AI测试 「0 代码,会思考」:我们开源了一个能自主找 bug 的 agent
本文转自我的公众号:https://mp.weixin.qq.com/s/Mp1pNgUetApP2nAGQndIZw
上一篇讨论文章:https://testerhome.com/topics/42784 中,给出了我个人对 AI 给软件质量领域带来的挑战的一些思考——当生产过程、运行结果都变得难以预测时,我们过去依赖的确定性测试体系,似乎正在失效。
也提到了一个想法:或许 QA 的新角色,是一起去成为 “造船师”,去打造能驾驭这股不确定性浪潮的新工具。
这个想法过去其实一直萦绕在脑海里,与其停留在内部讨论,我和其它同事觉得不如动手试一下,基于这个初衷,我们进行了一次不成熟的探索,并在内部一些项目应用后,把这个阶段性的产物 webqa-agent:一个能自主进行测试评估的智能体开源。
我们希望将它作为一个具体的话题起点,与社区的朋友们一同探讨,AI 下的质量保障工具可能会是什么样的。
GitHub:https://github.com/MigoXLab/webqa-agent
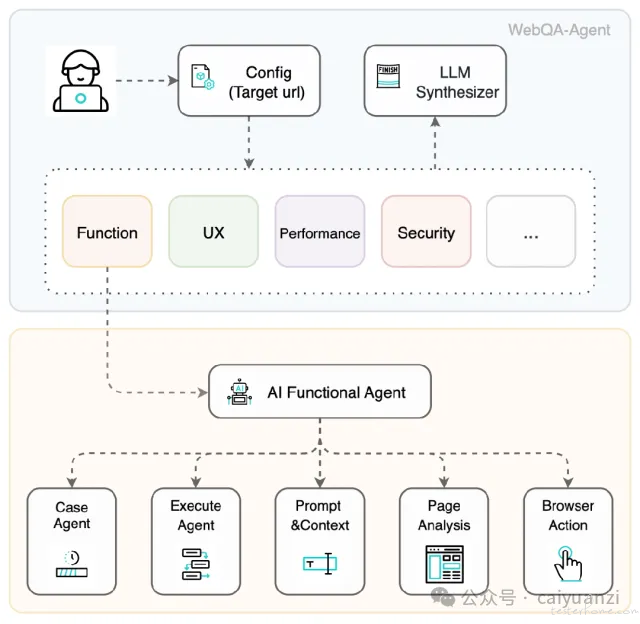
我们的初步思考:从 “寻找已知” 到 “感知意外”
在设计之初,我们反复思考一个问题:一个智能化的质量 Agent,其核心应该是什么?如果只是让 AI 替代人去编写或者是执行已经写好的测试脚本,那似乎只是效率的简单提升,而非范式的改变;似乎也只能满足一些专业测试工程师,而不是面向当前投身 vibe-coding 浪潮中的更多的创作者。
同时我们受启发于一个简单的观察:用户体验专家是如何发现系统深层问题的?往往不是通过核对清单,而是当现实的反馈与内心的预期产生冲突时,那种 “咦,这里不对劲” 的直觉。
我们尝试将这种 “差异认知模型” 放到 webqa-agent 中:
建立心智模型: 在 planning 阶段,Agent 会先通过多模态大模型(MLLM)理解目标网站的视觉、元素布局和用户提供的描述,结合它内置的 Web 通用知识,在 “脑海” 里形成一个关于网站该如何运作的初步心智模型,并规划出一张 “探索地图”。
带着预期去探索: 它的每一步交互,都不是随机的。它会带着 “如果我点击这个按钮,页面大概会跳转到...” 的预期去行动。
感知 “意外: 当操作后的实际结果,与它的预期严重不符时——比如点击后页面崩溃、陷入死循环,或进入了毫不相关的流程——这个 “意外” 就会被敏锐地捕捉。我们认为,这些预期之外的 “意外”,往往就是最值得关注的缺陷信号。
我们希望,通过这个思路,能让测试的重心从 “检查一个个已知的功能点”,稍微地转向 “探索和感知系统中不符合内在逻辑的异常”。
一份可追溯的 “思考过程”
面对 AI 这个 “黑盒”,过程的透明与可解释性,可能比结果本身更重要。因此,我们还希望它会努力呈现出自己的 “思考过程”:
一份动态生成的测试用例集: Agent 的每一次探索、预期和发现,都会被结构化地记录下来,希望能沉淀资产,并可以随时独立执行。比如测试一个大模型 chatbot: https://demo.chat-sdk.dev/ ,生成的其中一个测例:
"name": "首页对话功能-发送空消息校验",
"objective": "验证用户尝试发送空消息时,系统能正确阻止并给予友好提示,防止无效数据进入对话流程",
"test_category": "Chat_Validation",
"priority": "High",
"business_context": "防止用户误操作或恶意提交空消息,保障对话内容有效性和系统稳定性",
"functional_criticality": "高 - 影响数据质量和用户体验",
"domain_specific_rules": "禁止空消息发送,需有前端或后端校验与提示",
"test_data_requirements": "空白输入、仅包含空格、Tab等不可见字符",
"preamble_actions": [],
"steps": [
{"action": "在首页输入框不输入任何内容"},
{"action": "点击发送按钮"},
{"verify": "确认页面未发送空消息,且有提示信息如'消息不能为空'"},
{"action": "在输入框输入多个空格"},
{"action": "点击发送按钮"},
{"verify": "确认页面未发送空消息,且有提示信息如'消息不能为空'"}
],
"reset_session": true,
"success_criteria": [
"空消息无法被发送",
"用户获得明确的错误提示",
"页面无异常或崩溃"
],
...
一份多维度的健康度评估: 除了功能缺陷,它也会从性能、设计一致性、安全等多个方面,给出对系统当前状态的综合看法。
一张可视化的 “探索地图”: 我们会尝试让 Agent 的探索路径和决策过程变得更加清晰可见。
仅是一次尝试,不是一个答案
这个测试智能体目前还远非完美,它更像是一个原型,承载了我们对于未来质量工具的一些初步想法。
选择在这个阶段将其开源,正是想将这些不成熟的想法抛出来,与社区中每一位正在思考、探索的同行们进行交流。
也欢迎关注和 star 我们在 QA 领域探索的一系列其它测试工具:
面向大模型/数据质量评估工具:https://github.com/MigoXLab/dingo
面向大模型服务压测工具:https://github.com/MigoXLab/LMeterx