前言
之前用 5 篇文章详细介绍了开源监控软件《普罗米修斯》的使用, 还没看过的同学可以翻阅我的专栏, 可以说普罗米修斯是我在测试中很常用的工具了, 但是普罗米修斯毕竟不是为测试场景设计的,尤其在基于 K8S 的测试环境中它依然有一定的局限性, 比如:
- 普罗米修斯的产品定位更偏向于收集性能数据并提供丰富的长期性能分析能力。 并无法在异常事件发生时提供相关日志信息帮助用户定位问题。
- 普罗米修斯由于其定位原因,架构上采取基于 Pull(主动拉取) 的采集机制, 使用的是周期性采样的策略, 这样势必会漏掉瞬时事件, 比如普罗米修斯默认每隔 15 秒去抓取一次数据,但是 pod 在这 15s 内 crash 并完成重启也是比较正常的事情, 这样这个异常事件就漏掉了。
- 普罗米修斯是通用的监控工具,并不是专门为了 K8S 而生。 所以它无法在监控过程中分析 k8s 集群中的服务是否在高可用,稳定性,资源占用等方面是否存在隐患,也无法准确分析出监控期间服务的 SLA,无法判断服务异常是否是部署更新操作导致。
- 普罗米修斯的资源监控更偏向于整体分析,除 CPU 和内存外采集的均为节点维度的数据。 在问题发生时,较难排查出具体是哪个容器出现的错误。
- 普罗米修斯的在收集服务资源数据的时候没有很好汇总能力, 比如我想在一个表格里看到所有 pod 的 cpu,内存,gpu 在一段时间内的平均和最大使用情况, 以及对应的 request 和 limit 情况, 这个在普罗米修斯里是看不到这样的汇总消息的。
所以, 我决定在普罗米修斯的基础上, 开发自己的组件来补足缺失的功能。
架构设计
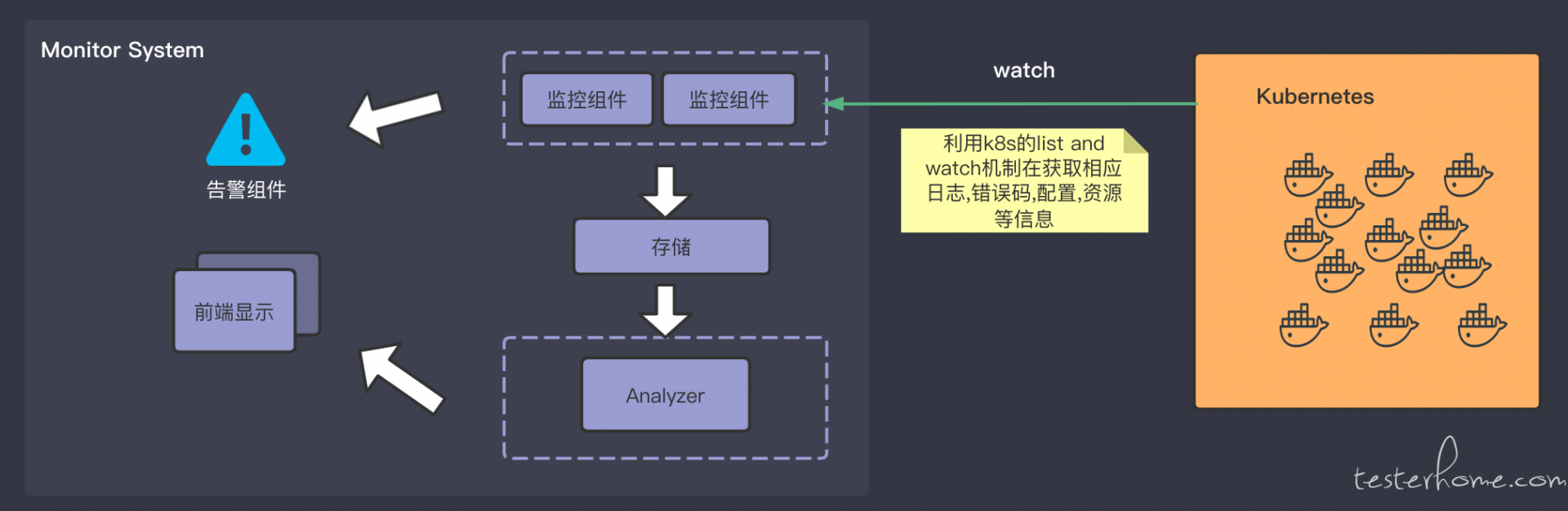
- 为了解决普罗米修斯的 PULL 架构和无法在服务异常时提供日志等相关信息的问题,平台的核心组件基于 K8S 的 List And watch,属于典型的发布订阅模型。 该组件运行于集群内部并订阅 K8S 集群中的事件, 集群任何的异常都会被记录下来,并且可以通过 k8s 的 api 抓取错误码和日志。
- 根据不同的监控目的会运行不同的监控组件用于收集服务信息。 如果遇到服务异常这种需要告警的事件发生,会通知告警组件进行告警。 目前主要设计的告警形式为企业微信
- 存储设备会保存监控组件收集来的数据,包括但不限于服务的资源信息,日志,调度策略,配置信息等等
- Analyzer 读取存储设备中的数据对服务进行分析, 主要会从高可用,稳定性,资源占用,各种泄露问题等进行分析
- 前端服务主要用于展示 Analyzer 分析的结果
监控组件
目前设计两类监控组件:
- 事件监控 :基于 K8S 的 List And Watch 机制, 解决普罗米修斯 PULL 架构的遗漏事件问题, 并可抓取更详细的服务数据。如:日志,错误码,错误信息,资源占用。
- 容器监控: 容器级别的监控,收集容器内的资源使用数据。 如 socket,fd 和僵尸进程等,用于帮助用户分析各种泄露问题。 该组件以自定义 exporter 的形式对接普罗米修斯(相关代码在自定义 exporter 那篇帖子中写过)
以上这两种监控是对普罗米修斯缺失能力的补充。 容器监控的相关代码在自定义 exporter 那篇帖子中写过, 这里就不再多提了。 而事件监控主要基于 k8s 的 list and watch, 核心代码如下:
func (watcher *PodWatcher) Watch() {
startTime := time.Now()
watchPods := func(namespace string, k8s *kubernetes.Clientset) (watch.Interface, error) {
return k8s.CoreV1().Pods(namespace).Watch(context.Background(), metav1.ListOptions{})
}
podWatcher, err := watchPods(watcher.Namespace, watcher.K8s)
if err != nil {
log.Errorf("watch pod of namespace %s failed, err:%s", watcher.Namespace, err)
watcher.handelK8sErr(err)
}
for {
event, ok := <-podWatcher.ResultChan()
if !ok || event.Object == nil {
log.Info("the channel or Watcher is closed")
podWatcher, err = watchPods(watcher.Namespace, watcher.K8s)
if err != nil {
watcher.handelK8sErr(err)
time.Sleep(time.Minute * 5)
}
continue
}
// 忽略监控刚开始的1分钟的事件, 防止是事前挤压的事件传递过来
if time.Now().Before(startTime.Add(time.Second * 20)) {
continue
}
pod, _ := event.Object.(*corev1.Pod)
for _, container := range pod.Status.ContainerStatuses {
if container.State.Terminated != nil || container.State.Waiting != nil{
if pod.ObjectMeta.DeletionTimestamp != nil {
log.Warnf("the event is a deletion event. pod:%s namespace:%s, skip", pod.Name, pod.Namespace)
continue
}
now = time.Now()
var isContinue = false
for _, o := range pod.OwnerReferences {
if strings.Contains(o.Kind, "Job") || strings.Contains(o.Kind, "PodGroup"){
// 如果处于Completed状态的POD是属于JOB的,那是正常结束
if container.State.Terminated != nil {
if container.State.Terminated.Reason == "Completed" {
log.Debugf("Completed container is belong to job, skip. pod: %s", pod.Name)
isContinue = true
}
if time.Now().After(container.State.Terminated.FinishedAt.Time.Add(time.Minute * 5)){
log.Debugf("当前pod属于一个job,并且容器在很久之前就已经处于Terminated状态, 怀疑是k8s重复发送的update事件,所以不予记录和告警, pod:%s, namespace:%s, terminatedTime:%s, nowTime:%s", pod.Name, pod.Namespace, container.State.Terminated.FinishedAt, time.Now())
isContinue = true
}
}
if container.State.Waiting != nil {
if time.Now().Before(pod.CreationTimestamp.Add(time.Minute * 5)) {
log.Warnf("container Waiting in 5 minutes after pod creation, maybe need an init time. pod:%s namespace:%s, skip", pod.Name, pod.Namespace)
isContinue = true
}
}
}else {
if time.Now().Before(pod.CreationTimestamp.Add(time.Minute * 5)) {
log.Warnf("container terminated in 5 minutes after pod creation, maybe need an init time. pod:%s namespace:%s, skip", pod.Name, pod.Namespace)
isContinue = true
}
}
}
if isContinue {
continue
}
var reason string
if container.State.Terminated != nil {
reason = container.State.Terminated.Reason
}else {
reason = container.State.Waiting.Reason
}
logger := log.WithFields(log.Fields{
"pod_name": pod.Name,
"container_name": container.Name,
"reason": reason,
"namespace": pod.Namespace,
})
var errorMessage string
if container.State.Terminated != nil {
if container.State.Terminated.Message == "" {
errorMessage = "容器异常退出,请查看日志内容"
} else {
errorMessage = container.State.Terminated.Message
}
}else{
errorMessage = container.State.Waiting.Message
}
logger.Infof("container is not ready, the event type is:%s, reason:%s, message:%s", event.Type, reason, errorMessage)
cLog, _ := watcher.getLog(container.Name, pod.Name)
e := &Event{
PodName: pod.Name,
Namespace: watcher.Namespace,
Reason: reason,
Message: errorMessage,
Error: nil,
EventType: PodException,
ErrorTimestamp: time.Now(),
Log: cLog,
}
// 获取pod所属的服务名称
serviceName, serviceType, err := watcher.parseServiceInfo(pod)
if err != nil {
log.Errorf("从pod获取对应的owner的类型失败, 错误信息:%s", err)
}
e.ServiceName = serviceName
e.ServiceType = serviceType
for _, logData := range cLog {
if strings.Contains(logData, "unable to retrieve container logs for docker") {
log.Debugf("this pod is deleted manully, skip, pod:%s, log: %s", pod.Name, logData)
isContinue = true
}
}
if isContinue {
continue
}
watcher.event <- e
}
}
//}
}
}
func (watcher *PodWatcher) checkBlackList(pod *corev1.Pod) (ok bool) {
ok = false
if watcher.BlackList != nil {
for _, v := range watcher.BlackList {
if strings.Contains(pod.Name, v) {
ok = true
break
}
}
}
return
}
func (watcher *PodWatcher) getLog(containerName string, podName string) (map[string]string, error) {
// 抓取container日志
line := int64(1000) // 定义只抓取前1000行日志
opts := &corev1.PodLogOptions{
Container: containerName,
TailLines: &line,
}
containerLog, err := watcher.K8s.CoreV1().Pods(watcher.Namespace).GetLogs(podName, opts).Stream(context.Background())
if err != nil {
return nil, err
}
clog := make(map[string]string)
data, _ := ioutil.ReadAll(containerLog)
clog[containerName] = string(data)
return clog, nil
}
- 首先通过 k8s 的 client 调用 watch 方法, 这个方法返回一个 channel, 后续事件会通过这个 channel 源源不断的发送过来, 这里需要注意的是这个 channel 每隔 20 分钟就会关闭一次(我也不知道为什么 k8s 要这么设计),所以在代码中需要判断如果 channel 关闭后再重新进行 watch
- 拿到 pod 事件后,需要遍历 pod 下面所有容器的状态, 发现如果是 terminated 状态那说明这个容器已经 crash 了,是我们需要抓取并记录的。 这里需要注意的是要看一下 reason 字段, 如果是 completed 并且这个 pod 是属于一个 job 的话, 那么是正常退出的情况,需要进行过滤。 事实上 job 是一个特殊的资源类型,我们需要对它进行单独处理, 相关处理的细节可以看代码中的日志和注释。
- 代码最后有个 getLog 方法是使用 k8s client 来抓取日志的, 这里需要注意的是日志一定要在这里抓取而不能事后抓取, 因为这里是最后一次抓取日志的机会了, 后面容器被删除就抓不到了。
后面把相关信息通过企业微信的接口进行告警, 大概的效果如下:
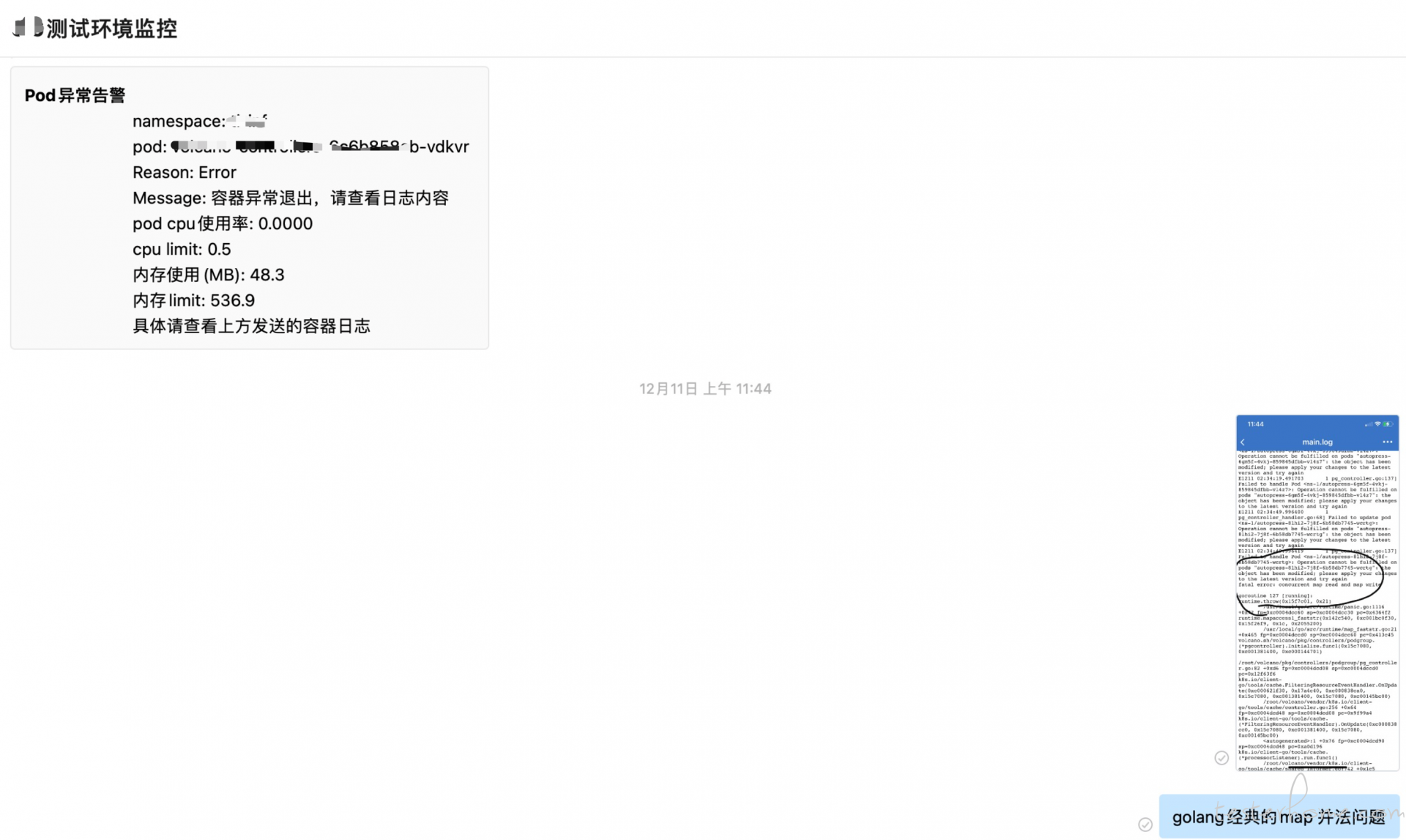
效果展示
资源分析模块
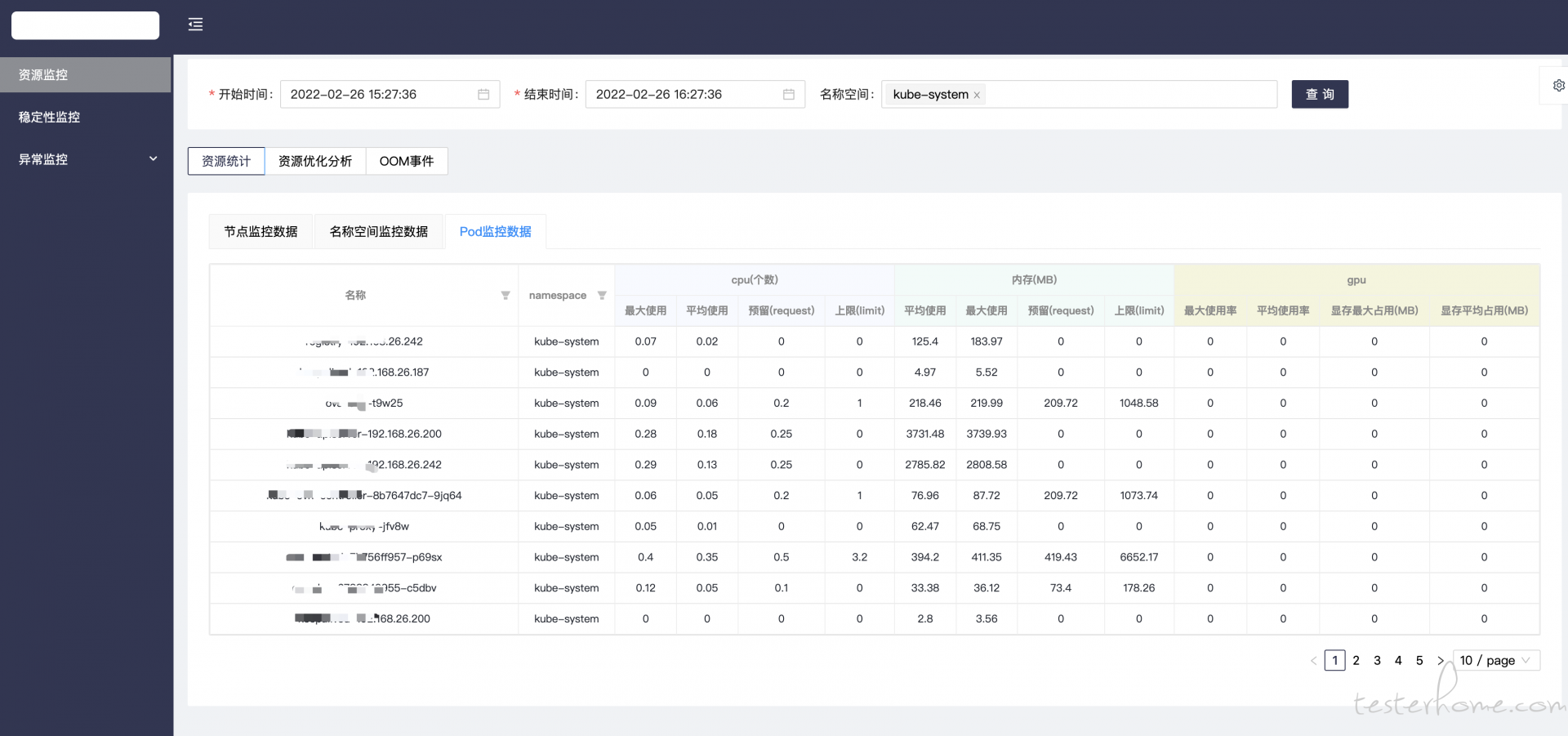
资源分析模块主要针对性能测试和 k8s 中资源配置测试场景而设计, 普罗米修斯结合 grafana 可以方便的制作仪表盘, 但是缺少一些汇总和分析能力, 而这个模块就是由此而诞生的。 这里没有过多自研的东西, 主要还是调用普罗米修斯的 HTTP 接口来抓取性能数据。 如何调用也再之前的帖子里介绍过了。 这里就贴一下收集 pod 性能数据的核心代码。
func GetPodsResources(namespaces []string, startTime, endTime string) ([]*PodResourceInfo, error) {
resultMap := make(map[string]*PodResourceInfo)
namespaceLabel := parseNamespaceLabel(namespaces)
var podCpuUsageResults *PromResult
var podCpuRequestResults *PromResult
var podCpuLimitResults *PromResult
var podMemoryUsageResults *PromResult
var podMemoryRequestResults *PromResult
var podMemoryLimitResults *PromResult
var podGpuUsageResults *PromResult
var podGpuMemoryResults *PromResult
wg := sync.WaitGroup{}
wg.Add(8)
var err error
var stepTime = "30"
// 开始收集POD CPU使用率
go func() {
defer wg.Done()
podCpuUsageResults, err = getPromResult(
fmt.Sprintf(`sum(irate(container_cpu_usage_seconds_total{container !="",container!="POD", namespace=~"%s"}[2m])) by (namespace, pod)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD CPU Request
go func() {
defer wg.Done()
podCpuRequestResults, err = getPromResult(
fmt.Sprintf(`sum(container_cpu_cores_request{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD CPU Limit
go func() {
defer wg.Done()
podCpuLimitResults, err = getPromResult(
fmt.Sprintf(`sum(container_cpu_cores_limit{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD memory 使用
go func() {
defer wg.Done()
podMemoryUsageResults, err = getPromResult(
fmt.Sprintf(`sum(container_memory_working_set_bytes{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD memory request
go func() {
defer wg.Done()
podMemoryRequestResults, err = getPromResult(
fmt.Sprintf(`sum(container_memory_bytes_request{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD memory limit
go func() {
defer wg.Done()
podMemoryLimitResults, err = getPromResult(
fmt.Sprintf(`sum(container_memory_bytes_limit{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD GPU usage
go func() {
defer wg.Done()
podGpuUsageResults, err = getPromResult(
//sum(irate(container_cpu_usage_seconds_total{container !="",container!="POD", namespace=~"%s"}[2m])) by (namespace, pod)
//max(container_gpu_utilization{container !="",container!="POD", namespace=~"%s"}) by (pod_name, container_name)/100
fmt.Sprintf(`max(container_gpu_utilization{namespace=~"%s"}) by (namespace, pod_name)/100`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD GPU memory usage
go func() {
defer wg.Done()
podGpuMemoryResults, err = getPromResult(
//sum(irate(container_cpu_usage_seconds_total{container !="",container!="POD", namespace=~"%s"}[2m])) by (namespace, pod)
//max(container_gpu_memory_total{container !="",container!="POD", namespace=~"%s"}) by (pod_name, container_name)
fmt.Sprintf(`max(container_gpu_memory_total{namespace=~"%s"}) by (namespace, pod_name)`,
namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
wg.Wait()
if err != nil {
return nil, errors.Cause(err)
}
// 解析CPU使用率
parsePodResource(podCpuUsageResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.CpuMaxUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64)
result.CpuAvgUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue), 64)
}, resultMap)
// 解析GPU使用率
parsePodResource(podGpuUsageResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.GpuMaxUtilization, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64)
result.GpuAvgUtilization, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue), 64)
}, resultMap)
// 解析GPU Memory 使用
parsePodResource(podGpuMemoryResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.GpuMemoryMaxUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64)
result.GpuMemoryAvgUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue), 64)
}, resultMap)
// 解析CPU Request
parsePodResource(podCpuRequestResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.CpuRequest, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64)
}, resultMap)
// 解析CPU Limit
parsePodResource(podCpuLimitResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.CpuLimit, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64)
}, resultMap)
// 解析memory usage
parsePodResource(podMemoryUsageResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.MemoryMaxUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue/1000/1000), 64)
result.MemoryAvgUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue/1000/1000), 64)
}, resultMap)
// 解析memory request
parsePodResource(podMemoryRequestResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.MemoryRequest, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue/1000/1000), 64)
}, resultMap)
// 解析memory limit
parsePodResource(podMemoryLimitResults, func(result *PodResourceInfo, maxValue, avgValue float64) {
result.MemoryLimit, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue/1000/1000), 64)
}, resultMap)
return mapToPodSlice(resultMap), nil
}
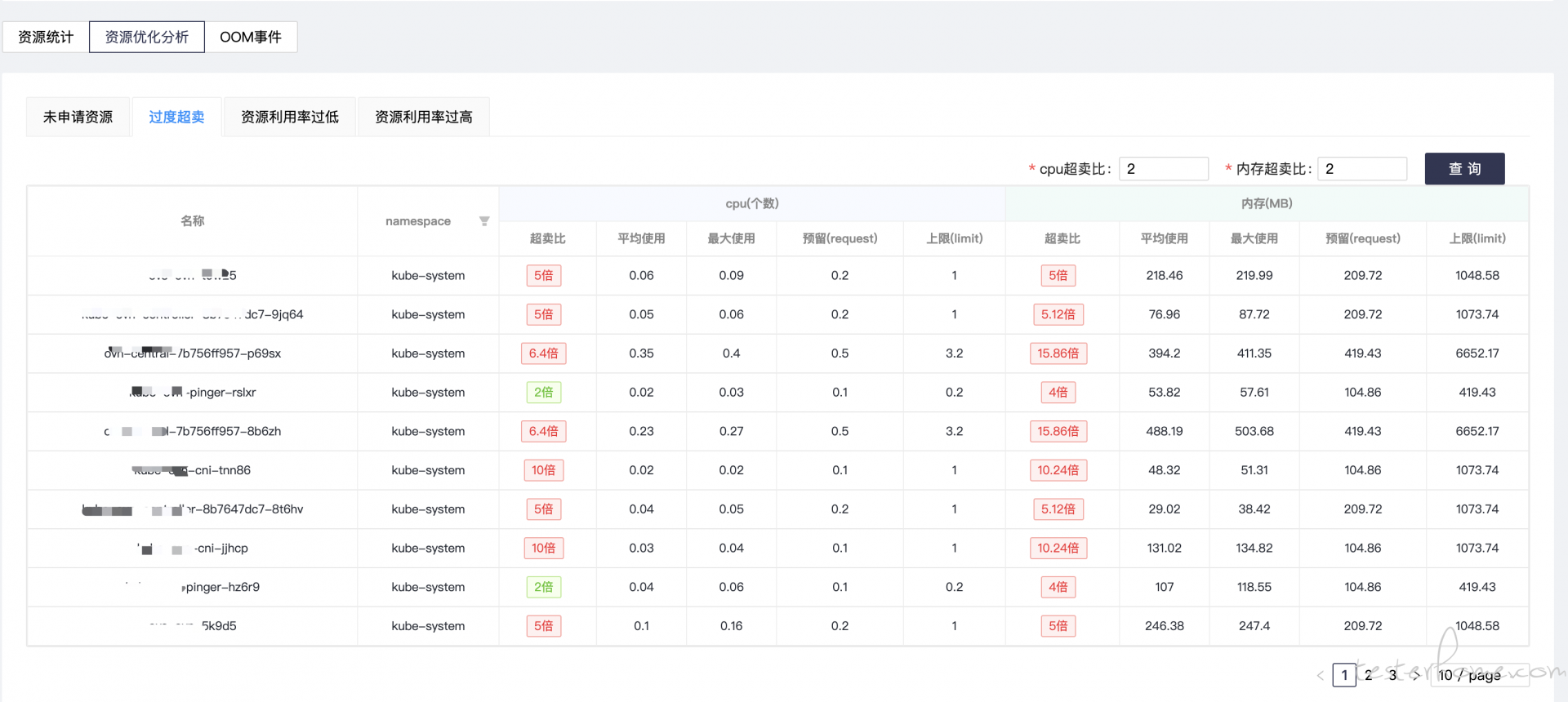
这里还需要提一下为了针对产品服务的资源配置进行测试而设计的资源分析模块, 这个场景主要是为了在压测中分析服务配置的资源参数是否合理而设计。 是否有过度超卖, 资源利用率低下的问题等。 如下:
稳定性分析模块
这个模块主要利用收集的数据分析集群在运行中是否存在一些高可用,稳定性等相关的隐患。 如下:
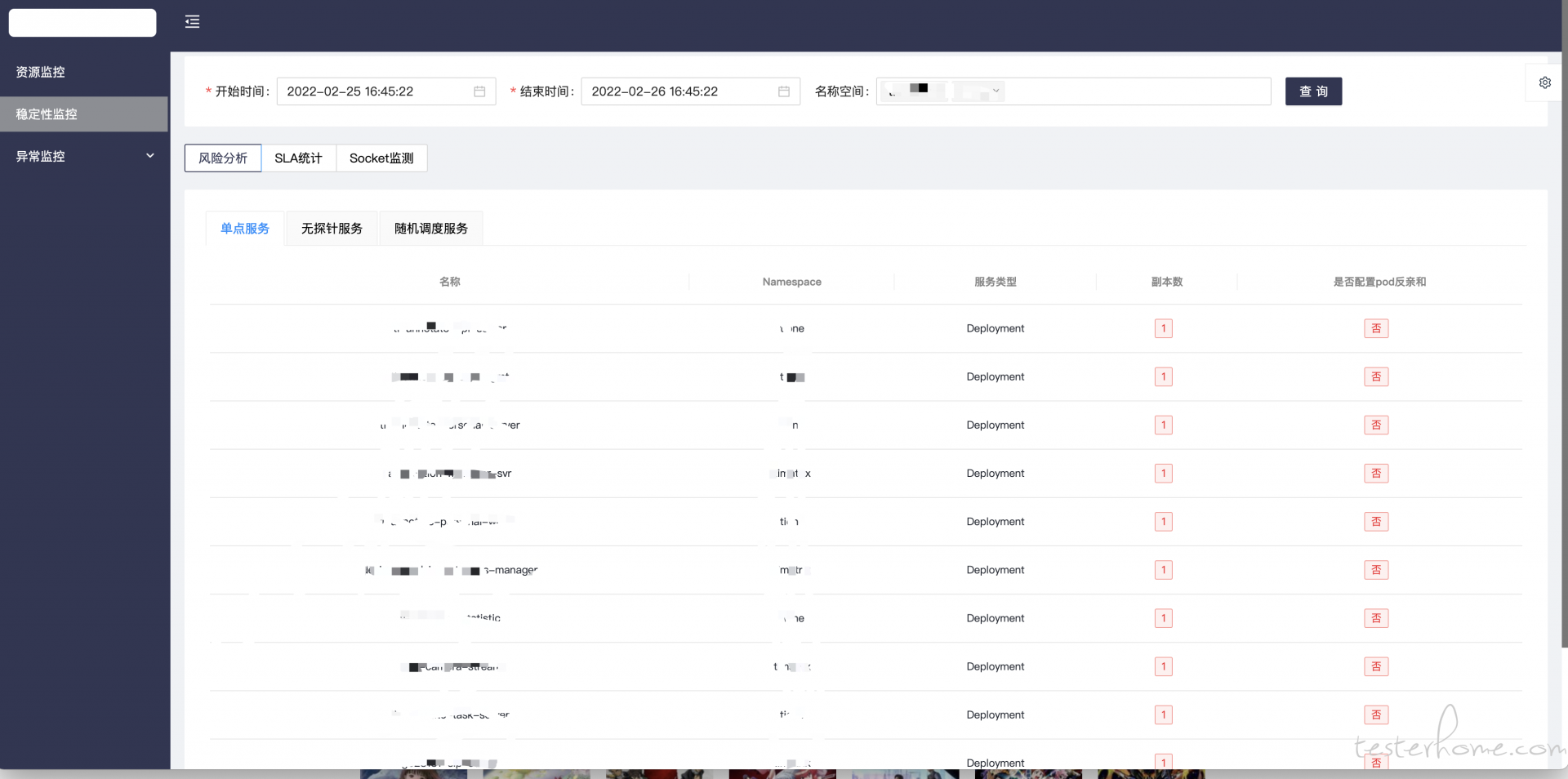
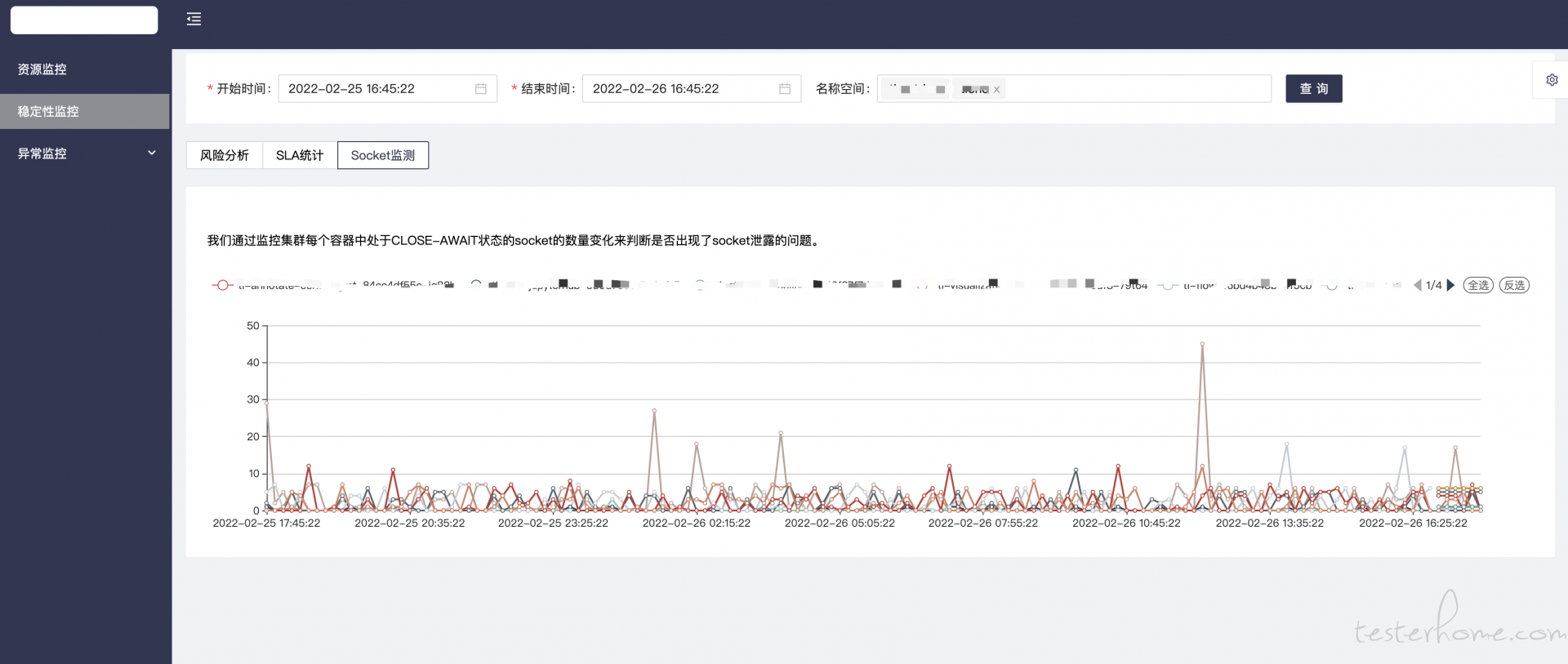
这里有 3 个子模块:
- 风险分析主要利用 k8s 的 client 来抓取 pod 配置信息并分析其中是否有隐患
- SLA 统计主要利用的是异常监控模块中抓取到的事件来进行分析计算。 在异常监控组件中, 有一个监控类型是 watch 住了 pod 对应 service 下的 endpoints 对象, 这个对象里维护了该服务下所有 pod 的 ip 地址。 一旦 pod 有异常该 ip 地址就会被放到不可用列表中。 监控组件当发现一个服务下没有任何 pod 可用时就会判断服务不可用并记录在数据库中, 等服务恢复后再把状态进行更新。 这样通过 sql 语句就可以计算出每个服务具体的 SLA 了。
- Socket 监控是我自研的一个普罗米修斯的 exporter, 这个监控 socket 泄露的 exporter 在之前专门讲过这里就不说了。
异常监控模块
这个模块没啥好说的, 主要就是把异常监控的数据在页面上做了一个可视化展示, 就不多说了。
总结
监控平台还没有完全开发完, 算是个半成品。 主要利用了普罗米修斯和 k8s 的 client 进行了定制化开发。 前面写了 5 篇介绍普罗米修斯的帖子其实也是为了今天介监控平台做的铺垫。 不过其实铺垫的也不够, 因为利用 k8s client 定制化开发监控组件没有详细的讲, 还是懒了