背景:
在公司 C2B2C 的这种业务模式中,C2B 回收流程用户下单的预估价、精准估价、最终质检完成的回收价格、通过天路 B2C 或者 B2B 进入到各个卖场的价格大部分都需要由估价器来提供,在整个业务场景中,估价器系统的稳定性以及给出价格的准确性、可靠性就至关重要了。

估价器系统实现主要有映射关系、公式计算、算法策略等,在测试中主要关注的点有映射逻辑、公式计算、业务逻辑、异常处理、价格的准确度等。
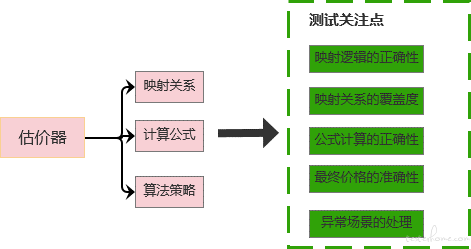
估价器系统中存在很多映射关系,比如:把 sku 的属性映射成估价器所能识别的属性 ,如质检项、估计项的映射;估价项、估价等级的映射;等级、等级价格的映射等等。测试估价的过程一大部分就是对这些映射关系进行测试,初期测试手段主要是通过手动筛选映射关系模板,人工核对代码的输出结果跟筛选的结果是否一致,工作量比较大,重复性强。
目标:
重复的事情简单做,繁琐的事情用心做!
怎么能把重复的事情简单做呢,我们进行了估价器测试方案的讨论,刚开始讨论,我们想到的思路是 QA 自己去写一套代码逻辑,来实现开发实现的效果,这样对于 QA 来说能力和时间都是一个挑战 而且还要后期去迭代,最终被 pass 掉了;那么换一种思路,我们能不能把手动执行的过程通过自动化执行的方式去实现呢,比如手动筛选 excel 的过程是否可以通过自动筛选;比对结果是否可以通过其他手段自动比对呢?如果可以通过自动的方式来实现,那么对于新人来说来测试估价器的需求可以快速的上手,同时也可以同步到团队其他同学,提供工作效率。
调研:
1、常用的两种 excel 的数据筛选模式:
- (1)使用 excel 的函数
- (2)通过 pandas 进行数据分析
2、分析优缺点:
- (1)使用 excel 函数,优点:比较方便;缺点:不利于共享和复用;
- (2)使用 pandas,pandas 是 python 语言的扩展程序库,优点:提供了大量能使我们快速便捷地处理数据的函数和方法 ,python 脚本方便集成平台,大家共享和复用;缺点:需要编写 python 脚本;
既然是一个工具,做到大家都可以使用,那么我们就要考虑更多扩展性和适用性,故选择了第二种模式来实现。
实现:
1、实现思路:
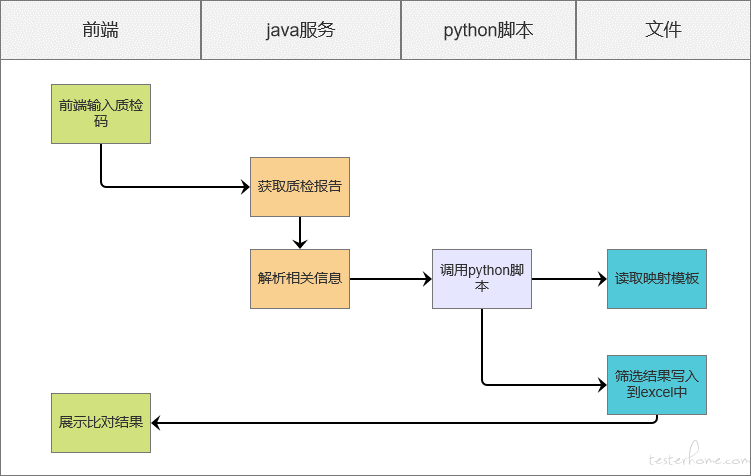
2、实现过程:
(1)python 需要导入的类库
import pandas as pd
import numpy as np
(2)pandas 常用的函数:
- 读取 excel:read_excel
py spu_sku_template_excel = pd.read_excel('C:/Users/Administrator/Downloads/spu_sku映射.xlsx',sheet_name="SKU属性映射模板",dtype={'外部参数值Id(若有多个请使用+分隔)':np.str_}) - 筛选:loc
# “等于” 条件筛选
level_price_item = level_price_template.loc[level_price_template['型号'] == model_name]
- “包含” 条件筛选
py foreign_template_item = foreign_template_excel.loc[foreign_template_excel['外部检测值id'].isin(foreign_id)] - 写入 excel:ExcelWriter
py valuation_item_result_writer = pd.ExcelWriter('C:/Users/Administrator/Downloads/估价项列表导出筛选结果_数码.xlsx') valuation_item_result_df.to_excel(valuation_item_result_writer,sheet_name='筛选之后的',index=False) valuation_item_result_writer.close()
(3)pandas 常用的数据结构,对筛选结果进行处理:
- Series:类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型
比方说:获取 “运存容量” 这一列
#运存容量 list
sku_capacity_list = sku_template_result['运存容量']
sku_capacity_series = pd.Series(sku_capacity_list.values).drop_duplicates()
- DataFrame:一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)
比方说:
#2.根据估价项三级id筛选excel
valuation_item_result_df = valuation_item_excel.loc[valuation_item_excel['3级类id'].isin(foreign_template_item_result_arr)];
valuation_item_result_df = pd.DataFrame(valuation_item_result_df.values)
valuation_item_result_df.columns = valuation_item_excel.columns
3、实现效果:
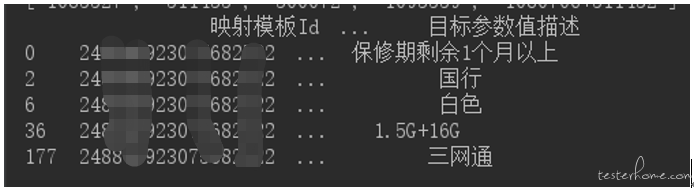
如:质检报告中 sku 以及对于的 key 值是这些:
sku_list = ['10*27','5135','372','1006','5132','109*59']
sku_key_list = ['7*8','62','5587','101','71','7**0']
python 脚本中通过筛选结果为:
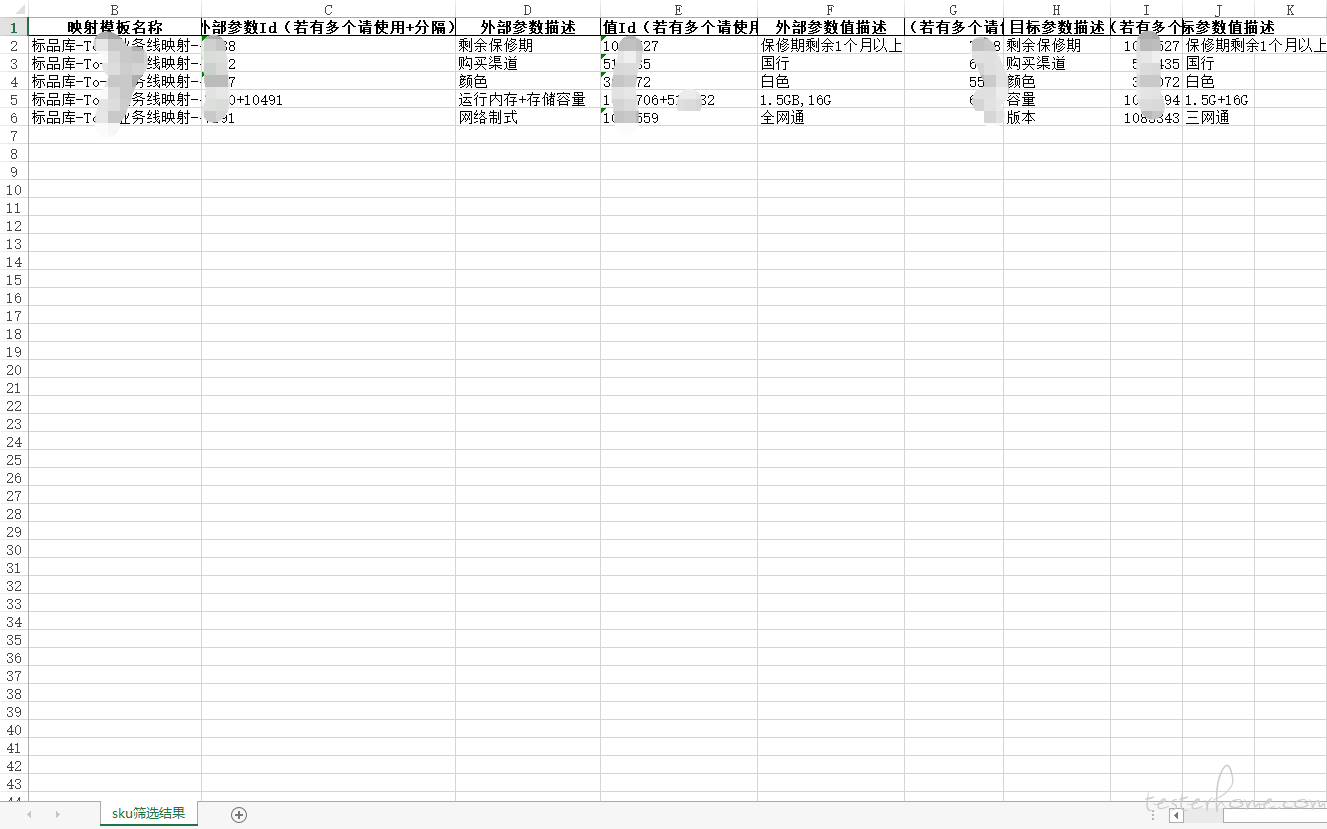
写入到 excel 中结果为:
4、落地效果:
按照原来的模式,一个估价的 case 手动筛选 excel(6 个 excel 模板)的过程大概需要 10 分钟,在估价器接入新品类和新质检的项目中,我们通过自动筛选的方式,需要不到 1 分钟的时间,大大缩短了人工筛选匹配所投入的精力,提高了覆盖率和准确性。
5、后期完善内容:
(1)提供更好的交互,通过前端页面将比对结果进行展示,推广使用;
(2)目前为手动下载 excel 映射关系,可以根据条件自动下载 excel。
总结
在平时业务测试过程中,总是会遇到相同的业务反复测试,总是会遇到重复的动作反复执行,如何践行 “复杂的事情简单做,繁琐的事情用心做”,提高测试效率,也是一名 QA 成长之路必备的能力之一。
如果喜欢我们的文章,请微信公众号搜索 “转转 QA”,关注我们吧~