一,新建钉钉机器人
1.钉钉群右上角点击群设置,选择智能群助手,点击添加机器人,选择自定义机器人;
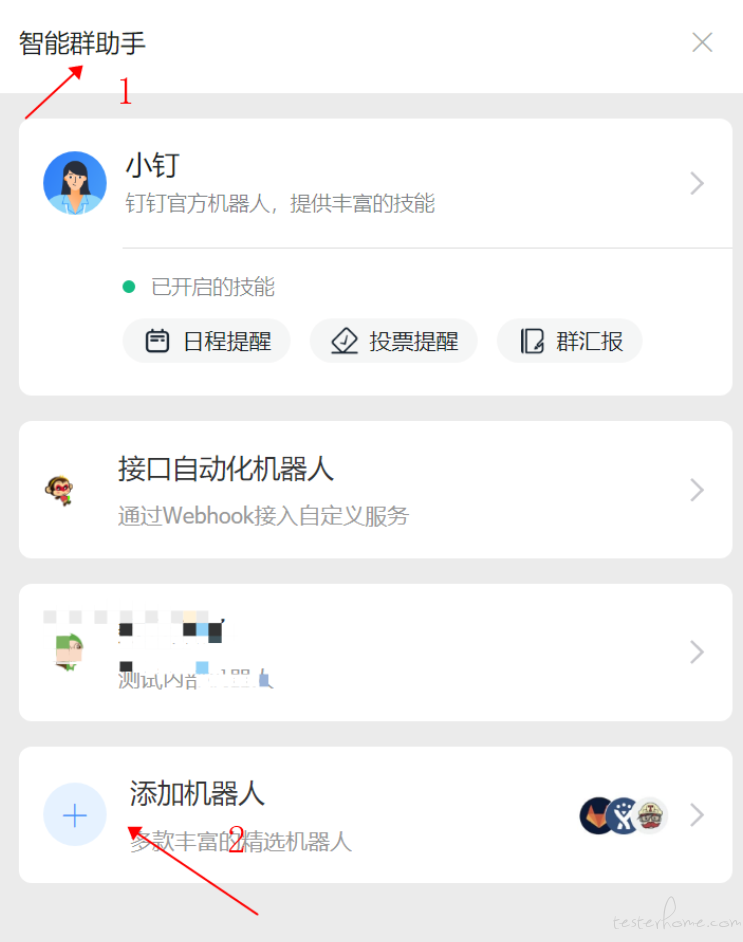
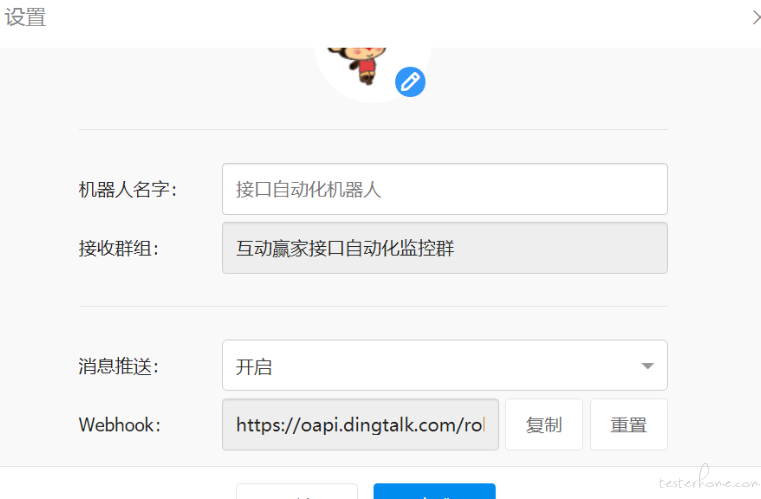
2.给机器人起个名字,消息推送开启,复制出 webhook,后面会用到,勾选自定义关键词,填写关键词(关键词可以随便填写,但是一定要记住,后面会用);

二,钉钉机器人发送消息
url 就是创建机器人时的 webhook,data 中的 atMobiles 可填写多个手机号,发送的消息会直接 @ 这个人,text 的 content 里面一定要加上创建机器人时设置的关键词,msgtype 意思时文本格式,也可以 link 格式,就可以放链接了;
def send_text(self):
url = "https://oapi.dingtalk.com/robot/send?access_token=43c4dab2ac31125e605c458b4b9561a73"
headers = {'Content-Type': 'application/json'}
data = {"at": {"atMobiles":["18206264857"],"atUserIds":["user123"],"isAtAll": False},
"text": {"content":"砍价小程序接口自动化测试"},"msgtype":"text"},"msgtype":"text"}
requests.post(url,headers=headers,data=json.dumps(data))
三,钉钉机器人实际的应用
1.监控接口自动化结果
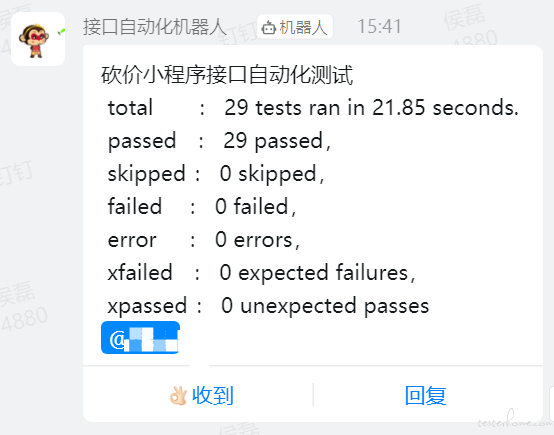
实现思路是:jenkins 定时执行自动化——执行完后生成 html 报告——BeautifulSoup 模块解析 html 报告——发送钉钉消息
如下代码:
解析 html 的模块:
from common.handle_path import html_path
from bs4 import BeautifulSoup
class GetHtml:
"""
读取测试报告,解析html 获得测试用例总数,通过数等,发送到钉钉
"""
def get_total(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("p")[1].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
def get_pass(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("span",class_="passed")[0].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
def get_skipped(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("span",class_="skipped")[0].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
def get_failed(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("span",class_="failed")[0].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
def get_error(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("span",class_="error")[0].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
def get_xfailed(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("span",class_="xfailed")[0].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
def get_xpassed(self):
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
soup = BeautifulSoup(file, 'html.parser') # 使用BeautifulSoup库解析网页内容
item = soup.find_all("span",class_="xpassed")[0].string # 使用BeautifulSoup库的标签方法找到你需要的内容
return str(item)
if __name__ == '__main__':
t = GetHtml()
t.get_xpassed()
如下代码:
发送钉钉消息的模块:
import requests
import json
from common.handle_readhtml import GetHtml
class SendMassage:
"""
发送测试结果到钉钉群
"""
result = GetHtml()
total = result.get_total()
passed = result.get_pass()
skipped = result.get_skipped()
failed = result.get_failed()
error = result.get_error()
xfailed = result.get_xfailed()
xpassed = result.get_xpassed()
def send_text(self):
url = "https://oapi.dingtalk.com/robot/send?access_token=43c4dab2ac3152e605c458b4b9561a73"
headers = {'Content-Type': 'application/json'}
data = {"at": {"atMobiles":["18206233880"],"atUserIds":["user123"],"isAtAll": False},
"text": {"content":"砍价小程序接口自动化测试 \n total : {}\n passed : {},\n skipped : {},\n failed : {},\n error : {},\n xfailed : {},\n xpassed : {}".format(self.total,self.passed,self.skipped,self.failed,self.error,self.xfailed,self.xpassed)},"msgtype":"text"}
requests.post(url,headers=headers,data=json.dumps(data))
if __name__ == '__main__':
s = SendMassage()
s.send_text()
jenkins 配置的 shell 为:
先执行接口自动化脚本,等待一会然后发送钉钉消息;
${PYTHON} main.py
sleep 100
${PYTHON} handle_dingding.py
接口自动化发钉钉群消息还可以再优化,比如可以加上断言失败的错误日志等;
2,监控 qa 环境错误日志
这里贴上周游大佬的一篇博客:https://www.cnblogs.com/zy0209/p/12769466.html
此处发送的 qq 邮件,消息查看不方便,且不好共享,可以优化为发钉钉群消息,然后将开发也拉到群里,提高效率;
3,jira 上有钉钉机器人插件,可以每天发送消息 @ 某某开发 还有 N 个待处理 bug,@ 某某测试 还有 N 个待验证 bug,以及监控看板指标达到阈值报警等;
「原创声明:保留所有权利,禁止转载」
