-
AI 对测试到底哪些领域有真正的收益 at 2026年07月09日
最主要的问题是用例如果都由 AI 生成,那测试就没办法再书写用例的过程中梳理需求/理解需求,但是最终还要人来验证这就很扯淡,尤其是碰到新产品,跟没有用例有什么区别,让 AI 生成用例的不知道是咋想的
-
【杭州】测试&后端开发 at 2025年07月12日
-
【北京】【Meshy AI】测试开发工程师 at 2025年07月12日
-
【济南】法正智能科技 招聘中、高级测试工程师 2 名【第一学历放宽至统招大专】 at 2025年07月12日
-
脚本多次运行后总是会重复报一个错,但页面元素并未调整 at 2025年02月17日
直接问 chatgpt 吧
-
jmeter 和 postman at 2025年02月09日
我知道:你 JMeter 脚本写的有问题

-
数据工厂相对于接口自动化平台,它的价值是什么? at 2025年02月09日
价值就是造一个概念,让人觉得很厉害的样子...
-
当了 3 年全职妈妈现在还机会回到职场吗? at 2025年02月09日
能力上来说应该没问题,但是就现在的就业环境真是让人很无语...
-
给小工具穿了件新衣服 - intellij plugin 开发 at 2025年02月08日
是不是 ide 版本太低了,这个插件最低支持到 2023.1
-
给小工具穿了件新衣服 - intellij plugin 开发 at 2025年02月07日
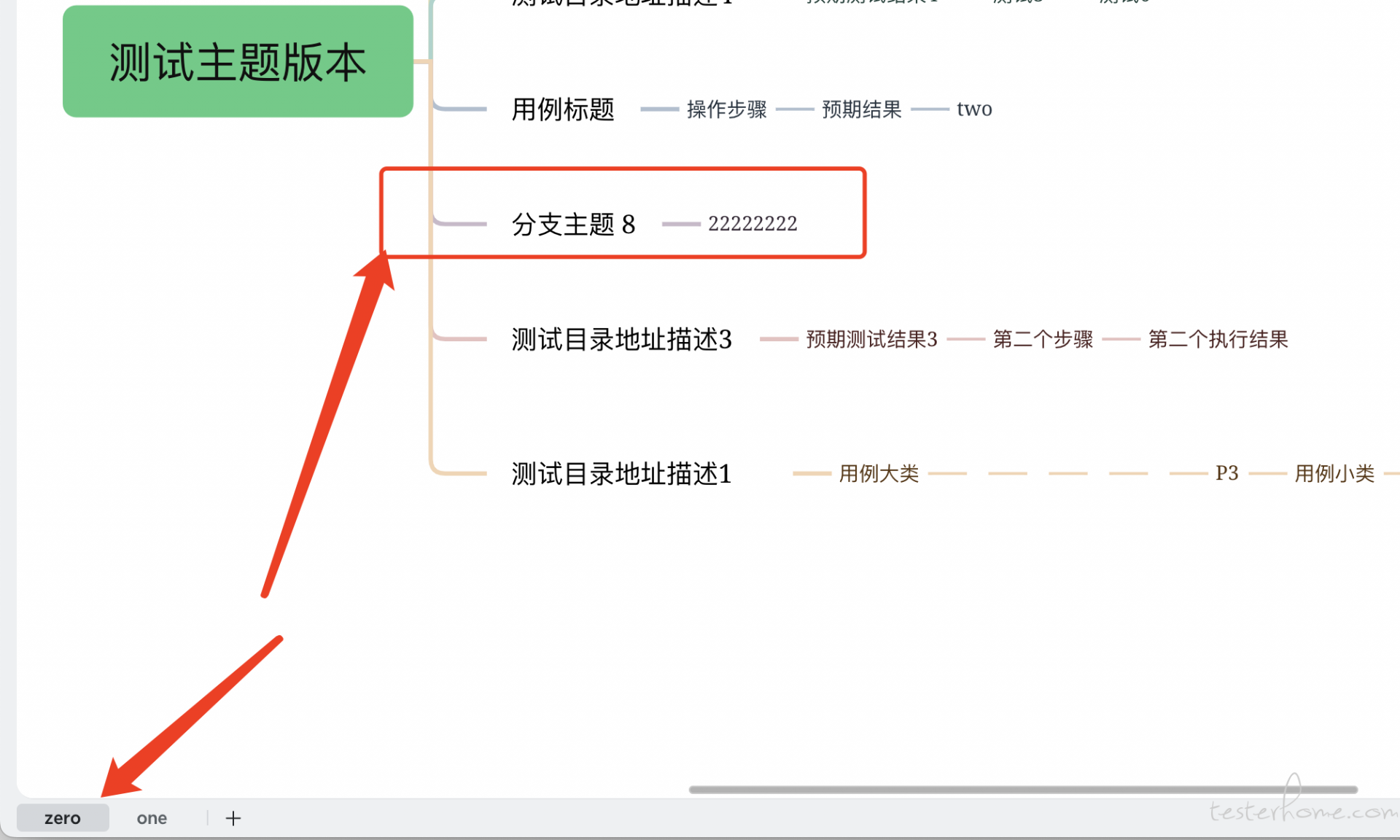
当前默认设置的层级=two, 就导致了主节点下每个分支节点的长度最少等于 4 , 整个路径就是: 中心主题 - 一层目录 - 二层目录 - 用例标题 - 操作步骤 - 预期结果; 如果要最大兼容性的话不想有这么多的节点, 就把 XMind 画布名改成 zero(等于把层级设置成 zero,此时中心主题下的分支节点长度最小等于 2 ,因为必须有两个节点表示操作步骤和执行结果), 这个路径就是:中心主题 - 操作步骤 - 预期结果, 此时中心主题就是用例名。
-
给小工具穿了件新衣服 - intellij plugin 开发 at 2025年02月07日
没呢

-
给小工具穿了件新衣服 - intellij plugin 开发 at 2025年02月05日
哈哈,有 BUG 欢迎反馈
-
XMind 转 Excel 与 CSV 的思路 at 2025年01月30日
OK
-
测试覆盖率二改实现 at 2024年03月04日
没有说啥内容啊,好像就是把成果说了一下
-
【急急急】jmeter 怎么使用并行控制器 Parallel Controller? at 2024年01月31日
JMeter 中无法通过现有组件排列组合实现这种效果,因为他是阻塞执行的,必须执行完一个请求才会执行下一个请求,不过可以迂回一下,使用同一个线程组或者不同线程组的参数 + 时间来实现这种效果。比如使用一个线程间的共享变量,让一个线程通过一个 while 循环进入第二个个 while 循环, 让第二个线程放入第一个 while 循环中,让他们在各组的循环中等待某个时间到了之后执行请求。
-
XMind 转 Excel 与 CSV 的思路 at 2024年01月31日
刚看了下思路完全不一样,大佬做的比较全,连 Web 页面都提供了,我这个要手动执行 JAVA 程序,而且可以说思路完全不一样
-
XMind 转 Excel 与 CSV 的思路 at 2024年01月31日
嗯嗯
-
(杭州)诚招测试工程师(初中高级都有 hc) at 2023年02月20日
-
JMeter Groovy 中求数据类型的方法是什么?还有 Java 中求数据类型的方法是什么? at 2022年01月14日
Groovy 中 getClass 不可用 ?
-
这个辩论的话题可以结束了 at 2021年06月30日
值得反思。招人的时候,短短一个小时,一个人业务测试做的怎么样,是否认真,很难看出来。但是一个人的技术怎么样,通过几个技术问题却是能很快了解。慢慢的让许多人对技术侧的倚重越来越强。对业务测试工作忽略。
-
需要在 module_config 表中增加一条记录,其中 app_name = repeater ,environment = daily,因为 bootstarap.sh 中的启动代码是 -Dapp.name=repeater \ -Dapp.env=daily \ 要保持一致,不然数据库中查出为空还会报空指针异常。
-
关于 jmeter 性能测试的 局限性 at 2020年05月14日
首先我对 TPS、QPS、RPS 这些概念认为都查不多,只是细微之处有些变化来描述一种特定的场景,没必要纠结那个大于哪个,反正都是反映服务器的性能,对于性能测试工具 JMeter 是 BIO 的,也就是同步阻塞,这样做有及其大的优势,同时更加符合人的操作逻辑。不然一整套逻辑接口,后面的接口的数据怎样根据前面已知的条件生成?(之后输入的数据根据已知的条件随机生成才能更加符合人的操作逻辑),数据也能更好的监控。JMeter 的分布式压测产生的背景是一台客户端由于内存、CPU 、网络(主要是内存)的限制造不成更加的压力,因为 JMeter 是基于线程的内存开销较大。
对单个接口来说多线程访问因为代码逻辑是一样的,在不考虑线程占用内存的影响时,TPS 最大值应该是一个固定的值,但是创建一个线程会占用服务器的内存资源,从这方面说 高线程就是等于高压力,基于线程也是 JMeter 的一种局限,因为单台客户端产生的线程有限,所以才有了分布式解决这个问题。
线程会占用服务器内存和 CPU 资源,同时也挤占了程序运行时的资源,所以高并发(大量线程)会造成内存溢出。也会造成 TPS 下降,楼主的那种情况应该是虚拟用户数过低,也就是服务器中运行的线程数不足以把程序运行的空间挤压的很小,造成程序处理速度变慢,又回到上面说的当 JMeter 一个线程发送一个请求没有响应的时候该线程是不会再发送第二个请求的。所以要想出现性能拐点必须增加虚拟用户数量,一方面需要单个客户端增大线程数量,另一方面分布式多个客户端运行。就好了。
最后说说,任何工具都有优点和局限性,有的特性可能在某种角度先是优点从另一种角度看就是局限性。JMeter 作为性能测试工具很好用。 -
JMeter 实时监控仪表板配置 (Grafana + InfluxDB) at 2019年07月25日
不会影响被测试程序,无论怎么查询只是查询 InfluxDB,对 InfluxDB 所在的服务器造成点压力,跟被测对象程序没关系