-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 27, 2018
额,这是一个性能测试平台,不负责接口测试的事情。
接口测试的报告还是接口测试平台来做。其实平台缺少的是一个调试脚本的手段方式,并且这个需求场景越来越频繁。
依次说一下吧。
ant 主要是卡在脚本执行结果文件格式上了。 ant 需要 jtl,但是测试报告需要 CSV,有冲突。
allure 等的是接口测试平台的职责,作为调试手段不如 ant 了。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 27, 2018
还不支持。
不过你这种方式真的是不错的,借助 docker 解决 client 部署的问题,甚至能解决 slave 的重复利用问题(需要测试验证不能贸然使用)。
目前平台还仅仅是支持 slave 的事先部署(也可以用 docker 部署 Jmeter),没有 docker 的这种脚本的自动批量部署和销毁(平台虽然没有但是使用者可以自己实现,然后将数据插入到数据库的 slave 表中即可)。平台目前的职责非常单一清晰,就是把脚本能页面执行 + 页面监控 + 生成测试报告。脚本的页面执行包含了分布式情况下的执行。分布式环境的其实并不在平台的核心职责之内。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 27, 2018
这个人不是我,是拿我的东西给自己宣传了。
我 QQ 邮箱是 : 444104595@qq.com -
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 26, 2018
感谢能把你的思考写到评论中来,感谢。
我主要是思考几个问题来的,分享一下:- 如果完全不懂业务能不能做性能测试? 答案是可能的,虽然不是说所有的性能测试都不要业务吧,但是完全不懂业务是可以做性能测试的,因为存在接口的性能压测,因为就算页面录制脚本的操作可以由功能测试或者开发代为执行。
- 如果完全不懂系统架构能不能做性能测试? 答案是可能的,就算系统是个黑盒,我也能做性能测试,并且根据折线图做一下基本的判断,如果给我服务器被压测机的系统监控指标或者日志记录,或者就给我服务器登录密码,我真的可以告诉你它性能有没有问题,问题出在哪。 我认为这是性能测试的基本功。
工作岗位的胜任力是一门科学,你的胜任力中很关键的一部分是业务,那就要把业务搞熟悉。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 26, 2018
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 26, 2018
目前的定时压测是使用本身 Jmeter 脚本的自带功能:
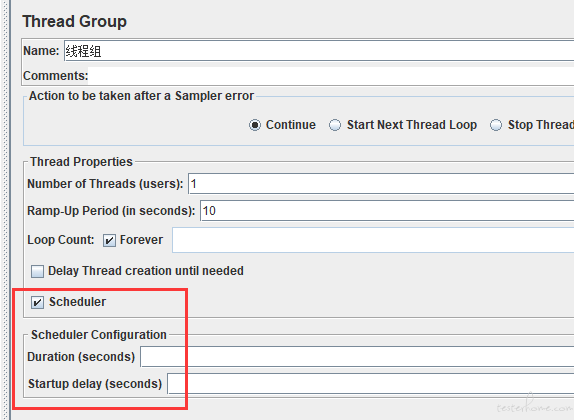
其他定时任务是执行平台的方法,需要个人对平台根据需求二次开发,和性能测试关系就不太大了。
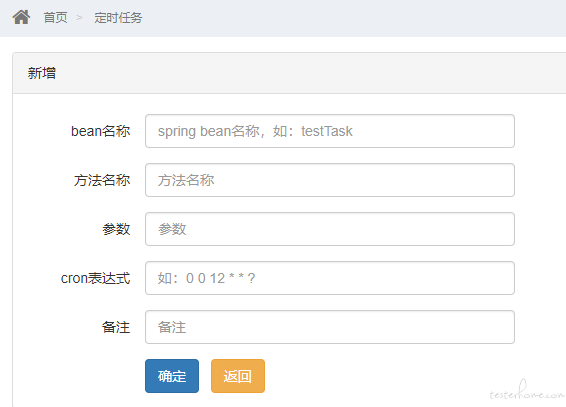
-
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 26, 2018
以后我会发帖子简单说说,主要是想讲讲方法论。
因为调优的例子网上多了去了,但是能从例子中总结出自己东西的能有几个人?很多人也根本看不出门道。
方法论是一些基本的东西,抛砖引玉吧。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 22, 2018

建议直接使用 Jmeter 的脚本命令先试一下生成报告。
生成测试报告是建立在 Jmeter 本身的功能上的。
同时注意运行平台的用户和安装平台的用户权限是否一致。这个异常信息是 Jmeter 自己打印的,我自己的异常信息都是中文大白话的……。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 22, 2018
我本地执行是正常的。
建议把这种必现问题提到 issue 上吧,然后请详细说明一下报的异常是什么,问题现象是什么,多谢了。因为我初步判断这里应该不存在兼容性问题。那么我的环境是 OK 的,想不到为什么你那里会失败。
提 issue 吧。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 22, 2018
你好,主要是因为我使用 jtl 文件生成测试报告会遇到异常,我看是 Jmeter4.0 里强制写的判断。

同时还有一些附带的原因:- 相同的请求数量,jtl 文件比 CSV 的文件大。
- CSV 文件的内容比 jtl 文件的丰富,有一些指标是仅支持 CSV 文件的(jmeter.properties 文件中有说明,不详细贴了)。
可能我这方面了解的还不多,如果你有好的方式,让 Jmeter4 使用 jtl 来生成测试报告,一定要知道我一下如何做……对平台的结果展示很有用。
-
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 22, 2018
测试的立足之处早有权威定论,就是测试这个岗位是必要的,软件工程离不开测试过程。
可能你想说的是如何能立足之稳,这在我的文中有说明,这里不复述了。
我可没说过技术不如开发,环境不如运维。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 22, 2018
可以的。
-
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 21, 2018

-
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 21, 2018
其实是你太强势了,产品相对弱小了,哈哈。 -
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 21, 2018
确实,我有点儿不严谨了,一般在一行做了十几年的测试……肯定是业务精熟了。
-
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 21, 2018
希望能举出业务上,测试大于等于产品的行业例子,我也学习一下。
-
尴尬的性能测试岗位——顺便聊聊 “点点点” at November 21, 2018
有支持的就没白写啊!感谢。
-
无尽的压力,吐槽一下吧,有相关经历的同学给我说一下你们的见解 at November 19, 2018
建议每天自学到凌晨 2 点以上坚持完整个试用期。同时和同事们搞好关系。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 16, 2018
可以的。
你可以查一下源码中的 org.apache.jmeter.report.dashboard.ReportGenerator 类, 是通过它生成报告的。
调用如下:
ReportGenerator generator = new ReportGenerator(reportFile, null);
generator.generate(); -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at November 14, 2018
你好,可以到项目的 issue 里去提一下问题。
需要看一下异常是什么才能确定到底缺什么包。 -
你愿意为了提升自己的测试水平而花钱购买相关课程吗? at November 14, 2018
愿意。
极客时间我买过。
一个同学的,互帮互助:
https://www.jianshu.com/p/cd6388627f64 -
中级测试的面试记录与感受 at November 13, 2018
高级岗位:部门 Leader,或者团队 Leader,或者核心测试开发岗位(至少是在某个领域,要有独立产出的)。
中级岗位:能独立负责一个项目的整体测试工作,常规来看,2-3 年的从业者 。
初级岗位:刚入行,或者入行 1 年左右 。
这是引用过来的。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 31, 2018
这几处代码是我当初没有放进去的。主要是因为最后一行:Thread.currentThread().setContextClassLoader(loader); 这会将当前线程的类加载器换成自定义的。
Jmeter 的自己的原有的启动类是需要这个的,为了将 lib 目录下的 jar 包的类加载到内存中,但我们平台是不同的,平台的环境里已经存在了绝大部分的类,没必要把 lib 目录下的所有的 jar 包都在每一个脚本执行的时候再加载一遍(应该还是占用内存的,即使重复也要来一套,没验证)。如果你非要追求 Jmeter_Home 的那种全量的环境,可以使用脚本模式执行,同时外挂 influxDB+Grafana 监控,这是满足你的需求的。
当前平台还不打算搞的所有的 lib 包还要重复加载一遍。
-
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
嗯嗯。也可以。
我刚刚查了一下测试 dubbo 的。确实比较复杂。 -
基于 Jmeter 的轻量级云压测平台的原理与实现 (一):开篇 at October 26, 2018
是吧,平台上传 jar 包这种操作,是测试自己掌握的。
不能说平台的管理还搞一堆其他部门的人来染指,那就说不过去了。
你说的包冲突,频繁上传,都是我们测试来掌握的。测试的 jar 包要稳定,可以先 Jmeter 工具自身测试验证后,再到平台上来,所以你说的平台频繁启动刷新 JRE,是属于过度使用平台了。