问答 对于接口自动化的疑惑
自学接口自动化有一段时间了,这段时间也浏览了包括 TesterHome、csdn 等社区里面很多大佬的文章,接口入门就是看的 liuchunming033 大佬的那篇万字长文入门篇,现在写的代码也是偏向这个风格。但是看了很多大佬写的文章后,了解到了很多接口方面的新名词,这些名词让我对接口自动化产生了陌生感。举个例子:我看大佬们都说用例之间不能相互影响,然而我写的是:查询接口获取的 id 直接用于修改等需要 id 参数的接口上面。然后我就根据用例之间不能相互影响这个规则去修改自己的代码结构,改着改着发现这个修改接口的 id 只能通过数据库创建,然而对于我这个平时 80% 时间功能,10% 划水,10% 被叫去干苦力的点点点人员来说,没权限去操作数据库。这时我浏览社区看到了个新名词:混合业务接口测试,但是这个混合业务接口测试,我的理解就是和上游接口之间产生了依赖。不太清楚之后的自动化该怎么走了,浏览其他大佬写的开源代码,基本上看不懂,感觉自动化越学越迷茫,下面是我写的代码的截图,有大佬能指导下接下来我该怎么优化、怎么走么?
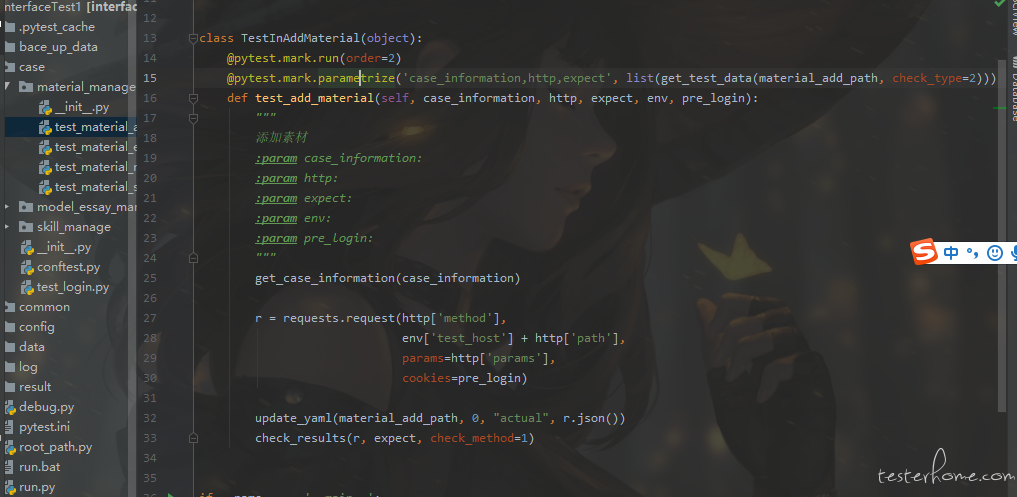
你好,我也是看的刘春明大佬的博客,说说我的做法 (应该也是目前比较普遍的做法),将每个接口的响应结果存起来 (我存在了一个 dict 中) 对于需要依赖的参数 通过 用例的自定义语法糖 (我的用例用 excel 管理所以读取出来是字符串类型,然后去替换用例中的语法糖标识,其中这个标识可以从之前的响应字典中直接通过提取 json/dict 的方式把对应的 id 取出来),https://www.cnblogs.com/zy7y/p/14022398.html 希望对你有所帮助,加油!
我想问一下,这样做的话,如果这个接口出现了问题,依赖于这个接口的其他接口不也会失败么?然而我百度看了看接口自动化说是有几个准则,其中之一就是单个用例要能独立运行,这最近又看到了这个业务流程接口测试,就感觉很懵逼,究竟哪个才是能应用于实际项目的规范的接口自动化呢?
你好,“其中之一就是单个用例要能独立运行” 这个的意思其实是每个用例不能依赖于其他的用例,但是用例本身就是由许多步骤(等于接口)组成的,所以单个用例中调用到多个不同的接口是必然的,这和 “其中之一就是单个用例要能独立运行” 并不冲突,至于你说的另外一个接口失败的依赖于这个接口的用例失败是必然的吧
我认为你把这个依赖的部分算做前置条件即可,如功能用例登录,一般会在前置条件写明可用的账号/密码,操作步骤中再一步步输入,既然是前置条件 你是需要保证他不会出问题的,再换种说法你也不用去动态获取这个依赖的 id 了,你接口入参直接写死一个 id 的值 (表面上看你这用例就不冲突了,这样从操作者角度来看你这业务链没拉起来,一直都是同一个 id)
楼主应该混淆了单个用例独立运行和单个接口独立运行的概念,所以产生了这样的疑惑
实际测试中一个用例关联多个接口是很正常的现象,这是业务决定的
我现在是这样子搞:
保证每一条用例执行,都不会有影响。
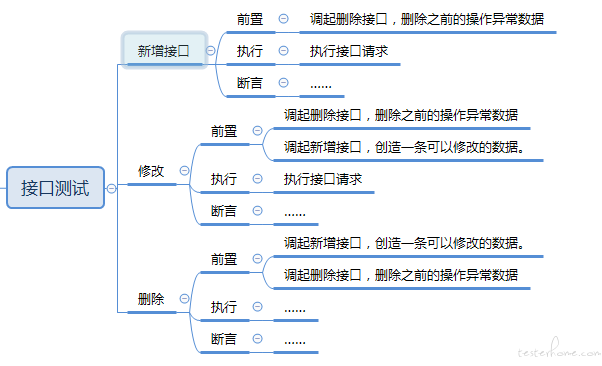
也就是说当前用例依赖于上个接口而不是上个用例,所以我需要在当前用例执行前重新执行所依赖的接口而不是直接用之前该接口所配套的用例产生的数据对么?
其实我认为,本身你测试有一条正常 (百分百成功) 的测试用例,而且能够返回你所需要的值,下个接口要用可以直接取,另一种就相当于执行需要 id 这个用例的时候本身调了 2 个接口,最终都是把返回 id 的接口 (该接口务必正常返回内容),然后取到 id 放到需要 id 的接口中
个人理解:用例之间不能相互影响,后面用例需要的参数不能依赖于前面的某个用例,这个是必须的,否则耦合性高维护代价自然高;如果需要测试某接口,该接口需要指定数据,方法有二:1.将依赖接口作为前置条件来请求,获取想要的数据;2.从数据库层面操作(我没有涉及过,但是应该可以)
可以依赖接口,但是不能依赖用例,虽然是这么说的。但是对于大佬说的第一个方法:将依赖接口作为前置条件来请求,获取想要的数据。再次调用该接口来获取响应数据和直接用上个用例的响应数据,我怎么感觉前者的耦合性更高呢。例如:该接口依赖于上个个接口的返回数据,按照前者的话,我需要上个接口重新请求获取的返回值,但是如果上个接口同样依赖于别的接口,那么我需要在上个接口去调用它所依赖的接口。同样的情况按照后者,我直接用上个接口的用例执行完成获取的返回值,这样难道步骤不会更加简略么?(用例数据不会出错的情况下)
目前来说,我用的就是该接口所依赖的数据就是来源于上个用例的返回数据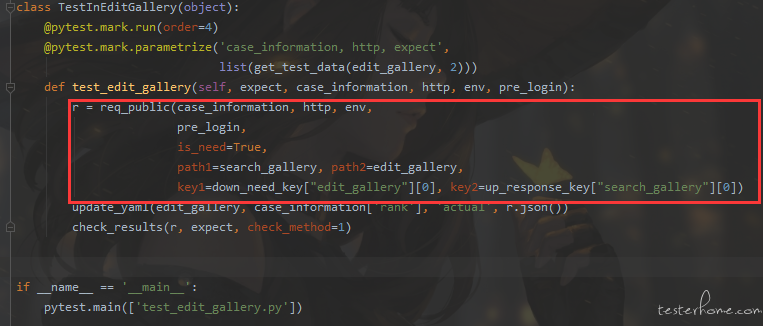
但是如果说需要重新请求上个接口来获取返回数据应用于该接口的话,我需要在该模块下添加 conftest.py,并在其中添加方法去获取该接口依赖的数据,如果存在依赖多的情况下,conftest 中的代码量会比我现在写的多的多。
建议别定义这么多中间函数,像这样平铺写法不是更直白么:
多个接口 -- 增删改查
import jmespath
from loguru import logger
from tep.client import request
def test(faker_ch, login, url):
fake = faker_ch
logger.info("新增")
nickname = fake.name()
phone = fake.phone_number()
response = request(
"post",
url=url("/api/users"),
headers=login.jwt_headers,
json={
"nickname": nickname, "phone": phone
}
)
assert response.status_code < 400
user_id = jmespath.search("id", response.json())
created_at = jmespath.search("createdAt", response.json())
updated_at = jmespath.search("updatedAt", response.json())
logger.info("查询")
response = request(
"get",
url=url("/api/users"),
headers=login.jwt_headers,
params={
"page": 1,
"perPage": 10,
"keyword": nickname
}
)
assert response.status_code < 400
logger.info("修改")
nickname_new = fake.name()
phone_new = fake.phone_number()
response = request(
"put",
url=url(f"/api/users/{user_id}"),
headers=login.jwt_headers,
json={
"id": user_id, "createdAt": created_at, "updatedAt": updated_at,
"phone": phone_new, "nickname": nickname_new
}
)
assert response.status_code < 400
logger.info(f"用户姓名手机 {nickname} {phone} 修改后 {nickname_new} {phone_new}")
logger.info("删除")
response = request(
"delete",
url=url(f"/api/users/{user_id}"),
headers=login.jwt_headers
)
assert response.status_code < 400
比如check_results(r, expect, check_method=1),check_method=1是什么意思并不清楚。你截图出来的这部分代码,看不到用例是如何组织的,也不知道为什么再调一次接口,还需要在 conftest.py 增加很多代码。如果能重新组织下用例,也许你的疑惑会迎刃而解。
一条自动化用例可以包含多个接口,上个接口的数据应用到下个接口是很正常的,可以了解下 JMeter 的 “关联”。
接口自动化本质上是用接口重新做一次手动执行的用例,只是方式变了下而已。如果 1 条用例是走主流程,相应的接口自动化用例,会包含主流程涉及到的所有接口。如果 1 条用例是某个模块的特定场景,那么就会涉及到这个模块的接口。
同一个接口,一般会重复存在于多条自动化用例中。如果复用率很高,可以抽出来,如果复用率不高,或者参数差异比较大,保留一定冗余,提高可读性和共享性,也是可以的。没有必要为了封装而封装。
 我在 check_results 方法中加了注释,本来想在 case 中加,看了下加的话每个 py 都得加,就懒得加了。is_need 就是判断是否需要上个用例的返回数据,同样是方法中加了。。
我在 check_results 方法中加了注释,本来想在 case 中加,看了下加的话每个 py 都得加,就懒得加了。is_need 就是判断是否需要上个用例的返回数据,同样是方法中加了。。
为什么还需要有个 is_need 判断是否需要上个用例的返回数据?
首先,你看到文章都不错。用例都是必须能独立运行的。但是有一点,用例又分单接口用例和业务用例。所以这里我们要区别对待,单接口用例互不影响,类似 postman。业务用例就会出现参数传递的情况,类似 jmeter。现在开源是平台框架都是为了简单。把单接口用例这个概念去掉了。所以这个要看自己的理解。我接下来的接口自动化的设计,我会将这两种用例区分出来,这样才不会搞混,实际情况下,业务用例是极少的。希望我的回答能帮助解答你的疑惑
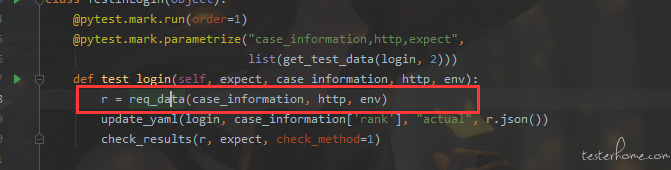
可以依赖接口,但是不能依赖用例,虽然是这么说的。但是对于大佬说的第一个方法:将依赖接口作为前置条件来请求,获取想要的数据。再次调用该接口来获取响应数据和直接用上个用例的响应数据,我怎么感觉前者的耦合性更高呢。例如:该接口依赖于上个个接口的返回数据,按照前者的话,我需要上个接口重新请求获取的返回值,但是如果上个接口同样依赖于别的接口,那么我需要在上个接口去调用它所依赖的接口。同样的情况按照后者,我直接用上个接口的用例执行完成获取的返回值,这样难道步骤不会更加简略么?(用例数据不会出错的情况下)
楼主问题解决了吗