痛点
没看太懂它的本地部署是怎么部署的?难道就是拉整个代码仓库到本地吗?找了很多帖子。介绍的都是一知半解。问了 Ai 回答的也不是很准确。怕自己在这个上边走弯路。想问一下有没有人使用过。能给个避坑指南呢?
https://docs.stagehand.dev/reference/playwright_interop -官方文档
https://github.com/browserbase/stagehand/issues -代码仓库
我帮你试了下,直接安装就可以用了,就是这个模型好像只能用国外的
- 安装
pip install stagehand
python -m playwright install #playWright相关依赖
pip install python-dotenv
2.设置环境变量,项目文件夹里创建.env 文件
# 前面这两个配置呢,是如果你要用云端Browserbase调试,就配置
export BROWSERBASE_API_KEY="your_browserbase_api_key"
export BROWSERBASE_PROJECT_ID="your_browserbase_project_id"
# 这个是你要用的大模型密钥
export MODEL_API_KEY="your_model_api_key" # OpenAI, Anthropic, etc.
3.本地创建文件,如 demo.py
import asyncio
import os
from stagehand import Stagehand, StagehandConfig
from dotenv import load_dotenv
#读取.env配置文件
load_dotenv()
async def main():
config = StagehandConfig(
env="LOCAL", #你这里想要用本地浏览器就local,如果是云的就用"BROWSERBASE"
# 这两个配置是云端调试时使用,如果是本地就可以注释掉了
api_key=os.getenv("BROWSERBASE_API_KEY"),
project_id=os.getenv("BROWSERBASE_PROJECT_ID"),
#填写你要用的模型,密钥在.env文件配置
model_name="gpt-4o",
model_api_key=os.getenv("MODEL_API_KEY")
# 这里你可以做这些配置
headless=True, #打开调试窗口
verbose=3,
debug_dom=True
)
stagehand = Stagehand(config)
try:
await stagehand.init()
page = stagehand.page
await page.goto("填写你要跳转的网页地址")
await page.act("自然语言写明你要的操作")
result = await page.extract("extract the main heading of the page")
print(f"Extracted: {result}")
finally:
await stagehand.close()
if __name__ == "__main__":
asyncio.run(main())
4 运行 python demo.py 即可
5 相关流程顺序:
1. 页面导航page.goto(url)
2. 页面观察observe()
3. 页面执行操作act()
4. 页面数据提取extract()
eg:
# 1. 使用 observe() 找到元素
search_box = await page.observe("找到页面顶部的搜索框")
# 2. 使用 act() 执行操作
await page.act("在搜索框中输入'人工智能发展'并按下回车键")
# 3. 等待页面加载完成
await page.wait_for_load_state("networkidle")
# 4. 使用 extract() 提取数据
introduction = await page.extract("提取关于deepseek的全部文章链接")
6 核心方法
observe() 方法用于分析当前页面,根据自然语言指令识别和定位特定的页面元素。它不会执行任何操作,只是返回关于找到元素的信息。
# 查找页面上的登录按钮
login_button = await page.observe("找到登录按钮")
# 查找特定的文章链接
article_link = await page.observe("找到关于AI的最新文章链接")
# 查找搜索框
search_box = await page.observe("找到页面顶部的搜索输入框")
act() 方法用于在页面上执行具体的操作,如点击、输入文本、导航等。它接受自然语言指令并将其转换为具体的浏览器操作。
# 点击按钮
await page.act("点击登录按钮")
# 输入文本
await page.act("在搜索框中输入'人工智能'")
# 导航操作
await page.act("点击第一篇文章链接")
# 复合操作
await page.act("填写用户名为'user123',密码为'password123',然后点击登录")
extract() 方法用于从页面中提取信息。如果不指定特定的数据格式,它可以返回自然语言描述的内容。
# 直接用自然语言提取信息
content = await page.extract("提取页面的主要内容")
print(content)
# 提取特定信息
title = await page.extract("提取文章标题")
author = await page.extract("提取作者姓名")
summary = await page.extract("提取文章摘要")
就这个模型我用 deepseek 整不了,只能用 gpt 的,貌似没有兼容
 。你是直接新建了个 python 项目去跑这个脚本的吗?我目前也卡壳在这个配置国内模型上边。它的文档和 github 上都没有明确说明这个配置国内模型的地方。但是说支持自定义 llm
。你是直接新建了个 python 项目去跑这个脚本的吗?我目前也卡壳在这个配置国内模型上边。它的文档和 github 上都没有明确说明这个配置国内模型的地方。但是说支持自定义 llm
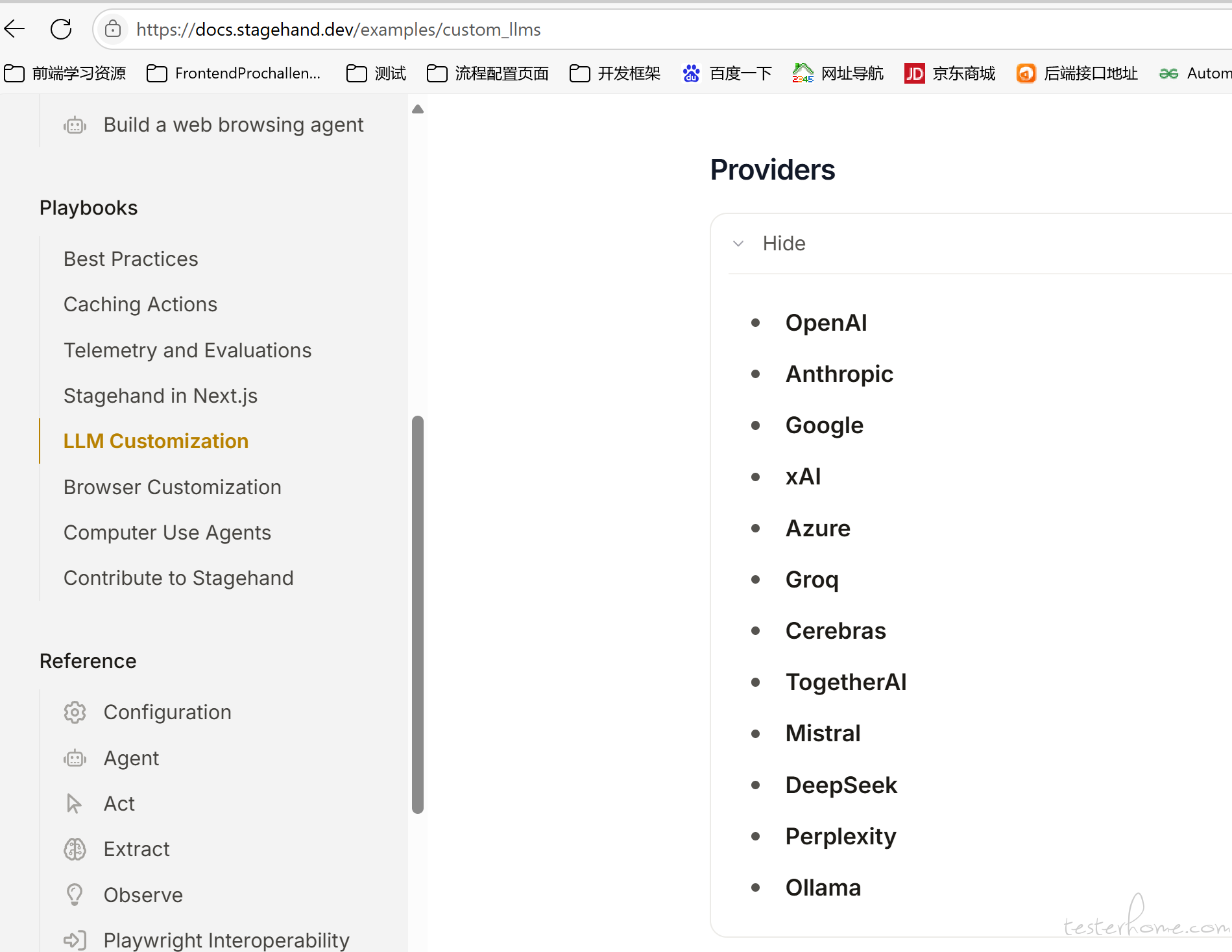
Nice! 我找到配置自定义大模型的方式了。在官方文档上边https://docs.stagehand.dev/examples/custom_llms
之前白走了好多弯路》谢谢大佬的灵感提供!!
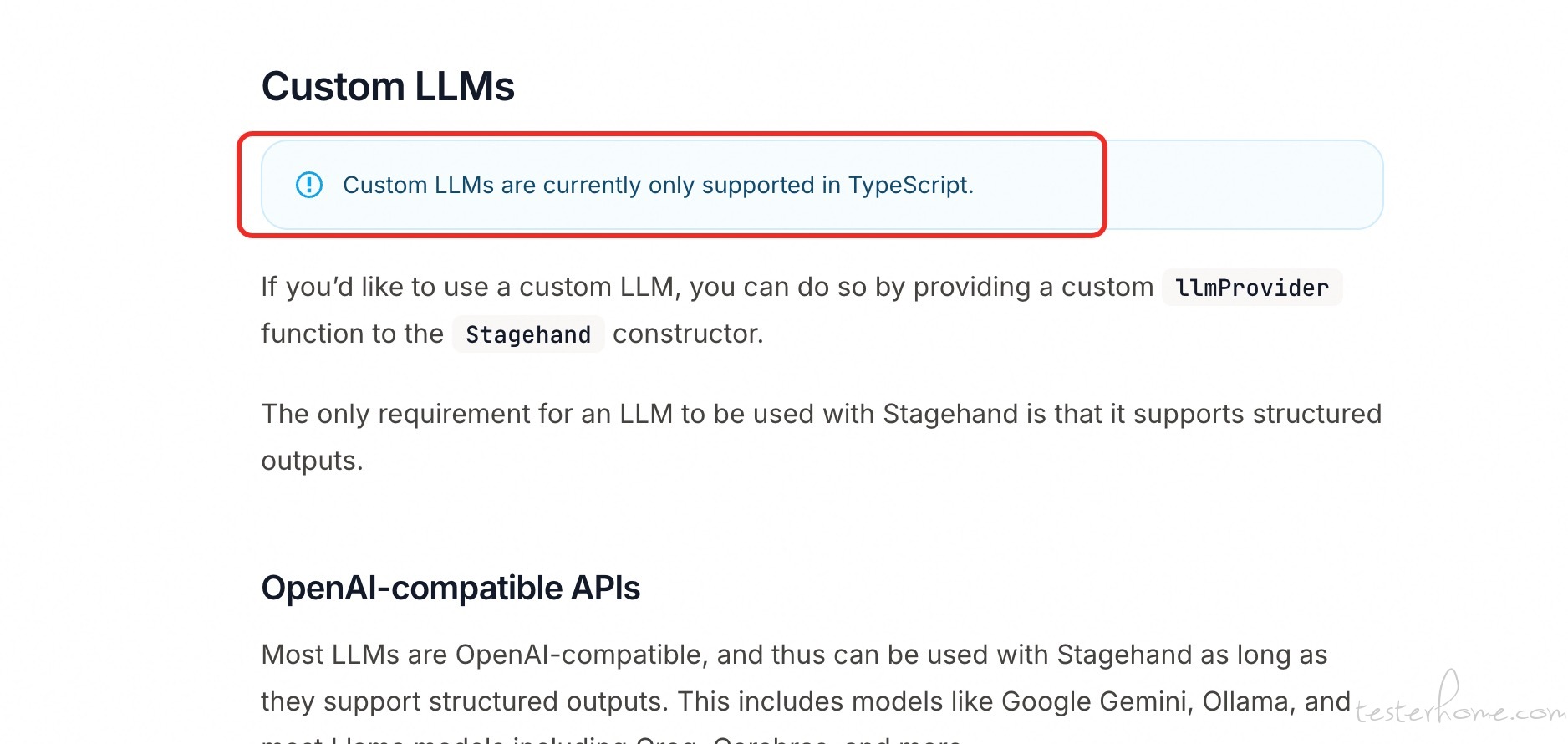
看官方文档说只支持 TypeScript 配置自定义模型。试了一下 Python 也能够设置自己的模型,只是有点 hacky
config = StagehandConfig(
env="LOCAL",
model_name="litellm_proxy/custom_deepseek_model_name",
model_api_key=os.getenv("MODEL_API_KEY")
)
stagehand = Stagehand(config)
stagehand.llm = LLMClient(
stagehand_logger=stagehand.logger,
api_key=stagehand.model_api_key,
default_model=stagehand.model_name,
metrics_callback=stagehand._handle_llm_metrics,
api_base="https://opt.mydeepseek-inc.com/deepseek/v1/",
**stagehand.model_client_options,
)
大佬,你那边可以用吗?
我用 deepseek 做调试时,一直给我返回 deepseek api 目前不支持 Stagehand 所需的特定 response_format 类型的报错
大佬成功了吗? 我之前试了千问和 deepseek 都不行,这个配置那个时候我看到了,但是一直返回这个报错
{"error":{"message":"This response_format type is unavailable now","type":"invalid_request_error","param":null,"code":"invalid_request_error"}}
Stagehand 会将网页的 dom 结构发送给 llm 进行分析,这可能包含页面上的敏感信息, 你这是公司要用,还是自己调研的?
我是自己部署的 deepseek,跑起来没问题的
你是用 deepseek 官方的 api,还是自己部署的 deepseek 哦?我看 stagehand 底层用的 litellm,可以参考这个配置使用官方 api: https://docs.litellm.ai/docs/providers/deepseek
如果是自己的部署的,模型名字前面加 litellm_proxy/
我没配置 deepseek.我以为你的意思是直接不能配置呢.我用的是 qwen3-14b。你可以先通过 curl 命令获取 deepseek 模型返回的数据结构。然后再一步步调整成 stagehand 适配的结构。最后应该就正常了。我之前是这样的。但是我发现我把模型直接写道那个用例.ts。没配置那些什么 strem,enale_thinking 这些参数就能正常使用
我主要是遇到:
- enable_thinking=False
- 使用结构化输出 (response_format) 时,【dashscope 要求消息中必须包含 "json" 关键词
- 这框架把千问模型的地址默认为国际地址,换成国内的需要自己设置下
这三个问题,在我各种瞎调下,是可以跑了,就是这个 token 的消耗还挺大,感觉实用程度有待商榷

import asyncio
import os
from stagehand import Stagehand, StagehandConfig
from dotenv import load_dotenv
import litellm
# 保存原始completion函数
original_completion = litellm.completion
# 创建一个新的completion函数,确保总是包含enable_thinking=False,并修复Dashscope的json要求
def patched_completion(*args, **kwargs):
# 确保extra_body存在并且包含enable_thinking=False
if "extra_body" not in kwargs or kwargs["extra_body"] is None:
kwargs["extra_body"] = {}
kwargs["extra_body"]["enable_thinking"] = False
# 修复Dashscope的json要求 - 确保messages中包含"json"关键词
if "response_format" in kwargs and kwargs["response_format"] is not None:
# 检查是否是json_schema格式
if hasattr(kwargs["response_format"], '__dict__') or isinstance(kwargs["response_format"], dict):
# 确保系统消息中包含json关键词
if "messages" in kwargs and len(kwargs["messages"]) > 0:
system_message = kwargs["messages"][0]
if system_message["role"] == "system" and "json" not in system_message["content"].lower():
# 添加json关键词到系统消息中
system_message["content"] += " Respond in JSON format."
try:
result = original_completion(*args, **kwargs)
return result
except Exception as e:
raise
# 替换litellm.completion
litellm.completion = patched_completion
load_dotenv()
async def main():
# 确保环境变量正确设置
os.environ['DASHSCOPE_API_BASE'] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 检查API密钥
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
print("错误: 未找到DASHSCOPE_API_KEY环境变量")
return
# 配置 Stagehand 使用 DashScope 的 Qwen 模型
config = StagehandConfig(
env="LOCAL",
model_name="dashscope/qwen3-14b",
model_api_key=os.getenv("DASHSCOPE_API_KEY"),
headless=False, # 显示浏览器窗口
verbose=3, # 最详细的日志输出
debug_dom=True, # 启用DOM调试
dom_settle_timeout_ms=60000, # 增加DOM稳定超时时间
wait_for_network_idle_ms=5000, # 等待网络空闲的时间
local_browser_launch_options={ # 本地浏览器启动选项
"slow_mo": 100, # 减慢操作速度以便观察
"devtools": True, # 打开开发者工具
"args": [
"--window-size=1920,1080", # 设置窗口大小
"--disable-web-security", # 禁用网络安全限制
"--disable-features=IsolateOrigins,site-per-process" # 禁用某些隔离功能
]
}
)
# 初始化 Stagehand
stagehand = Stagehand(config)
try:
await stagehand.init()
page = stagehand.page
print("=== 必应搜索测试任务 ===")
# 1. 访问必应
print("1. 正在访问必应...")
await page.goto("https://cn.bing.com/")
print(" 已访问必应")
# 等待页面加载完成
await asyncio.sleep(3)
# 2. 输入搜索词
print("2. 正在输入搜索词...")
await page.act("在搜索框中输入搜索词'天气'")
print(" 已输入搜索词")
# 等待输入完成
await asyncio.sleep(2)
# 3. 点击搜索
print("3. 正在点击搜索按钮...")
await page.act("点击搜索按钮")
print(" 已点击搜索按钮")
# 等待搜索结果页面加载
await asyncio.sleep(5)
# 验证操作结果
print("4. 正在验证搜索结果...")
title = await page.title()
print(f" 当前页面标题: {title}")
# 获取页面URL验证是否跳转
current_url = page.url
print(f" 当前页面URL: {current_url}")
# 提取页面主要内容
print("5. 正在提取搜索结果...")
content = await page.extract("提取页面中与天气相关的主要信息", schema=None)
print(f" 搜索结果: {content}")
# 保持浏览器打开一段时间以便观察
print("6. 保持浏览器打开10秒钟以便观察...")
await asyncio.sleep(10)
print("=== 必应搜索测试完成 ===")
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()
finally:
input("按回车键关闭浏览器...")
await stagehand.close()
if __name__ == "__main__":
asyncio.run(main())

确实,体验下来,感觉这类大模型的自动化始终存在两个问题不适合在 CICD 中使用
- 不稳定性:就算这里拆成单步操作,但也会存在不确定性
- 时间长:执行时间远比直接用 playwright 长
process.env.PYTHONIOENCODING = "utf-8";
import { Stagehand } from "@browserbasehq/stagehand";
import StagehandConfig from "./stagehand.config.js";
import { CustomOpenAIClient } from "./llm_clients/customOpenAI_client.js";
import OpenAI from "openai";
import dotenv from "dotenv";
import assert from "assert";
// 加载环境变量
dotenv.config();
assert(process.env.DASHSCOPE_API_KEY, "DASHSCOPE_API_KEY must be set in environment variables"); // [1]
async function performSearch(stagehand: Stagehand) {
const page = stagehand.page;
// 断言页面导航成功
const response = await page.goto("https://www.baidu.com");
assert(response?.ok(), Failed to load Baidu homepage. Status: ${response?.status()}); // [2]
// 断言搜索框存在并可输入
const typeResult = await page.act('type "Stagehand" into the search box');
assert(typeResult.success, Failed to type into search box: ${typeResult.message}); // [3]
// 断言搜索按钮点击成功
const clickResult = await page.act("click the search button");
assert(clickResult.success, Failed to click search button: ${clickResult.message}); // [4]
// 可选:断言搜索结果页面包含预期内容
await page.waitForSelector("#content_left", { timeout: 5000 });
const searchResults = await page.$eval("#content_left", el => el.textContent);
assert(searchResults?.includes("Stagehand"), "Search results did not contain expected term"); // [5]
}
(async () => {
let stagehand: Stagehand | null = null; // 显式声明类型并初始化为 null
try {
stagehand = new Stagehand({
...StagehandConfig,
llmClient: new CustomOpenAIClient({
modelName: "Qwen3-14B",
client: new OpenAI({
apiKey:"xxxxxxxxxxxxxxxxxxxxx",
baseURL: "http://xx.xx.x.xx:xx/v1/chat/completions",
}),
}),
});
await stagehand.init();
await performSearch(stagehand);
} catch (error) {
console.error("Test failed:", error);
process.exit(1);
} finally {
// 安全清理资源
try {
if (stagehand) await stagehand.close();
} catch (closeError) {
console.error("Failed to close Stagehand:", closeError);
}
}
})();
我这个控制台目前一直提示这样
ERROR: API key for openai not found in environment variable OPENAI_API_KEY
category: "init"
[2025-08-18 15:06:17.878 +0800] INFO: Custom LLM clients are currently not supported in API mode
category: "init"
我看和模型对话了。但是就执行了打开页面操作。那个 goto 又是 playwright 的。那个 act 也没执行
我安装了 stagehand 的库,然后 python 直接调用库来用就行了。但是感觉这个工具不太靠谱,粗看原理就是把 dom 结构全部发给语言大模型,然后让大模型把关键信息找出来再返回,一方面像上面那个大佬说的:不太稳定和执行缓慢。另一方面我是觉得 token 的消耗有点大,本地部署估计挺悬,非满血的大模型出来的效果更难保证。所以感觉这工具有点像坤肋
好的。我发现这个的相关资料也挺少的。我在 github 上问问题。也一直没见到有人回复。搜索到的资料都是说这个多厉害。但是具体的落地实现细节都没看到写的
playwright 也刚开始用,以前 cypress 用得多点,跑用例飞一样的感觉。
但感觉未来还是 playwright 的天下,因为他也很快,并且支持多语言,多浏览器,还自带并行执行,web 测试首选
我个人觉得这个落地的话,还需要跟公司申请一笔经费,以往自动化都不需要用钱,现在用上大模型还得花钱,能不能审批通过都是个问题,后期还得出份数据证明比免费的强
有大佬试过把这个 stagehand 与 pytest 结合起来吗?我试了一下把 stagehand 初始化的 pytest.fixture 里的 scope 设置为 session 之后就没办法顺利运行了