OOM 是非常常见的一类性能问题,发生的概率大,还无法避免。测试人员应该要熟练掌握这类问题的排查,刚好最近线上也出现了类似的问题,就做个简单的小结记录下。
01
对线上容器进行常规的监控,发现某个业务运行的 6 个实例,最多的时候可以一周有 2-3 天都会出现 OOM,且一天最多出现 3-4 次的 OOM。好在线上监控做的比较好,在出现 OOM 之后,会自动生成 dump 文件并保存,之后 jvm 进程终止。
容器平台的健康检查,监控到服务异常后,会销毁异常的运行实例,并重新拉起健康的运行实例,即相当于重启服务,只不过是销毁掉原来的容器的实例,重新拉起一个。
排查过程:
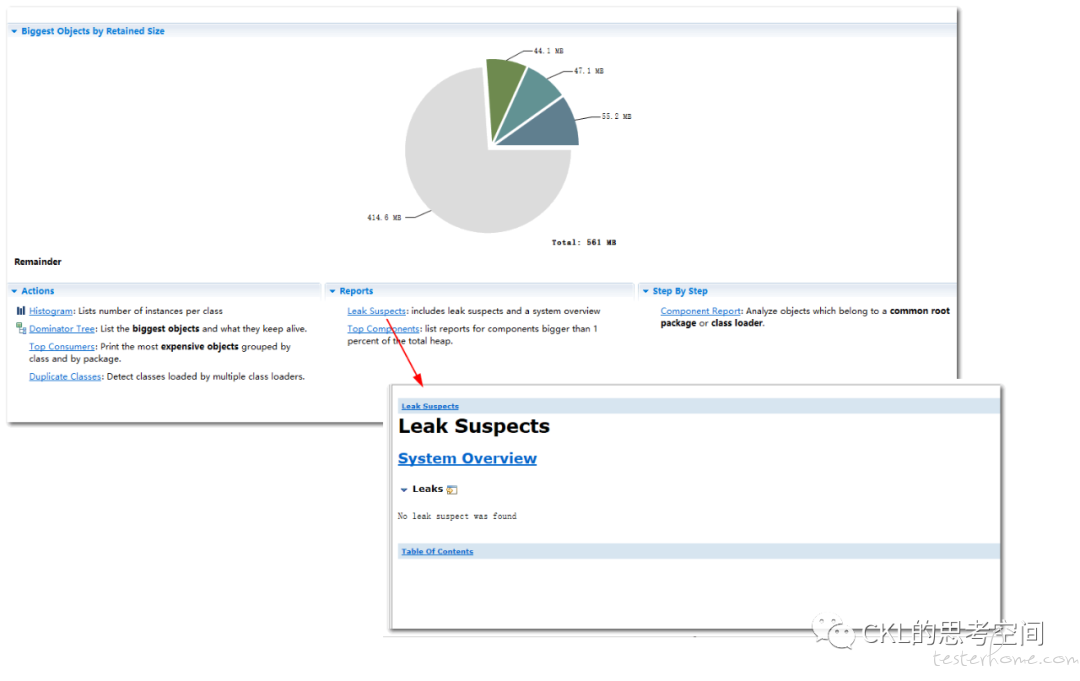
拿到 dump 文件之后,使用 MAT 工具进行分析,在 MAT 的 Leak Suspects,也就是造成内存溢出的,可能的内存泄漏原因,预测时,无法给出明确的预测得到的原因。
进一步分析,可以看到,OOM 报错,有明确的线程报错信息,可以看到,这是一个定时任务,相关的业务处理的线程。也就是说,最终造成 OOM 的,是这个线程。堆栈信息如下:
at com.tcl.tof.settlement.service.domain.rechargeOrder.RechargeOrderDomainService.lambda$writePaymentCollectionInfo$17(RechargeOrderDomainService.java:2122)
Local Variable: com.tcl.tof.settlement.service.domain.paymentCollection.entity.PaymentCollectionInfo#1
at com.tcl.tof.settlement.service.domain.rechargeOrder.RechargeOrderDomainService$$Lambda$4019.accept(<unknown string>)
at java.util.ArrayList.forEach(ArrayList.java:1259)
Local Variable: java.lang.Object[]#652058
Local Variable: com.tcl.tof.settlement.service.domain.rechargeOrder.RechargeOrderDomainService$$Lambda$4019#1
at com.tcl.tof.settlement.service.domain.rechargeOrder.RechargeOrderDomainService.writePaymentCollectionInfo(RechargeOrderDomainService.java:2094)
Local Variable: com.tingyun.agent.tracers.DefaultTracer#2907
Local Variable: java.util.ArrayList#667531
Local Variable: java.util.ArrayList#667530
at com.tcl.tof.settlement.service.domain.rechargeOrder.RechargeOrderDomainService.writePaymentCollection(RechargeOrderDomainService.java:725)
Local Variable: com.tcl.tof.settlement.service.domain.paymentCollection.entity.ClaimToPaymentCollectionVO#1
Local Variable: java.util.ArrayList#667528
Local Variable: com.tingyun.agent.tracers.DefaultTracer#2906
at com.tcl.tof.settlement.service.domain.rechargeOrder.RechargeOrderDomainService.createVerifyBill(RechargeOrderDomainService.java:506)
定位到业务代码后,查看对应的代码,是一个业务操作的对象 new 操作中的代码,对应的这一行是:
dto.setDate((new SimpleDateFormat("YYYY-MM-DD")).format(date));
网上查看相关信息后,了解到 SimpleDateFormat 是线程不安全的,如果是共享操作,则可能在并发环境下,造成一些问题,但是这个代码,是在类的某个方法中,每次都是 new,并不存在共享的问题。
这个线索,可能,可以进一步发掘,并得到问题的原因。但是在此处,线索中断了。
注:以上步骤是常规的堆内 OOM 分析方法:找报错日志 - 查看线程方法 - 定位代码分析可能的原因。基本上很快就能搞定了。
02
在多次观察 dump 文件,现一个比较明显的特点:线上环境的运行内存是 6G,JVM 参数也设置了,理论上可以用到 6G,但是每次 dump 的文件大小,均只有 1G 左右,且 dumo 文件中,显示的对象的大小,也只有 600M 左右,远远小于 6G。
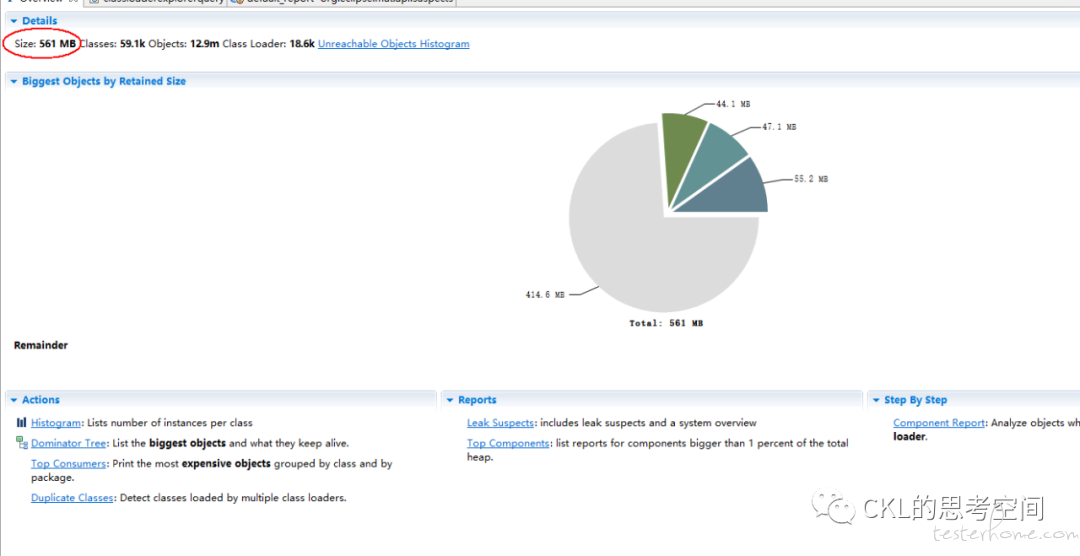
于是,带着这个疑问,进一步分析,结合 dump 情况的一些日志,一开始这些日志并没有拿到,且没有重视这块,一直在分析 dump 文件,在日志中发现了 “Metaspace OOM” 的提示
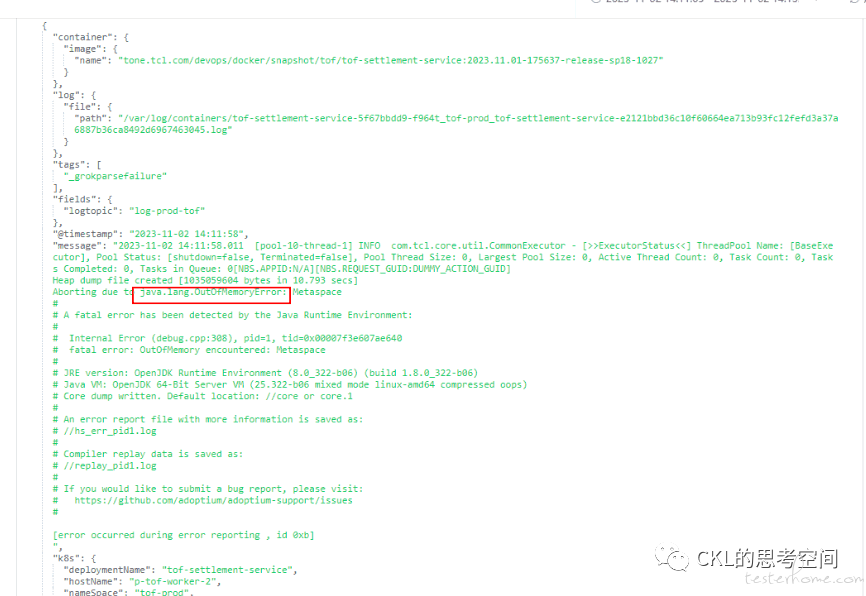
这就比较明显了,原来是 Metaspace(元空间,Metaspace,是 Java 虚拟机用于存储类和元数据的内存区域)的问题。直接在生产环境,查看正常运行(此时还没发生 OOM)情况下的 Metaspace 的使用情况,假设 jvm 进程的 pid 为 1。
/ # jstat -gcutil 1 | awk '{print($5)}'
M
91.59
/ #
上面的命令,是打印了当前 Metaspace 的使用率,可以看到,在服务正常运行的情况下,Metaspace 的使用率在 90% 以上,的确是使用了较多的元数据空间。
进一步,在 DEV 环境,重新发布应用,在应用刚开始运行的时刻,就用上述命令,打印 Metaspace 的使用情况,发现也是使用接近 90%。
那么,上述的分析,可以确定,发生了这么多次的 OOM,很可能大部分情况都是 Metaspace OOM。
正是因为 OOM 是 Metaspace OOM,所以每次 dump 的内存镜像文件,其文件大小,以及其中所显示的对象占用的内存大小,才远远小于 JVM 可用的内存容量。
03
好了,问题基本上定位到了。再深入分析下根因吧。
Metaspace 不足,那么说明加载的 class 类过多,每一个 class 类,由对应的 classloader 加载到 jvm 中时,都会占用 Metaspace。注意一个 class,即使会 new 多个对象实例,并不会再增加 Metaspace 的使用。new 的对象实例,占用的是 heap space 堆空间。
虽然 Metaspace 加载了较多的对象,使用的较多,但是若能够及时的进行内存回收,释放空间,也不会导致 OOM。
使用 MAT 工具,查看 classloader 的具体的信息:
可以看到,有非常多的,sun.reflect.DelegatingClassLoader 的 classloader 的对象实例。
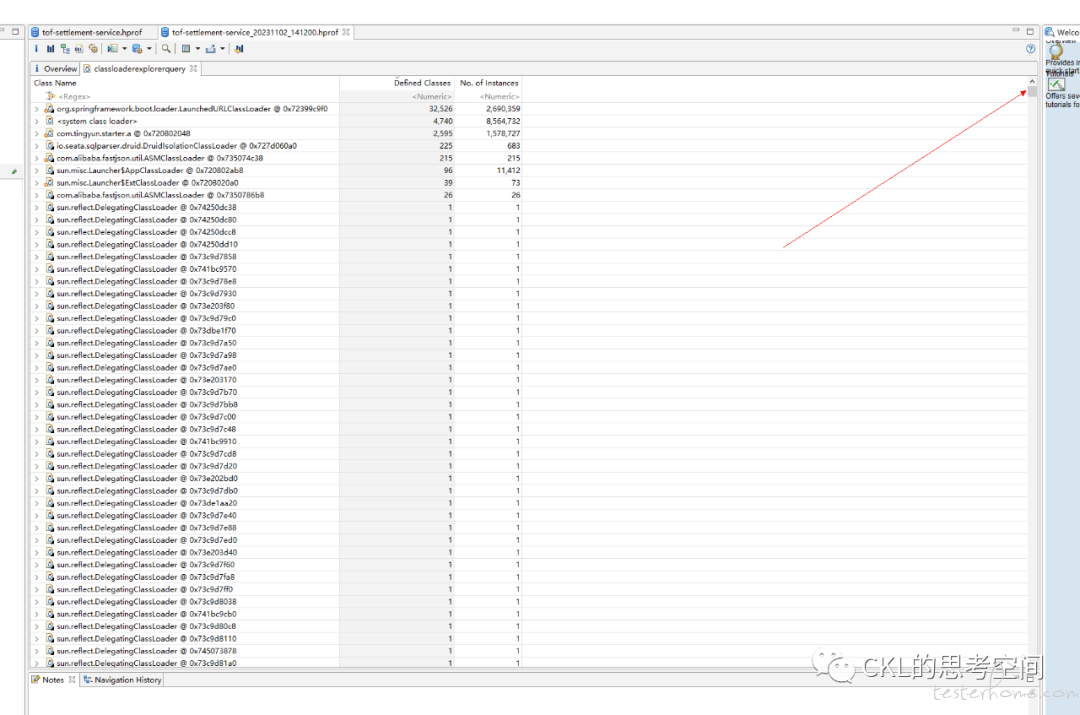
结合前面得到的结论,发生 OOM 的情况,大部分是定时任务运行触发的,在定时任务拉起处理线程,进行业务处理时,存在大量使用了反射的情况,因此产生了较多的 classloader,且这种反射所加载的对象,没办法重用 classloader,所有 classloader 的数量也很庞大。
进一步分析,在 MAT 中,查看某一个 classloader 所引用的对象的引用树,操作如下图
引用树显示结果,如下图
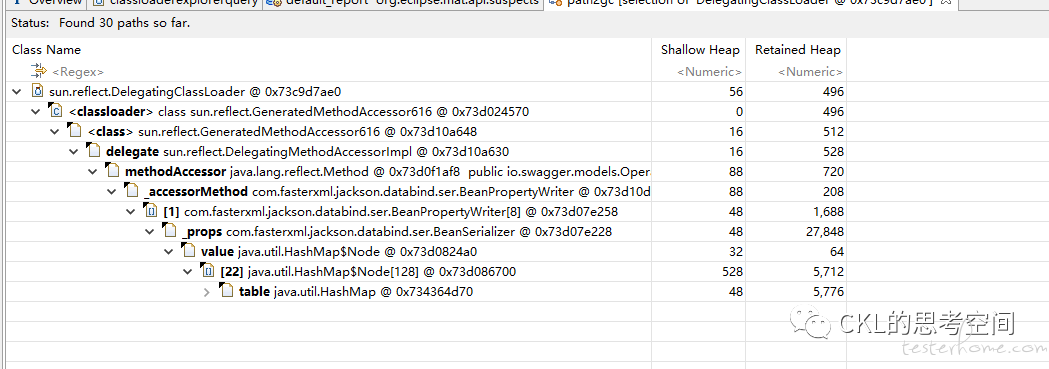
随机点开一些 classloader,查看其引用树,还有一些是 json 序列化相关的,这里其实底层也是用到了反射。关于反射,导致的 OOM 问题,网上有一篇文章,提到了如下内容:
当使用 JavaBean 的内省时,使用 Introspector,jdk 会自动缓存内省信息(BeanInfo),这一点是可以理解的,毕竟内省通过反射的代价是高昂的。当 ClassLoader 关闭时,Introspector 的缓存持有 BeanInfo 的信息,而 BeanInfo 持有 Class 的强引用,这会导致 ClassLoader 和它引用的 Class 等对象不能被回收。
简单点说,就是在反射处理时,为了优化性能,会使用缓存。但是这会带来副作用,有可能会导致 OOM,原因是:当 ClassLoader 使用完关闭时,缓存仍然持有 Class 的强引用,这会导致 ClassLoader 和它引用的 Class 等对象不能被回收。
那么,到目前为止,OOM 的原因基本上清楚了。
总结如下:
因为很多代码处理逻辑的底层,使用了反射(包括上面提到的 spring 的 BeanUtils 的拷贝对象,json 的序列化),而反射在大量使用时,因为使用了缓存的原因,导致 ClassLoader 和它引用的 Class 等对象不能被回收,进一步导致了元数据空间 Metaspace 被使用完,在总的已使用内存,远小于 JVM 的总的可用内存的情况下,发生了 Metaspace 的 OOM。
解决方案也比较简单:优化业务处理逻辑,避免瞬间的业务处理量急剧增加(这里除了数据量的因素,还需要考虑业务处理逻辑的的性能消耗的维度),或者才有简单直接的方法—减少每次处理的数据量,分多次处理 ,同时减少代码中,使用反射的情况,或者对反射进行优化。
注:这类问题比较少见,需要注意观察日志的报错信息,确定是哪部分的内存不够用。
04
在笔者接触过的 OOM 中,还有一类是堆外内存 OOM,大致的现象是:内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。
在排查 OOM 的过程中,需要增加 GC 日志打印、OOM 自动 dump 等配置内容,帮助进行问题排查,在 Out Of Memory,JVM 快死掉的时候,输出 Heap Dump 到指定文件。不然开发很多时候还真不知道怎么重现错误。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=${LOGDIR}/
附常见 JVM 查看命令和工具:
jps:JVM Process Status Tool 进程状况工具
jstat:JVM Statistics M onitoring Tool 统计信息监视工具
jinfo:Configuration Info for Java Java 配置信息工具
jmap:Memory Map for Java 内存映像工具
jhat:JVM Heap Analysis Tool 堆转储快照分析工具
jstack:Stack Trace for Java 堆栈跟踪工具
MAT:Memory Analyse Toll
共勉。