-
请教 selenium 或 selenide 怎么获取弹出窗口的元素? at 2018年04月21日
帅哥,遇到这种情况怎么解决啊?
-
请教 selenium 或 selenide 怎么获取弹出窗口的元素? at 2018年04月20日
还是不行啊

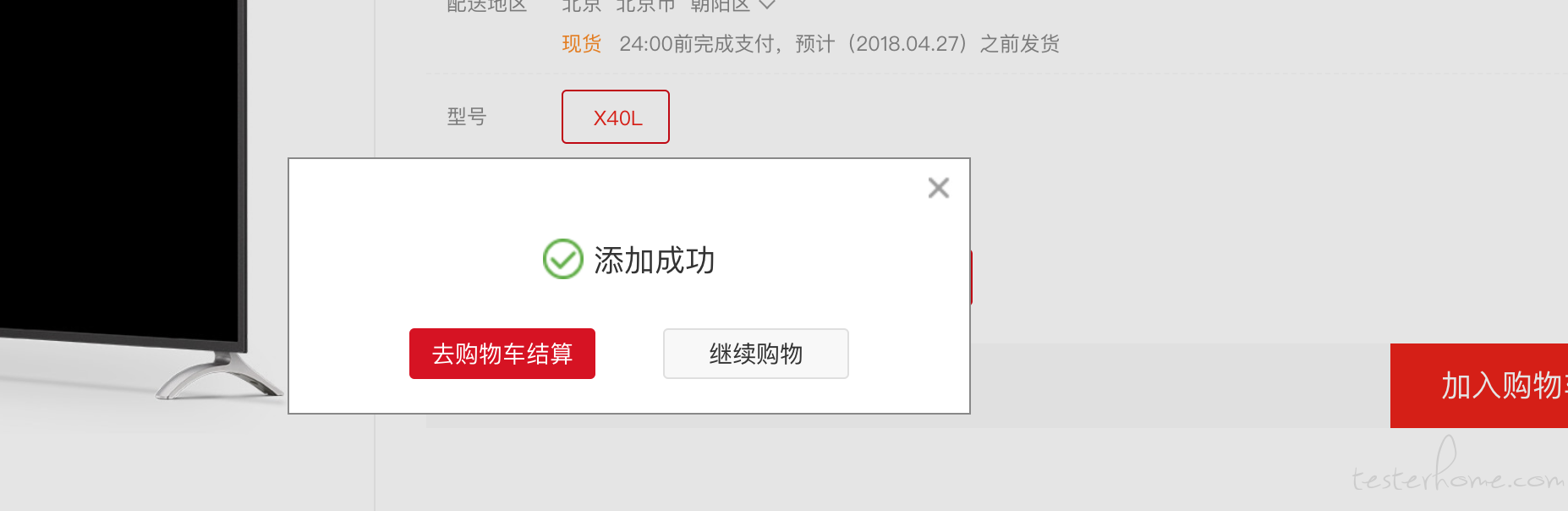
-
请教 selenium 或 selenide 怎么获取弹出窗口的元素? at 2018年04月20日
哥,谢谢你
-
null at 2018年04月19日

可以把你做的实战经验和成果写出来,然后让大家学习学习,同时欣赏你的测试 leader 或大牛也会为你推荐或招募的 -
Selenide 阶段性总结介绍 at 2018年04月18日
刚才试了一下,确实非常简单易用
-
Selenide 阶段性总结介绍 at 2018年04月18日
好嘞,谢谢
-
大家用过的好用的 web UI 自动化框架有哪些? at 2018年04月18日
嗯嗯,收到
-
Selenide 阶段性总结介绍 at 2018年04月18日
好的,我试试
-
大家用过的好用的 web UI 自动化框架有哪些? at 2018年04月18日
@ycwdaaaa 飞哥,除了 selenium, selenide,用 java 开发的,还有什么好用的 UI 自动化框架吗?
-
Selenide 阶段性总结介绍 at 2018年04月18日
飞哥,你的覆盖面太广了,我找个好用的 web UI 自动化框架,也能找到你这里来。
还有其他的推荐吗?关于 web UI 自动化的框架
-
大家用过的好用的 web UI 自动化框架有哪些? at 2018年04月18日
看了一下,selenide 是对 webdriver 做了一些封装,API 使用更加方便了,多谢
-
大家用过的好用的 web UI 自动化框架有哪些? at 2018年04月18日
不想重复造轮子,而且我能力有限,造轮子也造不太好,哈哈
-
多少遗憾在手机功能测试中耗费了多年的时光! at 2018年04月17日
依稀记得,14 年的时候,跟着开发过战斗机模块的领导,用 0101 跟车载终端对话的场景,做 809 协议的帧解析。
从那家公司离开后,再也没有碰到过拥有这样战斗力的领导了。 -
Avatar--行走的接口自动化框架 (支持 dubbo、http/https、mysql) at 2018年04月14日
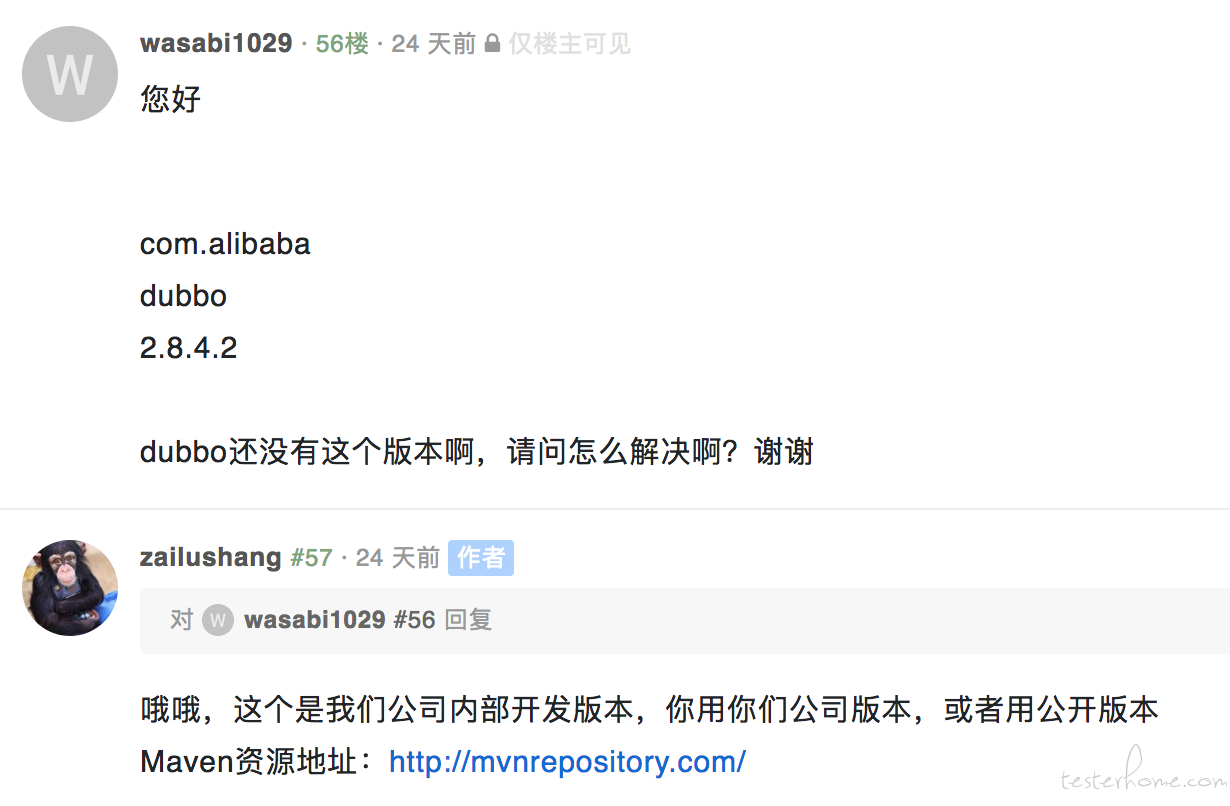
-
求助个关于 TPS 的问题 at 2018年04月12日
这个帖子也加精?
-
有自动化测试成功的案例吗 at 2018年04月12日
看看网易的 Airtest 有多成功
-
查找 UI 元素 (web 元素) at 2018年04月12日
多谢,正在寻找相关信息
-
查找 UI 元素 (web 元素) at 2018年04月12日
网页也是满地坑,我觉得还是需要好好看看前端的东西,不然进度太慢
-
求助个关于 TPS 的问题 at 2018年04月12日

1、理想情况:公式成立情况
TPS=并发数/平均响应时间
前提是服务器处理能力足够优秀,没有任何排队的情况下,网络耗时占响应时间极小的情况下,该公式成立。2、实际情况:
TPS 只跟服务器处理能力有关系,处理能力每秒多少,QPS 或 TPS 就是多少 (暂不考虑:因为排队导致资源紧张,导致服务处理能力下降)。
并发和 tps、响应时间是关联关系,没有固定的公式、比例关系。更多的并发只能证明可能发出更多的请求,不能证明有更多的请求成功和服务器建联。
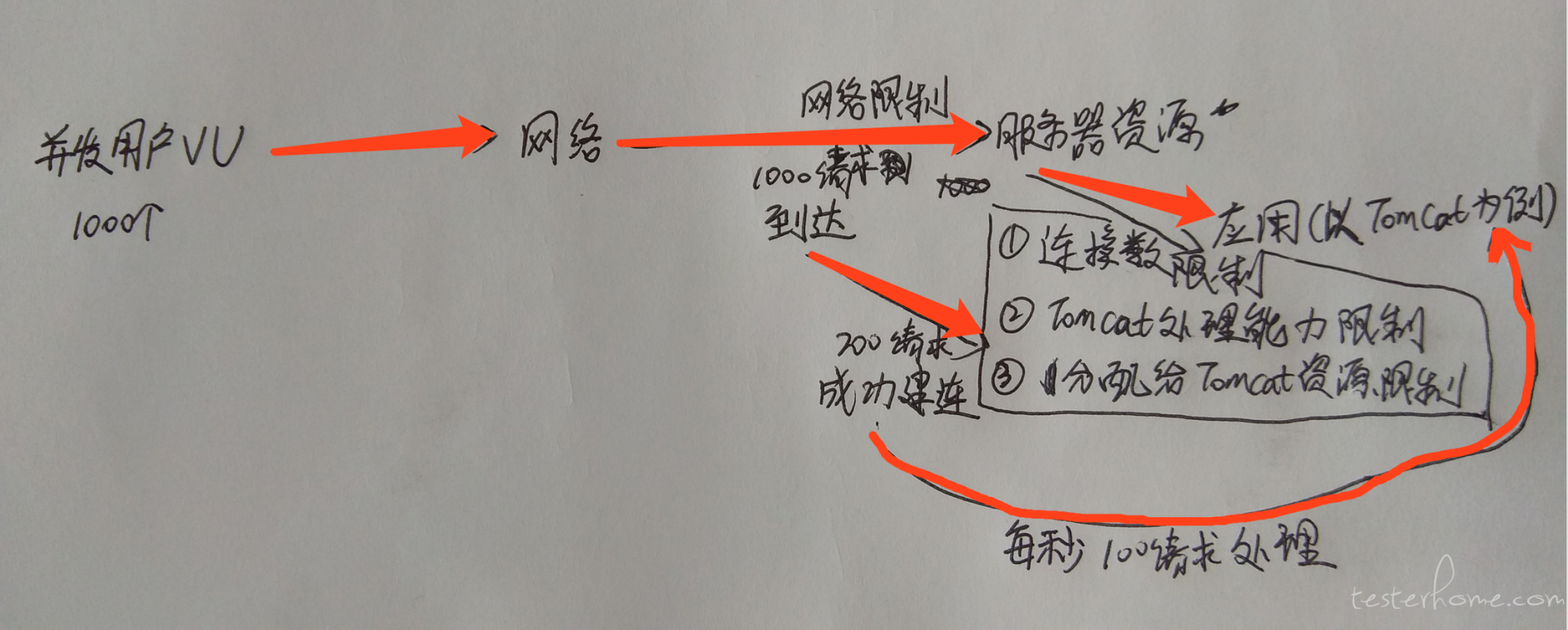
图中数字只是为了说明,并发、TPS 并无直接联系,跟实际情况有关系。 -
查找 UI 元素 (web 元素) at 2018年04月12日
我发现很多元素,这样做了,但是还是报 找不到元素
-
查找 UI 元素 (web 元素) at 2018年04月11日
copy xpath 好用?还是 By.xpath?
-
# 每日一道面试题 # 当线程和 tps 恒定的时候,为啥响应时间在增加? at 2018年04月11日
并发线程 2000,tps 吞吐量只有 300,说明线程处理一定在排队。
排队原因很多:可能是资源限制 (线程排队过多,导致上下文切换较多),可能是连接数限制等等
响应时间越来越长的原因:
第一秒,处理了 300,排队 1700,响应时间 = 处理时间 1 秒;
第二秒,处理了 300,排队 1700-300+300,响应时间=处理时间 1 秒 + 等待时间 1 秒 = 2 秒;
以此类推。。。。 -
现在的中国测试也许和经济结构一样是个 M 型 at 2018年04月10日
你这种就是典型的没脑子,只有充分的市场竞争,行业才会更好地成长。
慈善和公益只要是跟人做,难度都相当大,因为人大多数都是犯贱的。
还有,你敢实名吗?说这种话不敢实名的,估计人品也不咋地
-
接口测试测试报告的自动化生成及存储 at 2018年04月09日
项目体验地址,可以给一个体验的用户名和密码吗?谢谢
-
[求助] 岗位选择:知乎和百度金融 at 2018年04月09日
看你目前的阶段,更适合扩展面,还是深入点。以及对业务的感兴趣程度。
(建议百度,技术体系非一日建成,BAT 的技术体系很厉害,至少内部的专业性技术文章,就够学习和消化了)