前言
传统的跨地域多集群通信方案,一般都是购买对等连接服务,配置相应的路由表跳转规则,即可实现跨地域多集群的通信方案。
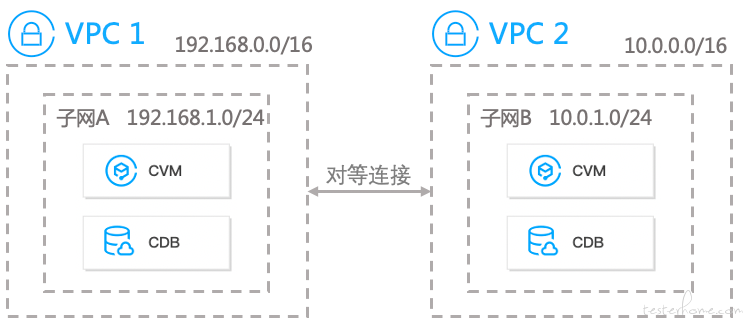
但是对等连接是有它自己的限制:
- 流量计费成本高
- 对等连接数存在限制
- 跨地域带宽存在上限
- 本端和对端都要配置相关路由,不能单向访问
所以我其实是想设计一套跨地域多集群的通信方案,跨地域的带宽跟流量计费可以保持跟 CVM 一样,量大便宜,流量转发性能损耗低。
不仅如此,它还可以搞很多的骚操作。
比如我们的压测业务,在不同的地域,有不同的发压主集群,这些集群可以双向通信,保持数据的双向同步。
比如我们支持用户自己上传 K8S 公有集群作为发压从集群,且可以限制单向访问确保安全,即仅主集群能访问接入从集群,而从集群无法访问主集群。
比如我们所有的跨集群流量,都经过特有证书 TLS 的安全校验,会定期滚动更新证书,自行维护每个集群的生命周期,可随时回收吊销每个集群的通信权限。
因此,这里想分享一下我这套方案是如何落地到压测业务中,利用云原生实现降本增效。
如果你也想要一套低成本高性能的跨地域多集群通信方案落地到业务中,这篇文章或许对你有帮助。
Istio
也许你已经猜到,想要实现这种跨地域流量的灵活转发和监控,核心就是实现一个 Sidecar,并辅以各类网络规则插件,最后通过统一的管理中心实现治理。
这不是就是 Service Mesh 吗?
刚好,每个地域的集群,其实就可以看成是不同的网格,而我们想要的,就是打通这些网格,实现服务的治理。
Istio 便是 Service Mesh 里面的佼佼者,同领域内的还有 Linkerd 这样的框架。
而我选择 Istio 的原因主要有以下几点:
- 在早期调研的时候,Linkerd 多集群部署功能仍处于实验阶段,而 Istio 已经可以通过各种配置实现多集群网格的扩展。
- Istio 支持流量熔断,流量转移,故障注入,延迟注入等等,有良好的流量管控和混沌工程演练的能力,而 Linkerd 无熔断、无延迟注入支持。
- Cert-Manager 提供了 Istio-csr 组件与 Istio 做集成,可以便捷地处理 Istio 网格所有服务的证书签名更新。
下面来看下 Istio 架构图:
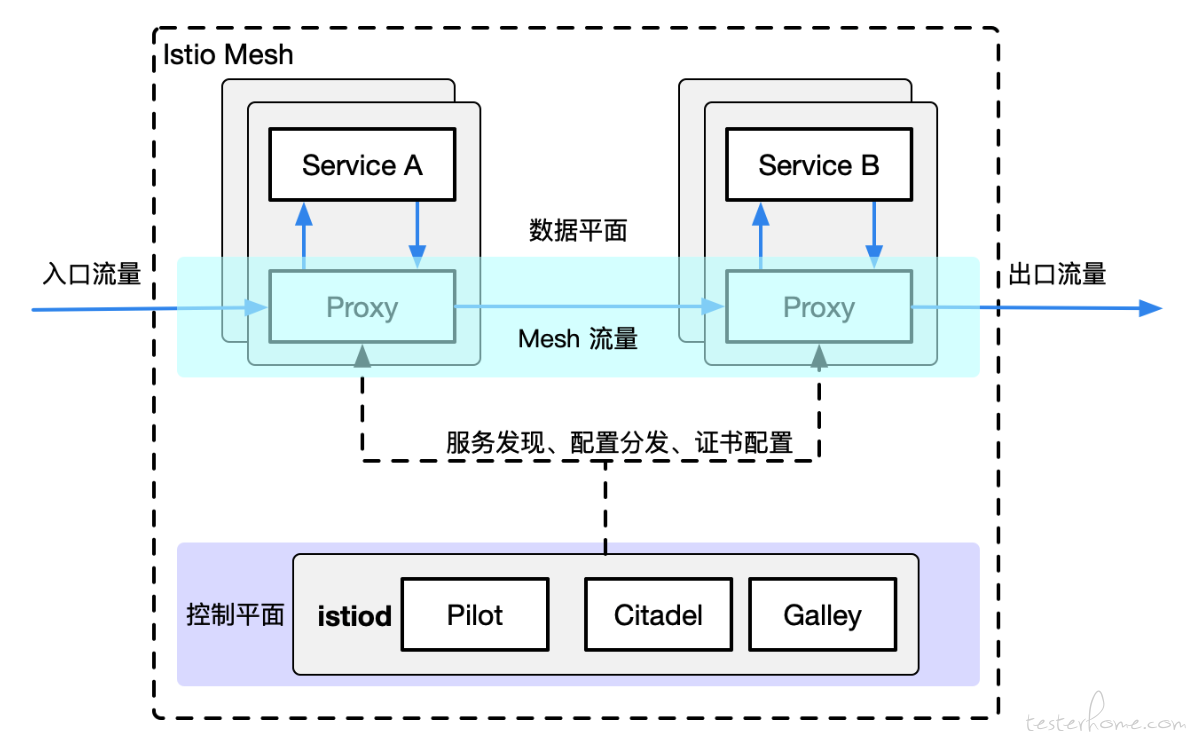
可以看到,Istio 会给每个服务 Pod 内置一个 Sidecar Container,负责管控整个 Service Mesh 流量的出入 Proxy。
这个 Proxy 就是以 C++ 开发的高性能流量代理插件 Envoy,支持负载均衡,健康检查,熔断器,故障注入等特性,属于数据平面。
而 Istiod 则是控制平面,负责管理和配置代理路由的流量,服务发现,以及证书签证管理。
所以,Istio 就是由数据平面和控制平面整合而成的服务网格,专注于对流量出入的掌控。
而当需要跨集群流量访问的时候,就需要用到 Istio 的 Eastwest Gateway。
Eastwest Gateway 作为跨集群边界的服务负载,能够根据集群网格的标识(DestinationRule)以及对应的路由转发(VirtualService),找到真正下游的服务。
Istio 提供了两种方式的跨网格架构。
- 主从架构
- 多主架构
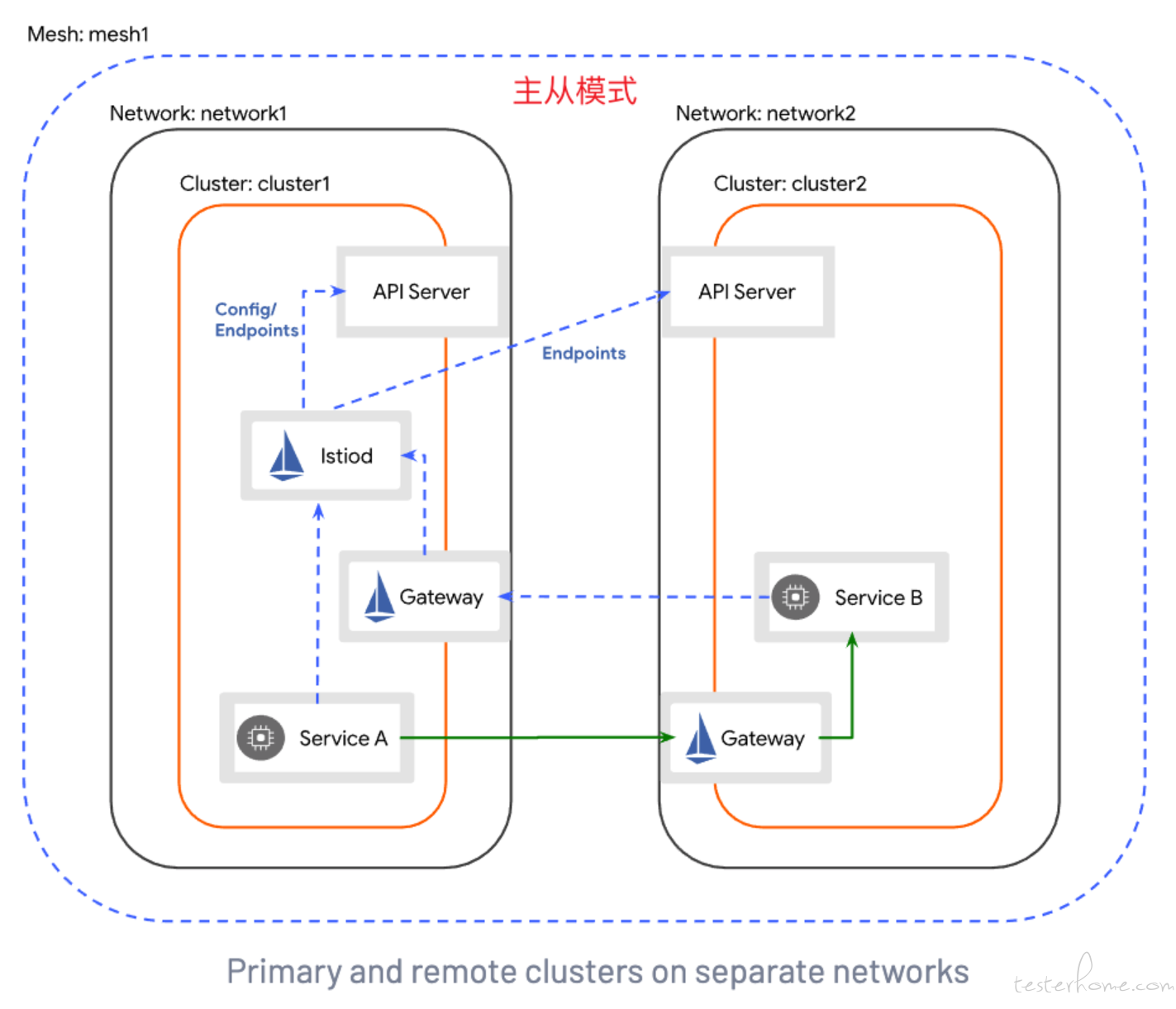
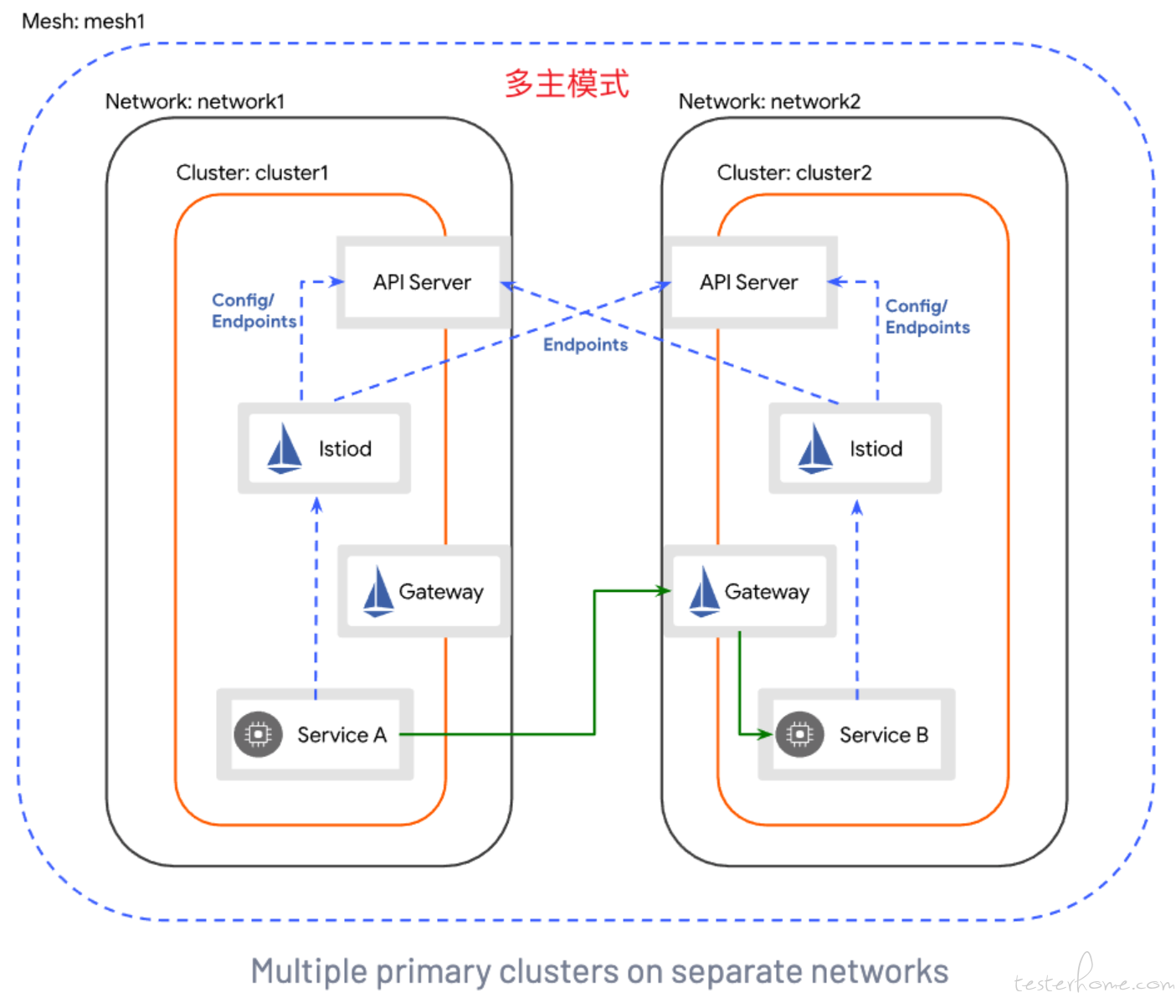
两者的区别主要在两点:
- 通信方式的不同,主从架构,只能主访问从,从不能访问主,而多主是可以相互访问。
- 证书安装的不同,主从同享一份根证书 Root CA,而多主不会共享彼此之间的 CA 证书,需要由根证书签证出中间证书进行校验。
然而很多时候,我们的业务场景更想要的是,主从的通信方式以及多主的证书安装。
因为主从的通信方式,能够保证主集群的安全性,而不同的证书,能够保证吊销了从集群证书之后,不会影响主集群的证书,从而就可以很方便断开主从之间的联系。
所以这里需要解决通信方式和证书鉴权两大问题。
自鉴权的 CA 签发
先解决证书问题。
鉴于 Cert-manager 有 Istio-csr 的插件,且可以接入 Vault,决定基于这套方案来完成 CA 滚动更新。
vault 高可用模式部署
- 先部署存储 Consul
helm repo add hashicorp https://helm.releases.hashicorp.com
helm search repo hashicorp/consul
helm install consul hashicorp/consul --set global.name=consul --create-namespace -n consul
- 再部署 Vault
编写 vault-config.yaml
global:
enabled: true
tlsDisable: true
server:
ha:
enabled: true
config: |
ui = false
listener "tcp" {
address = "[::]:8200"
cluster_address = "[::]:8201"
tls_disable = 1
}
storage "consul" {
path = "vault"
address = "http://consul.consul:8500"
}
service_registration "kubernetes" {}
使用高可用模式部署 Vault 集群:
helm install -n vault vault hashicorp/vault --values vault-config.yaml
Consul 存储的不稳定
虽然 Consul 作为 Cault 官方推荐的存储之一,也同属 Hashicorp 组织来维护,但是我在稳定性测试的过程中,经常发现由于一些 revoke expired auth/ca/xxx 的失败异常,导致 Consul 集群挂了,或者 Vault 集群由于 Consul 集群不稳定导致 Vault 集群重启了。
Vault 集群只要一重启,就会进入 seal 状态,且由于腾讯云不具备 auto unseal 的基建,需要手动 unseal 是一个非常麻烦且影响业务的举动。
一旦 CA 证书的滚动更新遇上了 Vault 的 seal 状态,就会导致更新失败,从而导致 pod 也会进入异常状态,无法提供对外服务。
手动写个 auto seal 进程服务在 Vault 集群定时去检测 vault status 是一个兜底方法,但是存储的稳定性也需要提高。
最后我选择了 Postgresql 作为 Vault 的存储后端,并进行了稳定性测试,大大降低了 Vault 集群重启的概率。
storage "postgresql" {
connection_url = "postgres://name:pwd@host:5432/vault?sslmode=disable"
table = "vault_pki_store"
ha_enabled = "true"
ha_table = "vault_ha_locks"
}
注意,由于 Vault 不会初始化 Postgresql,所以需要自己去初始化相关表结构。
CREATE TABLE vault_pki_store (
parent_path TEXT COLLATE "C" NOT NULL,
path TEXT COLLATE "C",
key TEXT COLLATE "C",
value BYTEA,
CONSTRAINT pkey PRIMARY KEY (path, key)
);
CREATE INDEX parent_path_idx ON vault_pki_store (parent_path);
CREATE TABLE vault_ha_locks (
ha_key TEXT COLLATE "C" NOT NULL,
ha_identity TEXT COLLATE "C" NOT NULL,
ha_value TEXT COLLATE "C",
valid_until TIMESTAMP WITH TIME ZONE NOT NULL,
CONSTRAINT ha_key PRIMARY KEY (ha_key)
);
Https 协议升级
Vault 集群需要对外暴露,接受所有从集群的请求,所以需要把 Vault 升级成 Https 协议。
对此,我需要生成一个属于 Vault 的根证书,并利用 k8s csr 签发证书。
openssl genrsa -out vault.key 2048 -days 3650
openssl req -new -key vault.key -subj "/CN=vault-tls.vault.svc" -days 3650 -out vault.csr -config csr.conf
CSR=$(cat < vault.csr | base64 | tr -d '\n')
cat <<EOF | kubectl -n vault apply -f -
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
name: vault-csr
spec:
groups:
- system:authenticated
request: ${CSR}
usages:
- digital signature
- key encipherment
- server auth
EOF
kubectl certificate approve vault-csr
serverCert=$(kubectl get csr vault-csr -o jsonpath='{.status.certificate}')
echo "${serverCert}" | openssl base64 -d -A -out vault.crt
openssl x509 -enddate -noout -in vault.crt
kubectl config view --raw --minify --flatten -o jsonpath='{.clusters[].cluster.certificate-authority-data}' | base64 -d > vault.ca
kubectl create secret generic vault-tls \
--namespace vault \
--from-file=vault.key=./vault.key \
--from-file=vault.crt=./vault.crt \
--from-file=vault.ca=./vault.ca
注意,由于 k8s csr 本身的机制,CA 有效期为 1 年,需要定期去更新 vault-tls,这块的功能最好跟之前提到的 auto-unseal 做在一块,补全 Vault 的基础建设。
最后是编写新的 Config 覆盖 Vault 的安装,以下是我编写的 Config,成功升级成 Https 协议。
global:
enabled: true
tlsDisable: false
server:
extraEnvironmentVars:
VAULT_CACERT: /vault/userconfig/vault-tls/vault.ca
VAULT_TLSCERT: /vault/userconfig/vault-tls/vault.crt
VAULT_TLSKEY: /vault/userconfig/vault-tls/vault.key
extraVolumes:
- type: secret
name: vault-tls
ha:
enabled: true
config: |
ui = false
listener "tcp" {
address = "[::]:8200"
cluster_address = "[::]:8201"
tls_disable = 0
tls_cert_file = "/vault/userconfig/vault-tls/vault.crt"
tls_key_file = "/vault/userconfig/vault-tls/vault.key"
tls_client_ca_file = "/vault/userconfig/vault-tls/vault.ca"
}
storage "postgresql" {
connection_url = "postgres://name:pwd@host:5432/vault?sslmode=disable"
table = "vault_pki_store"
ha_enabled = "true"
ha_table = "vault_ha_locks"
}
service_registration "kubernetes" {}
ui:
enabled: false
serviceType: "LoadBalancer"
serviceNodePort: 30082
externalPort: 443
annotations: |
service.kubernetes.io/existed-lbid: lb-xxx
使用 K8S 鉴权连接外部 Vault
Vault 连接模式里面,是支持 K8S 的集群鉴权,正好契合外接集群的需求。
这个过程非常繁琐复杂,为了便于复用和理解,我写了 Shell 脚本来归纳连接过程。
- 先鉴权并连上 Vault 集群
cat <<EOF | kubectl -n default apply -f -
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: vault-auth
---
apiVersion: v1
kind: Secret
metadata:
name: vault-auth
annotations:
kubernetes.io/service-account.name: vault-auth
type: kubernetes.io/service-account-token
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: role-tokenreview-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: vault-auth
namespace: default
EOF
vault auth enable --path=${NAME} kubernetes
TOKEN_REVIEW_JWT=$(kubectl -n default get secret vault-auth -o go-template='{{ .data.token }}' | base64 --decode)
KUBE_CA_CERT=$(kubectl config view --raw --minify --flatten -o jsonpath='{.clusters[].cluster.certificate-authority-data}' | base64 --decode)
KUBE_HOST=$(kubectl config view --raw --minify --flatten -o jsonpath='{.clusters[].cluster.server}')
vault write auth/${NAME}/config \
token_reviewer_jwt="${TOKEN_REVIEW_JWT}" \
kubernetes_host="${KUBE_HOST}" \
kubernetes_ca_cert="${KUBE_CA_CERT}"
vault write auth/${NAME}/role/issuer-istio-ca \
bound_service_account_names=vault-issuer \
bound_service_account_namespaces=istio-system \
policies=${NAME} \
ttl=72h
vault secrets enable -path=${NAME} pki
vault secrets tune -max-lease-ttl=43800h ${NAME}
vault write -format=json ${NAME}/intermediate/generate/internal \
common_name="${NAME}" \
| jq -r '.data.csr' > ${NAME}.csr
vault write -format=json pki/root/sign-intermediate csr=@${NAME}.csr \
format=pem ttl="43800h" \
| jq -r '.data.certificate' > ${NAME}.cert.pem
cat ${NAME}.cert.pem > ${NAME}.chain.pem
cat CA_cert.crt >> ${NAME}.chain.pem
vault write ${NAME}/intermediate/set-signed certificate=@${NAME}.chain.pem
vault write ${NAME}/roles/istio-ca \
allowed_domains=istio-ca \
allow_any_name=true \
enforce_hostnames=false \
require_cn=false \
allowed_uri_sans="spiffe://*" \
max_ttl=72h
vault policy write ${NAME} - <<EOF
path "${NAME}*" { capabilities = ["read", "list"] }
path "${NAME}/roles/istio-ca" { capabilities = ["create", "update"] }
path "${NAME}/sign/istio-ca" { capabilities = ["create", "update"] }
path "${NAME}/issue/istio-ca" { capabilities = ["create"] }
EOF
vault write ${NAME}/tidy \
tidy_cert_store=true \
tidy_revoked_certs=true \
safety_buffer=72h
- 再使用
cert-manager和cert-manage-istio-csr签发 CA
kubectl create ns istio-system
kubectl label ns istio-system topology.istio.io/network=${NAME}
kubectl create ns cert-manager
helm install -n cert-manager cert-manager jetstack/cert-manager \
--version v1.6.0 \
--set installCRDs=true
kubectl -n istio-system create serviceaccount vault-issuer
ISSUER_SECRET_REF=$(kubectl -n istio-system get serviceaccount vault-issuer -o json | jq -r ".secrets[].name")
CABundle=$(cat < vault.ca | base64 | tr -d '\n')
cat <<EOF | kubectl -n istio-system apply -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: vault-istio-ca-issuer
namespace: istio-system
spec:
vault:
server: ${VAULT_SERVICE_URL}
caBundle: ${CABundle}
path: ${NAME}/sign/istio-ca
auth:
kubernetes:
mountPath: /v1/auth/${NAME}
role: issuer-istio-ca
secretRef:
name: ${ISSUER_SECRET_REF}
key: token
EOF
for i in {1..10}
do
if [ $i == 10 ]; then exit 0; fi
READY=$(kubectl -n istio-system get issuers -o wide | awk '$2=="True" {print $2}')
if [ "${READY}" != "True" ]; then sleep 2s; else break; fi
done
kubectl -n istio-system get issuer -o wide
helm install -n cert-manager cert-manager-istio-csr jetstack/cert-manager-istio-csr \
--version v0.3.0 \
--set app.certmanager.issuer.name=vault-istio-ca-issuer \
--set app.certmanager.issuer.kind=Issuer \
--set app.certmanager.namespace=istio-system \
--set app.certmanager.preserveCertificateRequests=true \
--set app.logLevel=3 \
--set app.server.clusterID=${NAME}
for i in {1..10}
do
if [ $i == 10 ]; then exit 0; fi
READY=$(kubectl -n istio-system get certificate -o wide | awk '$2=="True" {print $2}')
if [ "${READY}" != "True" ]; then sleep 2s; else break; fi
done
kubectl -n istio-system get certificate -o wide
最终,vault-istio-ca-issuer 会把 istiod-tls 注入到 istio-system 作为 istio 的 CA 证书。
自定义的多主从模式
再解决通信问题。
经排查,多主之间可以相互通信,主要在于 Istio 会在两主之间写入各自的 API Server Access 的权限。
所以,如果我们在多主的安装模式中,实现主集群安装从集群 API Server Access 而从集群跳过此步骤,不就回归主从的通信方式了吗?
这里我设计了一个新的模式,多主从模式,架构如下。
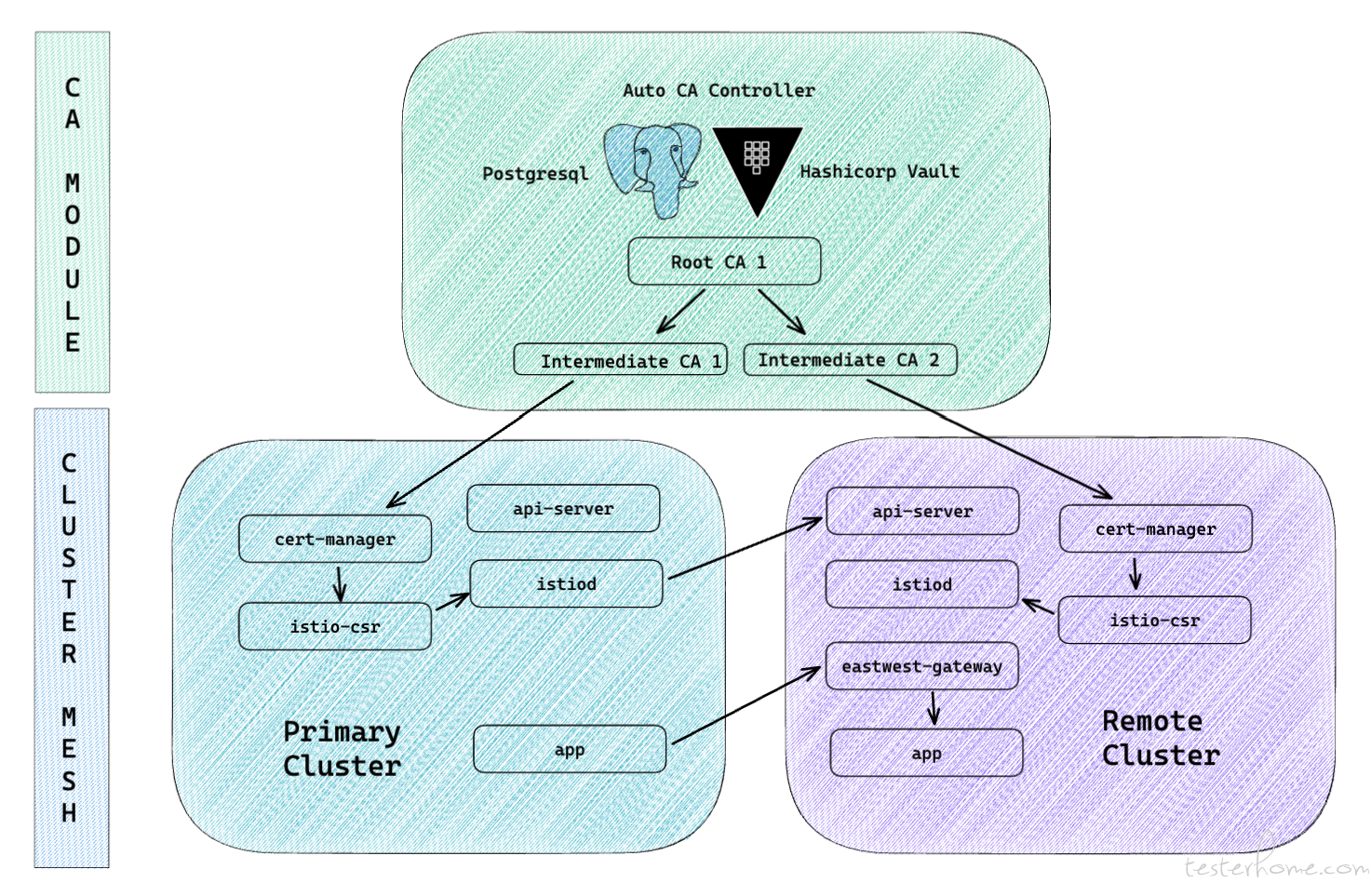
# 在主集群上配置子集群的 api-server secret
istioctl x create-remote-secret \
--context="${NAME}" \
--name="${NAME}" | \
kubectl apply -f - --context="${MASTER_NAME}"
# 从集群创建 istio-system 命名空间,在 master node 安装 istiod,配置证书服务为 cert-manager,并确认应用部署正常
cat <<EOF | istioctl install -y --context="${NAME}" -f -
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
metadata:
namespace: istio-system
spec:
profile: "default"
revision: ""
values:
global:
# Change certificate provider to cert-manager istio agent for istio agent
caAddress: cert-manager-istio-csr.cert-manager.svc:443
meshID: ${MESH}
multiCluster:
clusterName: ${NAME}
network: ${NAME}
components:
ingressGateways:
- name: istio-ingressgateway
enabled: false
pilot:
k8s:
env:
# Disable istiod CA Sever functionality
- name: ENABLE_CA_SERVER
value: "false"
overlays:
- apiVersion: apps/v1
kind: Deployment
name: istiod
patches:
# Mount istiod serving and webhook certificate from Secret mount
- path: spec.template.spec.containers.[name:discovery].args[-1]
value: "--tlsCertFile=/etc/cert-manager/tls/tls.crt"
- path: spec.template.spec.containers.[name:discovery].args[-1]
value: "--tlsKeyFile=/etc/cert-manager/tls/tls.key"
- path: spec.template.spec.containers.[name:discovery].args[-1]
value: "--caCertFile=/etc/cert-manager/ca/root-cert.pem"
- path: spec.template.spec.containers.[name:discovery].volumeMounts[-1]
value:
name: cert-manager
mountPath: "/etc/cert-manager/tls"
readOnly: true
- path: spec.template.spec.containers.[name:discovery].volumeMounts[-1]
value:
name: ca-root-cert
mountPath: "/etc/cert-manager/ca"
readOnly: true
- path: spec.template.spec.volumes[-1]
value:
name: cert-manager
secret:
secretName: istiod-tls
- path: spec.template.spec.volumes[-1]
value:
name: ca-root-cert
configMap:
defaultMode: 420
name: istio-ca-root-cert
EOF
# 检查 istiod 的状态,如果 status 的值为 Running 则停止
for i in {1..5}
do
if [ $i == 5 ]; then exit 0; fi
status=$(kubectl -n istio-system --context="${NAME}" get pod | grep "istiod" | awk '$3=="Running" {print $3}')
if [ "${status}" != "Running" ]; then
sleep 2s
echo "Checking istiod pod status."
else
break
fi
done
echo "Check istiod pod status done."
kubectl -n istio-system --context="${NAME}" get pod
# 在从集群 master node 安装 eastwest-gateway,完成对主集群的远程连接,确认已正常连接上
cat <<EOF | istioctl install -y --context="${NAME}" -f -
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
metadata:
name: eastwest
spec:
profile: empty
components:
ingressGateways:
- name: istio-eastwestgateway
label:
istio: eastwestgateway
app: istio-eastwestgateway
topology.istio.io/network: ${NAME}
enabled: true
k8s:
env:
# sni-dnat adds the clusters required for AUTO_PASSTHROUGH mode
# This is not required in Istio 1.11+, but we add it just in case.
- name: ISTIO_META_ROUTER_MODE
value: "sni-dnat"
# traffic through this gateway should be routed inside the network
- name: ISTIO_META_REQUESTED_NETWORK_VIEW
value: ${NAME}
serviceAnnotations:
traffic.istio.io/nodeSelector: '{}'
service:
type: NodePort
externalTrafficPolicy: Cluster
ports:
- name: status-port
port: 15021
targetPort: 15021
nodePort: 30021
- name: tls
port: 15443
targetPort: 15443
nodePort: 30443
- name: tls-istiod
port: 15012
targetPort: 15012
nodePort: 30012
- name: tls-webhook
port: 15017
targetPort: 15017
nodePort: 30017
values:
gateways:
istio-ingressgateway:
injectionTemplate: gateway
global:
meshID: ${MESH}
network: ${NAME}
multiCluster:
clusterName: ${NAME}
EOF
cat <<EOF | kubectl --context="${NAME}" apply -n istio-system -f -
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"
EOF
# 检查 istio-eastwestgateway 的状态,如果 status 的值为 Running 则停止
for i in {1..5}
do
if [ $i == 5 ]; then exit 0; fi
status=$(kubectl -n istio-system --context="${NAME}" get pod | grep "istio-eastwestgateway" | awk '$3=="Running" {print $3}')
if [ "${status}" != "Running" ]; then
sleep 2s
echo "Checking istio-eastwestgateway pod status."
else
break
fi
done
echo "Check istio-eastwestgateway pod status done."
kubectl -n istio-system --context="${NAME}" get pod
细心的可以发现,这里的网关我只装了 Eastwest Gateway,把 Ingress Gateway 取消了,同时使用了 NodePort 的部署模式。
因为很多时候业务场景有自己所需的负载均衡,甚至还要接 WAF 或各种安全防护,使用 Ingress Gateway 限制性太强了。
所以取消掉 Ingress Gateway 沿用自己惯用的网关入口,不会与业务有任何冲突。
这里就不继续展开了。
如果这时,我们在两个集群,相同的 namespace 上部署相同的 app,并在主从集群请求这个 app,会发生什么效果?
- 主集群
curl helloworld.sample:5000/hello
## return hello-cluster-primary
curl helloworld.sample:5000/hello
## return hello-cluster-remote
curl helloworld.sample:5000/hello
## return hello-cluster-primary
curl helloworld.sample:5000/hello
## return hello-cluster-remote
- 从集群
curl helloworld.sample:5000/hello
## return hello-cluster-remote
curl helloworld.sample:5000/hello
## return hello-cluster-remote
curl helloworld.sample:5000/hello
## return hello-cluster-remote
curl helloworld.sample:5000/hello
## return hello-cluster-remote
可以看到,在主集群中访问,可以随机把流量负载均衡到两个集群,在从集群中访问,只能收到从集群的响应,验证了新设计的多主从模式的正确性。
但这也暴露出来了一个新的问题。
流量控制
流量的精准代理
在上面,我们已经成功把两个不同地域网络的集群连接了起来。
但是会发现,对于主集群来说,它访问的服务,会随机负载均衡转发到该服务所部署在的所有集群。
而有些时候,我们业务其实是想要精准的流量代理。
举个简单的例子,我每个集群都有个 Grafana & Influxdb,那么我在主集群访问 Grafana 的时候,我其实是希望能够准确找到用户是在哪个集群写入的数据,从而展示对应集群的 grafana 给用户。
而负载均衡是给不了我们想要的结果,这个时候就需要借助 Istio 的 VirtualService & DestinationRule 来实现跨集群流量的精准代理。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: helloworld-vs
namespace: sample
spec:
hosts:
- helloworld.sample.svc.cluster.local
http:
- match:
- uri:
prefix: /cluster1/
rewrite:
uri: /
route:
- destination:
host: helloworld.sample.svc.cluster.local
subset: cluster1
- match:
- uri:
prefix: /cluster2/
rewrite:
uri: /
route:
- destination:
host: helloworld.sample.svc.cluster.local
subset: cluster2
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: helloworld-dr
namespace: sample
spec:
host: helloworld.sample.svc.cluster.local
subsets:
- name: cluster1
labels:
topology.istio.io/network: cluster1
- name: cluster2
labels:
topology.istio.io/network: cluster2
以上是一个简单的例子,可以看到,helloworld 这个服务被部署在两个不同的集群。
首先 VirtualService 通过 prefix 找到集群路由的标识,通过 subset 指定了下游的方向。
然后 DestinationRule 会根据 subset 匹配 topology.istio.io/network 这个标签,确定下游服务所在的网格。
这样,我们便可以通过以下的请求方式,实现指定集群的服务访问。
curl helloworld.sample:5000/cluster1/hello
## return hello-cluster1
curl helloworld.sample:5000/cluster2/hello
## return hello-cluster2
当我喜滋滋以为事情已经大功告成的时候,新的问题又来了。
流量代理的缺陷
在实际测试的过程中,主要遇到两个问题:
- Host 的解析异常
上面能够通过访问 svc 地址访问到两个集群的服务,前提是两个集群都要有相同的 Namespace,Service。
如果业务需要在主从环境部署不一样的 App,是无法直接跨集群提供 svc 访问的。
比如在 Cluster2 中创建了 sample1.helloworld,此时对于 Cluster1 来说,并不存在这个服务,也没有对于的 svc。
所以,这个时候如果从 Cluster1 去 curl sample1.helloworld:5000/hello,响应是 unresolve host sample1.helloworld。
这是因为对于 Cluster1 而言,Istiod1 不会接受到 Cluster2 的服务注册,且本集群也没有相关的服务注册,所以在请求解析 svc 的时候会直接返回失败。
Istiod1 只有在请求成功之后,才会同步更新其他集群节点的 svc 映射,从而实现负载均衡代理。
所以如果这个问题不解决,业务落地上会遇到很多麻烦,因为很多时候 Cluster2 的 Namespace 和 Service 都不需要再 Cluster1 再创建一份。
- Proxy 的代理异常
在我频繁修改测试 VirtualService & DestinationRule 的时候,会发现一些新增的规则,往往无法生效。
生效的时间会在 3min-5min 不等。
经排查,主要是因为 Istio Sidecar 规则更新的延迟,导致了流量的失效。
Istio Sidercar xDS 规则更新主要提供全量更新和增量更新两种方式。
经测试,Create 和 Delete 是响应最快的更新,而 Update 是响应最慢的更新。这是因为前两个触发的是全量更新,而后者触发的是增量更新。
这里可能会有个疑惑,增量不是会比全量更快更新吗,为什么反而是响应最慢的更新呢?
这是因为 Sidercar xDS API 是满足最终一致性,部分流量可能在更新时被丢弃。
比如只有集群 X 可以通过 CDS/EDS 发现,那么当引用集群 X 的路由配置更新时,并且在 CDS/EDS 更新前将配置指向集群 Y,那么在 Sidercar 实例获取配置前的部分流量会被丢弃。
所以如果代理规则生效时间无法缩短,会影响业务本身的体验。
看到这里大家可能会想,能不能把多个 VirtualService 的规则拆开来写,这样不就都变成 Create 而不是 Update 了吗?
这种方法也行不通,因为 VirtualService 不具备聚合的功能,且是依照 Prefix 的顺序匹配。
为了加快响应,可以每次都先 Delete 再 Create,但是这样的全量更新成本对网络节点压力是比较大的,且如果每个 App 新增一次就要变更一次流量规则,是一个非常差劲的方案。
起初我想通过 VirtualService & DestinationRule 套娃的方式解决问题,架构设计类似这样:
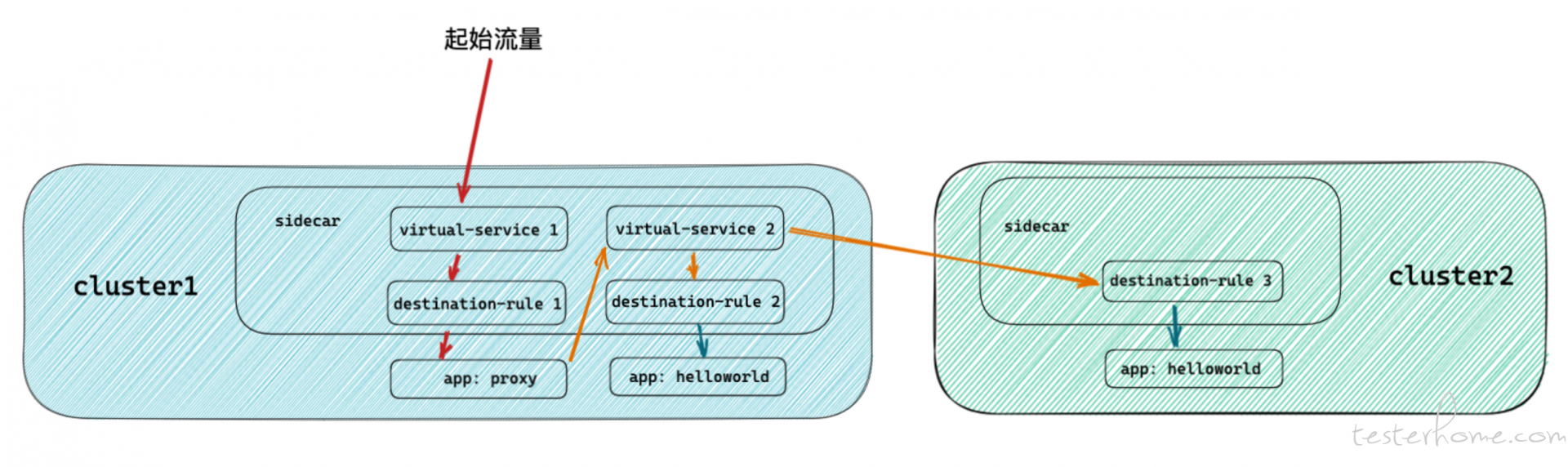
测试结果是失败的,Sidecar 无法支持不同 host 的多层流量规则的重定向,所以这条路也堵死了。
优化流量代理
突然灵感一闪,为什么我一定要局限于通过 Sidecar 来既完成不同 Cluster 的定位,又完成不同 App 的定位呢?
我完全可以通过 VirtualService & DestinationRule 来完成不同 Cluster 的定位,然后 App 的定位直接作为 Proxy 的业务功能进行自定义开发。
其架构设计如下。
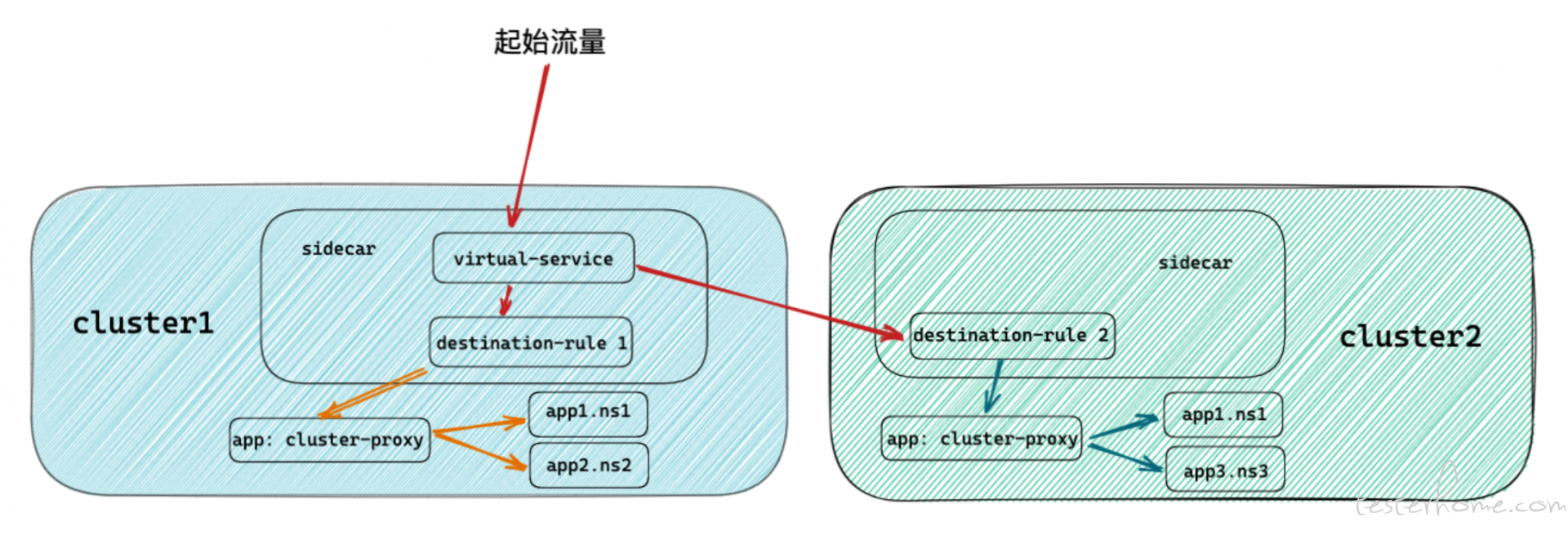
这个架构优化的核心就是,减少网格中 Sidecar 的数量。
大家可能会觉得,这个服务网格部署了不就是要每个 App 注入 Sidecar 吗?
其实并不是这样,如果你的目的是为了监控所有 App 的网络链路,这么做无可厚非,如果只是想打通集群间的通信,我们其实只想要一个代理服务注入 Sidecar 即可。
而且这样的设计,不仅大大优化了代理规则的更新速度,且集群之间的 svc 无需做双向同步,因为 cluster-proxy 这个服务本身的转发,就限定在了 Local,所以转发携带的 svc 的解析只会经过 Kube-dns 而不是 Istiod。
如此,一套方案成功解决了两个大的问题。
最终的跨集群通信架构
至此,一个支持多个第三方跨网络跨地域从集群接入,受主集群管控,具有 CA 鉴权滚动更新,并支持指定从集群专载流量的跨集群方案,设计完成并验证通过。
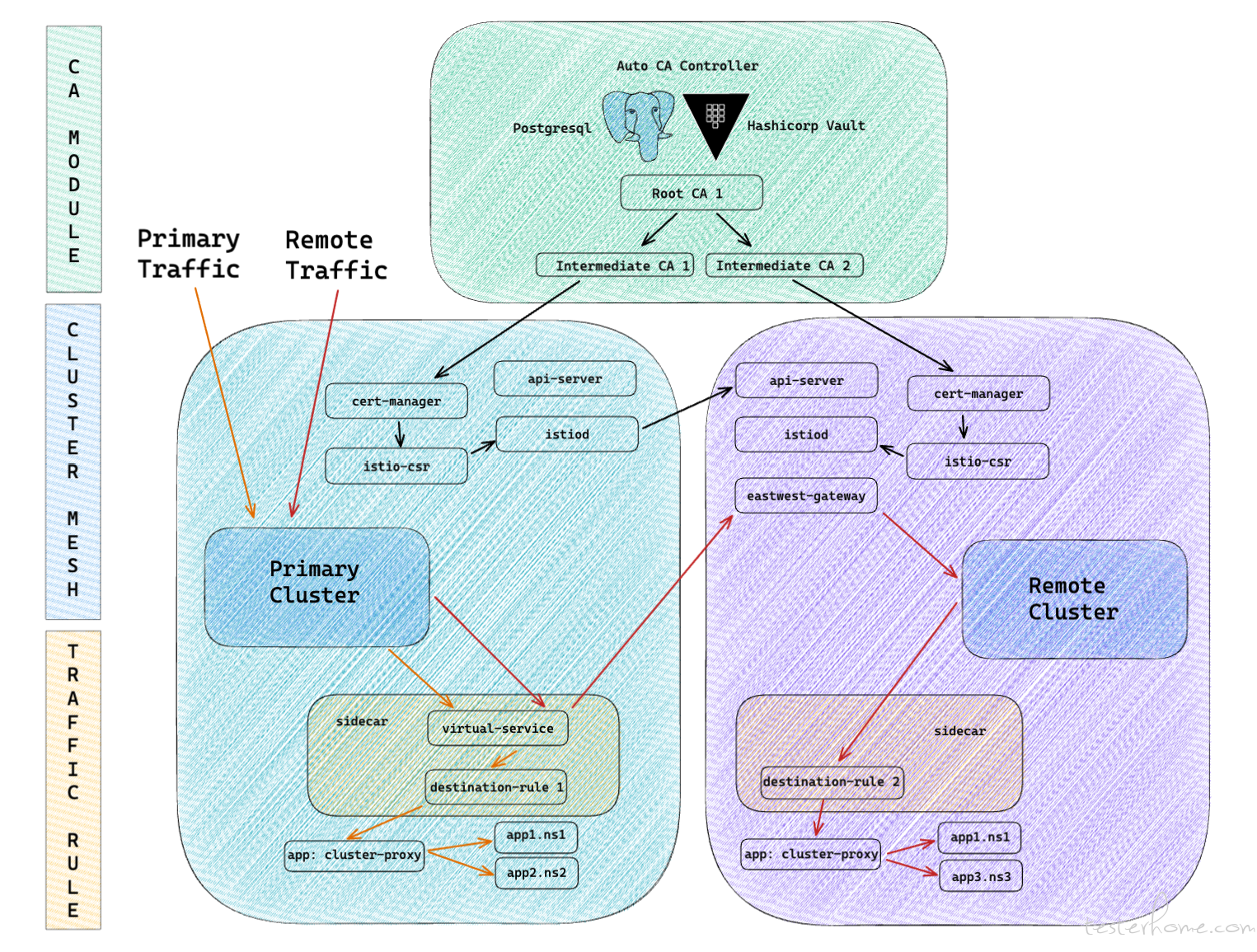
落地到压测的业务场景
- 多地联合发压
构建了一套跨地域跨集群的通信架构以后,其实多地联合发压这个问题,反而变得很简单了。
这也是压测业务中经常需要的功能。
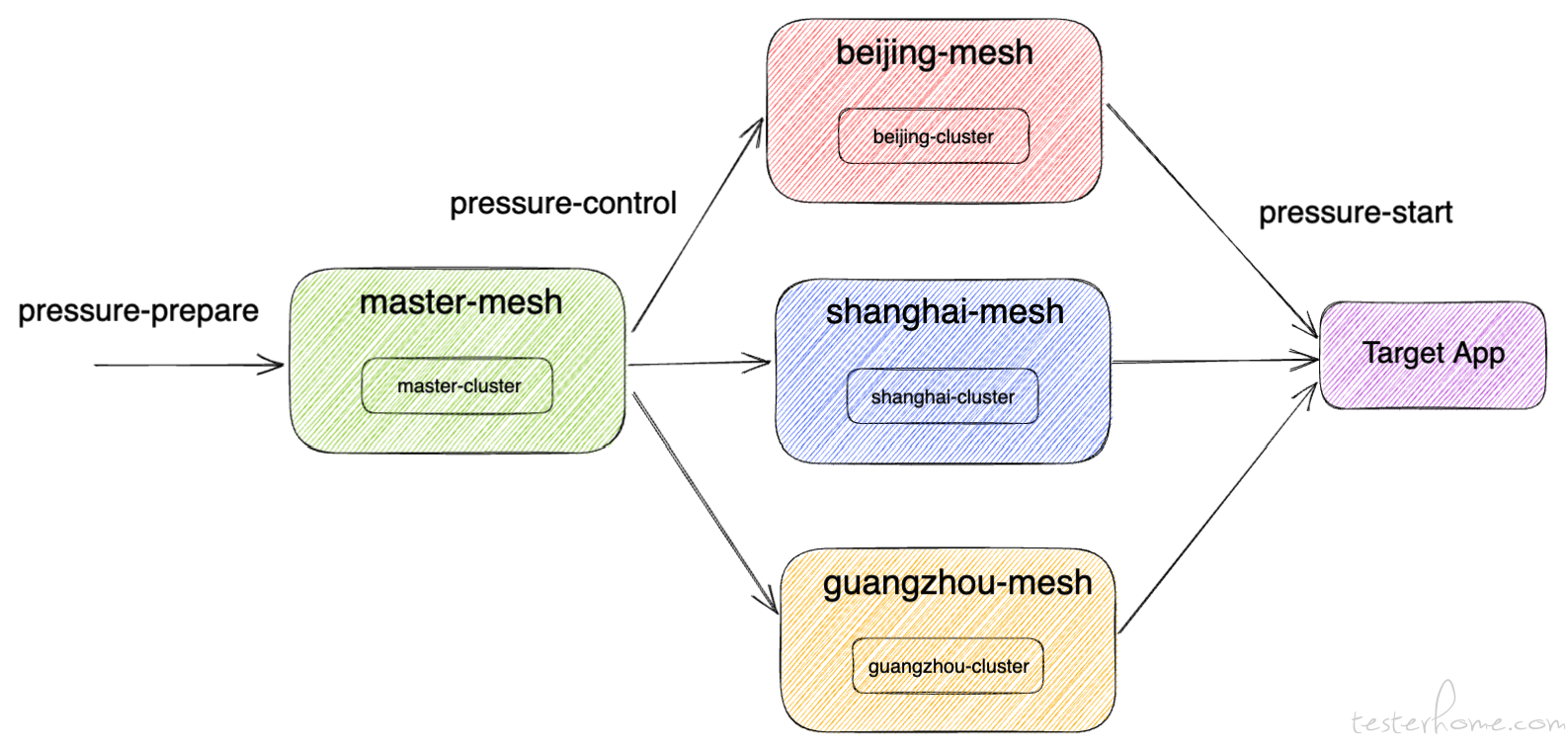
- 多地域负载均衡
对地域用户的流量做标识,比如北京地域的用户,优先负载到北京主集群的服务。
当北京集群服务不可用时,将会优先代理到最近的可用集群,比如上海集群。
这样既可以提高服务的响应速度,也可以做高可用。
- 可拔插资源
在护航各省市健康码的过程中,所需要的压测集群会来自不同的地域,不同的 VPC,不同的账号体系。
而这套架构可以无视这些区别,只要是基于 K8S 事实标准的集群,均可接入。
而当用完之后,只需要移除对应的 CA 证书,这个集群将会断开与主集群的连接。
方便项目的进出,以及资源的拔插,安全的管控,以及内网的压测。
最后就以手办结尾,纪念一下守护的那些健康码!

PS:

