今天聊得什么
提升个人的认知能力,是解决复杂工程问题、迈向资深测试工程师的必经之路。
然而,《黑客与画家》的作者曾说过一句话——“黑客永远是自负的”(他指的软件工程师)。这种自负、偏执,加上工程师长期浸泡在某种自洽的技术世界中,使我们往往陷在自己的偏见里而不自知,也因此降低了我们对真实世界的察觉与改造能力。
正因如此,许多大公司,如 Google、Microsoft、Meta,都对工程师进行系统性的反认知偏差(debias)培训(我自己每年也会被要求参加一次)。
今天,我想借着最近身边的三个故事,聊聊认知偏差是如何在无意识中形成的,以及作为测试工程师的我们,可以如何借助 “元认知” 这个工具来去认知偏差。
我的故事 1:从方向感错误中觉察认知偏差
孩子在多伦多市区附近学琴,所以我每周要从北边的家里开车接送 1–2 次,持续了三年多。
大约一个月前,我像往常一样开到距离目的地最后 1 公里处(图中 3 号路段),随口对孩子说:
“这路上往南开的车也太多了,对向往北的几乎没多少。”
孩子愣了一下:“爸,我们现在是往西开呀!你搞错了吧?”
我几乎是本能地反驳:“不可能,这就是南。”
但把孩子送进教室后,我再次打开 Google 地图,才确认:这条路真的是东西向。
那一瞬间,我的困惑扑面而来:“三年来,我为什么一直以为这是南?到底哪里出了问题?”
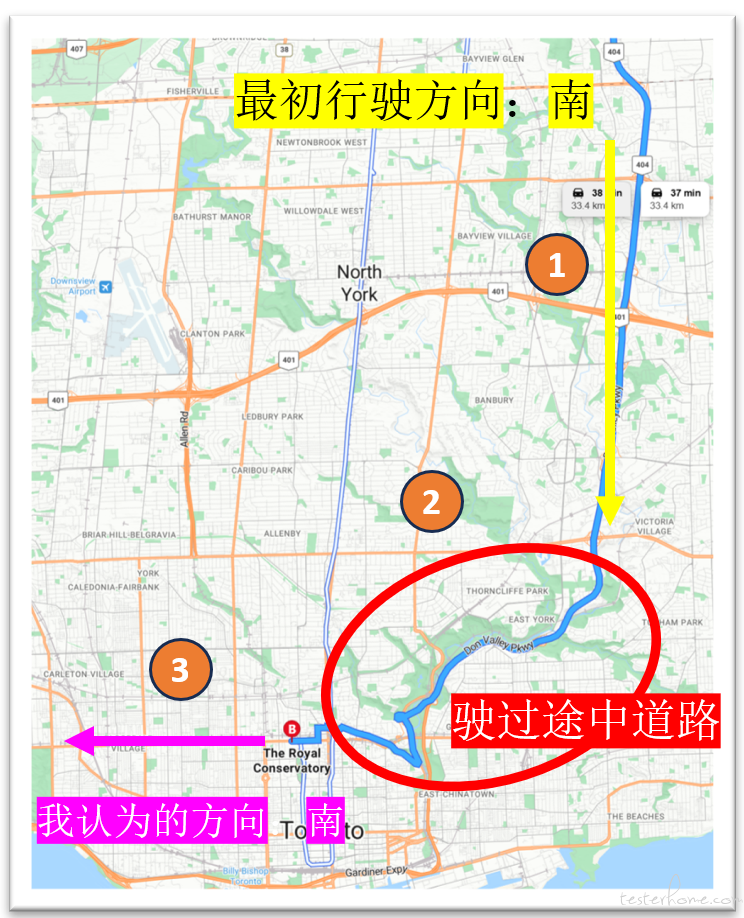
回顾整个路线(从 1 到 2 再到 3),我突然意识到了关键:
第一次开这条路时,路段 1 是我熟悉的,从南往北;但进入路段 2 和 3 后,由于道路弯曲且方向不明确,我只能依赖 Google 导航。

而我一直习惯把导航设成 “朝向行驶方向”。
在穿过路段 2 来到 3 的过程中,我的大脑自动把 “行驶方向” 当成了绝对方位——于是,“西” 被误以为是 “南”。
再加上路段 3 两侧被高楼遮挡,无法判断方向,我也从未主动去核查它。

结果,这个错误的 “方向感” 就在我脑子里静悄悄地扎根了三年。
当我试图纠正时,也经历了明显的 “内心打架”:
理性告诉我这是西,但直觉仍然坚持那是南——典型的系统 1 与系统 2 的冲突。
由此我才真正意识到:我们以为 “眼睛看到”“大脑认定” 的世界,并不总是客观真实的。
认知偏差(Cognitive Bias)是人类在思考和决策时,由于大脑习惯使用省力的 “快速思考”(卡尼曼称为系统 1)而产生的系统性错误。
系统 1 直觉、快速,却容易犯错;系统 2 更慢、更理性,但大脑常常懒得调动它。
过度依赖系统 1、系统 2 的缺席,就构成了认知偏差的根源。
当我把方向判断交给导航、交给直觉、交给经验时,我等于任由系统 1 替我做决定。
再加上一点惰性和自负,这个错误就稳稳地存在了三年。
后来,我把这个思路迁移到最近的一个技术事件上,又得到了相同的启发。
我的故事 2:从心歌的缺陷复盘中,看见偏差如何引入系统
今年 8 月底,在观察智能体(Agent)的快速发展后,我开始做一个实验性开源项目——心歌(https://www.signally.ink/)。
它的目标不是 “预测到底准不准”,而是借由构建一个股票行情的智能分析与预测 Agent,学习 “一个智能体应该如何搭建、如何协作、如何测试”。

两个月里,我利用下班时间,从零构建心歌。不得不说,Github Copilot 功不可没——我只要描述 UI、诉说需求,它就能像堆积木一样生成代码。
10 月 21 日,我把心歌部署到服务器,期待它可以 7×24 自主运行。
但随后的两周,我被一个缺陷折磨得抓狂。
每天 UI 都看不到预测结果,我试着把日志复制给 Copilot,它给的建议一堆,但都不是根因。
我不知道问题是出在模型本身、我的提示词不当,还是我没给够上下文。
我甚至不知道能向谁求助,总不能去质问 AI 吧?
于是我只能硬着头皮:读 AI 生成的代码、加更多日志、在生产环境实时监控。
但直到 10/28,我差点准备放弃时,才终于从实时日志里看到:
一个获取股票信息的第三方 Python 库抛出了异常,异常虽然被捕获,却没有被正确处理,导致系统在十分钟后悄无声息地失败。
修好后,心歌终于满负荷运行。
可在回家的路上,我突然反问自己:
这个缺陷到底是在哪个提示词、哪个上下文、哪句话时被引入的?
我很清楚——没有 Copilot,我几乎不可能在短时间内完成整个系统。
但它也让我变懒了。
因为一句话能生成一大段 “看起来合理” 的代码,我自然愿意偷懒,减少上下文输入,也减少代码审查。
如果我当时只加一句提示:
“这个获取股票信息的 API 虽然有 2.6k Stars,但不一定总是稳定;如果失败,请实现重试。”
这个缺陷就不会发生。
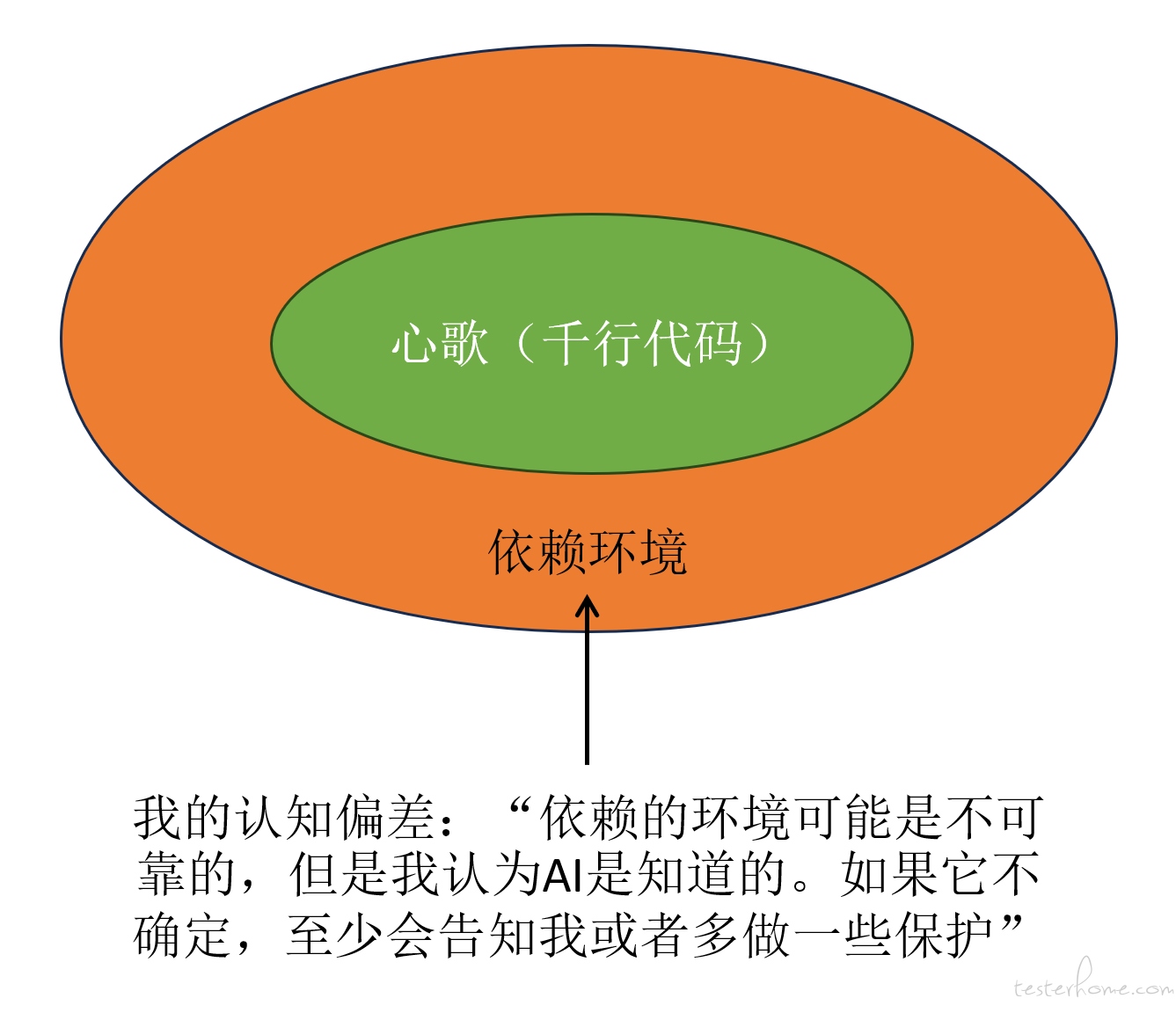
现在回看,我能非常肯定:
这是一个典型的 “系统 1 节省能量” 带来的认知偏差。
你觉得大语言模型是了解你的吗?其实可能只是我们的认知上的偏差:
1.让 LLM 生成一个冒泡排序算法,它默认就会输出 python 代码。如果你的项目刚好是基于 python 的,你会觉得 LLM 真懂你。而最近正在做 Java 项目的工程师就不会有这种误解了,因为他每次都要加上 Java 这个上下文去限制模型的输出。
2.当我让 LLM 帮我评价我写的文章时,几乎不出意外的都是一片叫好声。这样的设计,是不是会让我越发觉得 LLM 真像外界认为的一样客观和公正的。当我以 Guest 模式打开 LLM,然后输入:“我在网上看到有个家伙发了一篇文章 XXX,你觉得怎么样?”,我得到了不一样的答案。
3.去年 LLM 还没有引入 CoT 时,结果返回也就是十几秒。而如果我们告诉用户 LLM 已经集成了 CoT,并且结果返回时间增大到几分钟,其实啥都没做,会如何?我们应该可以设计一个双盲实验,验证这种认知偏差。
4.你的母语是汉语,如果用英文和 LLM 交互,它也会选择英文回复你。但是这时你正好在一台新装的 PC 上,没有中文输入法,你用英文向他发起会话。你下意识的期望它用你的母语回答你,因为你可能会无意识的认为 LLM 知道你是个没有中文输入法的母语是汉语的用户。
5.如果你在 LLM 输入"你能以第三人称的口吻写一篇 1000 字的短文吗?",答案永远都是 “他”,而不是 “她”。你如果不问 LLM,它是不会询问你第三人称的性别的。
...
了解更多的关于 AI 的认知偏差的研究可以参考:https://arxiv.org/pdf/2411.10915
随着 AI 大模型的发展,这样的任务偏差会逐渐减少,现在正在发生着。
我们期待某一天的到来,不再需要测试,去揪出这些认知偏差引入的缺陷。
我的故事 3:自动化开发目标的认知偏差
团队里经常能听到这样的抱怨:
“自动化不稳定”
“效果一般”
“上次小张写的脚本两周就跑不了了”
最近我们迁移到一个全新的测试框架,也不可避免地经历了类似的状况。
领导给出的目标很清晰:
自动化 Pass 率 > 95%
有了 KPI,我们马上用 Copilot 生成大量脚本,最初进展飞快。
但很快就进入漫长的 “稳定化阶段”:每跑一次就要复盘日志,再微调脚本,再跑。
某天 Pass 很高,会信心得不得了;但之后连续几天都会出现低概率 Fail,每次都要花大量时间追查。
两个月后,好不容易达成 KPI,但系统上线后依然出现 Fail,而且因为自动化漏检明显缺陷,我们还被非测试同事质疑。
于是在一次会议中,大家讨论 “如何提高自动化的质量和认可度”。
工程师提出各种 “具体问题”:
难预测的弹框
等待时间怎么设置才合理
框架升级带来的潜在影响
自动化漏测导致要求增加更多校验
但我觉得,有必要先从更底层的角度问:
这些混乱的根源是什么?偏差又在哪里?
如果把测试工程师与非测试工程师的视角拆开来看,会看到两种天然不同的期望。
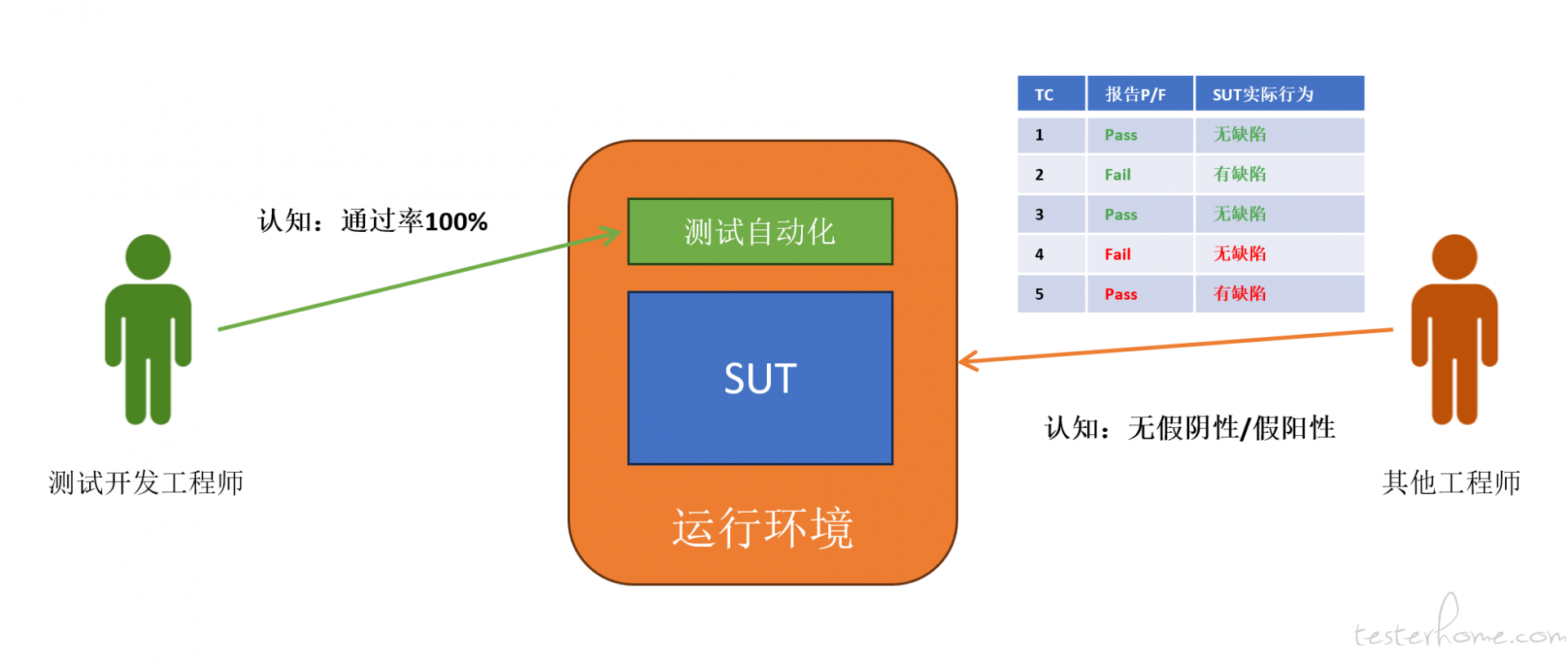
测试开发工程师希望 “构建稳定的质量工具”,但当他们开始写脚本时,会自然带入 “创造者” 的角色。
而在创造者的心理里,“工具要帮我证明它能跑通” 会悄悄替代 “工具要客观地反映质量”。
Pass 率越高越有成就感,于是:
对运行环境的不稳定敏感度下降
对 SUT 的易变性不够重视
更倾向于让脚本 “绕过不稳定点” 而不是正面处理
这是测试工程师常见的 “创造者偏差”。
而非测试工程师的偏差则恰好相反:他们认为自动化是 “铁板钉钉的机器”,应该比人工更不容易犯错,也应该 “永远稳定、永远准确”。
这种 “完美工具偏差” 让他们对失败零容忍,对自动化的脆弱性缺乏理解。
两个群体的偏差叠加,就导致了我们今天看到的混乱局面。
我理解的元认知:测试认知提升的工具
一在撰写本文之前,我读到了一篇论文(如 Arxiv: 1804.03919),其中讨论了专业软件工程师在项目实践中如何产生认知偏差,以及研究者设计的干预措施如何帮助工程师改善决策质量。这类研究也印证了业界已有的趋势——许多大型科技公司会组织员工接受反认知偏差(debias)培训,包括 Google、Microsoft、Meta 等。
事实上,在软件公司内部,测试团队本身就是一种系统性的 “反偏差力量”。
就像大模型团队需要红队去挑战系统一样,测试团队的角色往往是质疑、拆解、审视和暴露系统中的各种不稳定性与风险。
如果说红队是组织层面的反偏差机制,那么工程师可以随时随地使用的微观工具,就是元认知(metacognition)。
元认知(Metacognition)就是 “对自己思考的思考”。 它指一个人能够觉察、监控并调节自己的认知过程,例如注意力、理解、记忆、推理与决策。 简单来说,元认知让你能问自己:
我现在在想什么?
我为什么这样想?
我是不是遗漏了什么?
我应该怎样思考得更好?
软件工程师和测试工程师都是创造者。
测试输出的用例,不是凭空产生的,而是基于个人经验、知识结构、信息来源、风险模型,以及隐含的价值判断。
然而我们也清楚:
测试不可能穷尽
测试资源永远有限
测试需要在创造与批判之间平衡
任何测试最终都要形成 “可交付” 的结果
正因为如此,在得出测试方案的那一刻,再回头思考——我刚才是如何思考的?我在哪里可能犯了错?哪里可能有偏差?——这正是元认知被激活的瞬间。
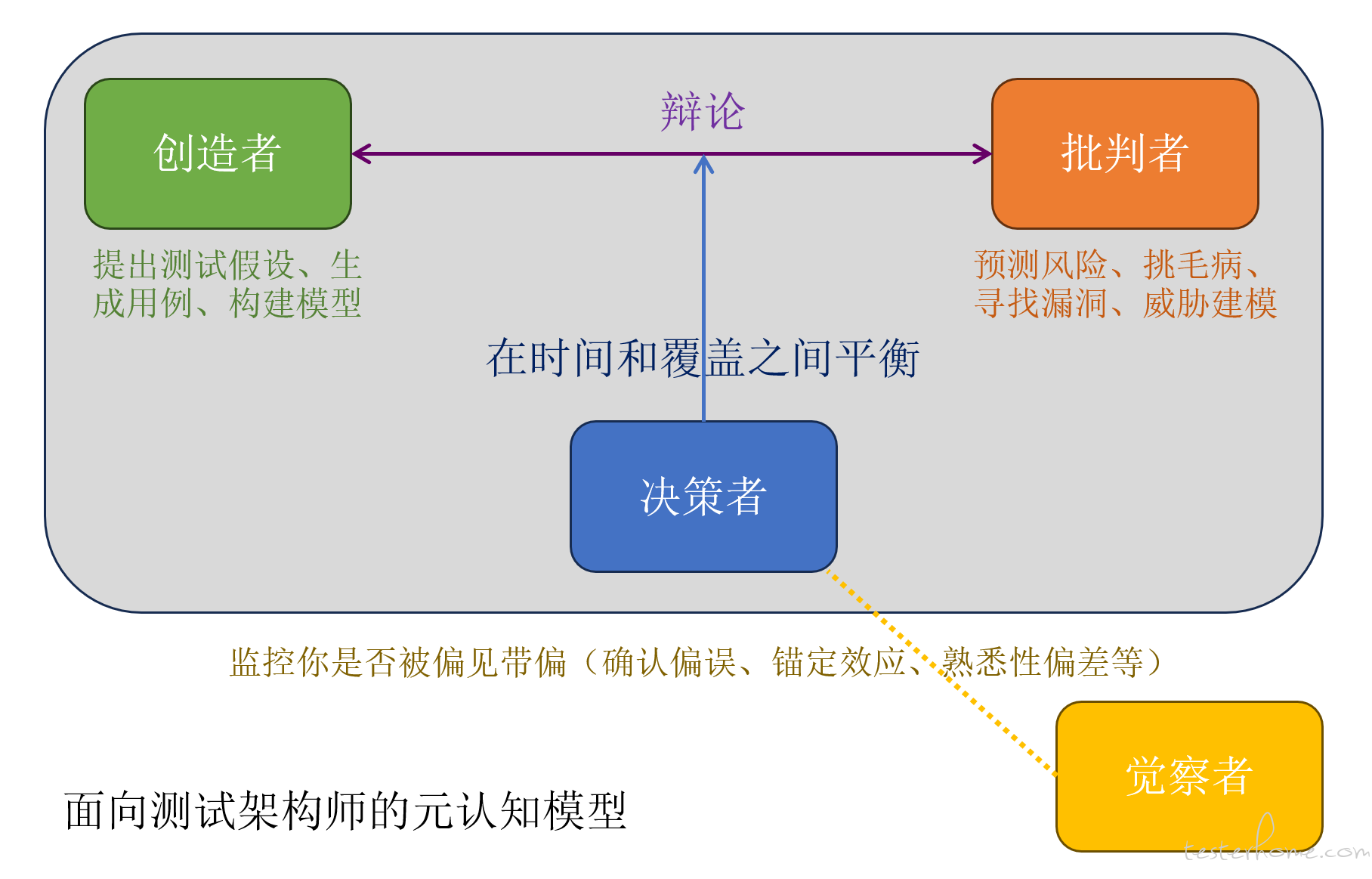
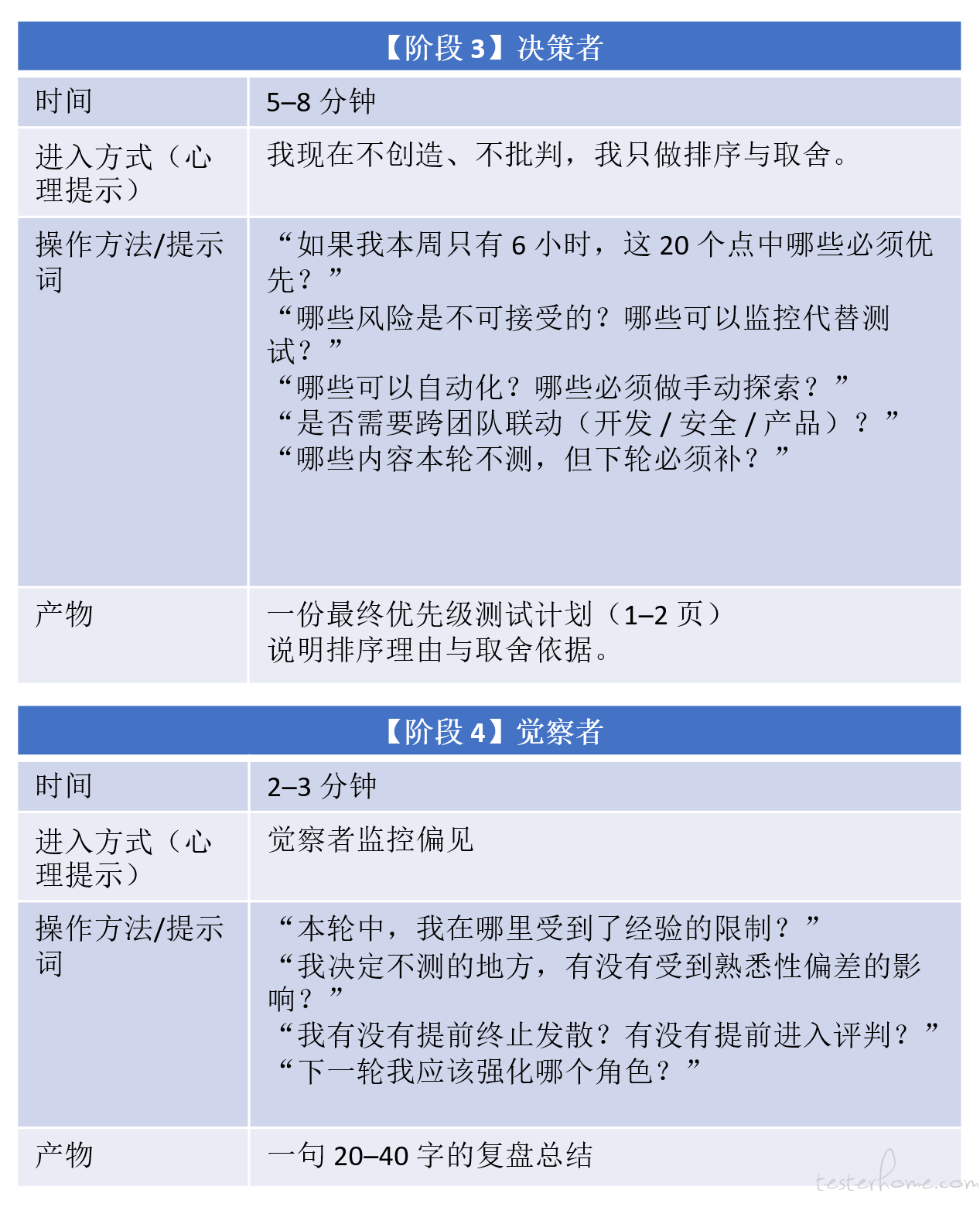
为了让元认知从抽象的理论变成可以日常使用的工具,我把测试过程拆成四个角色:
创造者(Creator):不设限地提出测试思路与想法
批判者(Critic):怀疑、挑战、反驳创造者的假设
决策者(Decision Maker):在成本、风险、资源间权衡
觉察者(Observer):观察前三者是否陷入偏差、遗漏或情绪化判断
你可以把它理解成一个 “测试团队的内部对话”,只是四个角色都在你的脑子里。
为了让工程师可以马上用起来,我设计了一个简单的引导表格。当你要为一个新产品设计测试时,可以按顺序扮演这四个角色。
创造者 → 批判者 → 决策者 → 觉察者
每个角色都在问不同的问题,也看不同的风险,因此能从不同角度暴露偏差。

让工程师扮演多个角色,很容易担心会产生 “认知切换负担”(context switching cost)。
但元认知工具恰好解决了这一点:
它把无意识、混在一起的 “直觉式快思考(System 1)” 拆解成几个步骤,从而有序地进入 “逻辑式慢思考(System 2)”。
元认知并不是为了让你的思考变慢,而是:
让你在关键节点启动系统 2
帮你避免惯性判断
让决策更贴近事实
减少由于偏差导致的返工
提升测试的覆盖性与可靠性
在资源有限的情况下做更合理的取舍
换句话说:
元认知不是降低效率,而是提升 “有效性”。
它让你的输出更接近客观世界,而不是某种个人经验、惰性认知或即时情绪的结果。
最后要说的
通过这三个故事,我更加确信:
AI 能极大提升效率,但会放大认知偏差
AI 生成的代码会把 “深层缺陷” 更快地带入系统
AI 时代测试的挑战不是变少,而是变得更隐蔽、更心理化
元认知是工程师最重要的 “工具中的工具”
未来测试工程师的核心竞争力,除了 “发现缺陷”,也应该包括:
觉察偏差
管理偏差
构建能抵抗偏差的流程与系统
这或许会成为后 AI 时代测试职业最关键的能力之一。
张昊翔
2025/11/24
WeChat: hzhan11
QQ: 22321262
Email: xjtu_xiangxiang@hotmail.com
LinkedIn: https://www.linkedin.com/in/hzhan11/