WeTest 导读
现在 app 越来越炫,动不动就搞点动画,复杂的动画用原生实现起来挺复杂,如是就搞起 gif 播放动画的形式,节省开发成本。
背 景
设计同学准备给一个 png 序列,开发读取 png 序列,一帧一帧的播放出来,实现一个动画的效果。
为什么不直接使用 gif,github 上有好的开源库可以直接播放 gif 的,为嘛?大部分原因还是要回答,项目需求决定。
实现思路:
1、比较偷懒的方式,将设计同学给的 png 序列直接放到一个 animation-list 中,就像这样子:
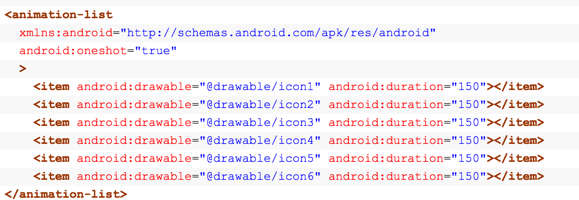
然后直接,放在设置为一个 ImageView 就可以了

那么,真的就可以了吗?答案是,可以,也不可以,因此最终不可以~~(有点绕。。。)
设计同学给了一个 90 多张 png 的序列,于是 oom 的发生,真是悲剧啊,这么简单的方案,结果却是这么华丽的被抛弃了。
2、使用一个线程来读取 PNG 序列,另外一个线程去播放读取出来的 PNG 序列,那么有一些问题我们要去面对:
a、一个线程来读,一个线程写,读 PNG 的线程写,播 PNG 的线程读,哎呀,有点拗口~~,不过很显然,这是一个《生产者 - 消费者模型》,那么问题是使用什么存放读取好的 bitmap 呢,使用 BlockingQueue 吧,为什么要使用 BlockingQueue,如果不懂,请点击这里,还能不能使用别的,当然,有,而且还不止一个,感兴趣可以去这个包下 java.util.concurrent 探索下。
b、不是怕 OOM 吗?那么,这个方案是否可以解决 OOM 呢?但是显然是肯定的了。为什么这么说,都到了这种粒度了,OOM 当然是可以解决。
b1、首先,我们可以拿到当前的最大内存 Runtime.getRuntime().maxMemory(),和当前的可用内存 Runtime.getRuntime().freeMemory();
因此,结合 BitmapFactory.Options,的这个 inJustDecodeBounds 属性,你完全可以判断是否还有足够的内存加载更多的 bitmap。
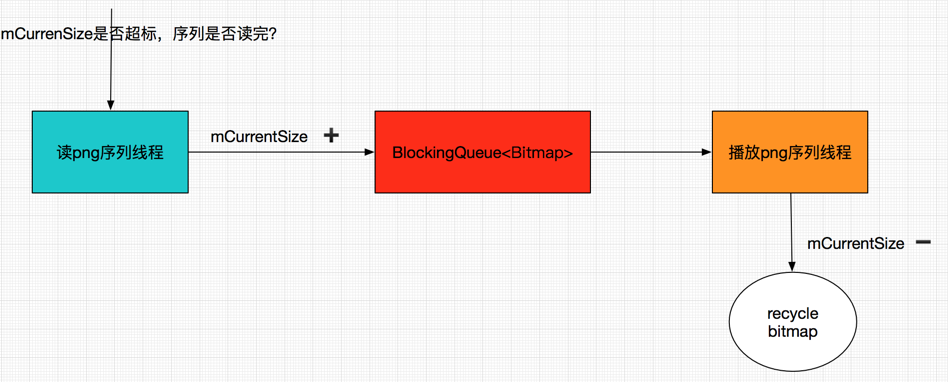
b2、其次,维护一个 currentSize,记录解析到内存测 bitmap 占用的内存,每读一张,currentSize+ 读出来的 bitmap 占用的内存,currentSize 显然是变动的,播放完的 bitmap 请补上一刀,currentSize - 刚刚播放完的 bitmap。
那么,整个过程似乎可以用这个图来清晰的表达了:
以为这样就结束了,那你就 TOO YOUNG TO SIMPLE 了,是否还能优化?你猜应该是可以吧!
我猜也是可以的,不难发现消费者的消费能力实在太强,读取 PNG 的线程太不给力,读的太慢了,播放总是等待读新的 bitmap 出来已供展示。那么?肿么办?
多个线程去读啊!
嗯,似乎可以改进成这样,对吗?

这里,可能有多个读取 PNG 的线程,一旦引入了多线程,你就会体会到问题会变得复杂多了!
这里,你要控制,当前读取进度到了哪里,因为是多线程,所以,你之间那个简单的 int currentLoad 已经不能用了,否则,三个线程读同一张 png 可能会被你不巧碰到,那么怎么办,使用 AtomicInteger,OK,这个问题好像被你解决了,此时,你保证了,所有 png 被不重复加载完毕!
然而,一个更加头疼的问题还要你去面对,注意,gif 是有播放顺序的,然而,你把 BlockingQuene 做成了这么一个序列:
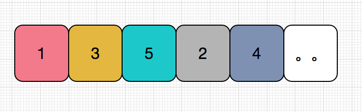
同学,这样好吗?显然不能接受。那么,如何保证塞入到 BlockingQuene 中的 bitmap 是按照 png 序列的顺序呢?
很显然要做到这一点,就需要将 png 的序号带入到读取线程中。读取线程读取完毕之后,去问一个 manger,大哥,有比我小的读取线程还没有提交他拿到的 bitmap 吗?大哥告诉你还有,那对不起,你乖乖等一会吧,wait(关键字),对么?如果大哥告诉你没有,你丫就是序号最小的那个哦,那你就把 bitmap 交给 BlockingQuene 吧,然而自己就完成光荣使命了。
可问题是,如果你在 wait,谁来叫醒你呢?大哥说,他来 notify,大哥收到最小的序号的提交的 bitmap,等等,(上面说错了,最小的需要把 bitmap 交给大哥来提交,),将 bitmap 交给 BlockingQuene,然后大哥此时通知所有读取线程的小弟们,大伙赶紧来交作业了,如是此时你单身 10 年的左手终于抢到了 “锁”,如是,你把你的作业 bitmap 交给了大哥了。
图,我就不画了,脑补也能补出来,不是吗?
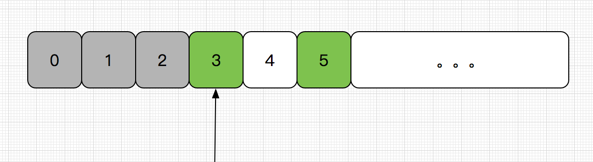
不满足锁,可以优化成无锁,大哥可以维护一个序列,1 对应的座位只能 1 提交过来,2 对应的只能 2 提过来,维护一个已交给 BlockingQuene 位置的游标,有好多种情况,我们用绿色的代表已交给大哥的任务好吗?
如是,这种情况表达 0123 已经提交给 BlockingQuene,5 先完成了,然后 3 完成了,4 没完成,此时大哥会吧 3 提交给 BlockingQuene 对吗?显然是,情况还有很多,,可以自己脑补一下,总之,这么做,读取线程只要读取完毕,把作业交给大哥就好,不用等待大哥说你是最小的,才让你提交,是吗?
这样就 OK 了吗?
如果说是,那你还是 TOO YOUNG TOO SIMPLE!
万万没想到,之前单个线程读的时候,加载一张 PNG 耗时才 220ms 左右,(测试使用模拟器),真机华为 mate8 略快。
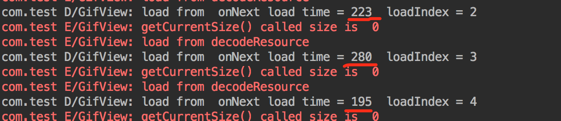
然而,使用多线程读的时候,加载一张 PNG 居然耗时 1100ms 左右,开了 4 个读线程。。,真是醉了。

线程开的有点多?那个 2 个试试???400ms 左右!!!

OH,no,回过头来想想,其实,瓶颈在读没有错,但是读的瓶颈在手机存储卡上。。。或许还有其他因素。
3、不死心,继续思考,单个线程读取 png 的情况下,是否有可能提高读取效率?
先把问题放一放,假如真的找不到好的办法,至少要保证内存占用方面,流畅性方面先,看下内存图谱吧,不看不要紧,一看,就醉了:

细心的同学应该看到了锯齿了,这 GC,太酸爽了吧,分析一下,我们没播放完一帧,就将 bitmap 给回收了 (recycle) 了。结果就导致了这种图的出现,但是又不能不 recycler 掉,随着 bitmap 内存占用不断增加,OOM 势必难以避免。
那么,既然释放也不是,不释放也不是,那么,可以不可以将这个要释放的 bitmap 继续拿过来用呢?
什么意思?
如果要释放的 bitmap 的那块内存,能够直接用来加载新的 png,那该多好啊,那么,是否有这个可能呢?问了下 google,他给了我这么一个答案:
https://developer.android.com/training/displaying-bitmaps/manage-memory.html#recycle

options 有这么一个参数 ,可以重用一个 bitmap 的内存去存放解析出另外一个新的 bitmap,但是有一定的要求:
4.4 以上,只需要 old bitmap 字节数比将要加载的 bitmap 所需的字节数大,但是低于 4.4,要满足和待加载 bitmap 长宽像素一致即可(更加苛刻)。
而我们的 png 序列,每张图片都是一样大小,显然,符合这个所有特性(长宽一致)。
如是,有多了集合去存储即将释放的 bitmap,用来重用。

测试一下:
锯齿果断消失了,而且,似乎还得到一个额外的奖励!

加载速度提升了
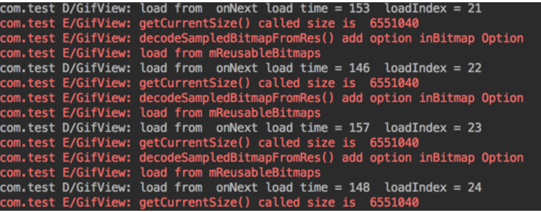
分析,可能是因为 bitmap 内存的重用,使得加载新 bitmap 的时候不用重新分配内存,节省了一定的时间。
最后看看丝丝顺滑的效果吧

针对手游的性能优化,腾讯 WeTest 平台的 Cube 工具提供了基本所有相关指标的检测,为手游进行最高效和准确的测试服务,不断改善玩家的体验。目前功能还在免费开放中。欢迎立即体验!
体验地址:http://wetest.qq.com/product/cube
帮助中心:http://wetest.qq.com/help/documentation/10096.html
如果对使用当中有任何疑问,欢迎联系腾讯 WeTest 企业 qq:800024531