360Qtest团队 自动生成 case 在 SDK 项目的 mock 测试中的应用 (使用篇)
结构流程设计
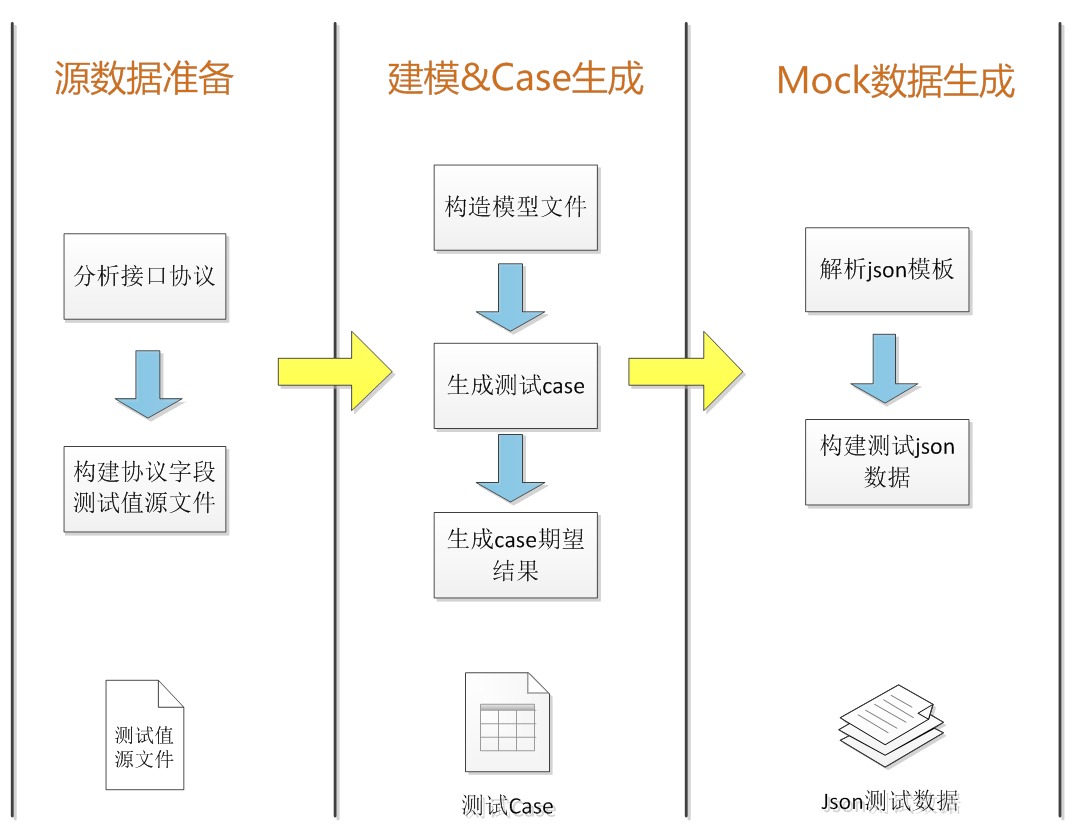
在整个测试过程中,我们唯一需要人工介入的就是字段值的赋值以及跟 error code 的对应关系设计,协议字段的取值会受业务影响,暂时无法通过自动化的方式来进行。流程如图所示:
阶段一
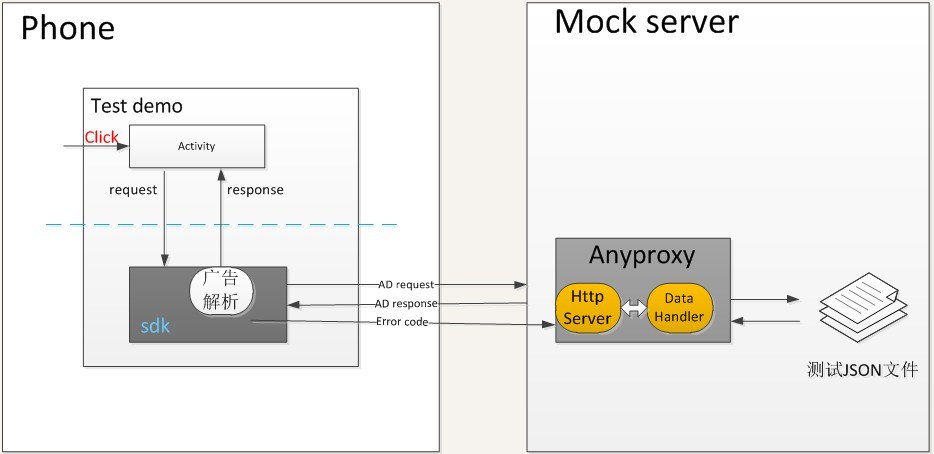
最初的版本比较简单,结构大概是这样的:
阶段二
原本的设想是想绕过广告宿主直接调用 SDK 的 API 请求广告,从而节省一部分时间,且更容易自动化,但是由于广告 SDK 本身特殊的设计,这个想法无法实现,因此当时的设计是通过触发 APP 按钮点击发送 request 给 SDK,再由 SDK 发送加工后的请求到 proxy server,再经过 mock server 处理数据以后,返回给客户端来显示广告。在此过程中,彻底抛弃了 Fiddler 重定向的传统做法。
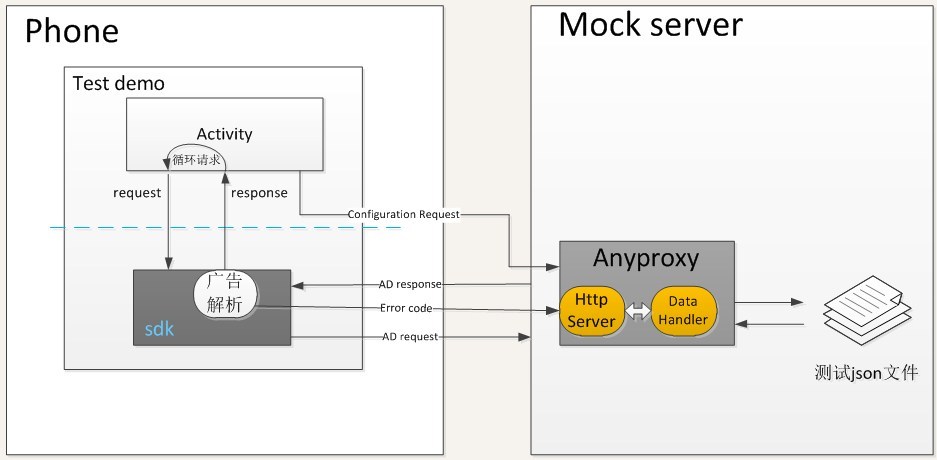
在阶段二我们解决了几个问题:
- 实现内部循环请求广告,解决手工触发请求的问题
- 监控 APP 自身出现的 crash 和 ANR
- 解决 case 失败后可以 rerun,
- 解决中途执行中断可以 rerun
- 由于一些广告请求失败会触发二次打点请求,因此我们需要把对应的 case 和打点请求结果匹配上,我们通过在 request 中加入 caseID 来解决该问题 解决多种广告类型不能连续一次性运行完,需要切换场景的问题
- 当出现期望结果与实际结果不符时,自动重新运行该 case 若干次(可配置),如果一直失败计为 case 失败
阶段三

该阶段很明显,我们遇到了执行速度的问题,由于广告种类的增加,我们的 case 达到了 3400 余条,由于还需要兼顾广告渲染完成后的打点结果检查,执行全量 case 耗时达到了3 个小时多,偏离了我们 mock 测试的初衷。因此如上图所示,我们用到了分布式结构。mock server 可以通过客户端指纹信息来调度和发送任务给指定的手机,把 case 和设备紧密连接在一起,避免重复运行相同的 case。
另外我们把 config、case、期望结果、执行结果等诸多信息全部迁移到 database 中,一方面解决频繁的文件读取问题,另一方面解决了分布式调度跨 server 的问题。
目前的收益
截止目前,我们的测试数据是这样的:
| Case 总数 | 发现 BUG | 遗漏的异常处理 |
| -------- | -------- | -------- |
| 3498 条 | 77 个 | 331 个 |
前面提到的问题,如果 error code 尚未明确,case 应该如何匹配呢?我们的做法是设定一个基准 error code,当运行结果出来后,会有实际结果与期望结果不符的 case,拿去和开发对一下就可以,而调整 error code 期望结果以后,重新生成 case 也只不过分分钟的事。
我们的执行时间:
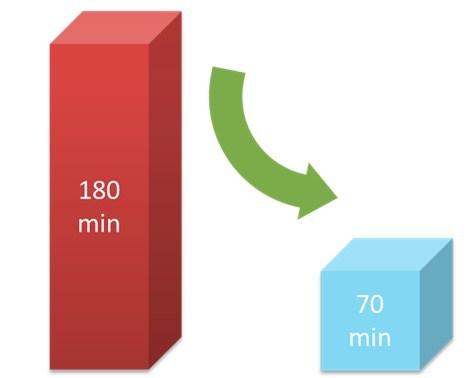
收益:协议变更时,只需要修改最开始的存放字段值的文件,后续的建模、case 生成、期望结果填充、执行测试用例全部自动完成,测试人员查看运行结果即可


问题总结
由于我们也是第一次在 mock 测试中实践自动化构造测试数据,包括用到的 pairwise 模型的合理性和准确性,都属于初次尝试,目前在项目中取得了一定的效果,但是也遇到了很多的困难,个中酸楚不足以一一道来,同时架构和流程还有很多优化空间。
目前依然留存的问题包括:
- 自动生成 case 中,int、string、date 等字段提取公共 case,比如特殊字符、空、null、js 等常规异常检查
- 更复杂的逻辑,比如关联字段依赖、加密字段、随机数、MD5、token 等情况
- 非 http(s) 的自定义协议
- 分布式调度的更大规模的使用
- SDK 的自动化测试对于 APP 的强依赖关系
- 正常的功能测试验证
- 业务逻辑产生的漏测率统计
诸如此类的问题还有很多很多,尤其是结合项目自身特点,就会更加复杂,希望通过我们的实践总结能给同行们一些启发或借鉴。