WeTest腾讯质量开发平台 移动平台 Unity3D 应用性能优化
作者:陈星百,腾讯移动客户端开发 工程师
商业转载请联系腾讯 WeTest 获得授权,非商业转载请注明出处。
原文链接:http://wetest.qq.com/lab/view/315.html
WeTest 导读
做了大概半年多 VR 应用了,VR 由于双眼 double 渲染的原因,对性能的优化要求比较高,在项目的进展过程中,总结了一些关于移动平台上 Unity3D 的性能优化经验,供分享。
一、移动平台硬件架构
移动平台无论是 Android 还是 IOS 用的都是统一内存架构,GPU 和 CPU 共享一个物理内存,通常我们有 “显存” 和 “内存” 两种叫法,可以认为是这块物理内存的所有者不同,当这段映射到 cpu,就是通常意义上的内存;当映射到 gpu,就是通常意义上的显存。并且同一段物理内存同一时刻只会映射到一个 device。
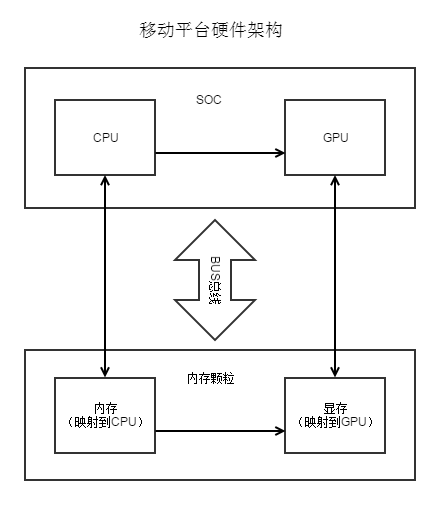
即使是在同一物理内存上 ,之前的 openGL ES 规范中 CPU 和 GPU 之间的内存是不能共享的,vertex 和 texture 的 buffer 是需要拷贝的。后面出来的 vulkan 与 IOS 的 metal 可以共享内存。
了解了移动平台的硬件架构,就知道了 1)CPU 2) 带宽 3) GPU 4) 内存 都有可能成为移动平台 3D 应用性能瓶颈。
二、移动平台 3D 应用的画面渲染过程
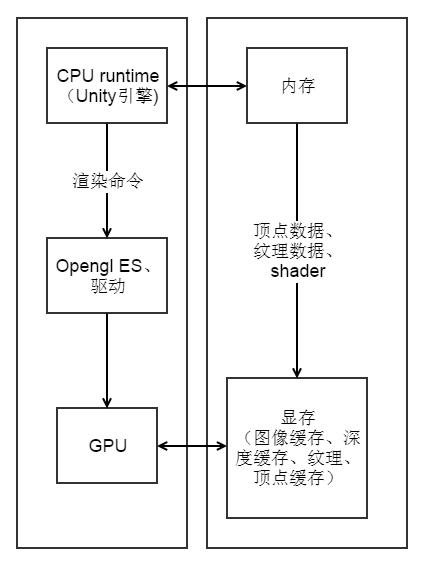
1、CPU 通过调用绘制命令(称为一次 Draw Call)来告诉 GPU 开始进行一个渲染过程的。一个 Draw Call 命令会指向本次绘制需要渲染的信息,这些信息包括:顶点数据、纹理数据、shader 参数(光照模型、法线方向、光照方向等)等,简单地说就 画什么,用什么画,怎么画。
2、GPU 接收到 Draw Call 命令之后就会开始进行一次单元渲染,关于 GPU 的单元渲染的过程是这样的(简单示意图):
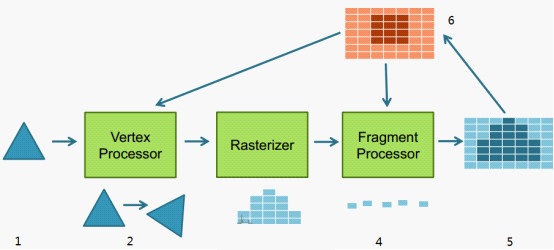
1)从显存中取出拷贝的顶点数据和光照模型。
2)通过顶点处理器(Vertex Processor)对顶点数据进行一系列的变换和光照处理,包括裁剪处理。tips: 简单的想想,游戏中的各个物体的坐标都是参照游戏中的世界坐标系的,而实际显示的画面是玩家视角或者摄像机视角,这中间就有许多坐标系的转换。这些活就需要顶点处理器来做,最终我们得到了我们所需要视角的画面。
3)到这一步,画面还只是一些多边形,而实际显示在屏幕上的是一个个像素,这里就需要(光栅处理器)Rasterizer 进行光栅化(Rasterization),从而将画面变成一个像素图,把所有的顶点对应到一个一个的像素位置。
4)对这些像素进行上色,通过片元处理器(Fragment Processor)中的像素着色器(Pixel Shader)按照 shader 光照模型,根据纹理对应位置颜色,计算元颜色,再经过深度计算、透明测试计算出每个像素的最终颜色。
5)把结果输出到图像缓存中,全部完成后拿去显示。
三、Unity3D 应用性能优化之 CPU
CPU 的优化非常重要,CPU 的表现直接决定了 VR 应用的帧率,应用的耗电量,发热量。我们来看看相比于普通的 app,VR 应用的 CPU 都承担了什么责任:a、业务逻辑 b、网络通信 c、I/O 操作 d、drawcall e、physic 逻辑 f、GC 内存回收 g、垂直同步等待。
业务逻辑、网络通信、I/O 操作
这一块的优化和普通的 app 差不多。
关于业务逻辑:有些不同的是 Unity 脚本中有一类 update 方法(Update、FixedUpdate、OnGUI 等),这一类方法是在每帧刷新的时候调用的,是比较影响每帧耗时的,为了严格控制这一部分的执行时间,需要注意的以下几点:
a、尽量不要再 Update 函数中做复杂计算,如有需要,可以隔 N 帧计算一次,对于纯数学计算,可以开辟新线程来计算(Unity 为什么一般避免使用多线程, 实际上大多数游戏引擎也都是单线程的, 因为大多数游戏引擎是主循环结构, 逻辑更新和画面更新的时间点要求有确定性, 如果在逻辑更新和画面更新中引入多线程, 就需要做同步而这加大了游戏的开发难度。UnityEngine 绝大多数类是不支持子线程的,所以一般只有纯数学计算才会用到子线程去计算。)
b、关闭所有在 update 类中执行 log 的打印操作 (Unity 中一次 log 打印有时长达 7ms,Profiler 数据)。
c、不在 update 类方法调用 Getcomponent、SendMessage、FindWithTag 这几个耗时较长的方法。
d、不在 update 类方法中使用临时变量。
关于网络通信、I/O 操作:这些普通 app 的优化和注意点没有什么很大区别,有一点是,Unity 工程中使用了资源动态加载,有些资源是保存在服务器端的,在有必要的时候才会通过网络 load 下去加载。这个资源动态加载需要注意一个问题:由于网络通信过程,CPU 总是处于等待的状态,一般资源下载是多线程同时操作,为了尽快上屏显示资源(在这个工程中是一些图片和英雄的 3D 模型),但是资源有可能是在同一个帧周期中下载完毕的,如果直接加载的话,可能会出现 Camera 瞬时渲染过多三角形面,造成渲染时间(Camera.Render() 函数执行时间)过长,,卡顿的现象。所以这里要注意,网络下载可以多线程多任务同时下载,但是在 Unity 主线程,要避免出现同时加载大型模型和大纹理的情况,最好使用队列的方式,保证一帧只渲染一个 3D 模型。
关于 GC
为什么要把 GC 放在 CPU 这一部分?虽然 GC 是用来处理内存回收的,但是却增加了 CPU 的开销(GC 一次开销可长可短,有时长达 100ms)。因此对于 GC 的优化目标就是尽量少的触发 GC。
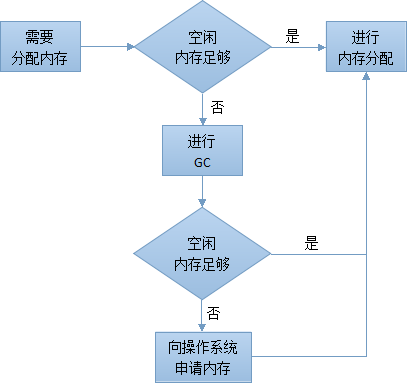
首先我们要知道所谓的 GC 是 Mono 运行时的机制,而非 Unity3D 游戏引擎的机制,所以 GC 也主要是针对 Mono 的对象来说的,而它管理的也是 Mono 的托管堆。 明白了这一点,你也就明白了 GC 不是用来处理引擎的 Assets(贴图,音效,模型等等)的内存释放的,因为 U3D 引擎也有自己的内存堆而不是和 Mono 一起使用所谓的托管堆。其次我们还要清楚什么东西会被分配到托管堆上?对,就是引用类型。引用类型包括:用户自定义的类,接口,委托,数组,字符串,Object.而值类型包括:几种基本数据类型(如:int,float,bool 等),结构体,枚举,空类型。所以 GC 的优化也就是代码的优化。
那么 GC 什么时候会触发呢?两种情况:
a、当我们的堆的内存不足时,会自动调用 GC 来回收内存。
b、手动的调用 GC,用 System.GC.Collect(),一般情况下,不建议手动去手动进行内存回收,因为容易出现问题。
检查整个工程代码,关于减少 GC 这一方面的优化经验总结大概如下:
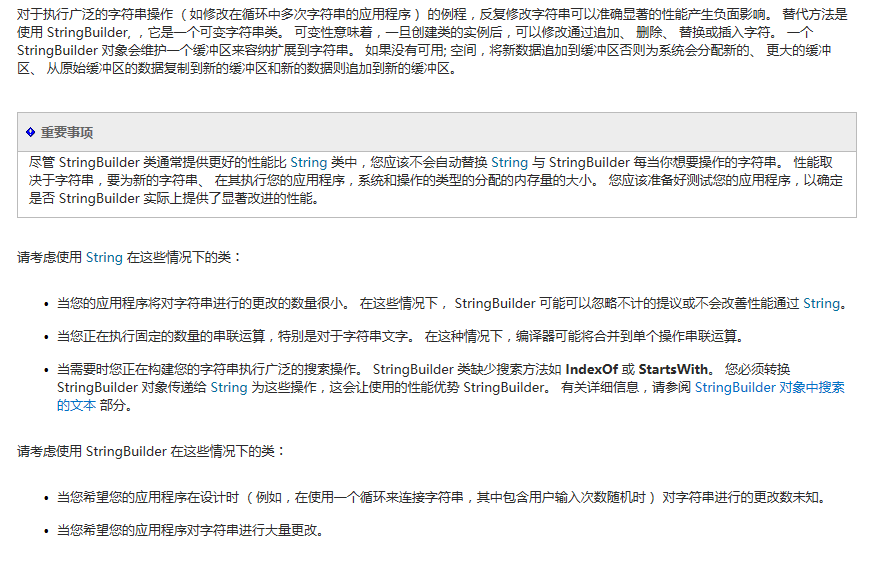
1、字符串连接的处理。因为将两个字符串连接的过程,其实是生成一个新的字符串的过程。而之前的旧的字符串自然而然就成为了垃圾。而作为引用类型的字符串,其空间是在堆上分配的,被弃置的旧的字符串的空间会被 GC 当做垃圾回收,可以使用 StringBuilder 来解决(注意:C# 没有 StringBuffer,Java 里才有!!String 在进行运算时(如赋值、拼接等)会产生一个新的实例,而 StringBuilder 则不会。所以在大量字符串拼接或频繁对某一字符串进行操作时最好使用 StringBuilder,不要使用 String)。
2、尽量不要使用 foreach,而是使用 for。foreach 其实会涉及到迭代器的使用,而据传说每一次循环所产生的迭代器会带来 24 Bytes 的垃圾。那么循环 10 次就是 240Bytes。
3、不要直接访问 gameobject 的 tag 属性。比如 if (go.tag ==“human”) 最好换成 if (go.CompareTag (“human”))。因为访问物体的 tag 属性(每次 Object.name 也会分配 39B 的堆内存.)会在堆上额外的分配空间。如果在循环中这么处理,留下的垃圾就可想而知了。
4、不要实例化(Instantiate)和(Destroy)对象,事先建好对象池,以实现空间的重复利用。
5、在某些可能的情况下,可以使用结构(struct)来代替类(class)。这是因为,结构变量主要存放在栈区而非堆区。因为栈的分配较快,并且不调用垃圾回收操作,所以当结构变量比较小时可以提升程序的运行性能。但是当结构体较大时,虽然它仍可避免分配/回收的开销,而它由于"传值"操作也会导致单独的开销,实际上它可能比等效对象类的效率还要低。所以要注意选择。
6、场景切换时,可以主动进行垃圾回收(调用 System.GC.Collect()),从而及时去除游戏中已经不必要地内存占用。
Draw Call 的优化
前面说过了,DrawCall 是 CPU 调用底层图形接口的操作。比如有上千个物体,每一个的渲染都需要去调用一次底层接口,而每一次的调用 CPU 都需要做很多工作,那么 CPU 必然不堪重负。但是对于 GPU 来说,图形处理的工作量是一样的。
我们先来看看 Draw Call 对 CPU 的消耗大概是一个什么级别的量:
NVIDIA 在 GDC 曾提出,25K batchs/sec 会吃满 1GHz 的 CPU,100% 的使用率。有一个公式可以和清楚得计算出在给定的 CPU 资源 与 帧率的情况下,最多能有多少个 DrawCall。
DrawCall_Num = 25K * CPU_Frame * CPU_Percentage / Framerate。
DrawCall_Num : DrawCall 数量
CPU_Frame : CPU 工作频率(GHz 单位)
CPU_Percentage:CPU 分配在 DrawCall 这件事情上的时间率(百分比)
Framerate:希望的游戏帧率
比如说我们使用一个高通 820,工作频率在 2GHz 上,分配 10% 的 CPU 时间给 DrawCall 上,并且我们 VR 要求 60 帧,那么一帧最多能有 83 个 DrawCall(由于双 camera 的存在,单眼 DrawCall 只能保证在 41 个以内)。其实,google 官方的建议是单眼 DrawCall 不多于 50 个。
所以对 DrawCall 的优化,主要就是为了尽量解放 CPU 在调用图形接口上的开销。所以针对 drawcall 我们主要的思路就是每个物体尽量减少渲染次数,多个物体最好一起渲染。那么 DrawCall 次数的优化有哪些方案呢?
DC Batching(DC 批处理)
batch 即批处理,DrawCall batching 即 DC 的批处理,即把多次 DrawCall 合并成一次 DrawCall 的方案。
Dynamic Batching 动态批处理
Unity 引擎对于使用相同材质的物体会自动进行批处理,相同材质意味着 shader 完全一样,这一部分主要是要注意那些破坏这一特性的人为因素,比如说:
1、批处理动态物体需要在每个顶点上进行一定的开销,所以动态批处理仅支持小于 900 顶点的网格物体,如果你的着色器使用顶点位置,法线和 UV 值三种属性,那么你只能批处理 300 顶点以下的物体(如果在这基础上还使用了 UV2,则只能批处理 180 顶点以下的物体);请注意:属性数量的限制可能会在将来进行改变。
2、使用不同的缩放比例的物体,unity 将无法对这些物体进行批处理。比如(1,1,1)和(1,2,2)就不会动态批处理,但是(1,1,1)和(2,2,2)会动态批处理。
3、拥有 lightmap 的物体含有额外(隐藏)的材质属性,比如:lightmap 的偏移和缩放系数等。所以,拥有 lightmap 的物体将不会进行批处理(除非他们指向 lightmap 的同一部分)。接受实时阴影的物体也不会批处理。
4、多通道的 shader 会中断批处理操作(为了达到特殊的渲染目的,可能某个物体要多遍渲染.这是就要多个通道)。
5、在脚本中动态地指定了物体的材质,也不会进行批处理。
Static Batching 静态批处理
动态批处理虽然是自动的,但是限制非常多,不小心就会打破批处理,所以 unity 在专业版中还提供了静态批处理,静态批处理要求是想批处理的物体一定是 static 的,静态的,不会改变位置和旋转角度以及缩放的,且必须材质一致。其原理是把物体的网格进行合并,变成一个静态的更大的网格物体,再使用一个统一的材质进行渲染。
知道了它的原理,它的某些坑就比较清晰了:
1、在一个平行光、环境光下,没有问题,但是如果你使用了多个平行光,点光源,聚光灯这种复杂的光源去照射物体,那么静态批处理就会被打断。(项目中就遇到过,因为两边有两排英雄模型,所以场景中使用了两个不同平行光,场景中勾选的 static 物体并没有被合并 drawcall,经过一番折磨才找到原因)。
2、如果静态批处理前有一些物体共享了相同的网格,那么每一个物体都会有一个该网格的复制品(本来 unity 只会保留一份,但是静态批处理会生成新的一个大网格,所以会保留所有物体的网格,最后合并),即一个网格会变成多个网格被发送给 GPU。这样会造成内存的使用变大,需要注意这个问题,但是一般场景中使用相同网格的物体会比较少。
3、对于那些 shader 相同,纹理不同导致的不同材质无法进行批处理的物体(比如项目中的场景环境,基座,地面,其实都使用了 unity 自带的 standard shader)可以通过纹理合并的方法来使得它们可以被静态批处理。这就引发了下面的事情:
BUS 总线带宽
CPU 完成一次 DrawCall,除了需要发一个 DrawCall 的命令之外,还需要把内存中顶点数据、纹理贴图、shader 参数通过 bus 总线拷贝到内存分配给 GPU 的显存之中,注意这是拷贝,不是指针传递,速度不快。如果一次 drawcall 传递的数据过大,带宽成为了瓶颈,那就会大大影响效率(其它的 DrawCall 无法出发,GPU 又处于闲置)。这种情况最有可能出现在为了减少 DrawCall,疯狂的合并纹理上。在项目中,UI 的 DrawCall 调用占了很大一部分,也会最难优化的,为了减少 drawcall ,我们把 UI 模块的静态部分(一些 UI 的底板,背景等不会发生变化的)全部合并成了一个纹理,最后导致了 DrawCall 下降了,但是帧率却也下降了,内存使用也增加了,原因就是这个。在项目中,不会同时出现的元素不要打包到一起,保证单张合并纹理不大于 1024*1024 一般就不会有问题了(王者荣耀最大纹理限制在了 256*256)。
DrawCall 的优化大概就是这些,优化的目标其实是往一个目标上靠,cpu 的 DrawCall 命令刚刚好能被 GPU 消化,不要让 CPU 等待(带宽限制),也不要让 GPU 闲置。如果即使做到了这个,应用帧率还是上不去,那么就只能去削减场景,做有损优化了。
Physics
Unity 内置 NVIDIA PhysX 物理引擎,来模拟物理世界的一些效果,比如说重力、阻力、弹性、碰撞这些,其中使用了一些内置的组件来实现这些模拟,用的比较多的如:刚体(Rigidbody)各种碰撞器(Collider)恒力(Constant Force)物理材质(Physic Material)铰链关节(Hinge Joint)弹簧关节(Spring Joint)。
unity 除了提供了一些重要的组件之外,在 unity 脚本中的生命周期中提供了一个专门为物理计算的刷新方法:
FixedUpdate()。FixedUpdate 跟 Update 的区别在于,这两个函数处于不同的 “帧循环” 中,FixedUpdate 处于 Physics 循环中,而 Update 不是。所以这两个函数的使用也有了不同。Update 的执行受场景 GameObject 的渲染的影响,三角形的数量越多,渲染所需要的时间也就越长。FixedUpate 的执行则不受这些影响。所以,Update 每个渲染帧之间的间隔是不相等的,而 Fixedupdate 在每个渲染帧之间的时间间隔是相等的。由于关系到物理模拟,所以一般涉及到物理组件,都需要放在 Fixedupdate 中进行计算。那么关于 physics,一般的优化手段都有哪些呢?下面是一些经验及总结:
1、将物理模拟时间步间隔设置到合适的大小。 Fixed Timestep 是和物理计算有关的,所以若计算的频率太高,自然会影响到 CPU 的开销。同时,若计算频率达不到软件设计时的要求,有会影响到功能的实现,所以如何抉择需要具体分析,选择一个合适的值,一般大于 16ms,小于 30ms。可以通过 Edit->Project Settings->Time 来改变这个值。
2、谨慎使用网格碰撞器(Mesh Collider),过于消耗性能,一般使用更简单的碰撞器,或者使用基本几何碰撞器合并的组合碰撞器。在这个项目中,把所有的网格碰撞体都抛弃了,都换成了 box collider。
3、真实的物理(刚体)很消耗,不要轻易使用,尽量使用自己的代码(数学计算)模仿假的物理。
4、最小化碰撞检测请求(例如 ray casts 和 sphere checks),尽量从每次检查中获得更多信息。
项目中涉及到物体的组件很少,关于 physic 的优化肯定还有很多可以说的,需要再去学习了。
VSync
简单地说,这是 CPU 优化的最直接的一个方法。
科普:VSync 垂直同步又称场同步 (Vertical Hold),垂直同步信号决定了 CRT 从屏幕顶部画到底部,再返回原始位置的时间。从 CRT 显示器的显示原理来看,单个像素组成了水平扫描线,水平扫描线在垂直方向的堆积形成了完整的画面。显示器的刷新率受显卡 DAC 控制,显卡 DAC 完成一帧的扫描后就会产生一个垂直同步信号(决定于屏幕的刷新率)。我们平时所说的打开垂直同步指的是将该信号送入显卡 3D 图形处理部分,从而让显卡在生成 3D 图形时受垂直同步信号的制约(注意是制约)。
如果我们选择等待垂直同步信号(也就是我们平时所说的垂直同步打开),那么在游戏中或许强劲的显卡迅速的绘制完一屏的图像,但是没有垂直同步信号的到达,显卡无法绘制下一屏,只有等垂直同步的信号到达,才可以绘制。这样 FPS 自然要受到操作系统刷新率运行值的制约。而如果我们选择不等待垂直同步信号(也就是我们平时所说的关闭垂直同步),那么游戏中作完一屏画面,显卡和显示器无需等待垂直同步信号就可以开始下一屏图像的绘制,自然可以完全发挥显卡的实力。但是不要忘记,正是因为垂直同步的存在,才能使得游戏进程和显示器刷新率同步,使得画面更加平滑和稳定。
取消了垂直同步信号,固然可以换来更快的帧率,但是在图像的连续性上势必打折扣。
四、Unity3D 应用性能优化之 GPU
一般人说 DC 的优化占了 unity3D 软件优化的三分天下,那么 GPU 的优化也占了三分天下。在了解 GPU 优化都有哪些着手点之前,我们先了解一下 GPU 在 3D 软件渲染中做了啥事:
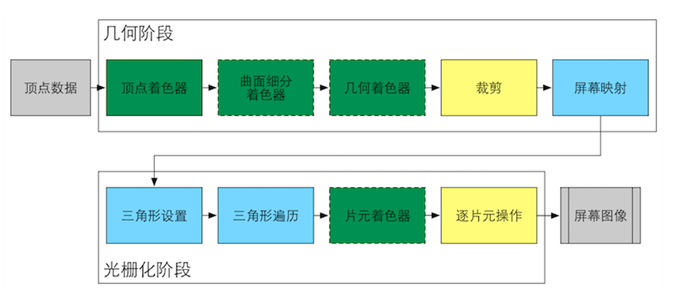
顶点着色器
GPU 接收顶点数据作为输入传递给顶点着色器。顶点着色器的处理单元是顶点,输入进来的每个顶点都会调用一次顶点着色器。(顶点着色器本身不可以创建或销毁任何顶点,并无法得到顶点与顶点之间的关系)。顶点着色器是完全可编程的,它主要完成的工作有:坐标变换和逐顶点光照。 坐标变换:就是对顶点的坐标进行某种变换—把顶点坐标从模型空间转换到齐次裁剪空间。顶点的多少直接决定了三角形面的多少,也直接决定了 GPU 的渲染流水线的工作量,所以减少顶点数是一个比较重要的优化点。那么减少顶点怎么操作呢,又有哪些途径?
1、优化基本几何体
3D 软件都是从模型制作开始,在设计师建模的时候就要想到应该尽可能地减少顶点数,一些对于模型没有影响、或是肉眼非常难察觉到区别的顶点都要尽可能去掉。比如在项目中,对于用户背后的环境模型,一些树木和石头,视频背面永远无法看见的神庙,能削减的都已经削减了。
2、使用 LOD(Level of detail)技术
LOD 技术有点类似于 Mipmap 技术,不同的是,LOD 是对模型建立了一个模型金字塔,根据摄像机距离对象的远近,选择使用不同精度的模型。它的好处是可以在适当的时候大量减少需要绘制的顶点数目。它的缺点同样是需要占用更多的内存,而且如果没有调整好距离的话,可能会造成模拟的突变。
3、使用遮挡剔除(Occlusion culling)技术
遮挡剔除是用来消除躲在其他物件后面看不到的物件,这代表资源不会浪费在计算那些看不到的顶点上,进而提升性能。刚才神庙后面的剔除就属于手动的遮挡剔除。
遮挡剔除是一个 PRO 版才有的功能, 当一个物体被其他物体遮挡住而不在摄像机的可视范围内时不对其进行渲染。遮挡剔除在 3D 图形计算中并不是自动进行的。因为在绝大多数情况下离 camera 最远的物体首先被渲染,靠近摄像机的物体后渲染并覆盖先前渲染的物体 (这被称为重复渲染"overdraw"). 遮挡剔除不同于视锥体剔除. 视锥体剔除只是不渲染摄像机视角范围外的物体而对于被其他物体遮挡但依然在视角范围内的物体,则不会被剔除. 注意当你使用遮挡剔除时,视锥体剔除(Frustum Culling)依然有效。
中间操作
1、曲面细分着色器:是一个可选的着色器,主要用于细分图元。
2、几何着色器:是一个可选的着色器,可用于执行逐图元的着色操作,或者被用于产生更多的图元。
3、裁剪:这一阶段是可配置的。目的是把那些不在视野内的顶点裁剪掉,并剔除某些三角形图元的面片。部分在视野内的图元需要做裁剪处理,在裁剪边缘产生新的顶点和三角形进行处理。
4、屏幕映射:这一阶段是可配置和编程的,负责把每个图元的坐标(三维坐标系)转换成屏幕坐标(二维坐标系)。
5、三角形设置:开始进入光栅化阶段,不再是数学上点了,而会把所有的点都映射到屏幕的具体像素坐标上,计算每条边上的像素坐标而得到三角形边界的表示方式即为三角形设置。
6、三角形遍历:这一阶段会检查每个像素是否被一个三角风格所覆盖。如果覆盖的话,就会生成一个片元(一个片元并不是真正意义上的像素,而是包含了很多状态的集合,这些状态用于计算每个像素的最终颜色。
这些状态包括了屏幕坐标、深度信息,及从几何阶段输出的顶点信息,如法线和纹理坐标等。),这样一个查找哪些像素被三角形覆盖的过程就是三角形遍历。
片元着色器
片元着色器的输入就是上一阶段对顶点信息插值得到的结果,更具体点说,是根据从顶点着色器中输出的数据插值得到的。而这一阶段的输出是一个或者多个颜色值。这一阶段可以完成很多重要的渲染技术,如纹理采样,但是它的局限在于,它仅可以影响单个片元。片元着色器是比较花时间的,因为它是最终颜色的计算者,在某些情况下,例如复杂灯光环境下,片元着色器会出现 GPU 流水线主要的拖后腿的存在。为了让片元着色器的计算更加快,我们需要从很多方面进行提前的优化:
1、尽量减少 overdraw
片元着色器最容易拖后腿的情况就是,overdraw!和 Android app 的开发一样,就是同一个像素点绘制了多次,某些情况会造成计算力的浪费,增加耗电量。前面提到的遮挡剔除有减少 overdraw 非常有用。在 PC 上,资源无限,为了得到最准确的渲染结果,绘制顺序可能是从后往前绘制不透明物体,然后再绘制透明物体进行混合。但是在移动平台上,对于不透明物体,我们可以设置从前往后绘制,对于有透明通道的物体(很多 UI 纹理就是含有透明通道的),再设置从后往前绘制。unity 中 shader 设置为 “Geometry” 队列的对象总是从前往后绘制的,而其他固定队(如 “Transparent”“Overla” 等)的物体,则都是从后往前绘制的。这意味这,我们可以尽量把物体的队列设置为 “Geometry” 。对于 GUI,尤其要注意和设计师商量,能用不透明的设计就用不透明的,对于粒子效果,也要注意不要引入透明值,多半情况下,移动平台的粒子效果透明值没有作用。
2、减少实时光照
移动平台的最大敌人。一个场景里如果包含了三个逐像素的点光源,而且使用了逐像素的 shader,那么很有可能将 Draw Calls 提高了三倍,同时也会增加 overdraws。这是因为,对于逐像素的光源来说,被这些光源照亮的物体要被再渲染一次。更糟糕的是,无论是动态批处理还是动态批处理(其实文档中只提到了对动态批处理的影响,但不知道为什么实验结果对静态批处理也没有用),对于这种逐像素的 pass 都无法进行批处理,也就是说,它们会中断批处理。
所以当你需要光照效果时,可以使用 Lightmaps,提前烘焙好,提前把场景中的光照信息存储在一张光照纹理中,然后在运行时刻只需要根据纹理采样得到光照信息即可。当你需要金属性强(镜面)的效果,可以使用 Light Probes。当你需要一束光的时候,可以使用体积光去模拟这个效果。
3、不要使用动态阴影
动态阴影很酷,但是对于片元着色器来说是灾难,阴影计算是三角投影计算,非常耗性能。如果想要阴影,可以使用 a、简单的使用一个带阴影的贴图 b、烘焙场景,拿到 lightmaps c、创建投影生成器的方法 d、使用 ShadowMap 的方法(目前还没有研究)。
4、尽量使用简单的 shader
a、建议尽量实用 Unity 自带 mobile 版本的 (built-in) Shader,这些大大提高了顶点处理的性能。当然也会有一些限制。
b、自己写的 shader 请注意复杂操作符计算,类似 pow,exp,log,cos,sin,tan 等都是很耗时的计算,最多只用一次在每个像素点的计算,还有有些除法运算尽量该能乘法运算等。
c、避免透明度测试着色器,因为这个非常耗时,使用透明度混合的版本来代替。
d、浮点类型运算:精度越低的浮点计算越快。
e、不要在 Shader 中添加不必要的 Pass.
五、Unity3D 应用性能优化之内存
unity 中有两类内存,一个是 Mono 托管的内存(相当于 DVM 的内存),一个是 Unity3D 使用的资源类类型的内存(Texture、Mesh 这种)。
Mono 内存
1、尽量不要动态的 Instantiate 和 Destroy Object,使用 Object Pool。
2、不要动态的产生字符串,使用字符串的直接拼接,使用 System.Text.StringBuilder 代替。
3、Cache 一些东西,在 update 里面尽量避免 search,如 GameObject.FindWithTag("")、GetComponent 这样的调用,可以在 Start 中预先存起来。
4、尽量减少函数调用栈,用 x = (x > 0 ? x : -x);代替 x = Mathf.Abs(x)。
5、定时重复处理用 InvokeRepeating 函数实现。
6、减少 GetComponent 的调用,使用 GetComponent 或内置组件访问器会产生明显的开销。您可以通过一次获取组件的引用来避免开销,并将该引用分配给一个变量(transform 用的最多)。
7、使用内置数组,内置数组是非常快的。ArrayList 或 Array 类很容易使用,你能轻易添加元件。但是他们有完全不同的速度。 内置数组有固定长度,并且大多时候你会事先知道最大长度然后填充它。内置数组最好的一点是他们直接嵌入结构数据类型在一个紧密的缓存里,而不需要任何额外 类型信息或其他开销。因此,在缓存中遍历它是非常容易的,因为每个元素都是对齐的。
Unity3D 类的内存
这类内存包括
1、AssetBundle
Unity3D 里有两种动态加载机制:一个是 Resources.Load,另外一个通过 AssetBundle,其实两者区别不大。 Resources.Load 就是从一个缺省打进程序包里的 AssetBundle 里加载资源,而一般 AssetBundle 文件需要你自己创建,运行时 动态加载,可以指定路径和来源的。
AssetBundle 运行时加载:
(1)来自文件就用 CreateFromFile(注意这种方法只能用于 standalone 程序,就不提了)。
(2)也可以来自 Memory,用 CreateFromMemory(byte[]),这个 byte[] 可以来自文件读取的缓冲,www 的下载或者其他可能的方式。其实 WWW 的 assetBundle 就是内部数据读取完后自动创建了一个 assetBundle 而已,Create 完以后,等于把硬盘或者网络的一个文件读到内存一个区域,这时候只是个 AssetBundle 内存镜像数据块,还没有 Assets 的概念。
下图是 AssetBundle 的加载卸载示意图:
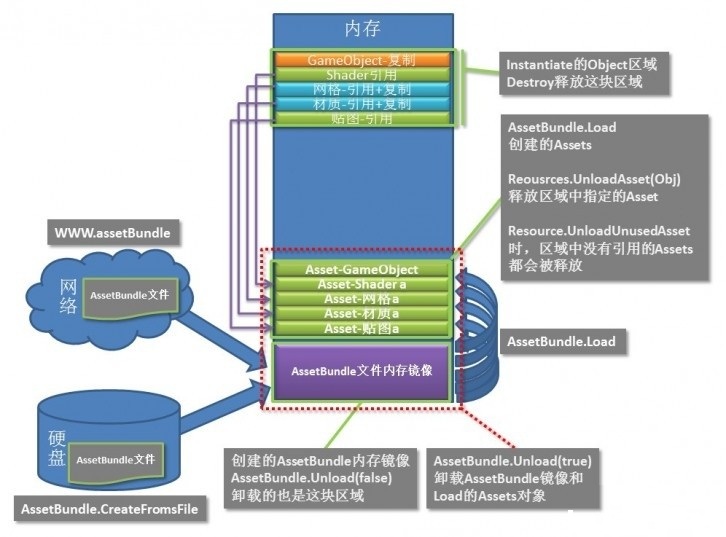
AssetBundle 是如何加载的呢?用 AssetBundle.Load(同 Resources.Load) 这才会从 AssetBundle 的内存镜像里读取并创建一个 Asset 对象,创建 Asset 对象同时也会分配相应内存用于存放 (反序列化)。异步读取用 AssetBundle.LoadAsync,也可以一次读取多个用 AssetBundle.LoadAll。
AssetBundle 如何释放呢?
AssetBundle.Unload(flase) 是释放 AssetBundle 文件的内存镜像,不包含 Load 创建的 Asset 内存对象。
AssetBundle.Unload(true) 是释放那个 AssetBundle 文件内存镜像和并销毁所有用 Load 创建的 Asset 内存对象。
2、Texture
对于 IOS 选择使用 PVRTC 压缩格式的,对于 Android 选择 ETC 压缩格式的,纹理可以节省大量内存和读取速度快,但是会有所降低图像的质量。
2D 纹理如果没有必要不要使用 mimap(会约增加 33% 的内存开销),曾经在 IOS 上吃过亏。3D 模型的纹理一般是需要 mimap 的,但是如果确定了 3D 模型距离摄像机的距离,在 GPU 分析器上确定了 unity 使用的纹理,就可以保留,关闭 mimap(比如项目中的 avatar)。
3.Mesh
有 Mesh 合并和 Mesh 压缩(坑比较多,不建议使用)。
4.Particle
粒子效果只要记住使用之后及时释放销毁就行。
针对手游的性能优化,腾讯 WeTest 平台的 Cube 工具提供了基本所有相关指标的检测,为手游进行最高效和准确的测试服务,不断改善玩家的体验。
目前功能还在免费开放中。,欢迎点击链接:
http://wetest.qq.com/product/cube 使用。

 因为文章关于 GC,重点是减少可能发生 GC 的情况,而不是针对 GC 的具体机制深入讲解的···文章有不足之处,还要继续学习的
因为文章关于 GC,重点是减少可能发生 GC 的情况,而不是针对 GC 的具体机制深入讲解的···文章有不足之处,还要继续学习的