
OpenClaw 科普:它和豆包、元宝、扣子有什么区别?
最近 OpenClaw 开始在社交媒体上出现,我看到不少人问:“它和豆包、元宝、这些我们常用的产品有什么区别?为什么说它给普通人带来了革命性的变革?”
如果不熟悉智能体领域的同学,可能确实不太能理解。毕竟大家最这方面的理解可能仅限于对豆包的使用, 但实际上真正的智能体要远比豆包。
所以我这里给一个科普,帮助大家理解 OpenClaw 能为普通人带来什么样的改变。
一句话先说明
OpenClaw 是 “可执行的本地/私有化智能体框架”,不只是聊天窗口。你和它对话,它不仅能回答问题,还能在你授权后调用本机或服务器能力去完成任务。
我们在以前使用豆包和元宝的时候,它们本质上还是在回答我们的问题,而不是去完成一个复杂的任务。当然他们已经做的很好了,尤其是豆包,它的回答很专业,也很全面。还能调用各种工具来进行辅助。 比如
网络检索,图像识别,语音识别等。PS:我家女王大人就经常用豆包来解决我儿子的作业问题。
但,这仍然停留在问和答这个层面上。 它没有帮助用户来执行一些复杂的任务。 比如:帮助我清理我的电脑,帮我备份我的文件,帮我安装软件等,或者调用外部 API,帮我在小红书上发布一篇文章等等。甚至于:帮我执行一个专项的测试任务。
所以我们通常说,豆包、元宝、扣子等这些产品,都是 “聊天窗口”,而不是 “智能体”。或者说做为一个智能体,它的能力太弱了。
而 OpenClaw 不同,它是 “可执行的本地/私有化智能体框架”。它拥有本地机器的全部权限,可以执行任何命令,包括:
- 执行本地命令,操作机器中的文件,运行相关脚本。
- 调用外部 API,访问互联网,访问其他设备等。
- 安装现有 skills,或者用户自己开发 skills,完成各种复杂任务。
OpenClaw 为什么能做到这些?
OpenClaw 本质上是一个智能体(Agent):
- 用户通过自然语言对话下达目标(OpenClaw 可以对接不同的大模型。)
- 智能体会做任务分解、调用工具、执行步骤、返回结果;
- 它关注的不是 “聊得像不像人”,而是 “任务有没有真正完成”。
也就是说,OpenClaw 更接近 “会干活的数字助理”,而不只是 “会聊天的 AI”。
我们来通过一个例子来理解一下 OpenClaw 的能力:
既然我们是测试人员,那我们先看一下如何使用它来做我们的高可用测试。之所以选择这个测试类型, 因为高可用测试需要登陆到目标测试集群,然后执行一系列命令,检查目标集群是否正常,注入相关故障,还要调用自动化测试脚本,然后分析测试结果。 这是一个标准的复杂任务,比较适合来说明我们的 OpenClaw 能力。
首先我们需要创建一个 skills,这个 skills 需要包含以下功能:
- 登录到目标集群执行相关命令,比如查看 k8s 集群状态,查看 pod 状态,执行节点重启,删除 pod 等命令。
- 注入故障,比如注入网络故障,磁盘故障,内存故障等。
- 调用自动化测试脚本,比如调用自动化测试脚本,检查目标集群是否正常。
- 分析测试结果,比如分析测试结果,判断是否正常。
- 生成报告,比如生成报告,判断是否正常。
- 查询测试进度,判断是否正常。
所以我们需要通过对话来创建一个 skills。 PS:一般来说都会内置一个 skills-create 技能,用于使用自然语言创建 skills。
因为我当初创建这个 skills 的时候,使用了很多轮对话进行调整,我没办法把截图都放出来, 所以这里我只列出我的关键提示词 (因为有项目内容,所以做了阉割,大家看这个意思就可以了。):
现在我希望创建一个高可用测试的skills。
要严格按以下工作流开展:
所有要使用的脚本放在:/mnt/cloud/automation_project/xxx-proj/tool目录下
要严格按照下面的工作流完成任务:
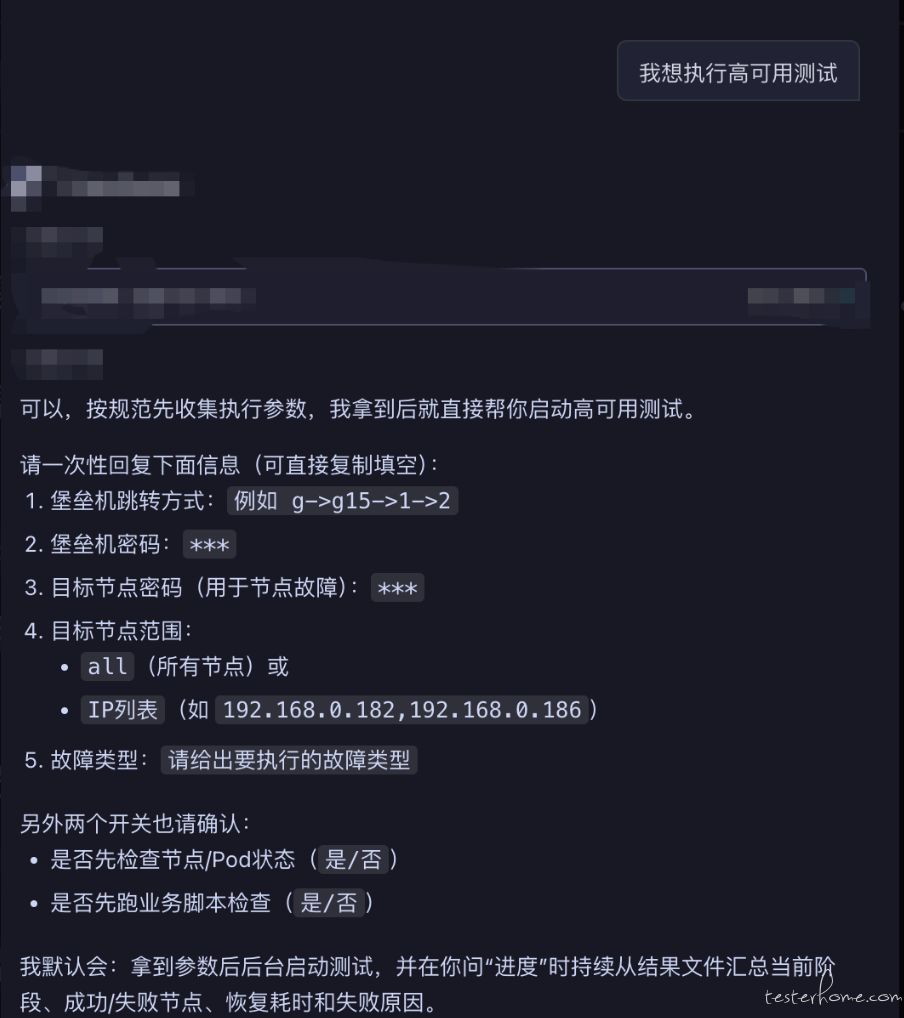
1. 如果用户要测试高可用,则需要先向用户收集必要的参数。 比如 堡垒机跳转方式, 堡垒机密码, 目标节点密码,目标节点ip(可以让用户选择all,或者某几个具体的ip),故障类型。
2. 需要询问用户,是否先检查节点和Pod状态。 如果用户选择需要,则调用bastion_exec.exp脚本登陆到目标环境检查k8s集群下的节点和Pod是否都是正常的状态。
3. 需要询问用户,是否通过业务脚本,检查业务状态, 如果用户选择需要,则tool/scripts/run_ha_env_check_nohup.sh 脚本来检查。 它的结果保存在 tool/ha_env_check_results.json。 你需要监控这个脚本,验证它执行成功或者失败。 如果失败,需要把哪个脚本的失败告诉用户,以及对应的报错信息。
4. 等到以上三点都结束后,你需要先调用 bastion_exec.exp查询k8s节点的节点列表。
5. 获取到列表后, 执行ha_fault_test_runner.py来执行高可用测试它的结果文件在ha_fault_test_results.json, 你可以根据这个文件判断任务执行的进度。 执行后,你的任务就结束了。后续用户询问进度的时候,再通过这个文件查看并返回给用户执行进度。
注意:如果你判断测试已经结束了, 需要汇总ha_fault_test_results.json中的内容来给用户做总结, 尤其是如果有测试失败,要详细总结告诉用户
注意:以上提示词中的脚本也都是用 AI 来完成编写的,通过输入提示词,AI 自动帮我生成脚本。
我使用的效果是这样的:
当有测试失败的时候,也会有当前的测试进度和分析内容:

所以大家看,这就是 OpenClaw 的能力,它可以执行任何命令,只要我们事前定义好技能和工作流,就可以让 OpenClaw 执行任何命令。
总结
OpenClaw 可以让普通人也能低成本的搭建属于自己的智能体助手,它可以帮助我们完成各种复杂任务:
- 如果你是一个自媒体从业者,我们可以在 OpenClaw 上定制定时任务,定期检索热点内容,分析总结,帮助生成口播文案,生成视频,生成音频。
- 如果你是一个和我一样软件测试人员,我们可以使用 OpenClaw 来完成各种测试和管理工作。
- 如果你是一个和我一样的业余小说作者,我们可以使用 OpenClaw 来完定期检索热门小说,分析总结,记录灵感等等。
如果我们愿意去研究和折腾,就可以搭建出一个能 24 小时帮助我们做事的小助手。业界也有很多现成的 skills 和 mcp 来帮助我们调用外部 API,比如我的一个在小红书上做自媒体的同事,它利用了 OpenClaw 对接小红书的 mcp 和 skills,来完成创作任务。我们在这里可以找到它支持的各种 skills:
https://github.com/openclaw/skills/blob/main/skills/hi-yu/xhs/SKILL.md
我自己也试了一下小红书的 skills,它的效果:

可以看到,我还把它与企业微信进行了对接,以后我只要有一部手机,就可以完成各种各样的工作。 再也不用守着电脑。
怎么说呢,我得感觉是这样的:OpenClaw 的出现让 “人” 的能力和效率扩大数倍甚至数十倍。但如果人的能力本来就是 0,那么 AI 再怎么放大仍然是 0。所以 AI 能发挥出多大的价值,还是要看使用 AI 的人。根据这个观点,我们会发现 AI 出现后会让行业专家与普通人的差距进一步的扩大。
最后再无耻的推广一下我得星球,后续我会在星球里更新更多 AI 类和其他测试教程:

