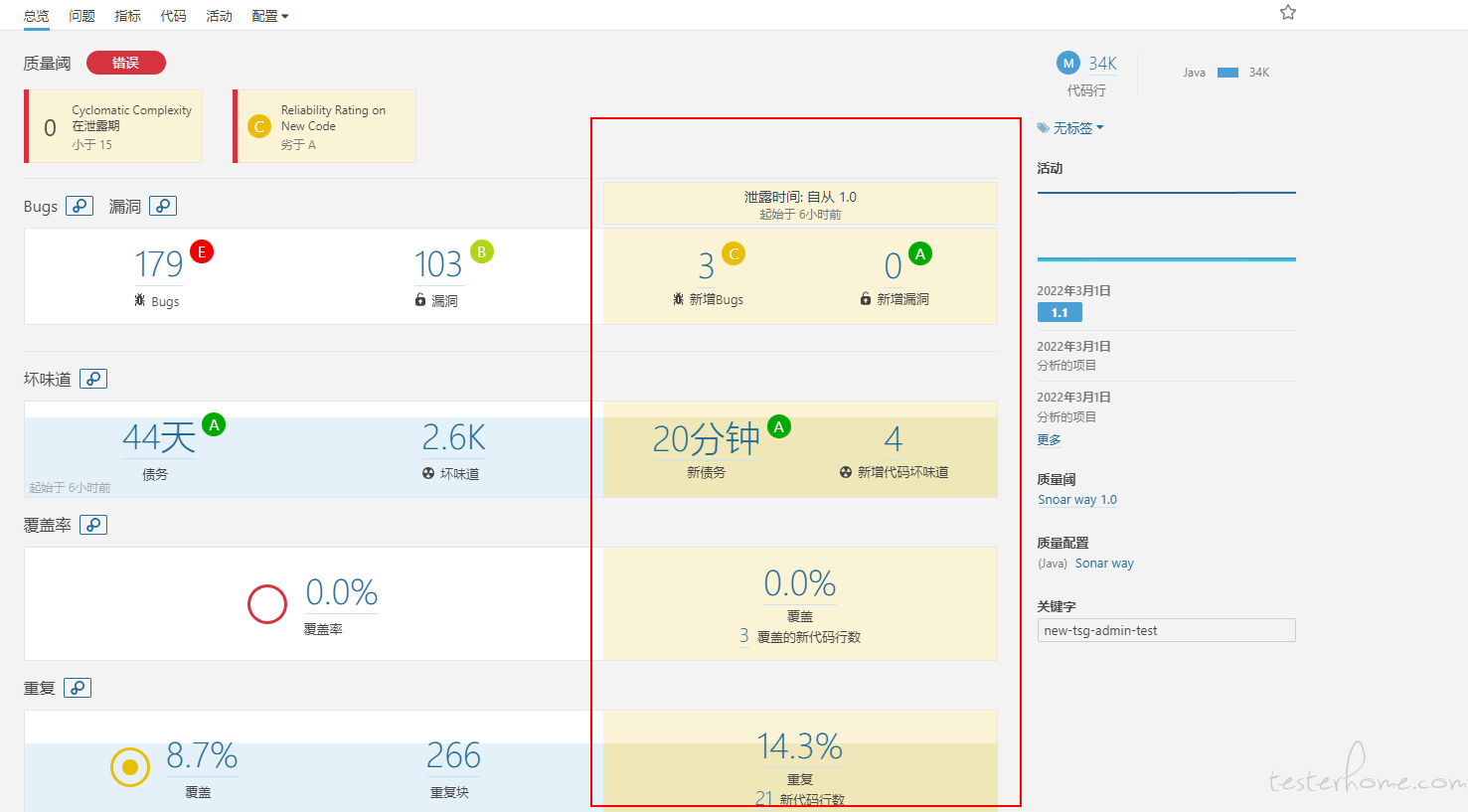
右侧出现这些我感觉我已经设置成功了,点进去确实看到的是增量代码的问题。
但是在 Jenkins 执行时每次还是进行了全量的扫描,大概 1 分多钟吧。 由于我们 Snoar 设置的是开发每次构建都会自动跑,一个开发在和前端联调时候一天会构建 N 次, 这样无中生出 1 分钟多会降低开发的效率。 请教下各位大佬,Snoar 只对增量代码扫描的话应该如何设置呢?
stage ('SonarScan') { echo "codeAnalyze started!" withSonarQubeEnv() { sh """cppcheck -j 4 src/ -itest --enable=all --xml --xml-version=2 ./* 2> ${WORKSPACE}/cppcheck-result.xml""" sh """sonar-scanner \ -Dsonar.projectKey=${JOB_NAME} \ -Dsonar.projectName=${JOB_NAME} \ -Dsonar.sources=${WORKSPACE} \ -Dsonar.host.url=http://jenkins.urcompany.com \ -Dsonar.language=c,c++ \ -Dsonar.exclusions=**/*.py,**/*.java,**/*.go,**/*.js,**/*.ts,**/*.css \ -Dsonar.inclusions=example1/**/*,example2/**/* """ } echo "codeAnalyze Completed!" script { timeout(10) { def qg = waitForQualityGate('caffe_quality_gate') if (qg.status != 'OK') { error "未通过Sonarqube的代码质量阈检查,请及时修改!failure: ${qg.status}" } } } }
1、只对增量代码扫描,可以用楼上说的这个方式,但粒度只能到文件粒度,没法到行级别
2、你框里的这个不是指增量代码扫描得出的内容,而是指从某个特定时刻开始,新增的问题。这个是 sonar 内部的一个过滤器,过滤掉这个时刻前的所有问题,只记录这个时刻后的新问题,在 sonar 概念里称为 “新增代码” 。由于 sonar 的理念是只要保障新增代码质量,久而久之整个项目的质量就会上升(老代码只要被重构或者优化就会当做新代码),所以把这个过滤器放到了一个比较显眼的位置。
默认配置这个 “新增代码” 的范围,是以版本号作为起点的,比如版本号 1.0.0 第一次扫描为基线,第二次扫描开始直到版本号变更前的所有扫描,产生的代码变化都会被认为 “新增代码” ,这部分代码产生的问题会被认为是 “新增问题”。
每个项目都可以配置自己的这个 “新增代码” 范围,我们一般配置为从此项目确认开始要求 sonar 代码质量那一天开始,这天前的旧代码问题不追究,这天后新增的都要求符合统一的质量阈要求(比如不能新增阻塞级别的问题等),不符合的就要修。
再看了下正文,发现我说歪了。。。忽略我。。。
一楼是正解。不过我更建议你们 sonar 不要配置成每次构建都跑(代码量大了之后很可能增加的时间更长,研发意见会比较大,而且 sonar 质量阈不通过是不是要阻断部署,这个要和研发达成共识,要不很容易背上影响工作效率的锅),而是独立一个 job 另外做,联动 gitlab push event 自动扫就可以,不要影响研发的正常构建部署。
没歪没歪,大佬说的挺有帮助