-
如何收集 nodejs 服务端的测试覆盖率(Nodejs) at 2021年07月26日
@ 清水 来个 github 仓库地址 如何,我试试看,因为截图内容好多,看的有点乱
-
如何收集 nodejs 服务端的测试覆盖率(Nodejs) at 2021年07月24日
你能提供下 你合并后的是什么样的吗,另外为什么说拿不到覆盖率数据呢
-
如何收集 nodejs 服务端的测试覆盖率(Nodejs) at 2021年07月12日
嗯,我觉得他挺适合 node 后台的
-
如何收集 nodejs 服务端的测试覆盖率(Nodejs) at 2021年07月11日
那可以考虑改造下 istanbul-middleware 看看,我找时间试试

-
如何收集 nodejs 服务端的测试覆盖率(Nodejs) at 2021年07月10日
嗯, 刚才试了下了,结果是可以的, 我就以使用 nyc 举例了,因为 istanbul-middleware 的方式也是可以的,而且看 readme 也很简单了
我写了一个 demo, 你自己可以访问去试验下 nyc-expresss-coverage-demo
这里使用的例子其实是istanbul-middleware test 目录的例子,只是我将其中关于 instalbul-middleware 库的引用都去掉了,增加了 nyc 的引用-
npm install安装依赖库 -
npm run instrument对服务的代码进行插桩,生成一个插桩后的目录 server-instrument -
node index启动服务, 这个时候服务引用的文件其实是 server-instrunment 的文件了,因为我在 index.js 里面将内容做了指定了。 - 直接访问 http://localhost:8888 即可看到服务网页的内容,其实就是开始我们的测试了。
再访问 http://localhost:8888/coverageData 就可以得到覆盖率数据
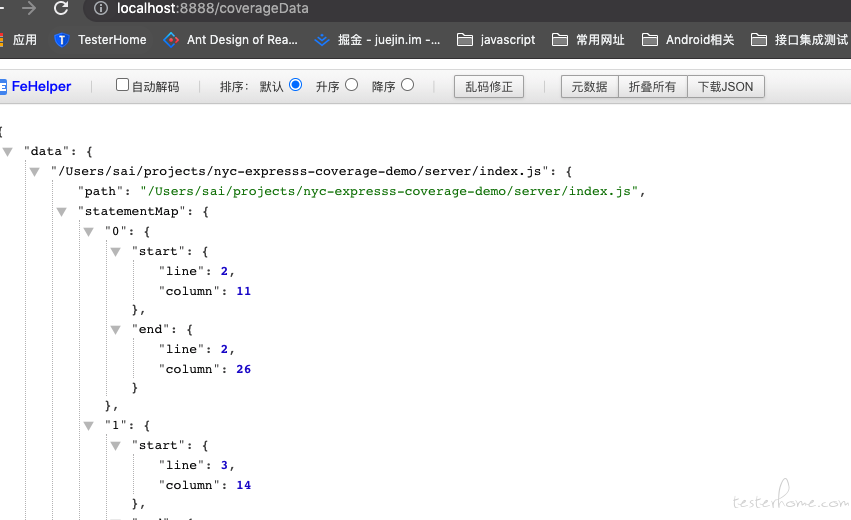
我们先麻烦点,将对应的数据放置到根目录的 .nyc_output 的 a.json 文件中,这里的文件名称可以随意。
nyc run report就会看到在 coverage 目录下生成了一个覆盖率的报告了。
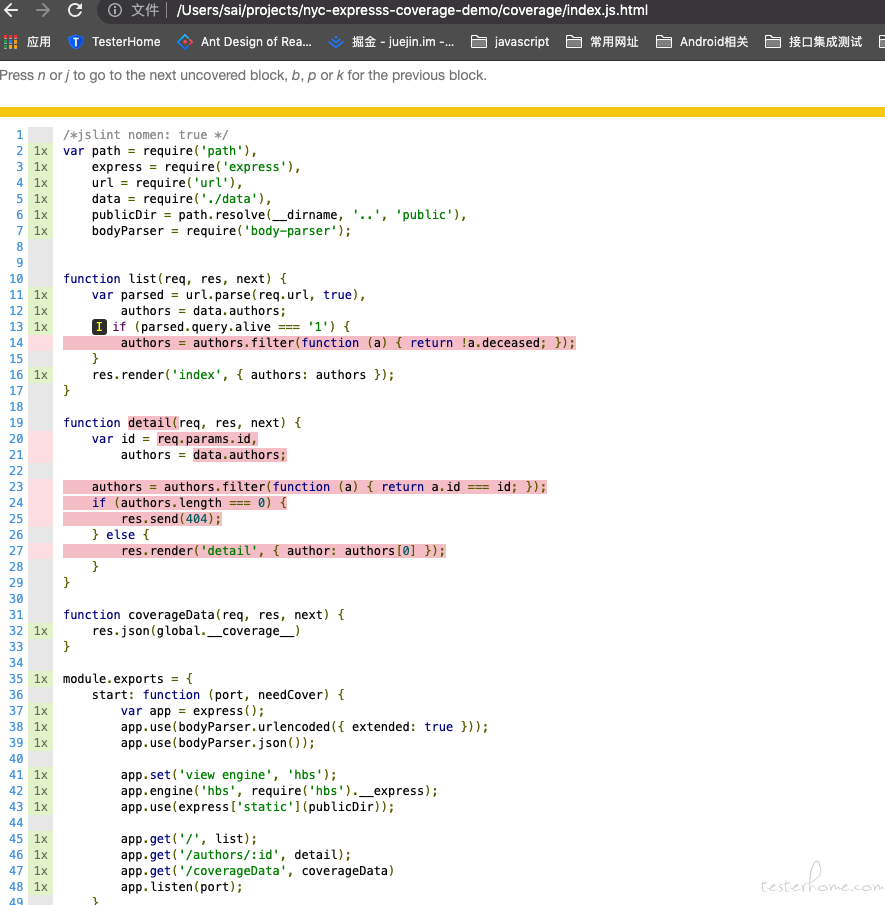
当然,这里有麻烦的地方就是需要自己去拷贝覆盖率的数据对吧,这个问题倒是不难,自己写一个第三方的库,然后做个定时任务,定时去上报全局变量中的coverage的变量给到真正处理覆盖率数据的后台就可以了。
-
-
如何收集 nodejs 服务端的测试覆盖率(Nodejs) at 2021年07月09日
首先说实话我并没有做过 nodejs 为后台的覆盖率,因为我们这边的实际场景都是 node 只是一个代理转发的逻辑,所以基本都没有针对 nodejs 这块来做覆盖率。
再来说下我觉得可能能够帮助到你的一些信息
你可以看下这个库, 它里面有可运行的 demo 了,而且也说明有 server 端的例子。你可以看下。 因为我之前也只是跑过 demo 所以了解的不多
istanbul-middleware另外一个是 nyc
这个库我用的比较多,不过 nodejs 这块我没有尝试过,下来我这边试试看 是否可以通过 nyc 插桩得到 nodejs 的覆盖率数据 -
感谢社区。好荣幸

-
支持下。
-
版主招募~ at 2021年05月27日
-
聊聊前端代码覆盖率 (长文慎入) at 2021年04月26日
感觉有点没到点上,不是在 webpack 的包里面,是在开发的项目代码中,一般都有一个 webpack.prod.config 这样子的文件,前提是这个项目是一个用 webpack 打包编译的,然后你就能看到类似这样子的配置:
module: { rules: [ { use: ['happypack/loader?id=babel'], test: /\.js$/, exclude: path.resolve(__dirname, 'node_modules'), include: path.resolve(__dirname, 'frontend'), }, ] }这个只是举个栗子哈,
-
聊聊前端代码覆盖率 (长文慎入) at 2021年04月22日
你微信多少,我加你看下
-
聊聊前端代码覆盖率 (长文慎入) at 2021年04月21日

你确认下你的目录下是否有这个文件? -
解决 jacoco 支持增量 kotlin 代码覆盖率 at 2021年04月21日
先说说你的报错信息是啥吧。你只是贴代码 完成不知道啥问题
-
appium+Pythom 运行脚本很很很慢!! at 2021年04月16日
楼上这个是正解
可以在 capability 里面配置 waitForIdleTimeout: 100 即可 -
AppCrawler 使用中遇到问题的问题及解决 at 2021年04月13日
开源的呀,自己了解逻辑的话可以定制下嘛
-
AppCrawler 使用中遇到问题的问题及解决 at 2021年04月13日
木有,因为临时接了这个任务,项目已经在使用 appcrawler 了。所以就硬着头皮去学习了这块的内容。
-
AppCrawler 使用中遇到问题的问题及解决 at 2021年04月13日
嗯 第一个在理,确实是应该去掉比较合适些,否则可能像爱奇艺那种视频播放页面就可能会重复点击了。
另外除了第 6 点了,其他可能还没遇到,等我遇到 再好好看看,感谢分享 哈哈。 -
AppCrawler 使用中遇到问题的问题及解决 at 2021年04月13日
还没有等我把这次的任务完成后,把通用的一些内容抽出来,提个 pr。因为有些内容是根据我们自己的一些需求做定制了。
-
使用 jacoco 实现多覆盖率文件合并 at 2021年03月21日
-
jacoco 收集测试覆盖率的时候,怎么避免代码改动导致覆盖率清零 at 2021年03月21日
这个其实修改很容易的,因为我那边是改了很多其他部分的东西,不能发你。 你可以看下这篇文章。里面写到了关于如何修改的逻辑
-
jacoco 收集测试覆盖率的时候,怎么避免代码改动导致覆盖率清零 at 2021年03月15日
针对 class 中新增方法这种情况,建议这个类就不要做合并的动作了,因为 jacoco 的源码中不单单是针对不同的 classId 不能合并,就算你改成了 className, 但是他还会去判断探针数组长度,两个探针数组长度不一样也不会合并成功,就算你强行要合并 合并的逻辑又是什么呢?
-
jacoco 收集测试覆盖率的时候,怎么避免代码改动导致覆盖率清零 at 2021年03月04日
嗯 也是可以的。
-
jacoco 收集测试覆盖率的时候,怎么避免代码改动导致覆盖率清零 at 2021年03月04日
看你的需求是想要做什么了,我们是做了一层二次处理,如果 id 找不到探针数据,就用 className 再次找一遍做个保底的情况,所以我们在
ExecutionDataStore中 又增加了一个private final Map<String, ExecutionData> classEntries = new HashMap<String, ExecutionData>();这个变量去维护 className 跟探针的关系
-
请问有人测试过 Javascript API 吗?如何测试的? at 2021年02月26日
跟我们测试的 sdk 很像。我们就是通过控制台调用 api 然后通过 selenium 去判断页面是否 ok
-
jacoco 收集测试覆盖率的时候,怎么避免代码改动导致覆盖率清零 at 2021年02月25日
public void put(final ExecutionData data) throws IllegalStateException { final Long id = Long.valueOf(data.getId()); final ExecutionData entry = entries.get(id); if (entry == null) { entries.put(id, data); names.add(data.getName()); } else { entry.merge(data); } }是的,你可以看下这块的逻辑,这个就是按照 classId 然后做数据的合并的。所以如果一定要 只能修改这块的逻辑