-
大家平时是怎么提高自己的? at 2020年04月30日
当然还有一个很重要的东西是, 你需要先研究出一定的成果来跟大家证明你做的这些是有价值的。 这样领导才会给你更多的时间和资源来做这些。 我对这个事情感受颇深。 我原来是 100% 业务的, 后面领导是看到了我做的这些东西越来越有价值, 所以慢慢的把我从业务中抽离出来。 直到现在让基本上大部分时间都专注在工程效能了。
-
大家平时是怎么提高自己的? at 2020年04月30日
深陷业务中是任何人都很难规避的现实。 但从另一个方面看, 就可以多思考怎么能用一些技术手段提高自己的效率, 让自己可以多一点时间去做别的。 这是循环, 就看是良性循环还是恶性循环。 良性循环就是:业务忙-> 挤时间做工程提效的东西 -> 效率提升-> 业务压力减轻-> 有更多的时间做工程提效。 我的经验看我们这里就是这样的。 一开始我们也没时间搞这些东西。 所以那段时间就挤时间去写自动化, 那一个十一期间, 我们光 UI 自动化就累了好几百, 总数破千, 直到现在 UI 自动化破 2000, 有了这些自动化垫底 ,我才有时间去做别的。 怕就是恶性循环。 越是忙,越没时间研究技术做工程提效, 然后就更忙。
-
大家平时是怎么提高自己的? at 2020年04月30日
我都是尽量在工作中提高自己,在工作中发现可以优化的地方,一步一步在工作中提高自己我觉得是最好的。 比如刚来公司的时候是没有自动化部署的, 所以自学 docker,推行容器化部署。 后来团队越来越大, 环境越来越多,要好几台机器上部署很多套环境。 效率越来越差, 所以自学 k8s,全面在测试环境中推行容器编排。 后来产品架构也接入 k8s 并推行微服务, 于是我提出混沌工程和稳定性测试,学习 golang, 调用 k8s 的 client-go 开始开发故障注入工具和稳定性测试工具。 后面为了优化用户提现,又开始学习开发 k8s operator。 就在容器这一条技术栈上, 我一直是在想办法发现目前团队中可以优化的地方, 然后学习新的东西去实践优化。 比如我这两天发现团队中做性能测试的时候针对 jmeter 的痛点, 比如想搭建稳定的分布式 jmeter 压测比较耗时, 比如没办法实时的看 tp99 tps 这些指标只能等测试完了才能看。 所以我针对这个痛点, 现在正在调研在 k8s 上一键部署 jmeter mater/salve influxdb grafana 的这套测试架构。只要成功了就可以提升不少性能测试的效率。
我一直觉得测开要有产品经理的能力, 要会给自己找活, 不断发现优化点,然后去学习去实践。 不要等着别人告诉你要做什么。
-
[面试题] 现在有一个未知大小的日志文件 (可能 100G),要求如果日志文件有包含字符串'error'的行,输出前后 3 行 (包括字符串所在行) 到新的文件中,问怎么实现,用 Python 实现,需要手写到纸上 at 2020年04月27日
过百 G 的我一般直接就 flink 或者 spark 读了。 python 单线程。。。。这得读到哪辈子去。。。
-
各位测试同行,我这样算不算是 [无不正业]? at 2020年04月23日
有些东西,要坚持很久才能有比较好的变现的。 就如郭德纲说岳云鹏一样, 你是在那一夜知道了岳云鹏,但是在那一夜前,岳云鹏在小剧场说了 10 年的相声。 所以很多爱好和兴趣,在一开始的时候都有些不务正业的味道。 但是当你坚持久了, 在这个领域打出名气了。 你就能看到现金变现的路子了。 比如 IT 圈子里很多的技术网红就是如此, 大家可能觉得人家钱来的这么容易, 刷刷脸写写书出出培训课程, 大把大把的钱就挣到手了。 但是能有人买他们的课的背后, 可能是他本人和他身后的团队运行了几年的结果。
-
测试会开发技术在你的职业生涯里真的那么重要吗? at 2020年04月09日
竟然在 2020 年的这个时代下又看到了技术无用论的苗头。。。。。 我真的是很不理解一群技术岗位的人在吵吵学技术没用这是个什么状态。 我感觉有些同学陷入了一个恶性循环。 不懂技术->导致不了技术类工作->导致长期用不上技术->导致以为学技术没用->导致继续不懂技术。 然后就只能整天抱怨又没什么办法了。 这个话题我真不想再吵了,你们觉得没用就没用吧,学不学做不做都是自己的事。 消极的人只能整日抱怨维持现状,积极的人不断学习升职加薪。
-
命令后面加分号然后接着下一跳命令~~~ 命令太多就写成脚本,先用 kubectl cp 命令 copy 到容器里。然后在 kubectl exec 去执行~
-
感觉这里堕落了 at 2020年04月01日
额, 我感觉我还是很努力的在写文章了。 基本上平均 2 个礼拜更新一次
-
持续集成的开源方案攻略 (三) jenkins pipeline 与 k8s 集成 at 2020年04月01日
用一段我写故障注入的注释来说明一下吧。

基本上就是 jenkins 也是用 exec 这个方式来像容器发送命令的,基本上是读取不到你定义的环境变量的。 这个问题我至今还没有找到原因。 所以你还是用 jenkins pipeline 中的环境变量语法,来搞这些事把
-
求一些 java 编写开源的 接口自动化项目 at 2020年03月23日
我是用 xml 哈哈哈, 这玩意随意了, 想用啥用啥
-
求一些 java 编写开源的 接口自动化项目 at 2020年03月23日
恩 很强, 我们测接口都用这玩意
-
你也可以用这个, 只不过你要测试什么版本就搭建什么虚拟机 + 浏览器。 然后注册到 grid hub 上就好了
-
尽量不要拿 docker 做兼容性测试, 它用的毕竟是 linux 内核。 用户是不会用 linux 系统访问你们的产品的。
-
kubectl 的命令不是这么用的~~~ kubectl exec -it podname bash 这个命令是使用 tty 打开了容器的 bash shell 窗口。 脚本不是你在 shell 里做命令交互~~ exec 是让容器执行命令的, 所以你直接用 kubectl exec podname 你要执行的命令 就行了
-
请教有两个 Windows 阿里服务器,如何可以让他们的一个文件夹共享 at 2020年03月20日
就 nfs 就行了吧
-
求一些 java 编写开源的 接口自动化项目 at 2020年03月20日
java 界 无可争议的 接口测试工具: rest-assured
-
想问一下各位大佬,现在都怎么做兼容性测试啊 at 2020年03月20日
只做过 web 端的, 就是用 grid 做
-
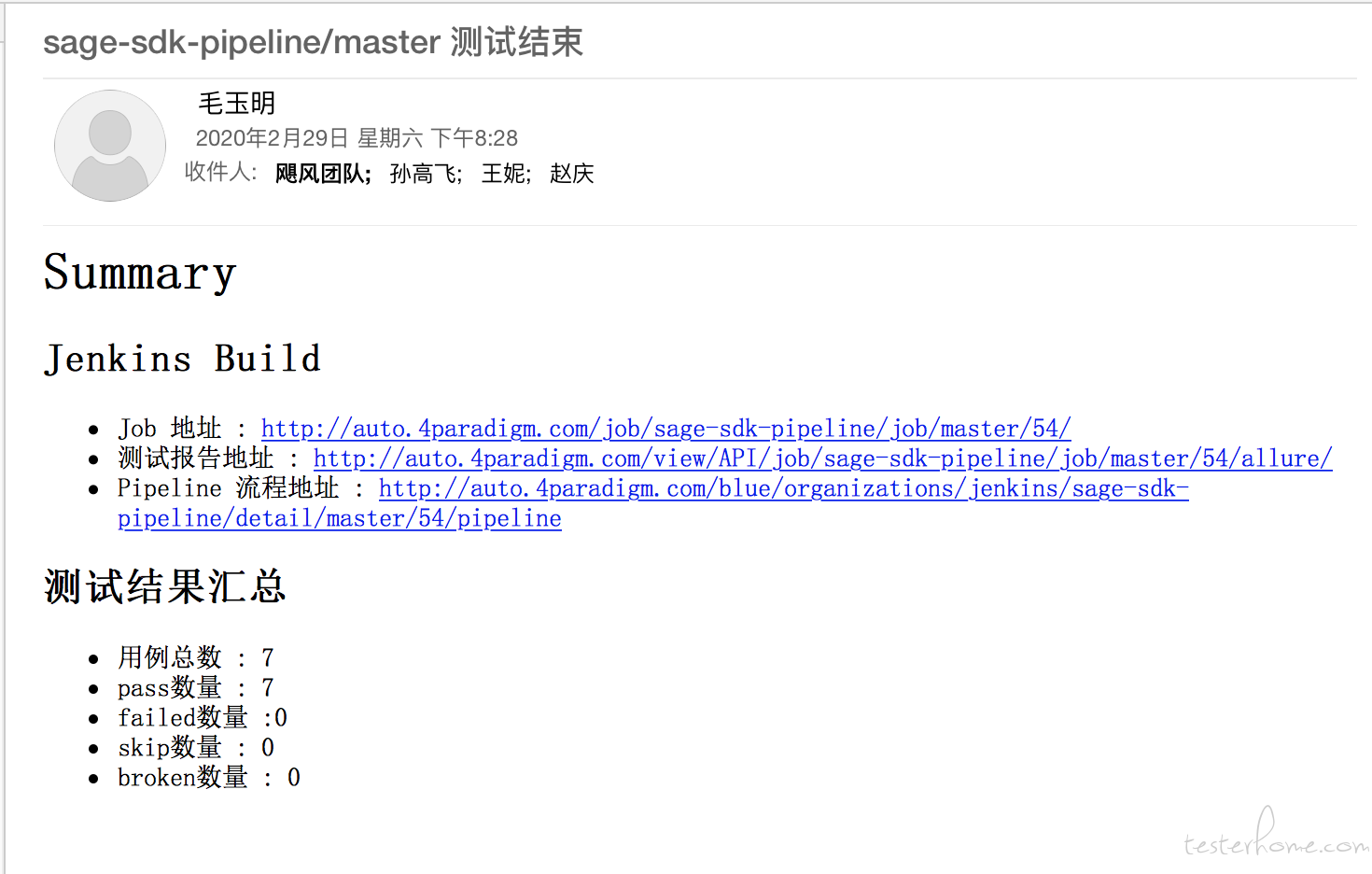
[求助] 如何把 allure 的 index.html 所显示的内容,展示在 jenkins 发送的 Email 中? at 2020年03月20日
效果图如下:
-
[求助] 如何把 allure 的 index.html 所显示的内容,展示在 jenkins 发送的 Email 中? at 2020年03月20日
这个很简单啊, allure 在 jenkins 上的插件也是用 allure command line 启动的一个服务。 暴露了 http 接口。 你可以从中获取测试结果的。我是写了一段 groovy 脚本来抓取 allure report 的结果的。 可以使用 pipeline 来 执行 groovy 脚本,你也可以在其他 job 中添加 groovy script 这个步骤。 你可以参考我这里的脚本。代码如下:
/** * Created by sungaofei on 20/2/8. */ @Grab(group = 'org.codehaus.groovy.modules.http-builder', module = 'http-builder', version = '0.7') import groovyx.net.http.HTTPBuilder import static groovyx.net.http.ContentType.* import static groovyx.net.http.Method.* import groovy.transform.Field //global variable @Field jenkinsURL = "http://auto.4paradigm.com" @Field failed = "FAILED" @Field success = "SUCCESS" @Field inProgress = "IN_PROGRESS" @Field abort = "ABORTED" @NonCPS def String checkJobStatus() { def url = "" if (env.BRANCH_NAME!= "" && env.BRANCH_NAME != null){ String jobName = "${JOB_NAME}".split("/")[0] url = "/view/API/job/${jobName}/job/${env.BRANCH_NAME}/${BUILD_NUMBER}/wfapi/describe" }else { url = "/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/wfapi/describe" } HTTPBuilder http = new HTTPBuilder(jenkinsURL) String status = success println("1111111111") println("${JOB_NAME}") println(url) http.get(path: url) { resp, json -> if (resp.status != 200) { throw new RuntimeException("请求 ${url} 返回 ${resp.status} ") } List stages = json.stages for (int i = 0; i < stages.size(); i++) { def stageStatus = json.stages[i].status if (stageStatus == failed) { status = failed break } if (stageStatus == abort) { status = abort break } } } return status; } @NonCPS def call(String to) { println("邮件列表:${to}") def reportURL = "" String jobName = "${JOB_NAME}" String blueOCeanURL = "" if (env.BRANCH_NAME!= "" && env.BRANCH_NAME != null){ jobName = "${JOB_NAME}".split("/")[0] reportURL = "/view/API/job/${jobName}/job/${env.BRANCH_NAME}/${BUILD_NUMBER}/allure/" // http://auto.4paradigm.com/blue/organizations/jenkins/gitlabtest/detail/master/217/pipeline blueOCeanURL = "${jenkinsURL}/blue/organizations/jenkins/${jobName}/detail/${env.BRANCH_NAME}/${BUILD_NUMBER}/pipeline" }else{ reportURL = "/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/allure/" blueOCeanURL = "${jenkinsURL}/blue/organizations/jenkins/${JOB_NAME}/detail/${JOB_NAME}/${BUILD_NUMBER}/pipeline" } def sendSuccess = { // blueOCeanURL = "${jenkinsURL}/blue/organizations/jenkins/${JOB_NAME}/detail/${JOB_NAME}/${BUILD_NUMBER}/pipeline" def fileContents = "" def passed = "" def failed = "" def skipped = "" def broken = "" def unknown = "" def total = "" HTTPBuilder http = new HTTPBuilder('http://auto.4paradigm.com') //根据responsedata中的Content-Type header,调用json解析器处理responsedata http.get(path: "${reportURL}widgets/summary.json") { resp, json -> println resp.status passed = json.statistic.passed failed = json.statistic.failed skipped = json.statistic.skipped broken = json.statistic.broken unknown = json.statistic.unknown total = json.statistic.total } println(passed) emailext body: """ <html> <style type="text/css"> <!-- ${fileContents} --> </style> <body> <div id="content"> <h1>Summary</h1> <div id="sum2"> <h2>Jenkins Build</h2> <ul> <li>Job 地址 : <a href='${BUILD_URL}'>${BUILD_URL}</a></li> <li>测试报告地址 : <a href='${jenkinsURL}${reportURL}'>${jenkinsURL}${reportURL}</a></li> <li>Pipeline 流程地址 : <a href='${blueOCeanURL}'>${blueOCeanURL}</a></li> </ul> <h2>测试结果汇总</h2> <ul> <li>用例总数 : ${total}</li> <li>pass数量 : ${passed}</li> <li>failed数量 :${failed} </li> <li>skip数量 : ${skipped}</li> <li>broken数量 : ${broken}</li> </ul> </div> </div></body></html> """, mimeType: 'text/html', subject: "${JOB_NAME} 测试结束", to: to } def send = { String subject -> emailext body: """ <html> <style type="text/css"> <!-- --> </style> <body> <div id="sum2"> <h2>Jenkins Build</h2> <ul> <li>Job 地址 : <a href='${BUILD_URL}'>${BUILD_URL}</a></li> <li>测试报告地址 : <a href='${jenkinsURL}${reportURL}'>${jenkinsURL}${reportURL}</a></li> <li>Pipeline 流程地址 : <a href='${blueOCeanURL}'>${blueOCeanURL}</a></li> </ul> </div> </div></body></html> """, mimeType: 'text/html', subject: subject, to: to } String status = checkJobStatus() // String status = $BUILD_STATUS println("当前job 的运行状态为: ${status}") switch (status) { case ["SUCCESS", "UNSTABLE"]: sendSuccess() break case "FAILED": send("Job运行失败") break case "ABORTED": send("Job在运行中被取消") break default: send("Job运行结束") } } -
持续集成的开源方案攻略 (三) jenkins pipeline 与 k8s 集成 at 2020年03月20日
不要在 jnlp 容器里用 cat 命令~~~ 加 cat 命令的目的是让其他容器能一直持续运行~~ jnlp 是 slave 容器, 不用加
-
持续集成的开源方案攻略 (三) jenkins pipeline 与 k8s 集成 at 2020年03月18日
我们很无脑的用的 nfs 哈哈哈哈。 ceph 现在没在用了。 因为我们没那么高的性能要求
-
吐槽下我那神奇的上司 at 2020年02月27日
额, 6 楼是我, 楼主可以去翻我写的 spark 的帖子。 刚才忘了解除匿名了
-
持续集成的开源方案攻略 (四) jenkins 与 k8s 集成的通信原理与配置记录 at 2020年02月25日
部署的时候配置域名跟 ingress 集成起来是这样的。 首先需要到你们的 dns 中添加一个泛域名解析。 解析地址填写你 ingress controller 的地址。 比如我们做的凡是以 testenv.4pd.io 为结尾的域名全部解析成我们 ingress controller 的 ip 地址。 然后为每一个环境创建一个 ingress 规则。 比如我们曾经做的:
def create_ingress_yaml(config): document = """ apiVersion: extensions/v1beta1 kind: Ingress metadata: name: %s annotations: nginx/client_max_body_size: 10240m nginx.org/client-max-body-size: "10240m" ingress.kubernetes.io/proxy-body-size: 10240m spec: rules: - host: %s.testenv.4pd.io http: paths: - path: / backend: serviceName: %s servicePort: 8888 - host: %s.preditor.testenv.4pd.io http: paths: - path: / backend: serviceName: %s servicePort: 8090 - host: %s.history.testenv.4pd.io http: paths: - path: / backend: serviceName: %s servicePort: 18080 """ % (config.pht_pod_name, config.name_prefix, config.pht_pod_name, config.name_prefix, config.pht_pod_name, config.name_prefix, config.pht_pod_name) data = yaml.load_all(document) with open(config.ingress_conf_path, 'w') as stream: yaml.dump_all(data, stream)在部署环境的时候就把 ingress 创建好。 然后配合泛域名解析,ingress controller 会自动的帮我们转发请求到具体的环境上。 就可以达到每个环境都自动的有一个域名对应上了。
部署其实很简单, 就像我上面做的那样就好。 维护一套 yaml 模板动态的去生成部署这些模块的 k8s 配置就可以了。
-
持续集成的开源方案攻略 (四) jenkins 与 k8s 集成的通信原理与配置记录 at 2020年02月25日

-
持续集成的开源方案攻略 (三) jenkins pipeline 与 k8s 集成 at 2020年02月24日
go 就直接用 vendor 吧, 直接在项目里把依赖打成 vendor 就好了。 不要用 go mod 下载或去 worksapce 里找依赖。