柯南流量录制回放平台 柯南平台的基本介绍(项目已开源文末福利)
一、前言
业务的线上质量与研发全流程的效率一直是工程师们关注的重点,近几年 CI/CD 的成熟度更是衡量研发团队效能体系的重要指标,质量与效率的博弈不断考验每一位工程师,本文重点介绍网校质量团队是如何基于线上真实流量来赋能于网校业务的质效保障工作的。
透过问题看本质,技术手段保障业务的核心原理。
- 没有稳定保障的自动化服务,等同于鸡肋
- 没有覆盖度分析的交付过程,等同于裸奔
- 没有持续测试能力的 CI/CD,等同于灾难

Devops 定义
二、基于流量保障质量需具备的核心能力
1.流量的录制采集:
线上真实的用户流量是后续所有能力的基础支撑,对于服务验证,性能测试,技术重构等大量场景来说,利用好线上流量能够为整个研发生命周期提供更高的质效保障能力,把更多的问题拦截在上线前是每个工程师的职责所在。
目前行业内对于流量采集行为主要分为两种类型
- 主路复制
- 旁路复制
主路复制
方式:日志上报、代码切面支持 、框架层面复制(Dubbo Service Mesh)、开源方案(rdebug,jvm-sandbox)
优点:流量可控制度强,灵活调配,高度结合业务。
缺点:耦合业务拓展性差,特定语言栈,采集模块可能对服务性能有损耗。
旁路复制
方式:网络协议栈采集
优点:业务无感知,与业务无耦合。
缺点:数据包解析,解析性能开销,流量加工成本较高。
选择最适合的方式:业务角度 + 接入成本
- 在线教育业务特性:
多类型直播 + 互动场景 + 课件 + 课堂行为 + 多种流量角色 - 流量采集规则控制:支持采集用户数配置与采集场景配置
- 无需业务改造,对服务无侵入,接入成本低
结论:
确定采用旁路复制方式,基于 Nginx Accesslog 以满足多维度的流量采集需求,并且无需安装采集服务,http 协议无语言栈壁垒,对业务无性能及安全影响。
面临挑战
- 如何基于多种维度进行流量的采集
- 如何识别流量身份
- 如何保证调用时序控制
- 作为集团中台项目如何快速适配不同事业部技术架构以支持各业务线的接入与使用
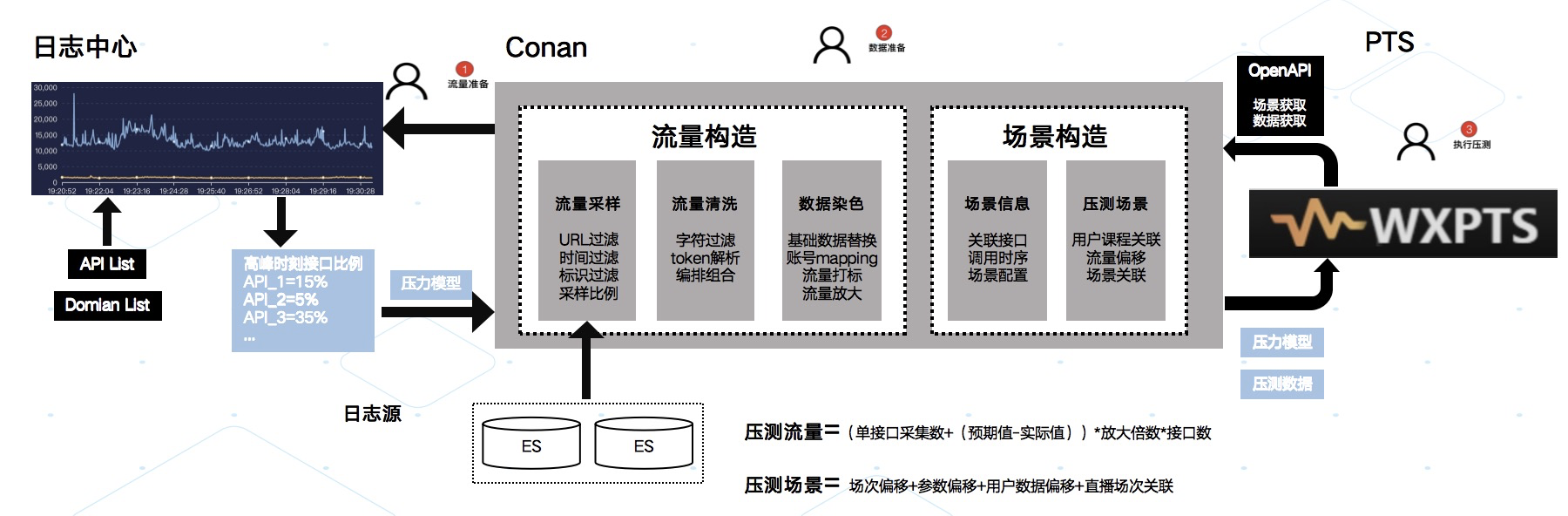
流量采集录制架构
整体架构基于流式模型设计,针对不同事业部网关日志进行数据清洗,根据核心字段通过数据转换层改造成可用作回放的初始流量同时通过 token 解析确定流量身份,并且基于 token 与 traceId 的串联关系来保证行为与链路精准采集。针对不同事业部流量基于业务 API 会做一次初步的数据替换与染色从而保证数据的安全性以免在后续的使用中影响到线上用户与业务数据。
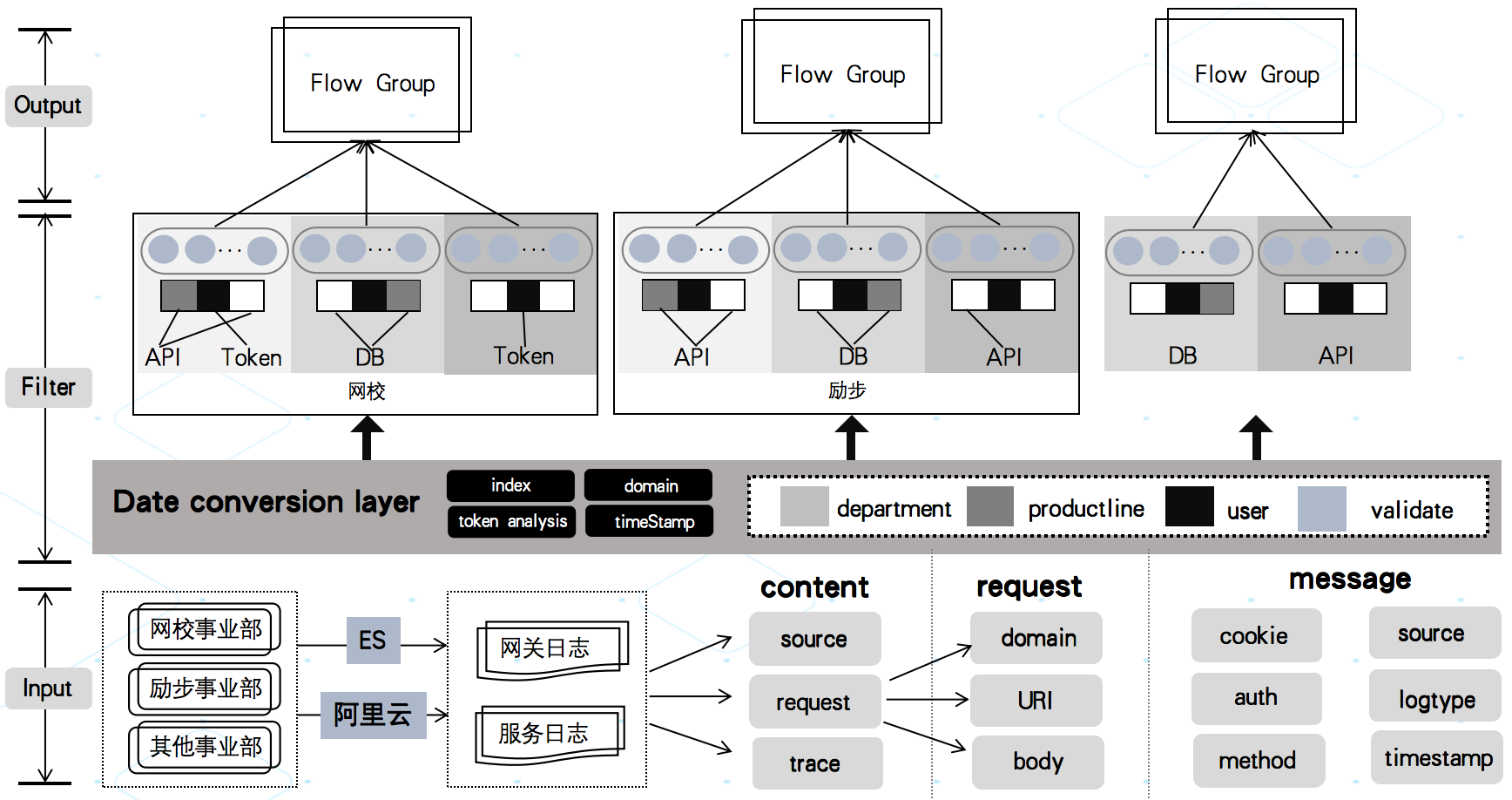
录制服务架构
提供能力
- 基于用户采集流量
- 基于场景采集流量
- 流量时序标识
- OpenAPI 赋能其他平台
2.业务模型构造:
这部分工作主要是针对核心写场景业务进行模型构造,从而保证基于业务模型来完成所需场景的构造与流量数据相结合,这部分产出的场景构造能力与数据清洗染色能力在为回放提供稳定流量的同时也为性能测试及内部其他平台提供高效的数据构造能力,为业务建模与测试行为提供更丰富的能力支撑。
面临挑战
- 模型特征如何分类
- 如何保障对用户与业务无影响
- 高效的数据替换方式
- 业务变更后初步的自适应能力
以网校大班直播业务场景为例
根据业务梳理出核心字段,对核心字段进行人工标记归类。模型构造服务主要对采集到的流量做二次染色偏移并且构造出回放依赖的业务场景,向量的起点与终点分别对应着 “原始流量” 中的场次与基于模型构造出的用来承载 “回放流量” 的偏移后场次,同时流量会在保留线上真实特征数据的情况下基于模型进行数据替换,从而保证回放的顺利执行。
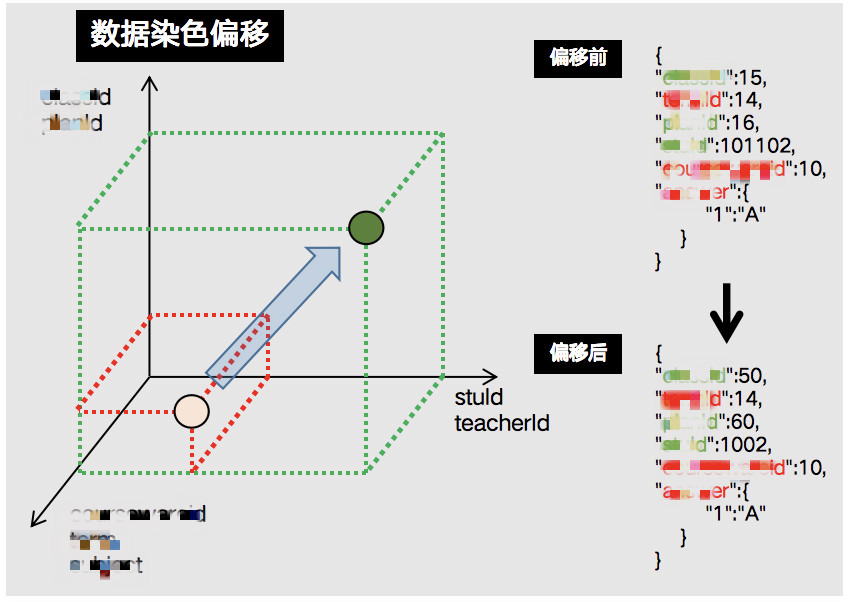
模型构造
分类的依据
- 特征数据类(用户作答记录,课件数据,教师操作 等)
- 课程数据类(课程 ID,场次 ID 等)
- 固定步长偏移类(学生 ID,教师 ID 等)
对于业务变更,如果有新增基础数据就可以根据类别进行划分并且结合自研的数据替换算法,以持续保证业务模型的长期稳定,也就解决了传统自动化无法快速适配业务变更需要持续维护脚本或服务的尴尬问题。
数据替换算法图示
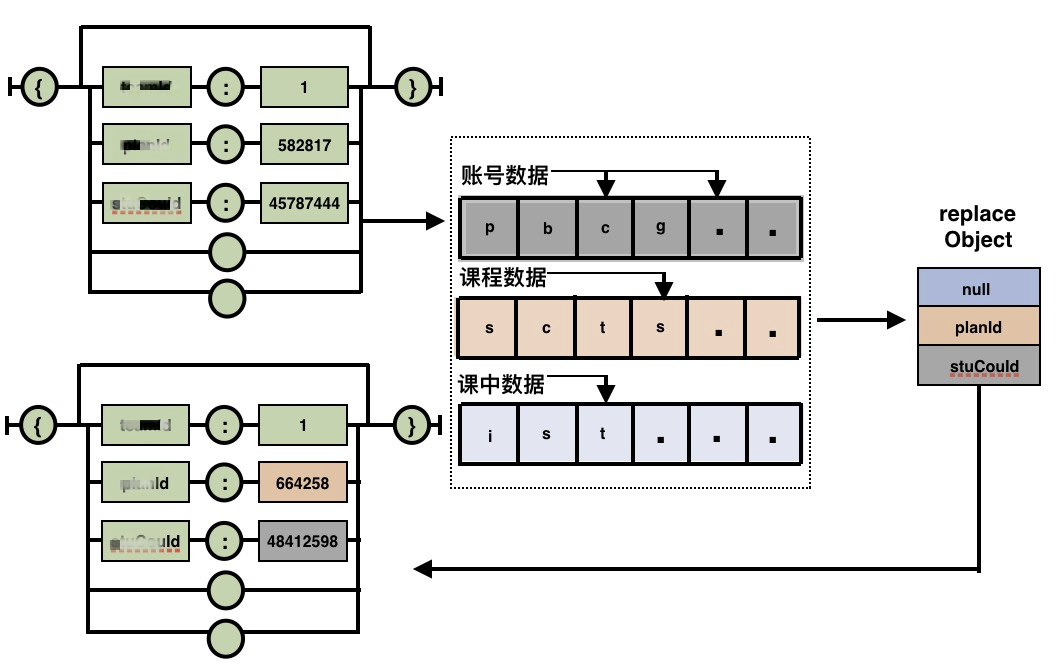
数据替换算法
成本曲线:数据模型方式 VS 传统自动化方式
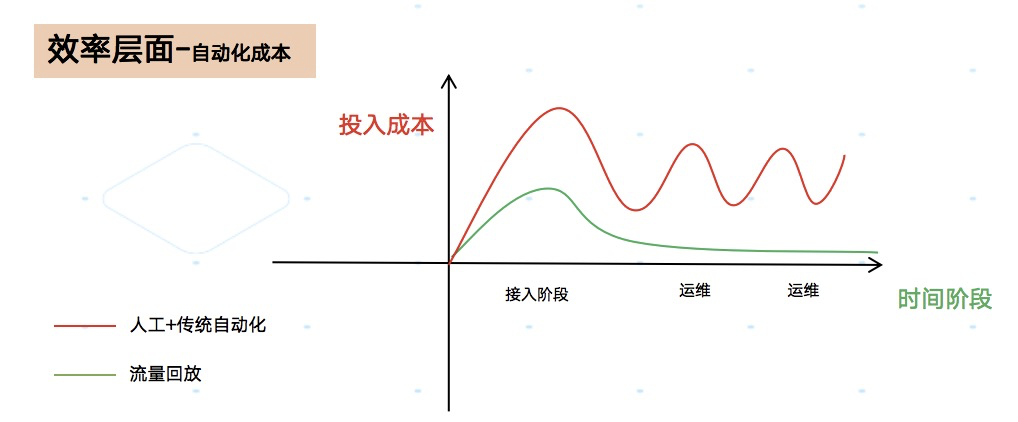
成本曲线
行业内在写场景方面也有其他实现
- 影子存储建设
- 框架层切面支持
- Mock 与沙箱环境
- 基于流量标识的业务改造
虽然通用的方案可以快速的落地降低项目组的开发成本,但却是阉割了流量回放本身要关注的质量保障问题,无论是回归测试与线上的健康巡检很多问题并非仅仅是代码层面的问题,所以全链路的方式就显得尤为重要,并且要兼顾到无需业务接入与业务改造的双重成本,这也就需要项目组成员有更高的业务理解力与开发压力。
3.流量回放的执行:
回放执行主要基于已处理好的流量数据进行服务施压,目前根据业务特性会进行线程控制以达到链路串联与执行效率的平衡。
面临挑战
- 上下游依赖数据如何透传
- 流量身份如何对应回放账号身份
- 如何维护数据生命周期
以网校的大班直播业务为例,具体方案如下
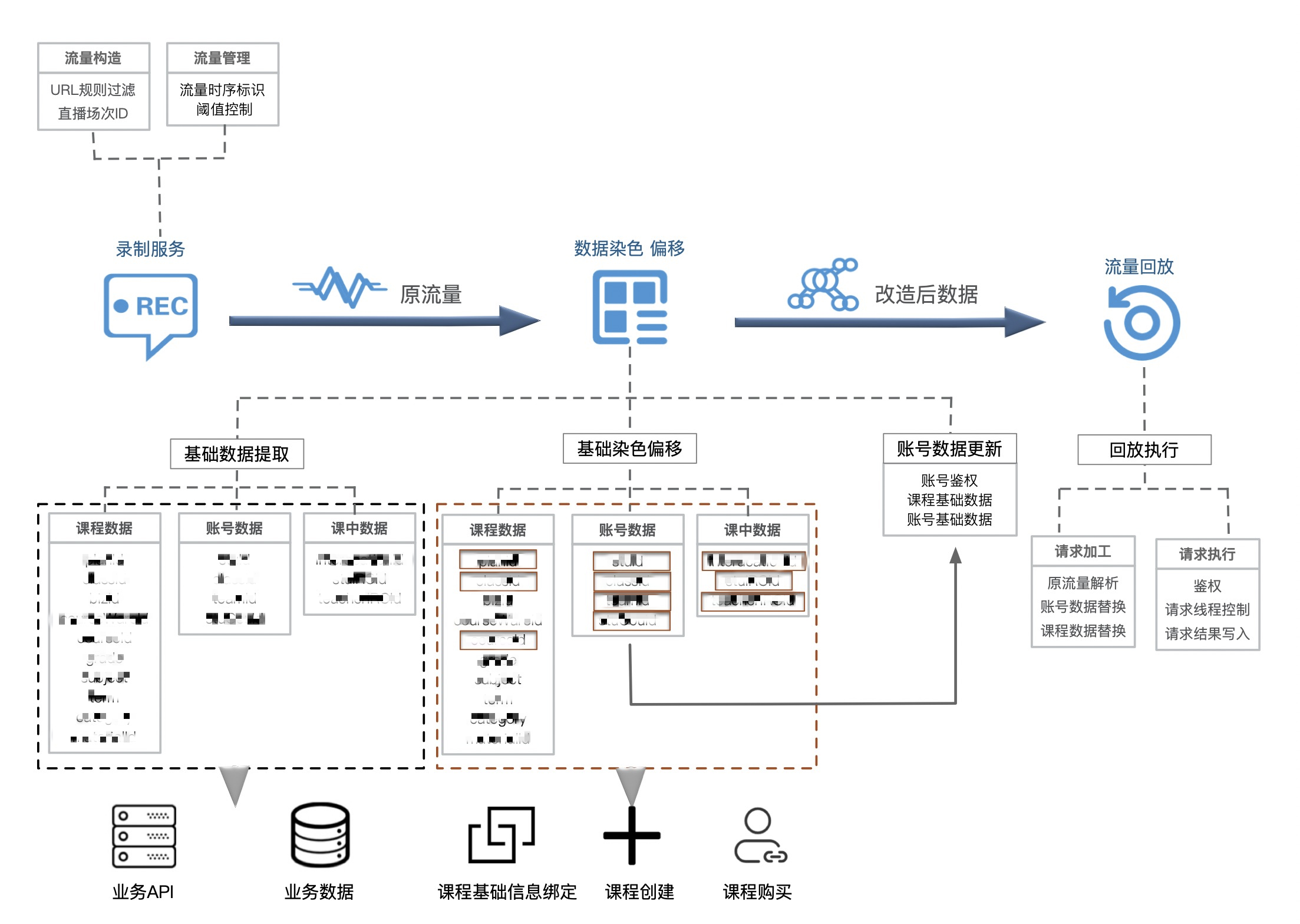
大班业务的回放数据流向
回放执行同时,结果的收集与校验同样是一个核心功能,通过对响应数据的各种判断与校验可以快速反应出被回放服务的健康状态,这部分工作类似于传统的接口测试,但海量的接口配置会为平台用户的使用带来极大的成本,所以项目组在简化配置中提供了极为便捷的功能。
提供能力
- 根据响应快速生成 JsonSchema,无需人工标记
- 相同开发规范接口统一校验规则配置
- 规则校验,降低配置错误风险
- 对于校验失败接口提供告警通知能力
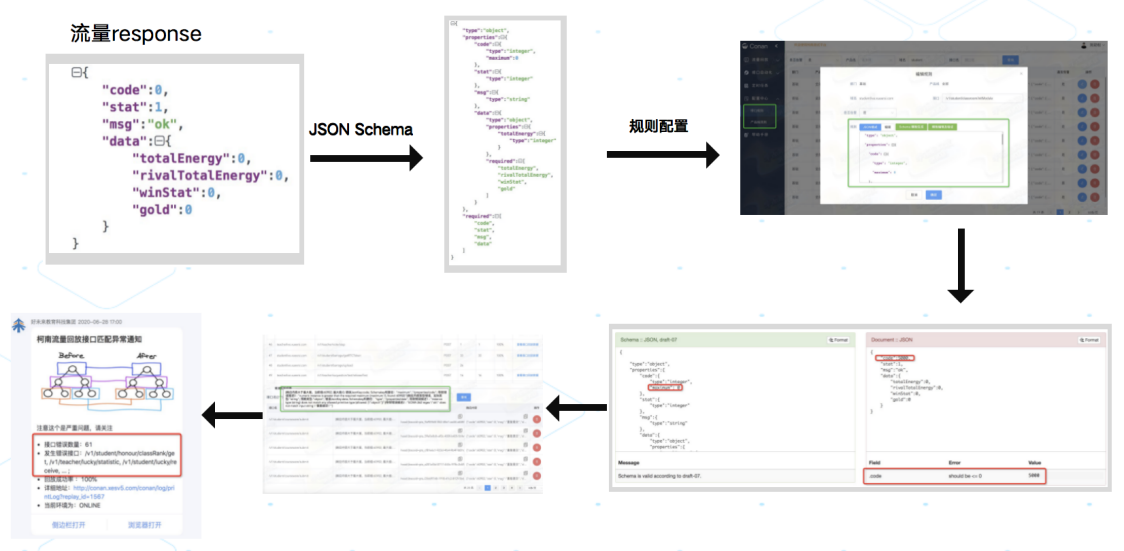
回放流程
4.流量比对服务:
Diff 能力是常用的质量保障手段,对于流量回放整体能力来讲同样极为重要,不同时间前提下下相同流量对服务发起请求当响应数据比对异常时就能反馈出当前服务的状态,这也是回归测试与线上巡检的常用做法,利用历史正常数据作为基准值可以大大降低人工干预带来的影响,同时对于历史异常结构信息可以分析归类,也为后续的流量异常计算积累起训练数据集。
面临挑战
- 流量响应值存在大量噪声(响应随机值,时间等)
- 比对规则多类型支持(结构化比对 ,忽略支持,数组型数据)
- 变更信息计算
- 海量结果的精准数据提取
基本逻辑
- 流量响应是一个组合结构,该结构常见形式为一个原子量与一个更小的同型结构组合而成;
- 数据的解结构可以通过原子量的解结构与更小规模的同型结构的解结构组合而成;
- 基于原子量的解处理同结构数据,异常结构数据的累积也可以作为后续计算的参考数据。
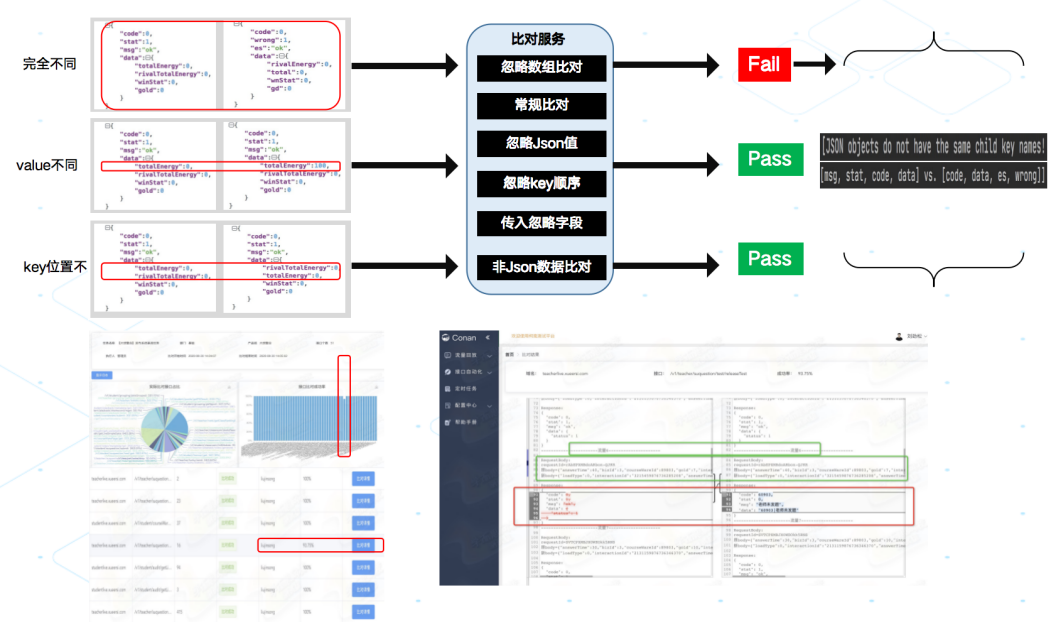
比对流程
当比对服务具备多种比对模式与降噪能力后,为了降低人工检查流量报告的成本,项目组在提供比对结果数据的基础上在报告中通过差异计算服务为用户量化了异常流量索引信息,异常字段,异常类型等数据,最终结果检查不在严重依赖于平台的使用。
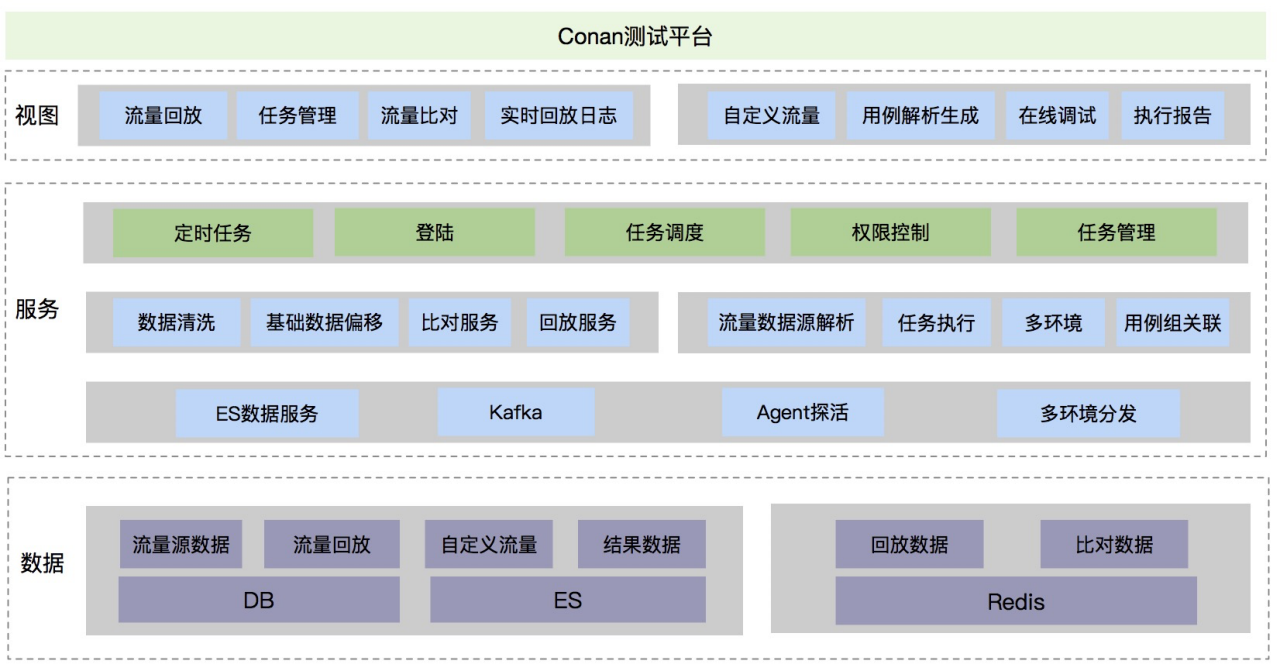
三、能力服务化,平台化
在面对业务越来越快速的升级迭代,基础能力服务化与平台化才能真正提升整体全流程的质效保障能力。
1.服务端架构
柯南平台作为以上能力的载体,除了流量回放的基础能力同时对外提供数据构造染色偏移,压测流量模型管理等其它服务,对于性能测试,接口测试,线上健康巡检,CI/CD 流水线集成等质量保障方式提供了稳定高效的基础支撑,合理使用可以迅速提升业务线的上层技术建设,同时对于各产品线业务&流量模型的快速生成能够帮助工程师群体理解不同业务特性并且形成技术方案。
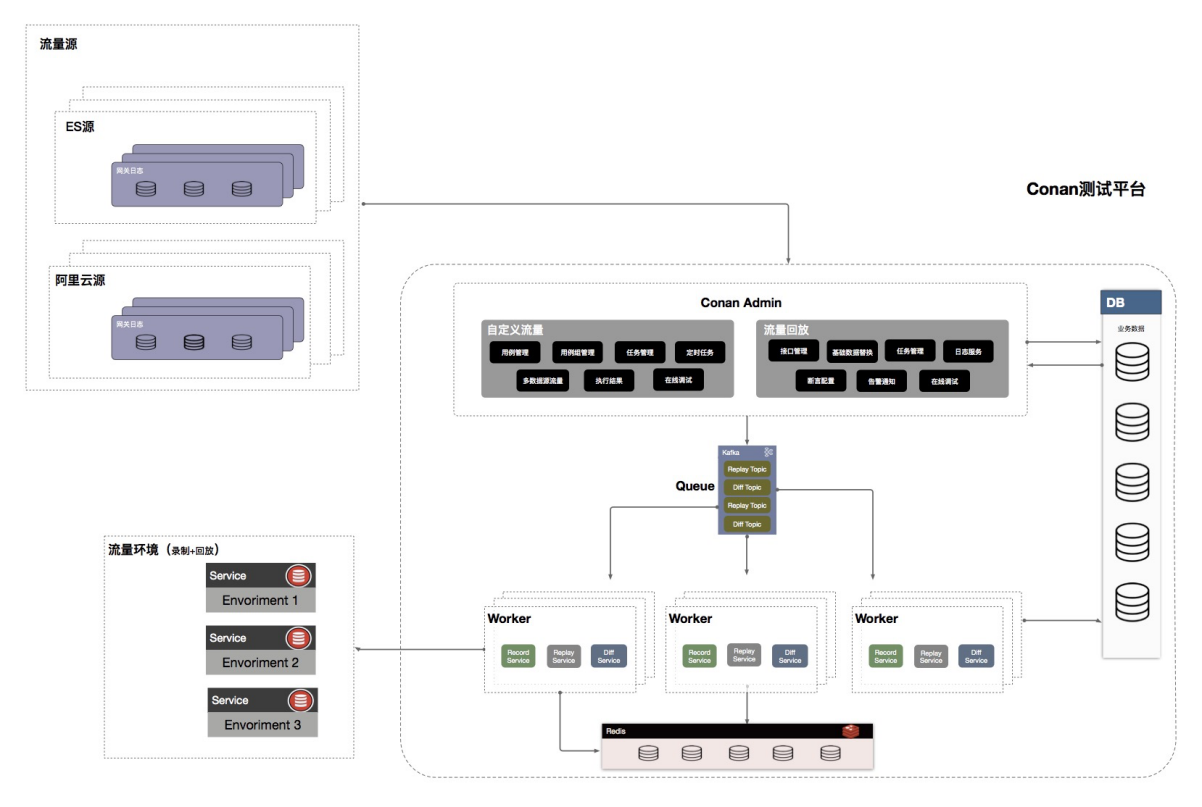
服务端架构
对于的线上流量的处理 + 多种类型任务的组合 + 对接集团多事业部 + 中台属性多种角色与性能开销考验着后端整体的架构,为了保证后端服务的稳定性柯南平台后端采用分布式架构,架构中 master 节点的任务下发与 worker 节点的状态管理依赖于一套简单的负载均衡服务,master 节点会根据各 worker 节点在注册中心记录的状态进行任务分发以达到高效利用机器资源,同时基于 K8s 可以动态调节 woker 机器,每一个 pod 对应一个 worker 节点,这个方案提升了柯南平台整体的稳定性与高可用,同时提供了一定的灾备能力。
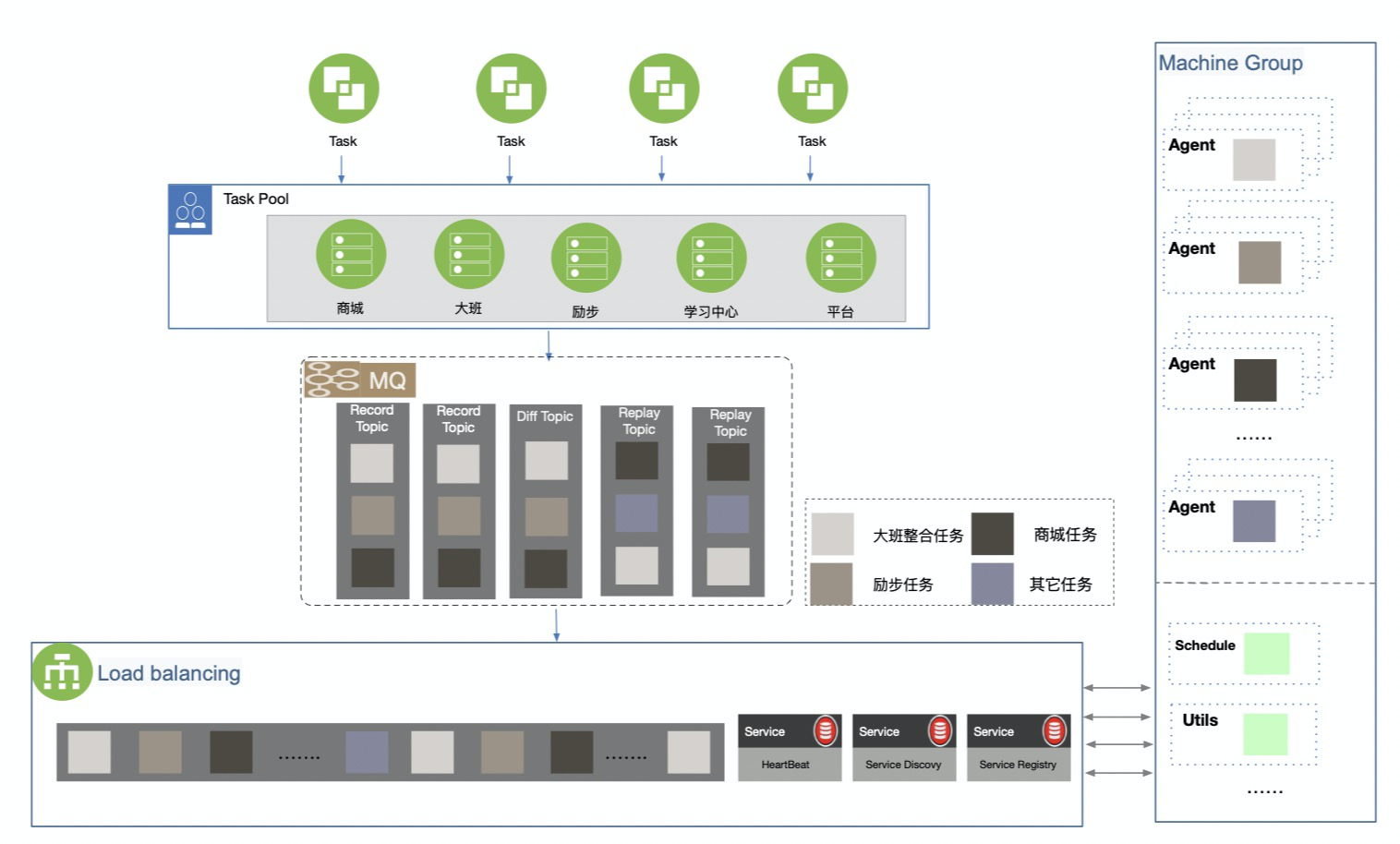
负载均衡
业务架构
2.基于线上流量的压力模型与数据
作为集团中台的两个项目柯南与 PTS 也在性能方面进行了技术共建能力互补,目前在网校核心直播业务中已完成基于线上真实压力模型与流量数据模型的性能保障方案实施,与原有的全链路压测方案相比这一套方案能够完美的弥补场景失真与压测数据构造维护的问题,同时提供模型放大等服务以适应不同性能预期的需求,目前已在大班业务中试运行。
真实流量模型方案
3.其他平台化能力
除了以上重点介绍的能力,柯南平台也同时兼备了技术类后台的一些基本能力,通过简单的交互降低整体的使用成本。
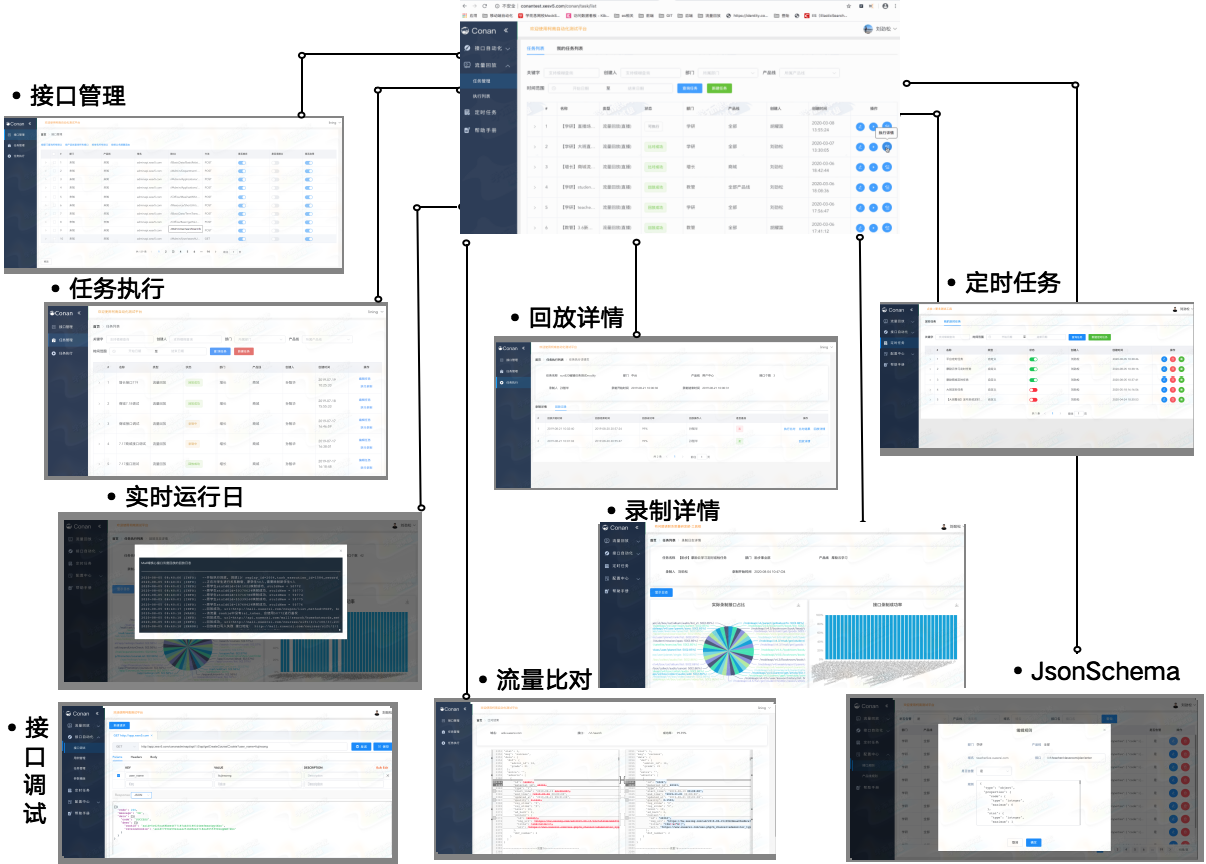
其他能力
基于线上流量的业务赋能整体架构

整体架构
四、应用场景
1.持续测试能力
发布环节作为持续测试能力的核心服务,为日常的服务段发布提供高效的回归测试能力,为底层依赖与组件升级的项目提供更高覆盖度的保障,同时提供了线上巡检的基础能力。

发布环节回归
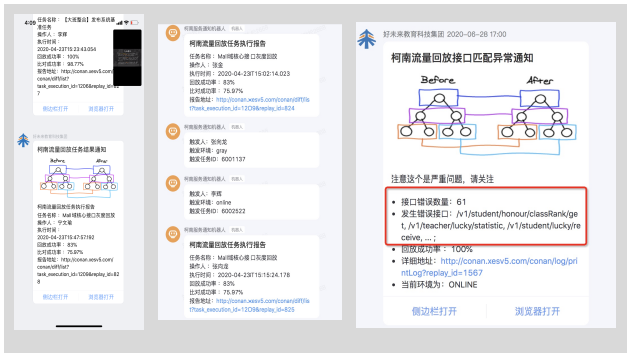
结果通知
2.性能测试联动
性能测试方面为 PTS 提供线上真实压力模型与压测数据,同时支持模型数据的等比放大,性能测试中存在大量的接口链路依赖关系,在数据染色偏移中会根据调用关系维护链路数据并且执行部分依赖前置操作,从而保证数据层面的高可用,除了提供前端操作同时为用户提供 OpenAPI 以便于为用户带来更多应用场景。
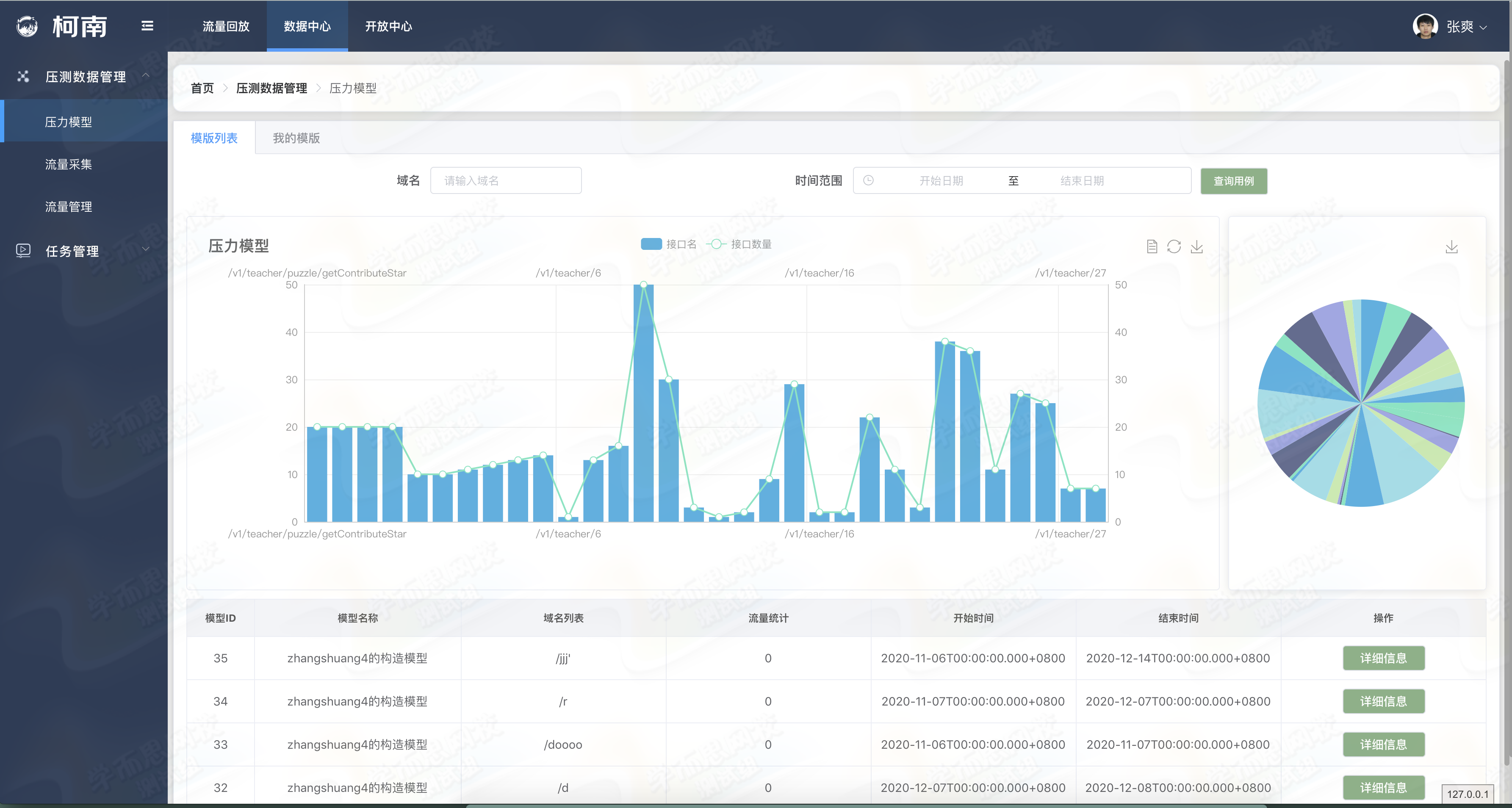
压力模型图示
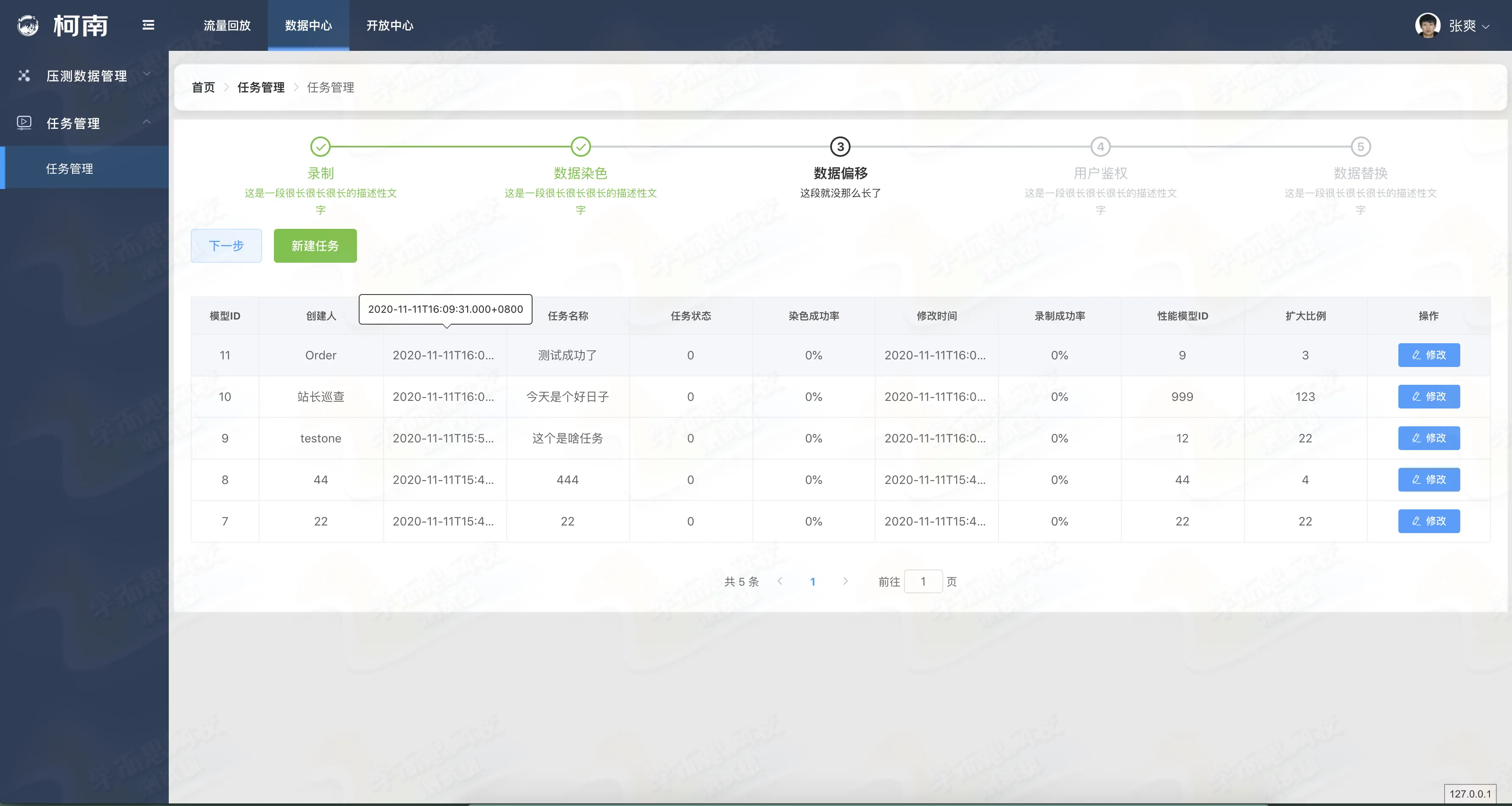
流量数据采集染色流程
3.常规业务保障
在常规的业务保障中柯南平台同样提供了对应的能力,对于已完成全场景接入的业务线,通过业务模型结合流量采集处理可以为 QA,RD 提供大量的线上真实流量去辅助测试,同样可以帮助传统自动化迅速转型以适应频繁的业务变动与数据的不可复用行等核心痛点。
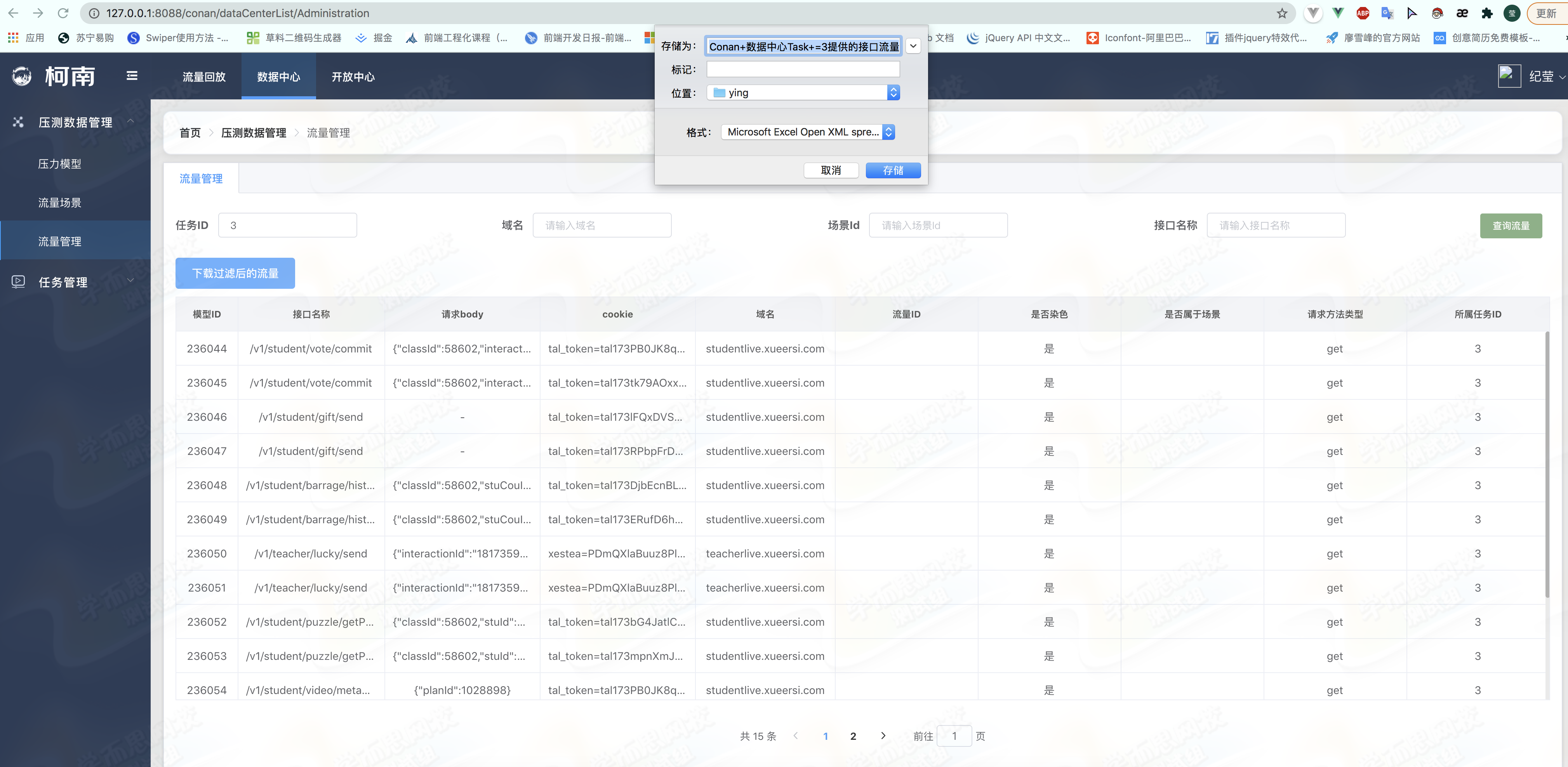
离线数据下载
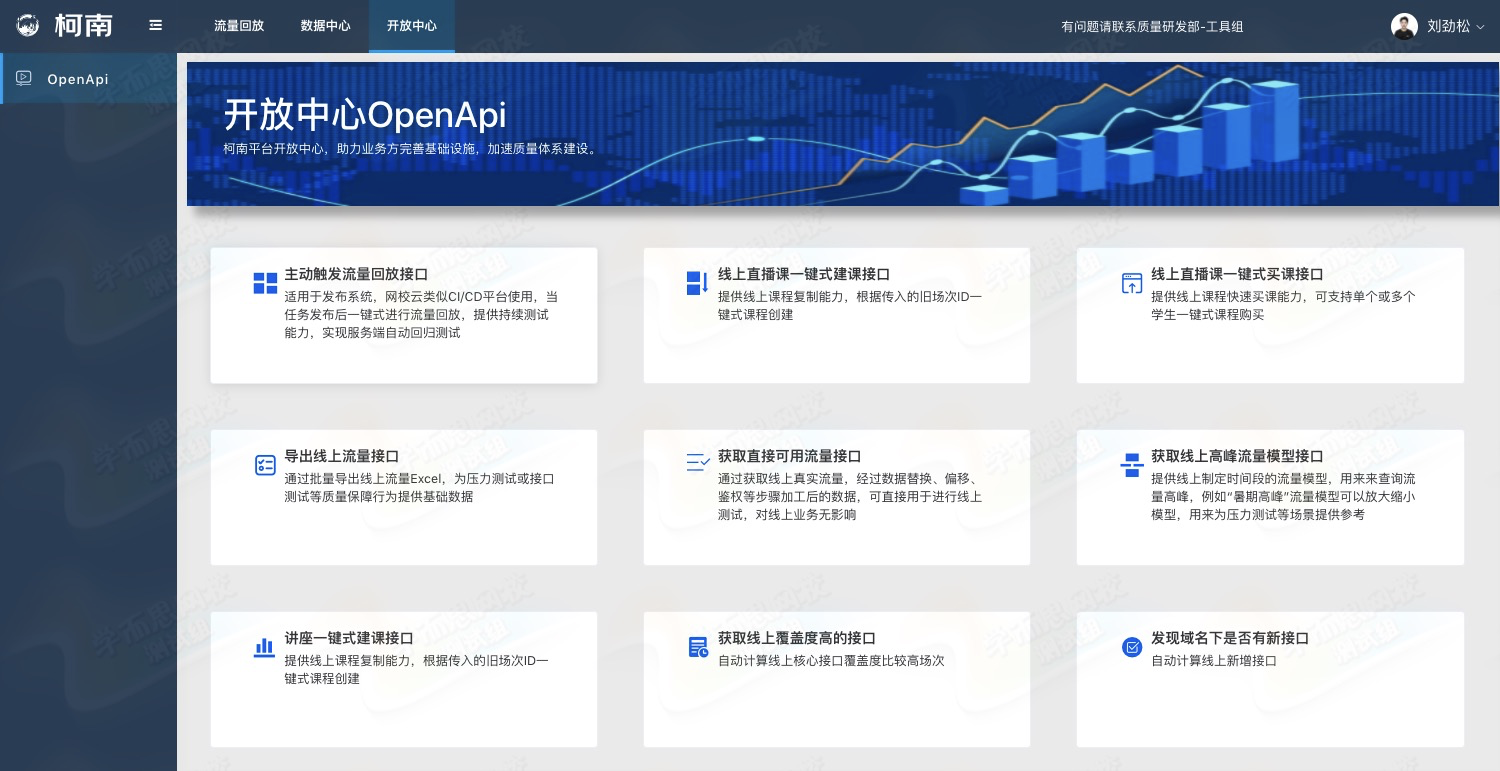
开放中心 OpenAPI 模块
五、写在最后
质效的提升也许不能单单通过一个平台,技术与人的结合才能带来更大的突破。善于利用技术创新才能从容的面对越来越频繁的需求,越来越复杂的业务,期待与更多行业内伙伴共同打造行业优秀实践,解决通用问题。
项目官网
https://tal-tech.github.io/conan/
Github
https://github.com/tal-tech/conan
好未来 - 技术中台 - 柯南项目组
好未来 - 学而思网校-ep 团队 - 柯南项目组
项目负责人
刘劲松

项目成员
邓坤楠 纪莹 张永鑫 胡耀国