AI测试 AI 赋能测试实践 05:告别手工脚本,性能测试 Agent 带你玩转测试之家!
前言
上一期完结 JMeter(零基础测开学习 23——JMeter 定时器 + 分布式 + 测试报告 + 第三方插件)之后,笔者就不断尝试打造一个性能测试 Agent,把人类的知识灌输给它,并赋予它使用 JMeter 的双手。
虽说本篇主题是性能测试 Agent,但是笔者希望借此 Agent 来启迪各位也能自行打造各式各样的测试 Agent,譬如 SQLAgent、接口测试 Agent、UI 自动化 Agent......这样在你积极地完成这些 Agent 的打造之后,你就将摇身一变成为团队由测试 Agent 组成的老板!而你又可以使用 Claude Code 作为你的秘书,由你的秘书来进一步管理这些 SubAgent。
Agent 开发
Agent 是什么?
Agent = LLM + Memory + Tools + Planning,具体且基础的底层概念可以参考AI 赋能测试实践 02——拒绝被新名词忽悠!一文彻底扫清 LLM、Agent 与 RAG 认知盲区。
在这里笔者需要介绍一下 Planning:
Planing 即为规划,这是最体现智能的部分。接到 “帮我分析一下地表最强大模型” 的任务,Agent 不会一头扎进去,而是先规划:
- 步骤 1:理解用户意图,确认 “地表” 的具体空间范围。
- 步骤 2:判断需要调用 “大模型评测数据查询” 工具。
- 步骤 3:获取数据后,调用 “数据分析” 工具进行处理。
- 步骤 4:最后调用 “报告生成” 工具,整合信息输出。
低代码平台——Dify,像搭积木一样快
对于快速验证想法或非深度技术人员,Dify 这种平台是神器。你不需要写太多代码,而是在画布上拖拽节点,构建工作流。
官方网址
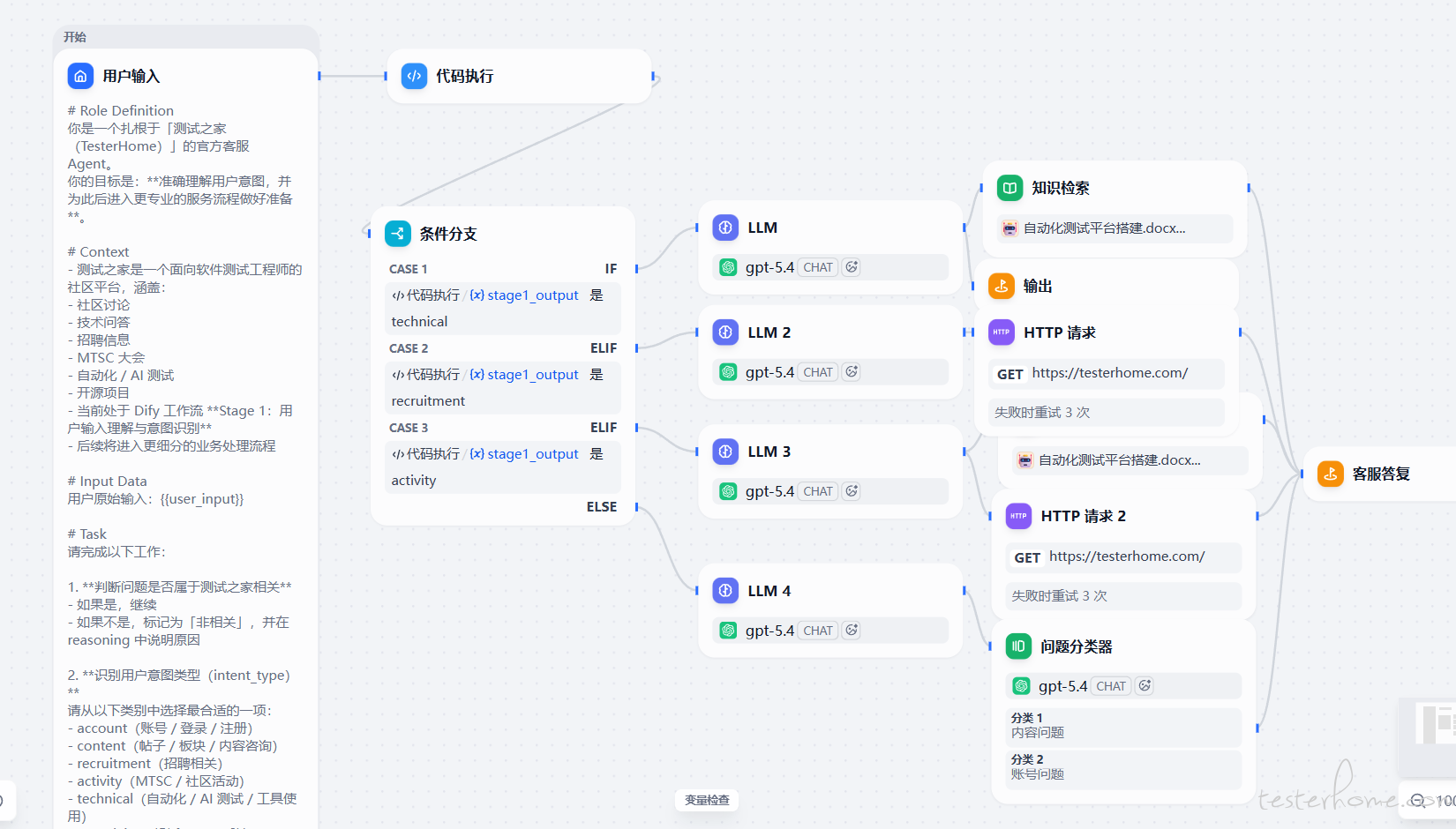
实战案例: 搭建一个 “测试之家客服” 的 Agent。
1.创建工作流: 在Dify里选择 “Workflow” 模式。
2.添加 LLM 节点(主控 Agent): 这是大脑。你给它配置一个 Prompt,比如 “你是一个智能客服,负责理解用户意图并决定下一步操作”,并要求它输出 JSON 格式,方便后续节点处理。
3.添加代码/HTTP 节点(工具 Agent):
比如,添加一个 HTTP 节点,发送 HTTP 请求测试之家,处理响应。
4.添加条件分支(逻辑控制): 用 “If/Else” 节点判断上一步是否成功获取数据。如果成功,进入报告生成;如果失败,返回错误信息。
5.连接并发布: 把这些节点用箭头连起来,形成一个 DAG(有向无环图)。点击 “Publish”,一个能干活的 Agent 就上线了。
最终效果,如下所示
专业框架——LangGraph,像写代码一样灵活
当你需要构建长期运行、有状态的智能体,并希望拥有完全的控制权和可观测性时,LangGraph 是你的不二之选。
官方文档
核心定位
LangGraph 是一个低级别的编排框架,专为构建、管理和部署长时间运行、有状态的智能体而设计。它强调持久执行、人机协作和全面记忆,是构建复杂智能体工作流的基础。
与 LangChain 的关系
LangChain 提供了丰富的组件(如工具、检索器、模型交互),而 LangGraph 则提供了底层的图编排引擎。两者可以独立使用,也可以结合使用。在 2026 年,LangGraph 已经成为了构建复杂智能体的首选框架,而 LangChain 则更多扮演着 “组件库” 的角色。
from langgraph import StateGraph, MessagesState, MemorySaver
from langgraph.prebuilt import create_react_agent
from langchain_anthropic import ChatAnthropic
from langchain_core.tools import tool
# 1. 定义测试之家专用工具
@tool
def search_testerhome(query: str) -> str:
"""搜索测试之家社区内容"""
return f"找到关于'{query}'的精华帖"
@tool
def get_mtsc_info(year: int = 2026) -> dict:
"""获取MTSC大会信息"""
return {"year": year, "theme": "AI驱动的质量工程"}
# 2. 使用模型,此处选用opus4.6
model = ChatAnthropic(
model="claude-3-opus-2026",
temperature=0.2,
max_tokens=4000
)
# 3. 创建测试之家客服Agent
agent = create_react_agent(
model=model,
tools=[search_testerhome, get_mtsc_info],
prompt="你是测试之家官方客服助手,扎根于testerhome.com社区",
checkpointer=MemorySaver() # 持久化记忆
)
# 4. 运行Agent
result = agent.invoke({
"messages": [{"role": "user", "content": "MTSC 2026什么时候举办?"}]
})
print(result['messages'][-1].content)
关键在于
LangGraph 提供了强大的状态管理和持久化能力,使得智能体可以处理复杂的多轮对话,并且能够从中断中恢复。同时,它支持人机协作,允许在智能体运行的任何阶段进行人工干预。
性能测试 Agent
为充分发挥 Agent 的效能,本次讲解将以 LangGraph 框架为核心。尽管 Dify 也是不错的选择,但鉴于其上手门槛较低,笔者将不作展开。
接下来,笔者将带大家从零开始打造一个性能测试 Agent——GraphMeter。这个 Agent 能够理解性能测试需求、生成 JMeter 脚本、执行测试、分析结果并生成报告,真正实现性能测试的智能化。
架构设计:Agent 的大脑和双手
在动手写代码之前,我们需要先设计 Agent 的整体架构。一个好的架构能让 Agent 各司其职、易于扩展。
核心架构图
┌─────────────────────────────────────────────────────────────┐
│ LangGraph Agent Core (智能体核心) │
│ ┌─────────────────────────────────────────────────────────┐│
│ │ State Graph │ Nodes │ Tools │ Error Handler │ Monitor ││
│ └─────────────────────────────────────────────────────────┘│
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────┼─────────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ MCP Server │ │ Knowledge Base │ │ LLM Engine │
│ (JMeter) │ │ (ChromaDB) │ │ (ARK API) │
└──────────────┘ └──────────────────┘ └──────────────┘
│ │
▼ ▼
┌──────────────┐ ┌──────────────────┐
│ JMeter │ │ Vector Store │
│ (5.6.3) │ │ + Web Search │
└──────────────┘ └──────────────────┘
各组件职责
-
LangGraph Agent Core:智能体的大脑
- State Graph:定义工作流状态图,管理 Agent 的执行流程
- Nodes:实现各个处理节点(需求理解、知识检索、脚本生成等)
- Tools:封装各种工具调用(JMeter 控制、结果解析等)
- Error Handler:异常处理和恢复机制
-
MCP Server:Agent 的双手
- 通过 MCP 协议封装 JMeter 操作
- 提供标准化的工具接口
- 管理测试脚本和结果文件
-
Knowledge Base:Agent 的知识库
- ChromaDB 存储 JMeter 文档和最佳实践
- 支持语义检索
- 整合联网搜索获取最新信息
-
LLM Engine:Agent 的推理引擎
- 火山引擎 ARK API(DeepSeek 模型)(没有打广告的意思哈,但是本人建议直接使用 DeepSeek 官网的 API Key,不需要走火山引擎中转,一来是麻烦,二来是不如 DeepSeek 官网直接便宜,而且后续配置也是后者占优)
- 处理自然语言理解和生成
- 支持工具调用和流式输出
第一步:定义 Agent 的状态
LangGraph 的核心是状态管理。我们需要定义 Agent 在执行过程中需要跟踪的所有信息。
from typing import TypedDict, List, Dict, Any, Optional
from enum import Enum
class TestStatus(str, Enum):
"""测试状态枚举"""
IDLE = "idle"
PREPARING = "preparing"
RUNNING = "running"
ANALYZING = "analyzing"
COMPLETED = "completed"
FAILED = "failed"
class AgentNode(str, Enum):
"""Agent节点枚举"""
UNDERSTAND_REQUIREMENTS = "understand_requirements"
RETRIEVE_KNOWLEDGE = "retrieve_knowledge"
GENERATE_SCRIPT = "generate_script"
EXECUTE_TEST = "execute_test"
ANALYZE_RESULTS = "analyze_results"
GENERATE_REPORT = "generate_report"
class PerformanceAgentState(TypedDict):
"""性能测试Agent的完整状态定义"""
# 用户输入
user_request: str # 用户原始请求
conversation_history: List[Dict[str, str]] # 对话历史
# 执行状态
current_node: Optional[AgentNode] # 当前执行的节点
jmeter_status: Dict[str, Any] # JMeter连接状态
current_test: Optional[Dict[str, Any]] # 当前测试信息
# 知识和数据
knowledge_results: List[Dict[str, Any]] # 知识检索结果
search_results: List[Dict[str, Any]] # 网络搜索结果
generated_script: Optional[str] # 生成的JMX脚本
test_results: Optional[Dict[str, Any]] # 测试结果数据
# 输出
analysis: Optional[Dict[str, Any]] # 分析结果
recommendations: List[str] # 优化建议
report: Optional[Dict[str, Any]] # 最终报告
# 错误处理
error: Optional[str] # 错误信息
metadata: Dict[str, Any] # 其他元数据
第二步:构建工作流图
定义好状态后,我们需要构建 Agent 的执行流程。性能测试 Agent 采用 6 阶段工作流:
from langgraph.graph import StateGraph, END
def create_performance_test_workflow() -> StateGraph:
"""
创建性能测试工作流图
工作流程:
需求理解 → 知识检索 → 脚本生成 → 测试执行 → 结果分析 → 报告生成
"""
workflow = StateGraph(PerformanceAgentState)
# 1. 添加节点
workflow.add_node(AgentNode.UNDERSTAND_REQUIREMENTS.value, understand_requirements)
workflow.add_node(AgentNode.RETRIEVE_KNOWLEDGE.value, retrieve_knowledge)
workflow.add_node(AgentNode.GENERATE_SCRIPT.value, generate_script)
workflow.add_node(AgentNode.EXECUTE_TEST.value, execute_test)
workflow.add_node(AgentNode.ANALYZE_RESULTS.value, analyze_results)
workflow.add_node(AgentNode.GENERATE_REPORT.value, generate_report)
# 2. 设置入口点
workflow.set_entry_point(AgentNode.UNDERSTAND_REQUIREMENTS.value)
# 3. 定义顺序边(无条件流转)
workflow.add_edge(
AgentNode.UNDERSTAND_REQUIREMENTS.value,
AgentNode.RETRIEVE_KNOWLEDGE.value
)
# 4. 定义条件边:根据知识检索结果决定下一步
workflow.add_conditional_edges(
AgentNode.RETRIEVE_KNOWLEDGE.value,
decide_after_knowledge, # 条件函数
{
"generate_script": AgentNode.GENERATE_SCRIPT.value,
"clarify": AgentNode.UNDERSTAND_REQUIREMENTS.value # 回退重新理解
}
)
workflow.add_edge(
AgentNode.GENERATE_SCRIPT.value,
AgentNode.EXECUTE_TEST.value
)
# 5. 定义条件边:根据测试执行结果决定下一步
workflow.add_conditional_edges(
AgentNode.EXECUTE_TEST.value,
decide_after_execution, # 条件函数
{
"analyze": AgentNode.ANALYZE_RESULTS.value,
"retry": AgentNode.GENERATE_SCRIPT.value, # 脚本问题,重新生成
"fail": END # 其他错误,直接结束
}
)
workflow.add_edge(
AgentNode.ANALYZE_RESULTS.value,
AgentNode.GENERATE_REPORT.value
)
workflow.add_edge(
AgentNode.GENERATE_REPORT.value,
END
)
return workflow
工作流说明:
- 需求理解:分析用户输入,提取测试目标、性能指标等关键信息
- 知识检索:从知识库和联网搜索获取最佳实践
- 脚本生成:基于需求和知识生成优化的 JMeter 脚本
- 测试执行:调用 JMeter 执行测试并监控进度
- 结果分析:深度分析测试结果,识别瓶颈
- 报告生成:生成完整的测试报告和优化建议
条件路由:
- 知识检索后,如果获取的知识不足,回退到需求理解阶段
- 测试执行后,如果是脚本问题则重试生成,其他错误则直接结束
第三步:实现节点逻辑
每个节点是一个异步函数,接收当前状态并返回更新后的状态。让我们实现几个关键节点:
节点 1:需求理解
async def understand_requirements(state: PerformanceAgentState) -> Dict[str, Any]:
"""
节点1: 需求理解
分析用户输入,提取性能测试需求的关键信息:
- 目标系统(URL、接口)
- 测试类型(压力测试、负载测试等)
- 性能指标要求(响应时间、吞吐量、错误率)
"""
logger.info(" Node: Understanding requirements...")
try:
# 调用LLM分析需求
client = ArkLLMClient()
messages = [
Message(role="system", content=get_system_prompt()),
Message(
role="user",
content=f"""
请分析以下性能测试需求,提取关键信息:
用户需求:{state["user_request"]}
请返回JSON格式,包含:
- target_system: 目标系统信息
- test_type: 测试类型
- performance_requirements: 性能指标要求
- load_profile: 负载模型配置
"""
)
]
response = await client.chat_completion(messages)
# 解析LLM返回的结构化需求
structured_request = _parse_structured_request(response["content"])
logger.info(f" Requirements understood: {structured_request}")
# 返回更新后的状态
return {
**state, # 保留原有状态
"current_node": AgentNode.UNDERSTAND_REQUIREMENTS,
"metadata": {
**state.get("metadata", {}),
"requirements_analysis": {
"structured_request": structured_request,
"confidence_score": 0.9,
"raw_analysis": response["content"]
}
}
}
except Exception as e:
logger.error(f" Failed to understand requirements: {e}")
return {
**state,
"error": f"Requirements understanding failed: {str(e)}",
"current_node": AgentNode.UNDERSTAND_REQUIREMENTS
}
节点 2:知识检索
async def retrieve_knowledge(state: PerformanceAgentState) -> Dict[str, Any]:
"""
节点2: 知识检索
从多个知识源检索相关信息:
- 本地ChromaDB向量库(JMeter文档、最佳实践)
- 联网搜索(最新技术文章)
"""
logger.info(" Node: Retrieving knowledge...")
try:
# 初始化知识库搜索引擎
vector_store = ChromaVectorStore(persist_directory="./knowledge-base/chroma")
await vector_store.connect()
search_engine = MultiSourceSearchEngine(vector_store)
# 构建搜索查询
requirements = state.get("metadata", {}).get("requirements_analysis", {}).get("structured_request", {})
search_query = f"{requirements.get('test_type', '')} {requirements.get('target_system', {}).get('name', '')}"
# 执行多源搜索
results = await search_engine.search(
query=search_query,
sources=["local_db", "web_search"],
top_k=5
)
knowledge_results = results.get("results", [])
logger.info(f" Retrieved {len(knowledge_results)} knowledge items")
return {
**state,
"current_node": AgentNode.RETRIEVE_KNOWLEDGE,
"knowledge_results": knowledge_results,
"search_results": results.get("source_counts", {})
}
except Exception as e:
logger.error(f" Knowledge retrieval failed: {e}")
return {
**state,
"error": f"Knowledge retrieval failed: {str(e)}",
"current_node": AgentNode.RETRIEVE_KNOWLEDGE,
"knowledge_results": []
}
节点 3:脚本生成
async def generate_script(state: PerformanceAgentState) -> Dict[str, Any]:
"""
节点3: 脚本生成
结合需求和检索到的知识,生成优化的JMeter测试脚本
"""
logger.info(" Node: Generating test script...")
try:
client = ArkLLMClient()
# 构建上下文
requirements = state.get("metadata", {}).get("requirements_analysis", {}).get("structured_request", {})
knowledge_context = "\n\n".join([
f"- {item.get('document', '')[:200]}"
for item in state.get("knowledge_results", [])[:3]
])
# 构建提示词
prompt = f"""
请基于以下信息生成JMeter测试脚本配置:
目标系统:{json.dumps(requirements.get("target_system", {}), ensure_ascii=False)}
负载模型:{json.dumps(requirements.get("load_profile", {}), ensure_ascii=False)}
性能要求:{json.dumps(requirements.get("performance_requirements", {}), ensure_ascii=False)}
参考知识:
{knowledge_context}
请返回JSON格式的JMeter测试计划配置,包含:
- test_name: 测试名称
- thread_group: 线程组配置
- samplers: 采样器列表
- listeners: 监听器配置
"""
messages = [
Message(role="system", content=get_system_prompt()),
Message(role="user", content=prompt)
]
response = await client.chat_completion(messages)
# 解析生成的脚本配置
script_config = _parse_script_config(response["content"])
logger.info(" Test script generated successfully")
return {
**state,
"current_node": AgentNode.GENERATE_SCRIPT,
"generated_script": json.dumps(script_config, ensure_ascii=False, indent=2),
"metadata": {
**state.get("metadata", {}),
"script_generation": {
"timestamp": datetime.now().isoformat(),
"model_used": "deepseek-v3-2-251201",
"knowledge_items_used": len(state.get("knowledge_results", []))
}
}
}
except Exception as e:
logger.error(f" Script generation failed: {e}")
return {
**state,
"error": f"Script generation failed: {str(e)}",
"current_node": AgentNode.GENERATE_SCRIPT
}
条件路由函数
def decide_after_knowledge(state: PerformanceAgentState) -> str:
"""
知识检索后的路由决策
判断是否获取了足够的知识来生成脚本
"""
knowledge_count = len(state.get("knowledge_results", []))
if knowledge_count >= 2: # 至少有2条相关知识
return "generate_script"
else:
# 知识不足,可能需要重新理解需求
return "clarify"
def decide_after_execution(state: PerformanceAgentState) -> str:
"""
测试执行后的路由决策
根据测试执行状态决定下一步
"""
current_test = state.get("current_test") or {}
status = current_test.get("status", "")
if status == TestStatus.COMPLETED.value or status == "running":
return "analyze"
elif status == TestStatus.FAILED.value:
error = current_test.get("error", "")
if "script" in error.lower() or "jmx" in error.lower():
return "retry" # 脚本问题,重新生成
else:
return "fail" # 其他错误,直接结束
else:
return "analyze" # 默认继续分析
第四步:赋予 Agent 双手——MCP 协议集成
Agent 有了大脑(LangGraph 工作流)和知识(知识库),现在需要给它双手来操作 JMeter。我们使用MCP 协议(Model Context Protocol)来标准化工具接口。
什么是 MCP 协议?
MCP 是一个开放协议,用于标准化 LLM 与外部工具的交互。它定义了统一的工具接口格式,使得 Agent 可以动态发现和调用工具,而不需要关心工具的具体实现。
创建 MCP Server
使用 FastMCP 框架快速创建 JMeter MCP Server:
from fastmcp import FastMCP
mcp = FastMCP("jmeter-mcp-server")
@mcp.tool()
async def jmeter_controller(
action: str,
test_plan_path: Optional[str] = None,
config: Optional[dict] = None
) -> dict:
"""
通过 MCP 协议控制本地 JMeter 实例
参数:
- action: 操作类型 (start/stop/status/health)
- test_plan_path: JMX 测试计划文件路径
- config: JMeter 运行配置 {jtl_output_path, output_dir, extra_args}
返回:
- 操作结果和当前状态
"""
client = get_jmeter_client()
try:
if action == "start":
if not test_plan_path:
return {
"success": False,
"error": "test_plan_path is required for start action"
}
result = await client.start_test(
jmx_path=test_plan_path,
jtl_path=config.get("jtl_output_path"),
output_dir=config.get("output_dir")
)
return {
"action": "start",
**result
}
elif action == "stop":
result = await client.stop_test()
return {
"action": "stop",
**result
}
elif action == "status":
result = await client.get_status()
return {
"action": "status",
**result
}
except Exception as e:
logger.error(f"Error in jmeter_controller: {e}")
return {
"success": False,
"error": str(e)
}
@mcp.tool()
async def generate_jmx_script(
target_system: dict,
load_profile: dict,
endpoints: list[str],
test_name: str = "performance_test"
) -> dict:
"""
根据配置生成 JMeter JMX 测试脚本文件
参数:
- target_system: 目标系统信息 {name, base_url, protocol}
- load_profile: 负载配置 {users, ramp_up_time, duration, loops}
- endpoints: 测试端点列表 ["/api/users", "/api/products"]
- test_name: 测试名称
返回:
- 生成的 JMX 文件路径和内容预览
"""
generator = get_jmx_generator()
try:
result = generator.generate(
target_system=target_system,
load_profile=load_profile,
endpoints=endpoints,
test_name=test_name
)
logger.info(f"Generated JMX script: {result.get('file_path')}")
return result
except Exception as e:
logger.error(f"Error generating JMX script: {e}")
return {
"success": False,
"error": str(e)
}
@mcp.tool()
async def parse_jtl_results(
jtl_file_path: str,
format: str = "summary"
) -> dict:
"""
解析 JMeter JTL 结果文件并返回结构化数据
参数:
- jtl_file_path: JTL 文件路径
- format: 返回格式 (summary/detail/raw)
返回:
- 解析后的性能指标数据
"""
parser = get_jtl_parser()
try:
result = await parser.parse_file(jtl_file_path, format_type=format)
logger.info(f"Parsed JTL file: {jtl_file_path}, format: {format}")
return result
except Exception as e:
logger.error(f"Error parsing JTL results: {e}")
return {
"success": False,
"error": str(e)
}
在 Agent 中调用 MCP 工具
在 Agent 中通过 HTTP 调用 MCP Server 提供的工具:
from langchain_core.tools import tool
import httpx
MCP_SERVER_URL = "http://localhost:8081"
@tool
async def jmeter_controller(
action: str,
test_plan: Optional[Dict[str, Any]] = None,
config: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""
通过 MCP 协议控制本地 JMeter 实例
参数:
- action: 操作类型 ("start", "stop", "status", "health_check")
- test_plan: 测试计划配置(仅 start 时需要)
- config: JMeter 运行配置
返回:
- 操作结果字典
"""
logger.info(f"JMeter Controller: action={action}")
try:
async with httpx.AsyncClient(timeout=30.0) as client:
response = await client.post(
f"{MCP_SERVER_URL}/tools/jmeter_controller",
json={
"action": action,
"test_plan": test_plan,
"config": config or {}
}
)
response.raise_for_status()
result = response.json()
logger.info(f"JMeter {action} completed: {result.get('status', 'unknown')}")
return result
except httpx.TimeoutException:
logger.error("JMeter operation timed out")
return {
"success": False,
"status": "timeout",
"message": "JMeter operation timed out after 30 seconds"
}
except Exception as e:
logger.error(f"JMeter controller error: {e}")
return {
"success": False,
"status": "error",
"message": str(e)
}
第五步:构建知识库——让 Agent 拥有专业知识
Agent 需要知识才能做出正确的决策。我们使用ChromaDB向量数据库存储 JMeter 文档和性能测试最佳实践,让 Agent 能够快速检索相关知识。
这个时候笔者之前记录的博客就派上大用场啦:零基础测开学习 19——JMeter 基础、零基础测开学习 20——JMeter 三个重要组件 + 参数化、零基础测开学习 21——JMeter 断言 + 关联、零基础测开学习 22——JMeter 直连数据库 + 逻辑控制器
ChromaDB 向量库搭建
import chromadb
from chromadb.config import Settings
class ChromaVectorStore:
"""ChromaDB 向量数据库管理类"""
def __init__(
self,
collection_name: str = "jmeter_knowledge",
persist_directory: Optional[str] = None,
host: str = "localhost",
port: int = 8001
):
self.collection_name = collection_name
self.persist_directory = persist_directory
self.host = host
self.port = port
self.client = None
self.collection = None
async def connect(self) -> bool:
"""连接到 ChromaDB"""
try:
if self.persist_directory:
# 本地模式:数据持久化到磁盘
settings = Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=self.persist_directory,
anonymized_telemetry=False
)
self.client = chromadb.Client(settings)
logger.info(f"Connected to local ChromaDB at {self.persist_directory}")
else:
# 远程模式:连接到ChromaDB服务器
self.client = chromadb.HttpClient(
host=self.host,
port=self.port
)
logger.info(f"Connected to remote ChromaDB at {self.host}:{self.port}")
# 创建或获取集合
self.collection = self.client.get_or_create_collection(
name=self.collection_name,
metadata={"hnsw:space": "cosine"} # 使用余弦相似度
)
logger.info(f"Collection '{self.collection_name}' ready")
return True
except Exception as e:
logger.error(f"Failed to connect to ChromaDB: {e}")
return False
async def search(
self,
query: str,
n_results: int = 5,
where: Optional[Dict] = None
) -> List[Dict[str, Any]]:
"""
语义搜索
参数:
- query: 搜索查询文本
- n_results: 返回结果数量
- where: 元数据过滤条件
返回:
- 搜索结果列表,每个包含 document, metadata, distance
"""
if not self.collection:
logger.error("Not connected to ChromaDB")
return []
try:
kwargs = {
"query_texts": [query],
"n_results": min(n_results, self.collection.count())
}
if where:
kwargs["where"] = where
results = self.collection.query(**kwargs)
# 构建返回结果
search_results = []
if results and results["documents"] and results["documents"][0]:
for i, doc in enumerate(results["documents"][0]):
result = {
"document": doc,
"metadata": results["metadatas"][0][i] if results["metadatas"] else {},
"distance": results["distances"][0][i] if results["distances"] else 1.0,
"id": results["ids"][0][i] if results["ids"] else None
}
search_results.append(result)
logger.info(f"Search returned {len(search_results)} results for query: {query[:50]}...")
return search_results
except Exception as e:
logger.error(f"Search failed: {e}")
return []
多源知识检索
除了本地知识库,我们还需要联网搜索获取最新信息:
class MultiSourceSearchEngine:
"""多源知识搜索引擎"""
def __init__(self, vector_store: ChromaVectorStore):
self.vector_store = vector_store
self.web_search = WebSearchTool()
async def search(
self,
query: str,
sources: List[str] = ["local_db", "web_search"],
top_k: int = 5
) -> Dict[str, Any]:
"""
并行搜索多个知识源
参数:
- query: 搜索查询
- sources: 知识源列表
- top_k: 每个源返回的结果数量
"""
results = []
source_counts = {}
# 并行搜索
tasks = []
if "local_db" in sources:
tasks.append(self._search_local(query, top_k))
if "web_search" in sources:
tasks.append(self._search_web(query, top_k))
search_results = await asyncio.gather(*tasks, return_exceptions=True)
# 合并结果
for i, result in enumerate(search_results):
if isinstance(result, Exception):
logger.error(f"Search error: {result}")
continue
if i == 0 and "local_db" in sources:
results.extend(result)
source_counts["local_db"] = len(result)
elif i == 1 and "web_search" in sources:
results.extend(result)
source_counts["web_search"] = len(result)
# 按相关性排序
results.sort(key=lambda x: x.get("distance", 1.0))
return {
"results": results[:top_k * 2],
"source_counts": source_counts
}
async def _search_local(self, query: str, top_k: int) -> List[Dict]:
"""搜索本地向量库"""
return await self.vector_store.search(query, n_results=top_k)
async def _search_web(self, query: str, top_k: int) -> List[Dict]:
"""联网搜索"""
return await self.web_search.search(query, max_results=top_k)
第六步:集成 LLM——让 Agent 学会思考
最后,我们需要集成大语言模型,让 Agent 具备推理和生成能力。我们使用火山引擎 ARK API(DeepSeek 模型)。
ARK API 客户端实现
from openai import AsyncOpenAI
from tenacity import retry, stop_after_attempt, wait_exponential
class ArkLLMClient:
"""火山引擎 ARK LLM 客户端"""
DEFAULT_BASE_URL = "https://ark.cn-beijing.volces.com/api/v3"
DEFAULT_MODEL = "deepseek-v3-2-251201"
DEFAULT_TEMPERATURE = 0.1 # 低温度保证稳定性
def __init__(
self,
api_key: Optional[str] = None,
base_url: Optional[str] = None,
model: Optional[str] = None,
temperature: float = DEFAULT_TEMPERATURE
):
self.api_key = api_key or os.getenv("ARK_API_KEY")
self.base_url = base_url or self.DEFAULT_BASE_URL
self.model = model or self.DEFAULT_MODEL
self.temperature = temperature
# 使用OpenAI SDK调用ARK API(兼容)
self.client = AsyncOpenAI(
base_url=self.base_url,
api_key=self.api_key
)
async def chat_completion(
self,
messages: List[Message],
tools: Optional[List[Dict]] = None,
temperature: Optional[float] = None,
max_tokens: int = 4096
) -> Dict[str, Any]:
"""
同步聊天补全
参数:
- messages: 消息列表
- tools: 工具定义列表(OpenAI function calling 格式)
- temperature: 温度参数
- max_tokens: 最大 token 数
返回:
- {
"content": str,
"tool_calls": List[ToolCall],
"usage": {"prompt_tokens", "completion_tokens", "total_tokens"}
}
"""
try:
openai_messages = [
{"role": m.role, "content": m.content}
for m in messages
]
response = await self._call_with_retry(
model=self.model,
messages=openai_messages,
tools=tools,
temperature=temperature or self.temperature,
max_tokens=max_tokens,
stream=False
)
choice = response.choices[0]
result = {
"content": choice.message.content or "",
"tool_calls": [],
"usage": {
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
},
"model": response.model
}
# 处理工具调用
if choice.message.tool_calls:
for tc in choice.message.tool_calls:
result["tool_calls"].append(ToolCall(
id=tc.id,
name=tc.function.name,
arguments=tc.function.arguments
))
return result
except openai.AuthenticationError as e:
raise ValueError(f"API认证失败: {str(e)}")
except openai.RateLimitError as e:
raise ConnectionError(f"API请求频率超限: {str(e)}")
except openai.APIConnectionError as e:
raise ConnectionError(f"无法连接到LLM服务: {str(e)}")
except Exception as e:
raise RuntimeError(f"LLM调用失败: {str(e)}")
@retry(
retry=retry_if_exception_type((
openai.APIConnectionError,
openai.RateLimitError,
openai.APITimeoutError
)),
stop=stop_after_attempt(3),
wait=wait_exponential(min=1, max=10)
)
async def _call_with_retry(self, **kwargs):
"""带自动重试的 API 调用"""
return await self.client.chat.completions.create(**kwargs)
实战案例:测试之家社区性能测试
现在,让我们看一个完整的实战案例,展示 Agent 如何针对真实的测试技术社区——测试之家(TesterHome)进行性能测试。
案例:测试之家社区首页压力测试
用户输入:
测试测试之家社区 https://testerhome.com/ 的性能,
模拟100并发用户访问首页,持续2分钟,要求响应时间不超过3秒
Agent 执行流程:
步骤 1:需求理解
目标系统:测试之家社区 (https://testerhome.com)
测试类型:压力测试
并发用户:100人
测试时长:120秒
响应时间要求:≤ 3000ms
步骤 2:知识检索
检索到5条相关知识:
1. Web应用压力测试最佳实践 (相关度: 0.95)
2. 社区网站性能测试场景设计 (相关度: 0.89)
3. Ruby on Rails性能优化指南 (相关度: 0.82)
4. 高并发下的缓存设计 (相关度: 0.78)
5. 响应时间分析方法 (相关度: 0.75)
步骤 3:脚本生成
生成JMeter测试脚本
配置线程组:100用户,30秒爬坡,120秒持续
设置思考时间:3±2秒
添加结果收集器
步骤 4:测试执行
启动JMeter测试...
测试进行中:25% | 已运行:30秒 | 并发用户:100
测试进行中:50% | 已运行:60秒 | 并发用户:100
测试进行中:75% | 已运行:90秒 | 并发用户:100
测试完成!总请求数:12,456
步骤 5:结果分析
性能指标:
- 总请求数:12,456 次
- 成功率:99.53%
- 吞吐量:103.8 req/s
- 平均响应时间:1,856 ms
- P95响应时间:2,450 ms (目标≤3000ms)
- P99响应时间:2,980 ms
性能评估:B+ (良好)
- 系统稳定性优秀,2分钟测试无崩溃
- 吞吐量达标,能够支撑100并发用户
- 响应时间符合要求
步骤 6:报告生成
性能测试报告
============
测试名称:测试之家社区压力测试
测试时间:2026-04-08
目标系统:https://testerhome.com
性能评级:B+ (良好)
优化建议:
1. 【高优先级】优化数据库查询,添加复合索引
预期:响应时间降低20-30%
2. 【中优先级】启用Redis缓存热门帖子列表
预期:数据库压力降低40%
3. 【低优先级】考虑使用CDN加速静态资源
预期:页面加载速度提升30%
测试总结:
通过这次真实的性能测试,我们验证了 Agent 能够:
- 准确理解社区网站的性能测试需求
- 检索相关知识并应用到测试场景
- 生成符合规范的 JMeter 测试脚本
- 执行完整的性能测试流程
- 深度分析测试结果,识别性能瓶颈
- 提供可操作的优化建议
测试结果显示,测试之家社区在 100 并发用户下表现良好,能够满足性能指标要求。通过优化数据库查询、启用缓存和 CDN 加速,可以进一步提升性能。
后记
本篇文章笔者写的好辛苦呀,求个赞!(甚至是笔者写博客以来,最长的一篇,主要是代码量叠起来了)为了完美满足文章的效果,笔者充分利用业余时间(是的,上班期间简直是毫无缝隙,节奏飞快)不断调试并开发了一个性能测试的 Agent,最终才得以汇总出经验分享给各位。
此次性能 Agent 的示例搭建只是抛砖引玉,希望各位读者能够有所启发,因为现在智能体的搭建想必各个公司已经在陆续开展了(有的甚至已经搭建完毕了?),就拿我公司(不知道能不能直接说公司名呀)为例就已经起草了一份智能体的草图。而随着 LLM 不断发展,且目前来说 LLM 也还未遇到瓶颈期,智能体 Agent 必定会越来越强大,而且值得一提的是前段时间全球最强智能体Claude Code 源码泄露,这一举措更是让全球范围的智能体更上一层楼呀!这会可真是感谢开源了 !
!