-
2025 年度总结 at 2025年12月02日
加油!我也是今年才晋升成奶爸的。这一路走来,看着宝妈为孩子忙前忙后,月子结束就要兼顾工作,我由衷地觉得她太不容易了。
-
大家在公司称呼同事什么呢? at 2025年11月26日
每个公司还不一样,在某家国企性质的一般同事都是老 + 姓,后面去了某民营企业姓或者名 + 老板,现在在外资企业都是叫英文名。
-
一个自然语言低代码用例开发框架思考 at 2025年10月28日
https://flybirds.readthedocs.io/zh-cn/latest/BDD-UI-Testing-Flybirds.html#id103 ,美团的已开源自动化框架。早几年前在顺丰也做过类似基于 behave 的自动化平台,不过没有开源出来。
-
最近我发现有年级大的 活的很消极 为什么不能快乐阳光的面向生活呢 at 2025年06月19日
小时候一块糖,一个小玩具,一个跟头,都是幸福的时刻。后来,经历了 “情随事迁”、“悲欢离合”、“物是人非”,不得不感慨 “向之所欣,俯仰之间,已为陈迹”。就如兰亭集序的片段:
夫人之相与,俯仰一世。 或取诸怀抱,悟言一室之内; 或因寄所托,放浪形骸之外。 虽趣舍万殊,静躁不同,当其欣于所遇,暂得于己,快然自足,不知老之将至; 及其所之既倦,情随事迁,感慨系之矣。 向之所欣,俯仰之间,已为陈迹,犹不能不以之兴怀,况修短随化,终期于尽! 古人云:“死生亦大矣。” 岂不痛哉! -
走还是不走 at 2025年05月29日
家里没有矿,银行没有足够的存款的情况下,工作第一目的是为了谋生,其次再是价值(社会价值和情绪价值)追求。现在大环境不是很乐观,如果没有更好的选择,建议还是先将就一下吧。
-
社区管理员召集令!跟帖回复即可 at 2025年05月21日
跟贴
-
测试用例最佳实践 at 2024年08月28日
我的一些经历和现状:很多都是测试接到需求,到交付的时间,只有一周的时间。而且这样的测试任务并行多个;迭代频率高,测试交付周期短,实际测试工作用思维导图做下测试分析,明确测试的范围、测试点、标注侧重点。所谓的最佳测试用例实践,没有统一答案,实际情况不同,最佳测试用例实践就不同。就像有人说 php 是最好的编程语言,也是一样的道理。
-
某大厂的机试题,解压压缩的字母串。 at 2021年07月13日

-
某大厂的机试题,解压压缩的字母串。 at 2021年07月13日
很厉害呀!可是 30[k] 呢 ,测试不通过。还得优化一下
-
某大厂的机试题,解压压缩的字母串。 at 2021年07月13日
你的思路还是不错的,但是字母压缩还有一种情况:m3[k] 2[am] 。这种情况还需要优化考虑一下
-
某大厂的机试题,解压压缩的字母串。 at 2021年07月13日
比我的强
-
python 小脚本 (实现 elasticsearch 导出导入) at 2021年06月02日
mappings 就是 es 存储数据的文档结构,相当于数据库的表结构,关于 mappings 怎么填写获取,我注释里面有写。properties 就是文档内容,这里怎么填写要看你自己的文档内容了,我这里提供了方式方法,但是不包教学。我觉得这些基本的 es 知识多去 baidu,Google 学习一下,那上面的内容比我在这里说的专业详细。
-
python 小脚本 (实现 elasticsearch 导出导入) at 2021年06月01日
有引用呀

,导入哪里就填哪里的 -
python 小脚本 (实现 elasticsearch 导出导入) at 2021年06月01日
导入步骤就是在测试环境创建 index,再创建 mapping,再解析已经导出的文件,构造数据,导入到新环境,就是这样,都有注释的,具体哪里不懂?
-
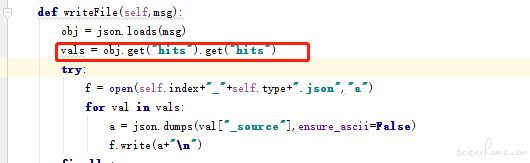
python 小脚本 (实现 elasticsearch 导出导入) at 2021年06月01日
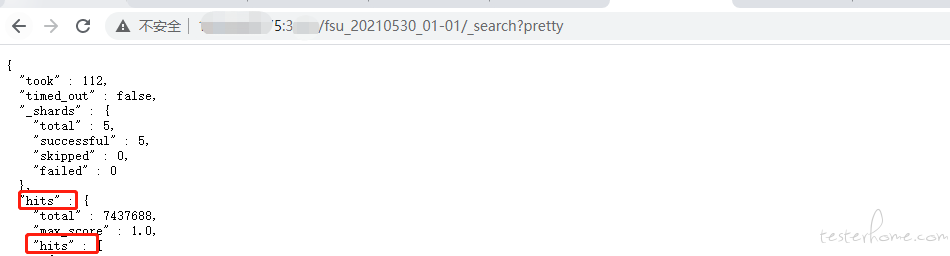
你看下,这里是否有两个 hits。
调整一下代码:
-
python 小脚本 (实现 elasticsearch 导出导入) at 2020年07月24日
数据量大的时候是比较慢,百万级别内还是可以用的
-
python 问题求助大佬们 at 2019年03月01日
年会,应该要多一个操作,就是已中奖的要去掉,不能重复中奖。
-
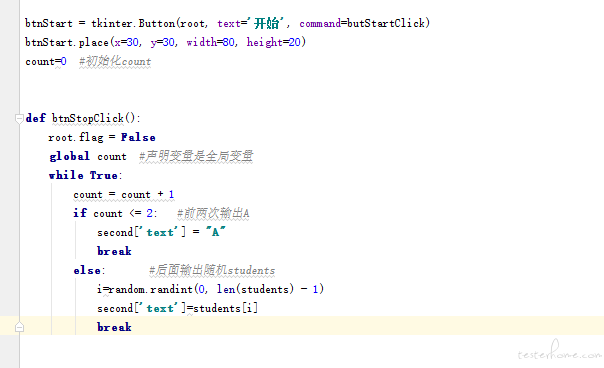
python 问题求助大佬们 at 2019年03月01日
-
老生杂谈 at 2019年02月28日
notepad++ 复制过来的
-
老生杂谈 at 2019年02月28日
我什么时候成大佬了?你认识我吗?
-
老生杂谈 at 2019年02月28日
由于大数据的源来自各个业务系统,各个业务系统的数据质量是不可控,所以在数据处理过程中,怎么保证最终数据质量,是个难点。怎么验证保证 etl 过程正确性和最优性,这需要对各个业务系统要有相应的了解程度。总而言之,不过什么测试最终要熟悉还是业务!
-
老生杂谈 at 2019年02月28日
依我个人经历来说吧。数据库方面的基础知识,数据仓库的理念,Hadoop 分布式系统架构,还有就是相关的 spark、hive、hue 。差不多就是这些吧。
-
笔试题 at 2018年12月28日
闲着做了下,代码奉上,没有多想。
#coding=utf-8 import re str1=open('./xxx.csv',encoding='utf-8').read() #读出文件 reword={'今天','天气','真赞'} #列出要匹配文字 setreword={} #初始化计数统计字典 for word in reword: #基数统计 count=0 for i in re.finditer(word,str1): #全文匹配计数 count=count+1 setreword[word]=count #设置字典 serewordorder=sorted(setreword.items(),key=lambda x:x[1]) #字典排序 print(setreword) #打印结果 str1.close() -
如何看待 antd 圣诞节彩蛋事件? at 2018年12月25日
你想埋我一个彩蛋给我,我踩到的是一颗炸弹。。。
