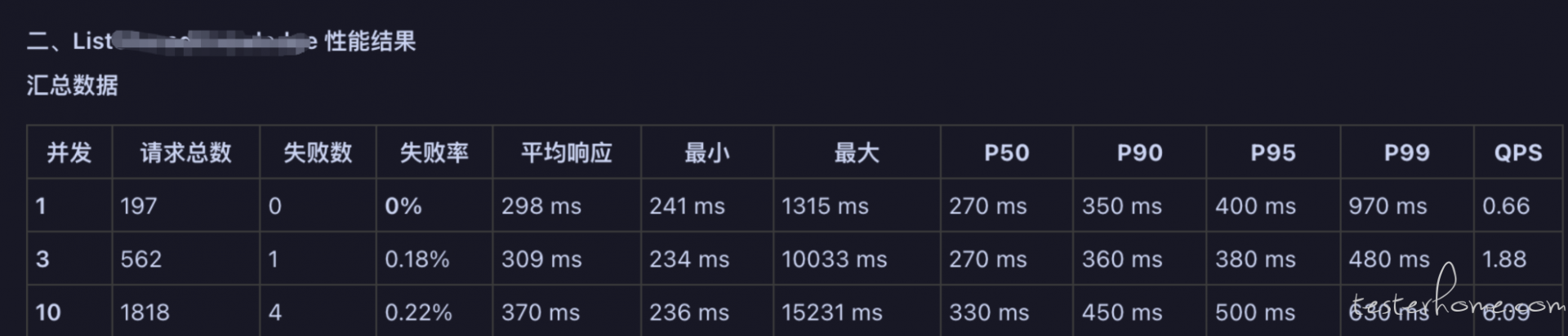
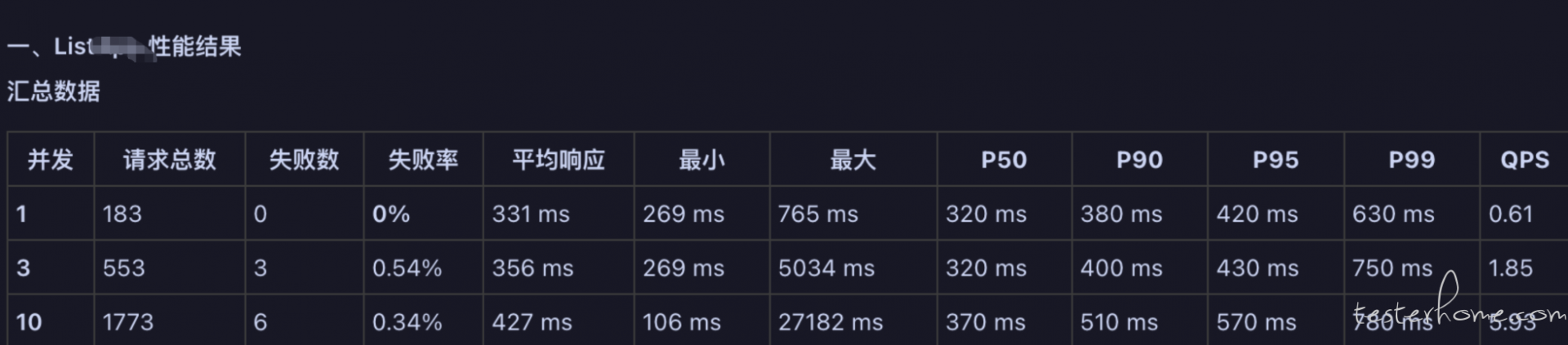

最后总结一下
一个好的 skill,需要具备我上面提供的目录结构:
- SKILL.md:规定要如何执行这个 skill,它是 skill 的大脑,是规定工作流程的地方。
- scripts 目录:为了能让 skill 每一次都稳定执行历史的最佳方案,需要让大模型落地成成熟的脚本,保证后续稳定运行。
- references 目录:skill 的参考手册与 cookbook,如果说 scripts 是保证历史中出现的场景能稳定执行下去,那么对于那些需要根据需求由 skill 动态来生成解决方案时,就由 references 来保证生成的准确性。
以上三个东西,我认为是缺一不可的。
最后再宣传一下自己的星球,后续会持续输出 AI 领域相关教程,下周我会开直播分享 AI 提效的一些心得:
