引言
为了支撑数十万 tps 的稳定性压测,,我们的压测平台对压测数据查询进行了优化,以提高整体测试效率和响应能力。这些优化措施确保平台能够在大流量场景下高效稳定地运行,从而为产品的性能和稳定性提供更有力的保障。
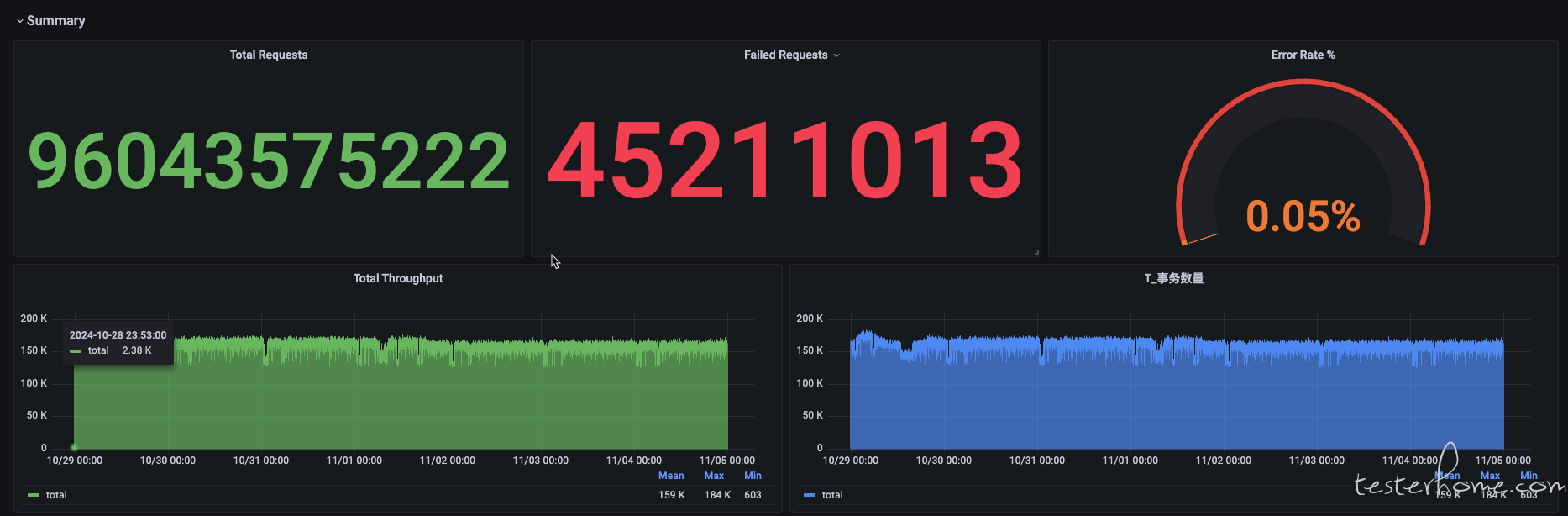
16w 左右 tps 的 7*24 小时压测
问题分析
1.压测数据无法加载
在压测平台中,InfluxDB 被用于存储和查询压测数据。然而,由于当时的 InfluxDB 数据库采用的是单体架构,未进行任何分片或分布式部署。随着系统中的数据量逐步增大,数据库逐渐暴露出性能瓶颈,尤其是在处理大规模的压测数据和历史数据加载时。
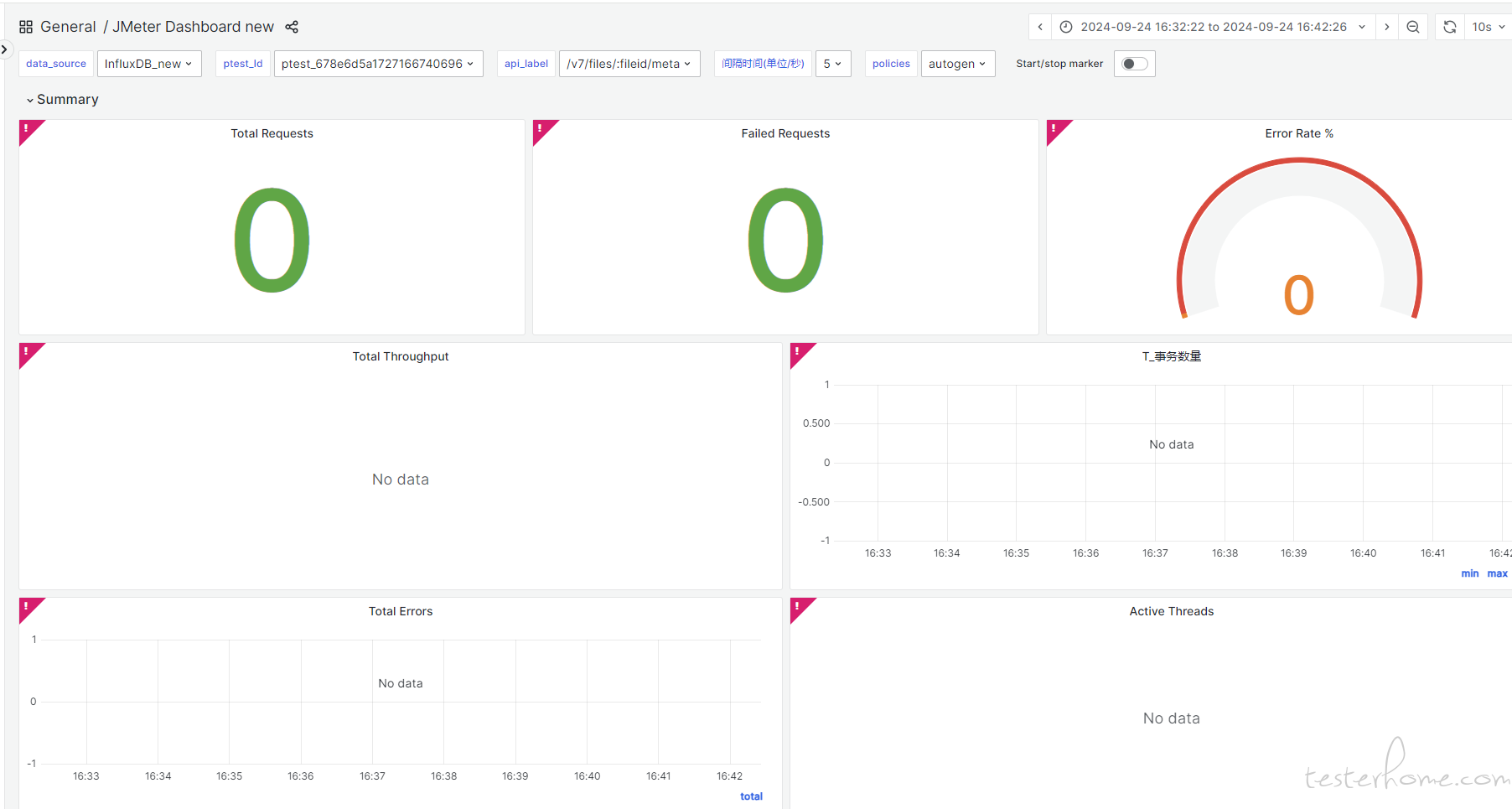
压测数据无法加载的情况
2.历史数据加载缓慢
在访问历史数据时,由于数据量庞大,InfluxDB 的查询效率下降明显。加载历史数据所需的时间变得过长,用户体验极差,查询往往需要等待数秒甚至数分钟才能完成,严重影响了系统的可用性和用户满意度。
3.资源利用率过高
单体架构的 InfluxDB 承担了所有的读写操作,导致日常查询和写入的负载极高,难以有效分担压力。数据库服务器的 CPU 使用率常年保持在 75% 以上,系统压力大时甚至接近满负荷,导致 CPU 无法为查询提供充足的资源支持。此外,数据库的内存经常性地被占满,进一步影响了数据查询的性能。
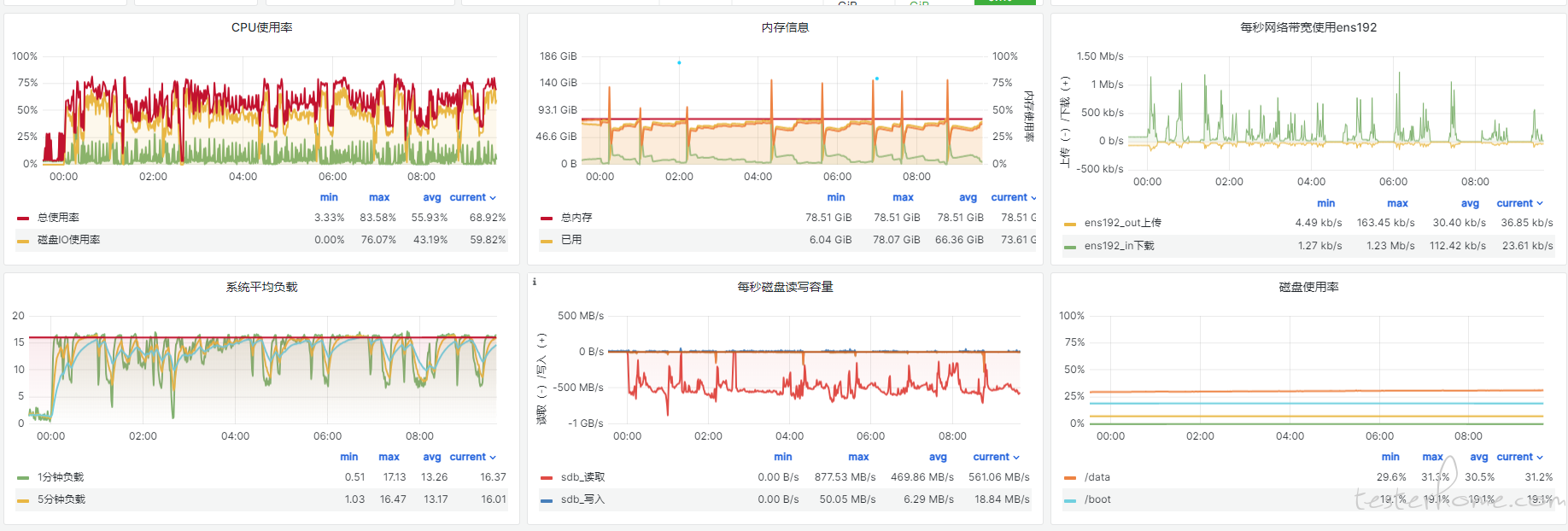
切换社区版 InfluxDB 的集群版后遇到的新问题
为了缓解单体架构的性能瓶颈,我们尝试切换到 InfluxDB 的集群版本,以便在分布式架构下处理更大的数据量。初期切换后,系统的负载确实有所缓解,一些性能问题得到了改善。然而,在运行约半个月后,新的问题开始显现:
高 IO 读操作
在没有任何查询操作的情况下,系统的 IO 读负载持续偏高。经过详细排查,发现这种高 IO 读并非由用户查询引起,而是在数据写入时触发的。这样的现象导致了系统存储设备的高频读操作,增加了硬件的负载,并降低了整体系统的稳定性。
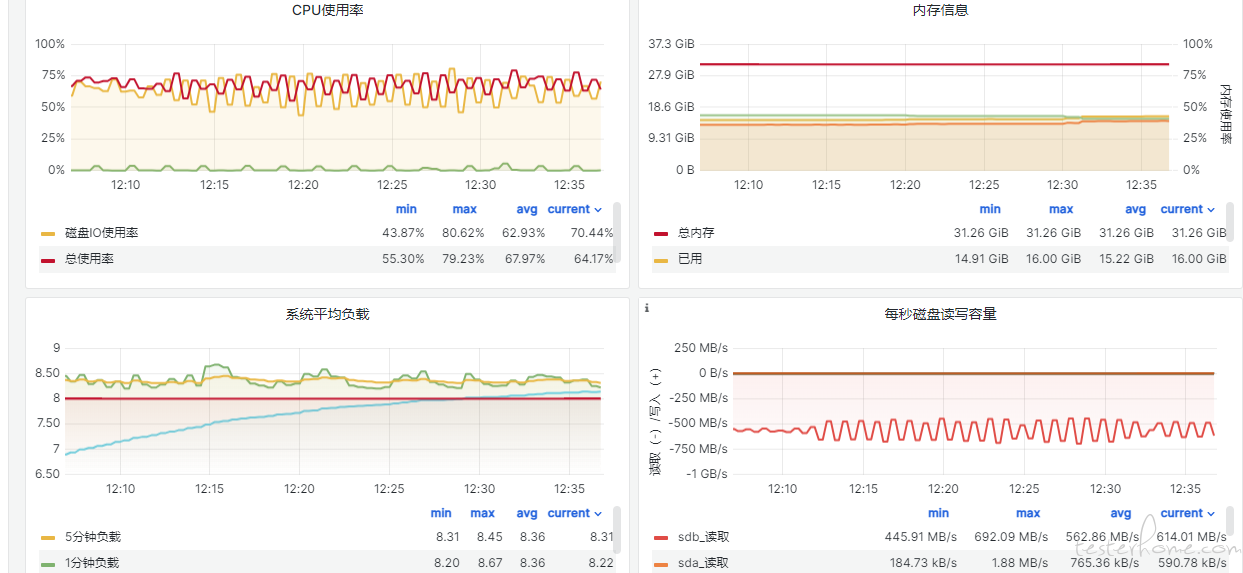
数据压缩导致的 IO 读压力
经过分析和阅读 InfluxDB 的代码,发现问题的根源在于 InfluxDB 在进行数据写入时,触发了自动的数据压缩机制。这个压缩机制在检测到内存索引达到压缩阈值时,会执行一次数据压缩操作。数据压缩的过程需要遍历索引,这种操作会频繁地进行大量磁盘 IO 读取,加重了系统的读负载。
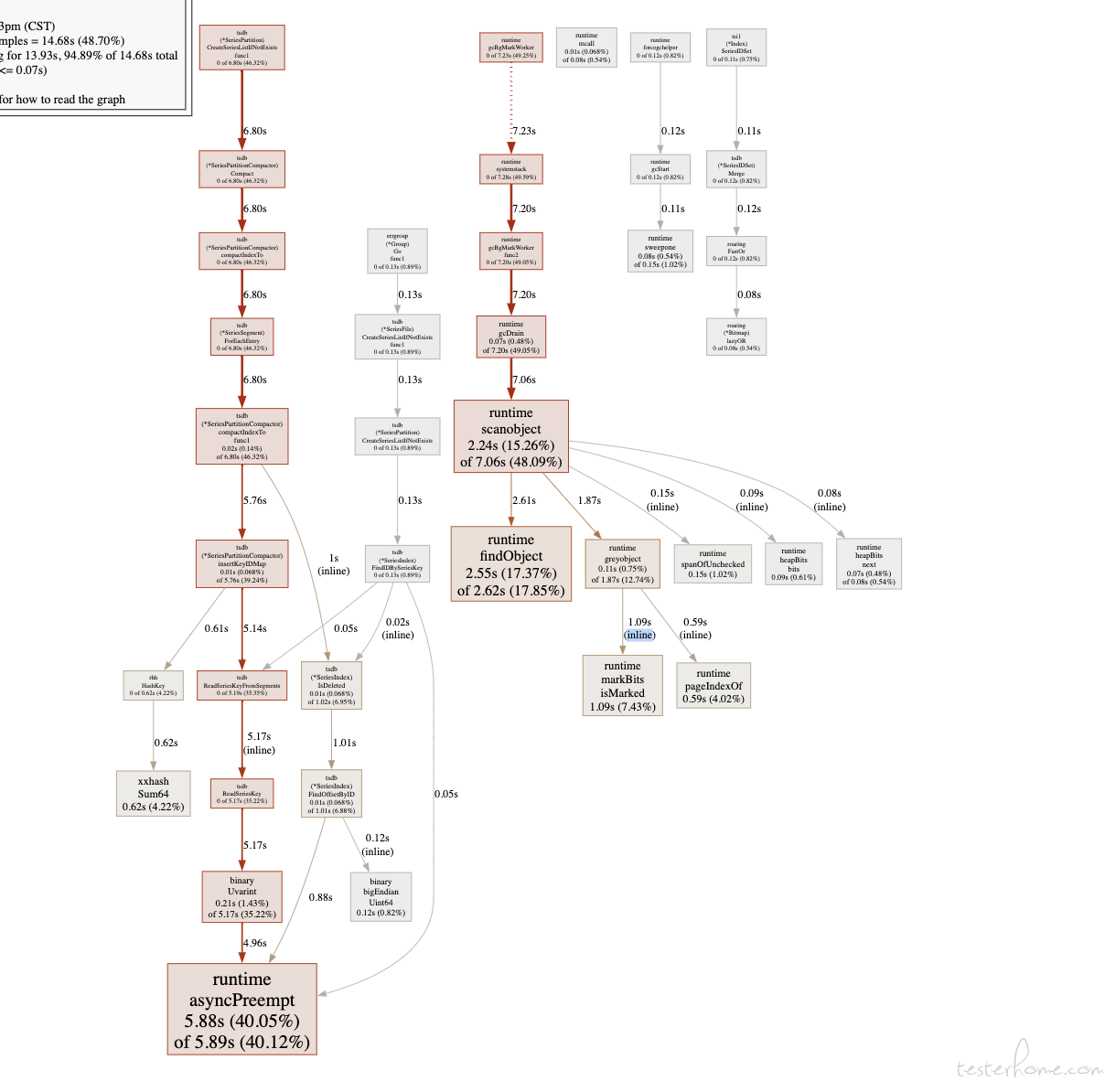
pprof 分析
influxdb 出问题的代码块
社区支持有限
由于 InfluxDB 的社区版集群是由社区维护,在发现高 IO 读负载问题后,我们尝试向社区寻求支持。然而,由于社区支持有限,未能找到有效的解决方案,问题持续影响系统性能,并可能导致数据加载变慢或读写操作卡顿。
决策与解决方案
在社区支持无果的情况下,为了保证系统的稳定性和高效性,我们最终决定 切换底层存储数据库,选择一个能够更好处理海量数据写入和压缩任务的数据库方案。这个决策的目的是找到一种能够提供稳定、高效的存储和查询功能的底层数据库,从而支持系统长期的高并发写入和查询需求,避免因单点存储性能限制带来的瓶颈问题。
新部署架构设计
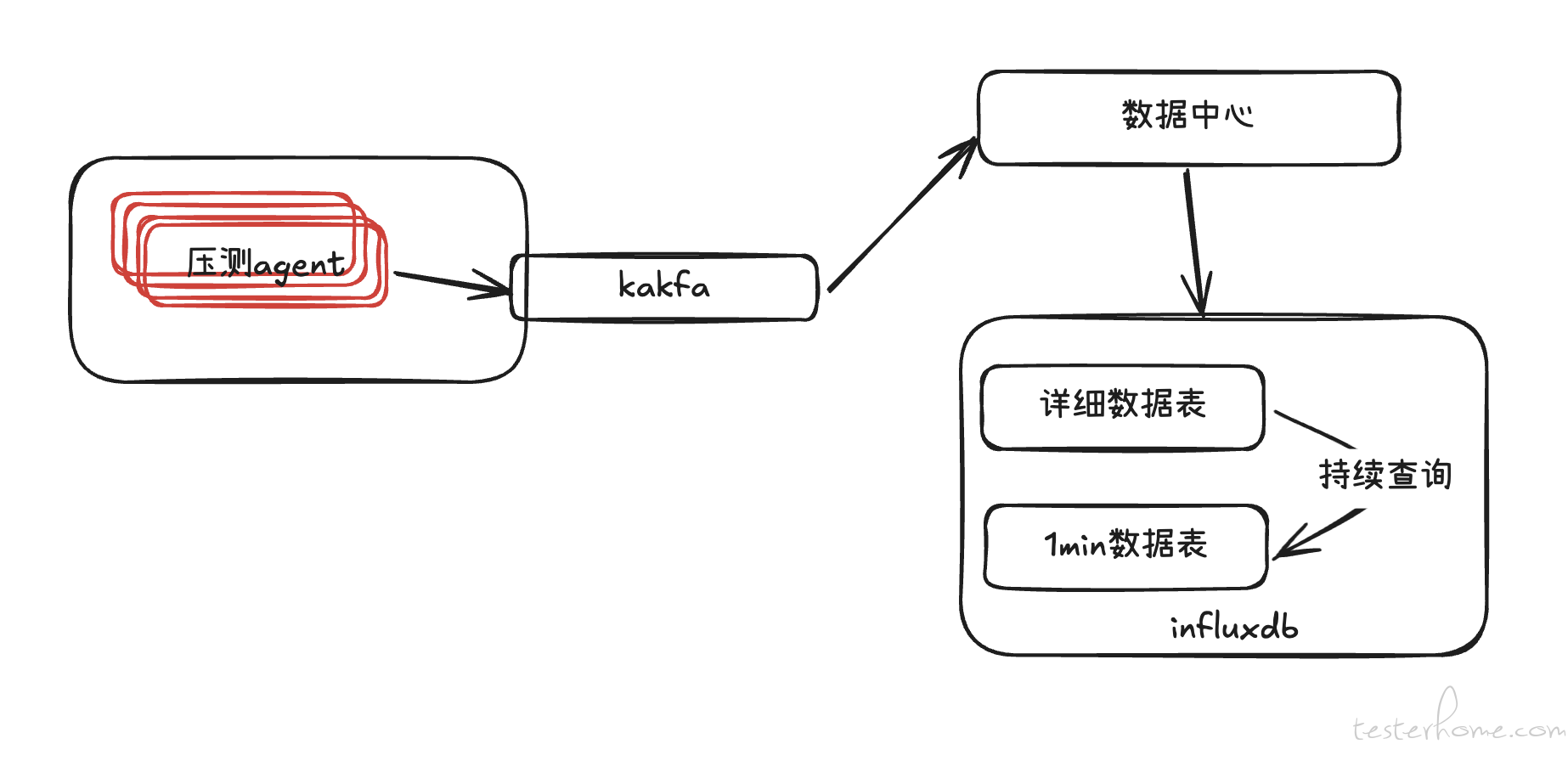
优化前架构梳理
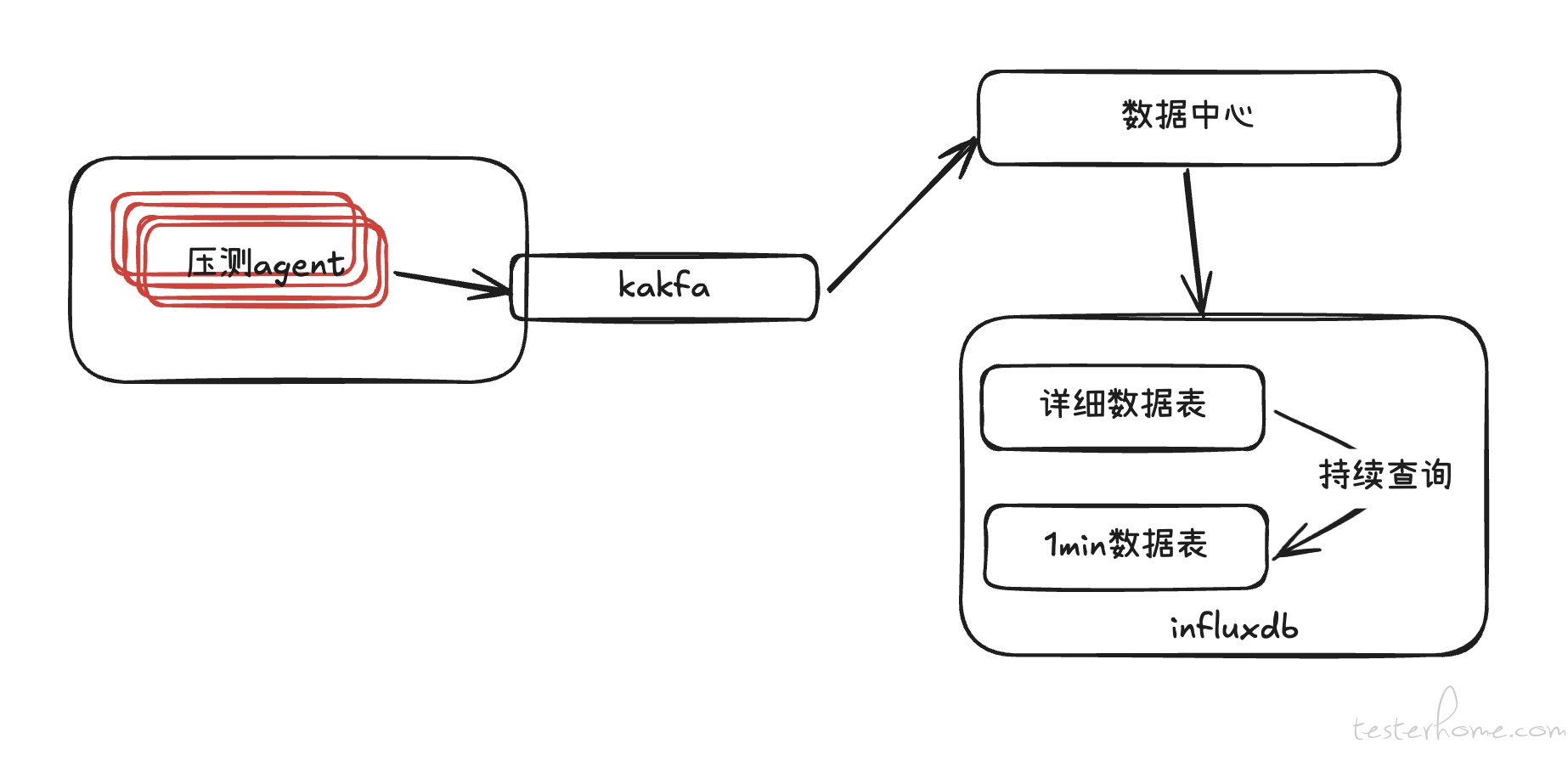
优化前的系统架构如下:压测代理(agent)将压测数据写入 Kafka,数据中心从 Kafka 中获取数据并按每秒进行聚合处理,随后将结果写入 InfluxDB。我们利用 InfluxDB 的持续查询功能,每分钟将详细数据转存至 1 分钟间隔的聚合数据表,从而将数据压缩至原始量的 50% 左右。
虽然该架构在设计上无明显缺陷,但由于 InfluxDB 的开源版本仅支持单机部署,无法进行分布式扩展,因此在短时间内出现大批量数据写入和查询请求时会遇到性能瓶颈。为确保系统能够支撑 15-17 万 TPS 的压测需求,我们决定更换底层的存储数据库,以支持更高的并发处理能力和更稳定的性能表现。
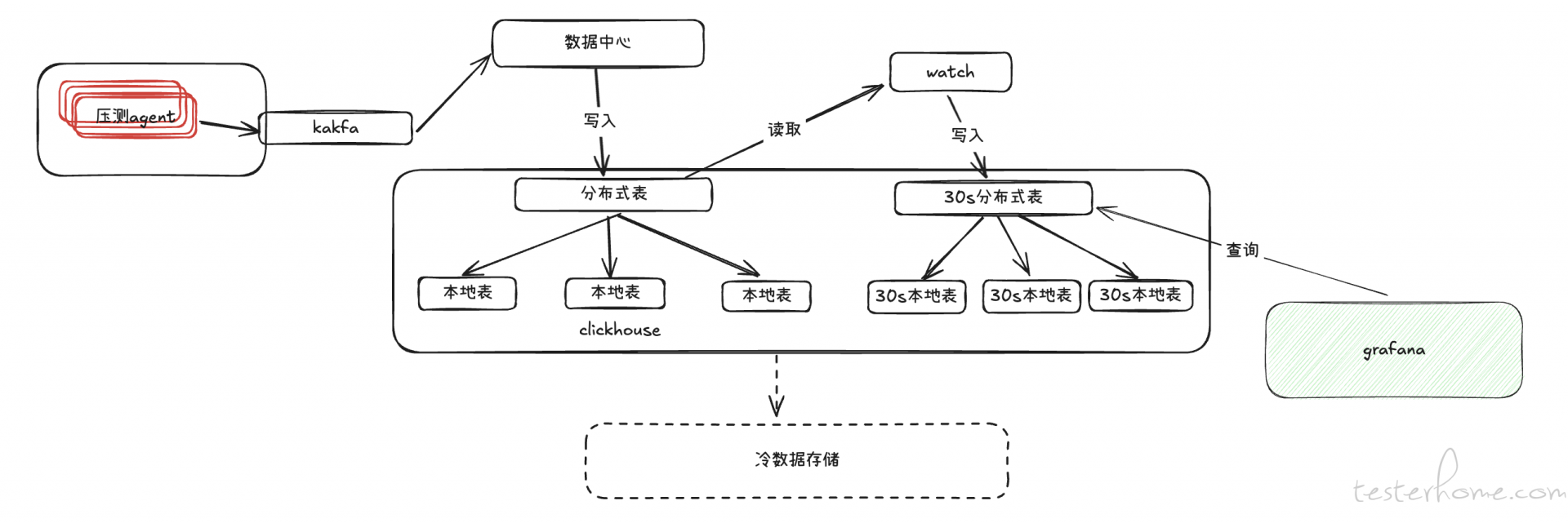
优化后核心部署架构
新的部署架构将原存储于 InfluxDB 的数据迁移至 ClickHouse 数据库,以充分利用 ClickHouse 多节点计算的优势。压测数据通常按列聚合计算,而 ClickHouse 作为列式数据库非常适合这一需求。
由于 ClickHouse 没有类似 InfluxDB 的持续查询功能,我们开发了一个自定义的 watch 服务,用于每 30 秒自动聚合并转存原始数据至新的 30 秒维度的表中。考虑到数据随着时间的推移查询频率逐渐降低,我们计划将超过 30 天的数据转存为冷数据至磁盘,以降低频繁读写对磁盘的压力。
Grafana 实时读取 30 秒维度的分布式表,以近实时方式展示压测数据,此时数据大约有 1 分钟延迟,但在性能测试中这一延迟可忽略不计。通过这种架构优化,ClickHouse 可以高效地执行数据聚合计算,并实现灵活的历史数据管理,显著提升了系统的性能和可扩展性。
watch 服务架构
watch 服务启动时,会从 Redis 中读取一个 startTime 作为初始查询时间,并将当前时间 now 作为 endTime,在 ClickHouse 中执行相应的查询和聚合操作。
在查询和写入操作完成后,watch 服务将 now 更新到 Redis 中的 startTime,实现查询时间窗口的动态滚动更新。这种设计确保 watch 服务始终在正确的时间窗口内执行数据查询和聚合操作,从而实现数据的持续更新和处理。
通过这种滚动更新机制,系统能够高效管理数据的时效性,确保数据处理的连续性与一致性,同时有效提升了整体系统的稳定性和可靠性。
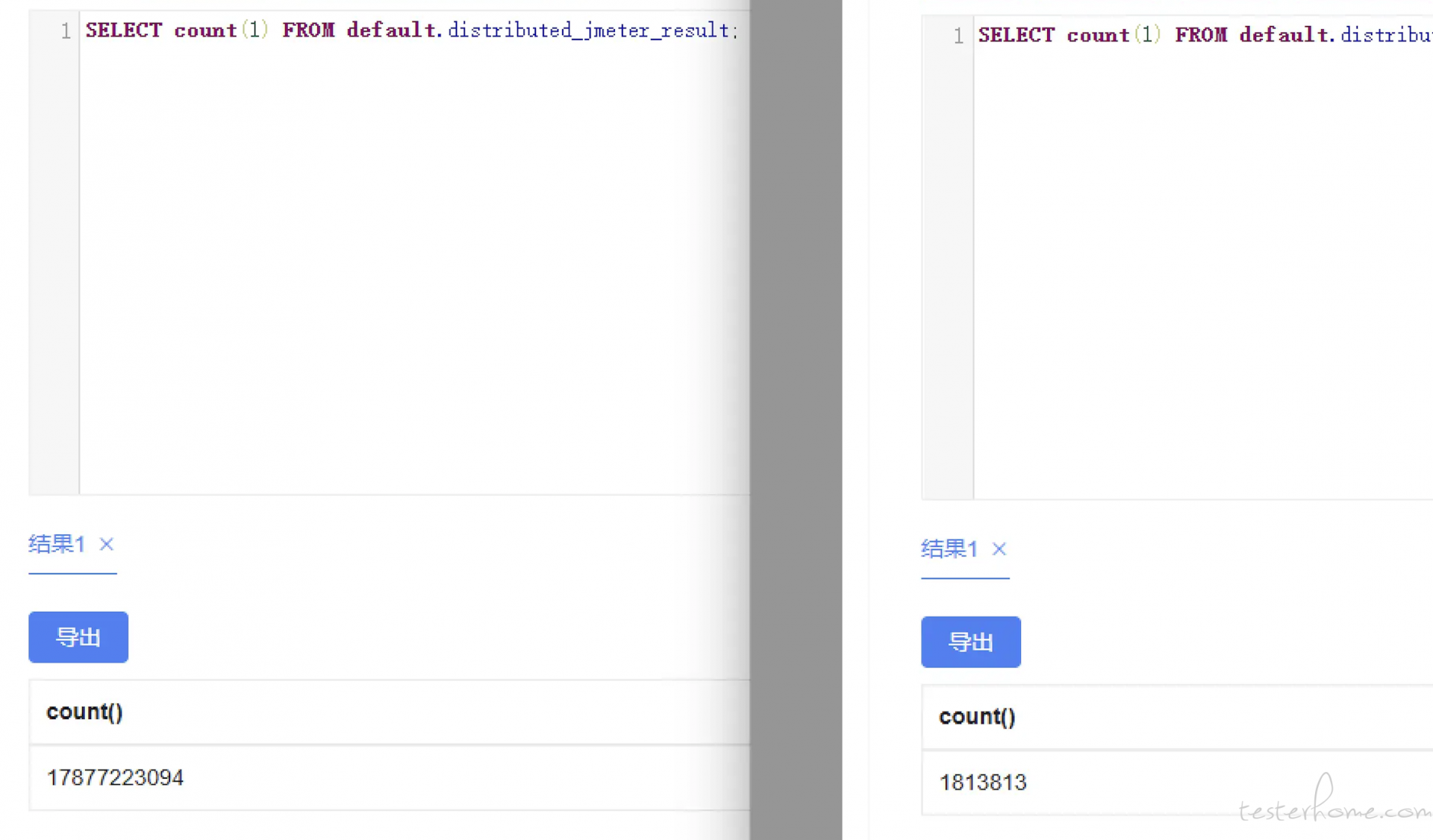
成果
通过数据转存与聚合,本项目成功地将原有的 178 亿条数据压缩至 181 万条,显著改善了系统性能和资源利用情况。具体成果如下:
- 查询效率显著提升
数据聚合后,查询的响应速度提高了数倍。由于数据量的减少,系统可以更快速地定位所需信息,查询平均响应时间从原来的数秒缩短至毫秒级别,为用户提供了更流畅的体验。这一提升在高频查询场景下尤为明显,减轻了服务器的查询负担,使系统在高峰期也能保持稳定的性能。
存储成本降低
聚合数据后的存储需求大幅下降,原本需要高存储容量的 178 亿条记录被压缩为 181 万条,大大减少了对存储空间的需求。这一变化带来了显著的成本节省,不仅降低了存储硬件的开销,还减少了备份、传输和维护数据的时间和成本。
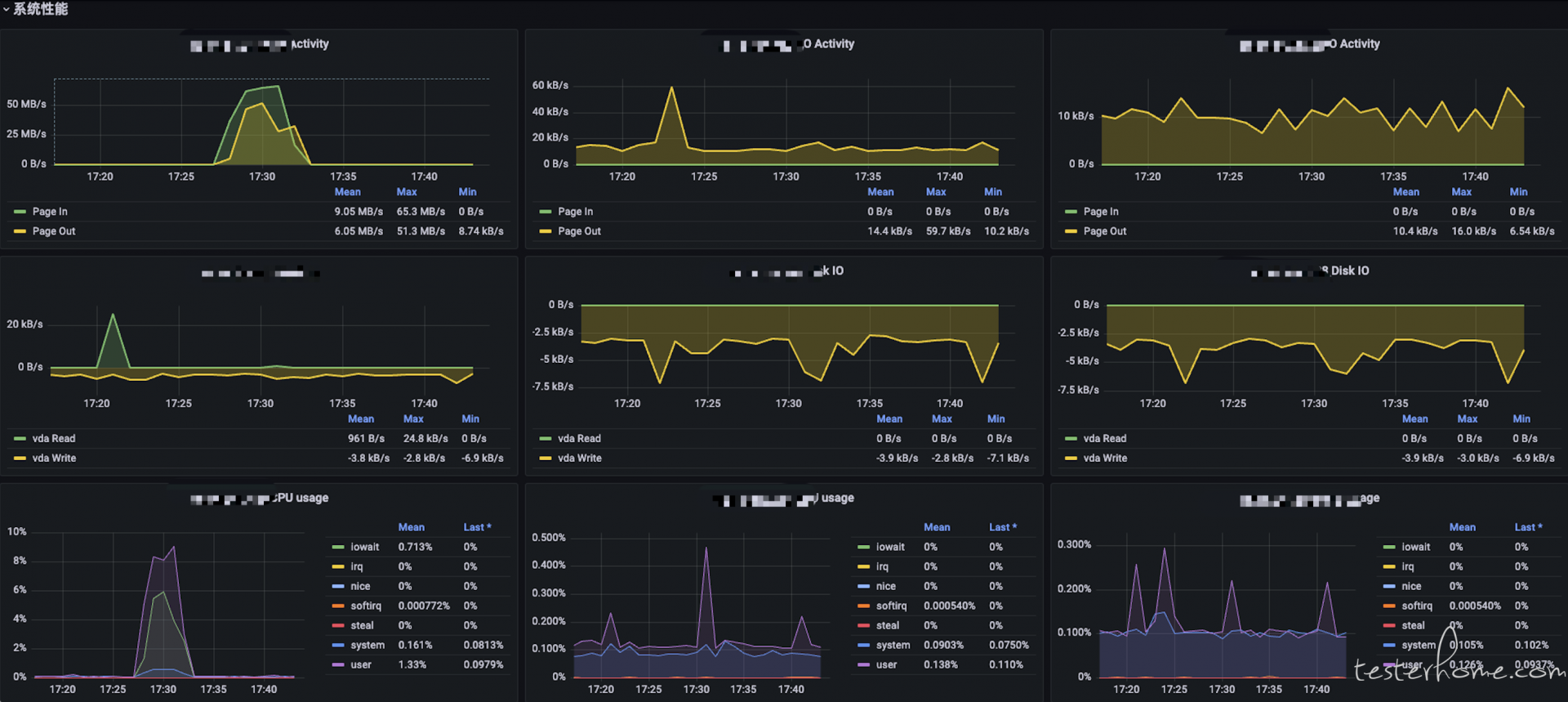
系统资源优化
数据量减少后,CPU 和内存的占用也显著降低,系统资源得到了更加高效的利用。由于减少了处理冗余数据的负担,服务器的整体性能得到提升,可以处理更多并发任务。此外,这种资源优化还延长了系统硬件的使用寿命,进一步节约了成本。
可扩展性提升
通过数据聚合,系统的可扩展性得到提升。在数据规模更大、数据增长更快的情况下,聚合策略能确保系统性能稳定,帮助应对未来的数据扩展需求,为系统长远发展奠定了基础。
