研发效能 流量回放框架 jvm-sandbox-repeater 实践二
前文链接:流量回放框架 jvm-sandbox-repeater 的实践
1.前言
前文中,我们已经介绍了 jvm-sandbox-repeater 的原理,以及我们对它的初步实践。本文将进一步介绍我们目前的平台化实践工作。我们将该平台称为 kurepeater。篇幅限制,这里主要介绍下 kurepeater 的基本架构和录制回放的优化设计。
2.基本架构
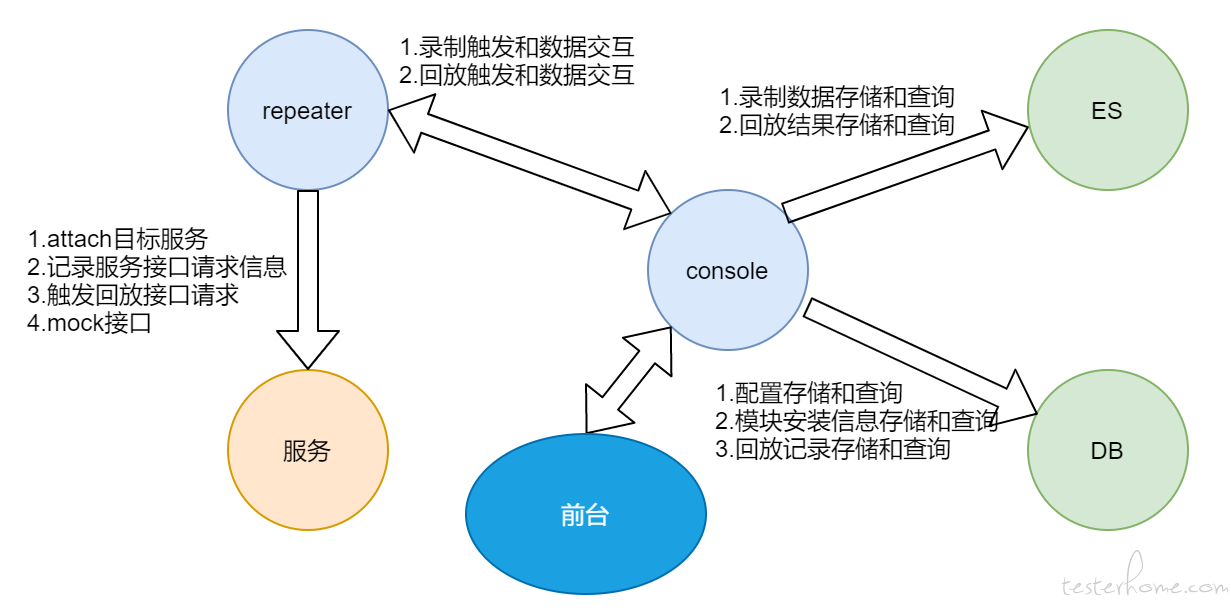
kurepeater 主要由 repeater(jvm-sandbox-repeater)、console、es、db、前台页面 5 部分组成。前端页面结构参考了官方 demon 并结合实际需要进行设计,采用公司内部框架进行开发;后台基于官方开源代码,并进行一些定制化的改造。
前台页面只和 console 进行交互,console 操控整个流程。各模块间交互关系如下图所示。
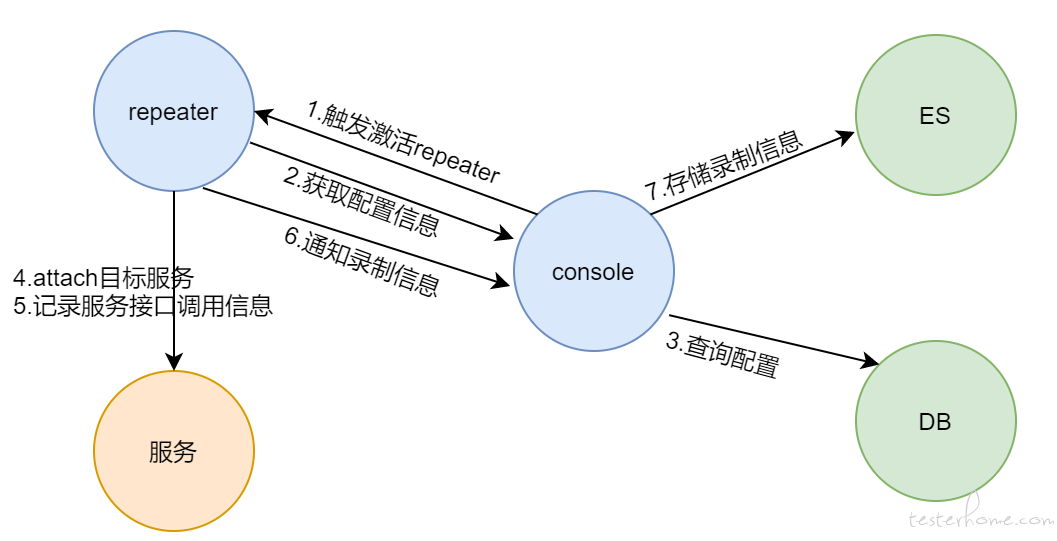
要启动 repeater 进行录制时,需先从前台进行配置和模块安装。配置我们存储在了 DB 里面。模块安装负责将 jvm-sandbox-repeater 安装到目标服务器上。点击激活,启动和录制流程如下图。录制数据序列化后存入 es。
录制结束,可以在前台选择需要回放的流量和方式,通知 console。后台回放流程如下。

回放成功后,我们可以在前台页面查看回放结果数据,成功失败信息,并对失败接口进行排查。
3.录制优化
平台化后,使用 kurepater 平台对流量进行录制,特别是线上环境,遇到了如下两个问题
1)有些接口不想录制怎么办
2)线上各接口流量严重不均衡,高频接口录制了一堆,低频接口可能一次都没录到
对于问题 1,一开始我们在白名单 httpEntrancePatterns 里面写正则过滤这些接口,比如^ ((?!/error$)).*$,然后重新启动服务。但是频繁的修改 httpEntrancePatterns 和重启服务比较麻烦,另外正则配置在辨识度和易用性上也存在一定的困难。为此,我们增加了黑名单 blackEntrancePatterns 过滤功能。与 httpEntrancePatterns 相对应,在 blackEntrancePatterns 中的接口都不录制。blackEntrancePatterns 优先级高于 httpEntrancePatterns。
对于问题 2,其中一种解决办法就是当某个接口录制的量太大了,我们就把这个接口加进黑名单,然后重新激活服务继续录制。如此循环,确保高频接口量不至于太多,低频接口也有录制到。当要录制的接口比较少时,这种方法还行。但当要录制大量接口时,这种操作就有点繁琐尴尬了,所以最好是一开始就根据不同的接口 qps 赋予接口级别采样率。
为此,我们在官方实现的 http 插件里面加了点代码,大致如下

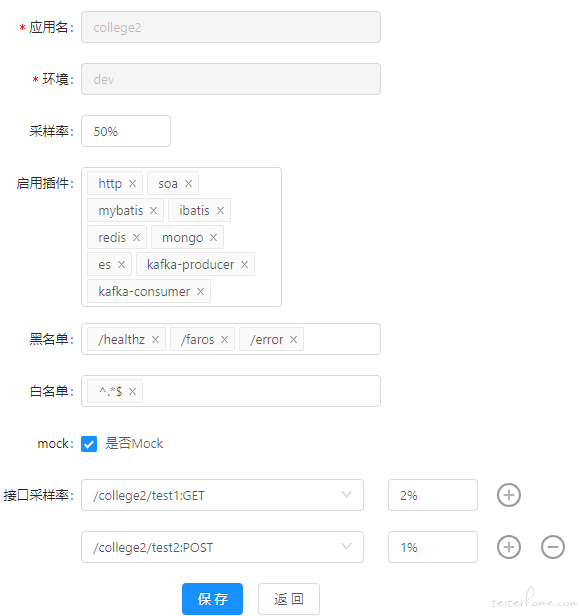
前端配置界面如下。第一个采样率是统一的采样率,供所有需要录制但是没有特别强调接口采样率的接口使用。console 里面的配置读存也做了修改。
4.回放优化
录制流量后对流量进行回放,发现回放结果比对失败的很多。经过对失败原因进行排查和统计,发现有些是真的新代码有 bug 导致的失败,但更多的失败并不是代码 bug,例如
1)代码修改,修改了子调用,导致 mock 失败
2)有不支持的子调用,导致失败
3)子调用有随机参数相关,导致 mock 匹配不上
4)响应的内容用了随机数或者时间相关参数,导致比对失败
5)repeater 代码缺陷
还有一些其它原因,这里不一一赘述。失败原因很多,真正有效的失败数很少。如此一来,每次回放失败的排查成本就非常高,这违背了我们的初衷,也给平台的内部推广带来了困难。我们迫切期望过滤无效的失败,节约不必要的排查时间。
4.1 diffy 降噪
为了提高回放结果失败的有效性,我们先尝试了过滤字段功能,diff 校验时对某些字段不进行校验。
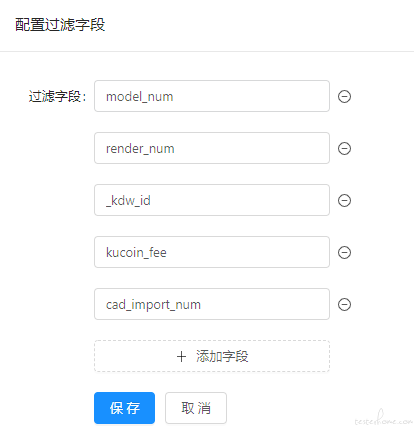
这种方案对单接口回放测试时比较有效。但是他只针对上述常见失败原因的第 4 条。而且如果想批量回归某个服务的所有接口,加之服务接口增加和迭代,使用起来就会比较麻烦。我们还是需要一种可以智能降噪的方式。为此我们使用了 diffy 工具来进行降噪。
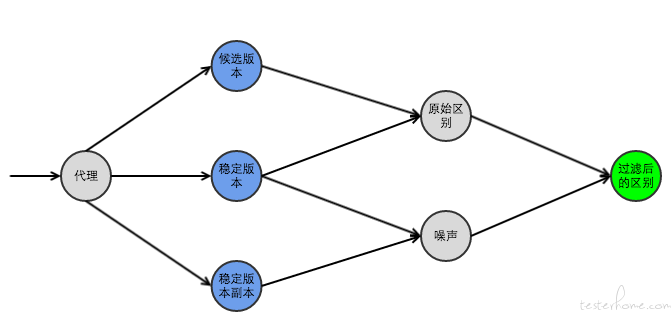
diffy 能够通过比较 candidate(候选版本)和 primary(稳定版本)和 secondary(稳定版本副本)的差异值来消除噪声,得到最终的 diff 结果。原理如下图,具体介绍网上很多,这里不仔细介绍。
我们在 diffy 开源代码的基础上做了修改,提供了如下接口功能。如下图,此时 left 传的是回放目标服务的响应,right 传的是录制服务的响应,right2 传的是降噪服务的响应。
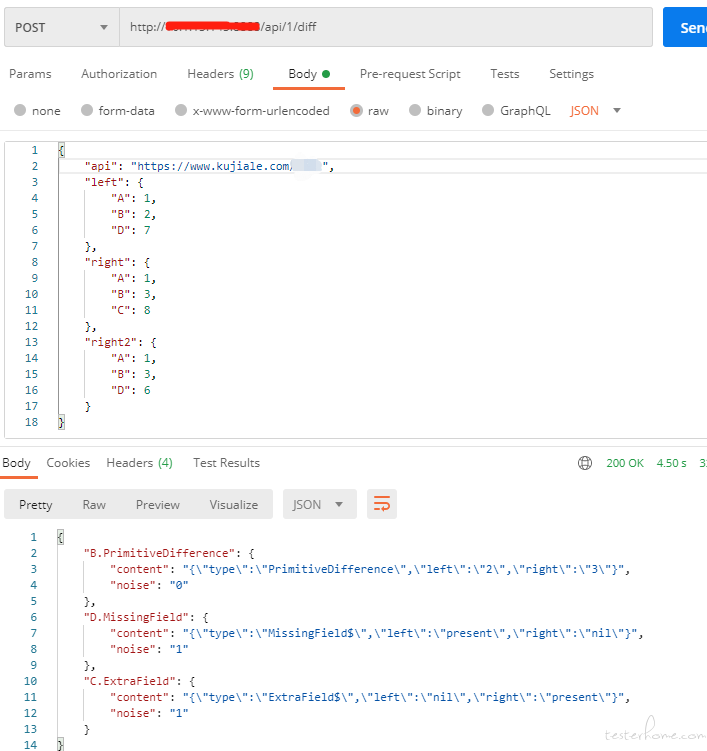
可以看到,接口请求 diffy 告诉我们 BCD 三个字段的响应值不同。其中 C 和 D 字段 noise 为 1,表示在降噪环境回放也是不对的,不具备比较和排查意义,只有 B 这个字段需要排查。
所以假如我们在线上环境 (prod) 进行了流量录制,欲要回放到开发环境 (dev),不妨使用一个线下稳定环境 (stable) 进行降噪。将三个环境的响应值都调用 diffy 进行比对,如果最终 diff 结果都没有差异,或者有差异的字段 noise 都为 1,就可以认为这条回放是成功的。
4.2 流量过滤
进一步考虑,既然我们需要回放到 stable 环境和 dev 环境,那么我们可以在回放到 stable 的时候对流量就先进行一个过滤,对那些明确会回放失败的流量我们就没必要再回放到 dev 了,比如有暂不支持的插件。这里需要判断怎样的流量是没有必要回放的,即无效流量。简单逻辑如下

stable 回放结果 diff 我们这里依旧使用了官方的,字段过滤逻辑保留。如果回放 diff 失败了,且有子调用 mock 没有兜住。那么说明他的代码走了新的链路,或者子调用请求中有较多随机数等。此时这些流量回放到 dev 去也难逃失败的命运,所以可以过滤掉这部分流量。反之,则可将流量回放到 dev 去。
4.3 回放流程逻辑
基于以上 diffy 降噪和流量过滤,降噪回放整体流程设计如下图所示
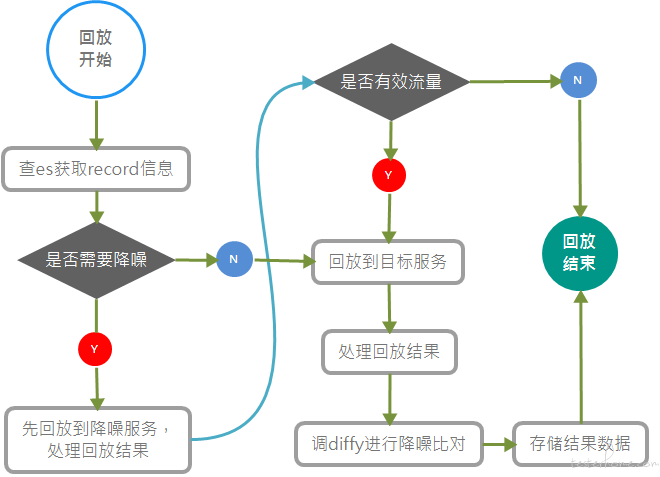
前端入口设计如下
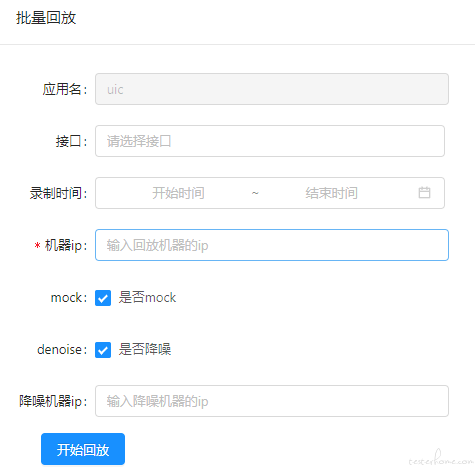
kurepeater 支持在前端选择是否降噪。选择降噪则进行流量过滤和 diffy 比较;选择不降噪则走原逻辑,直接回放到目标服务,使用开源代码自带的 diff 工具进行比较。
4.4 效果数据
下面是我们某一次回放的实验结果。如果我们选择不降噪,那么共回放了 38500 条,回放失败 249 条。这样回放排查的工作量是很大的。
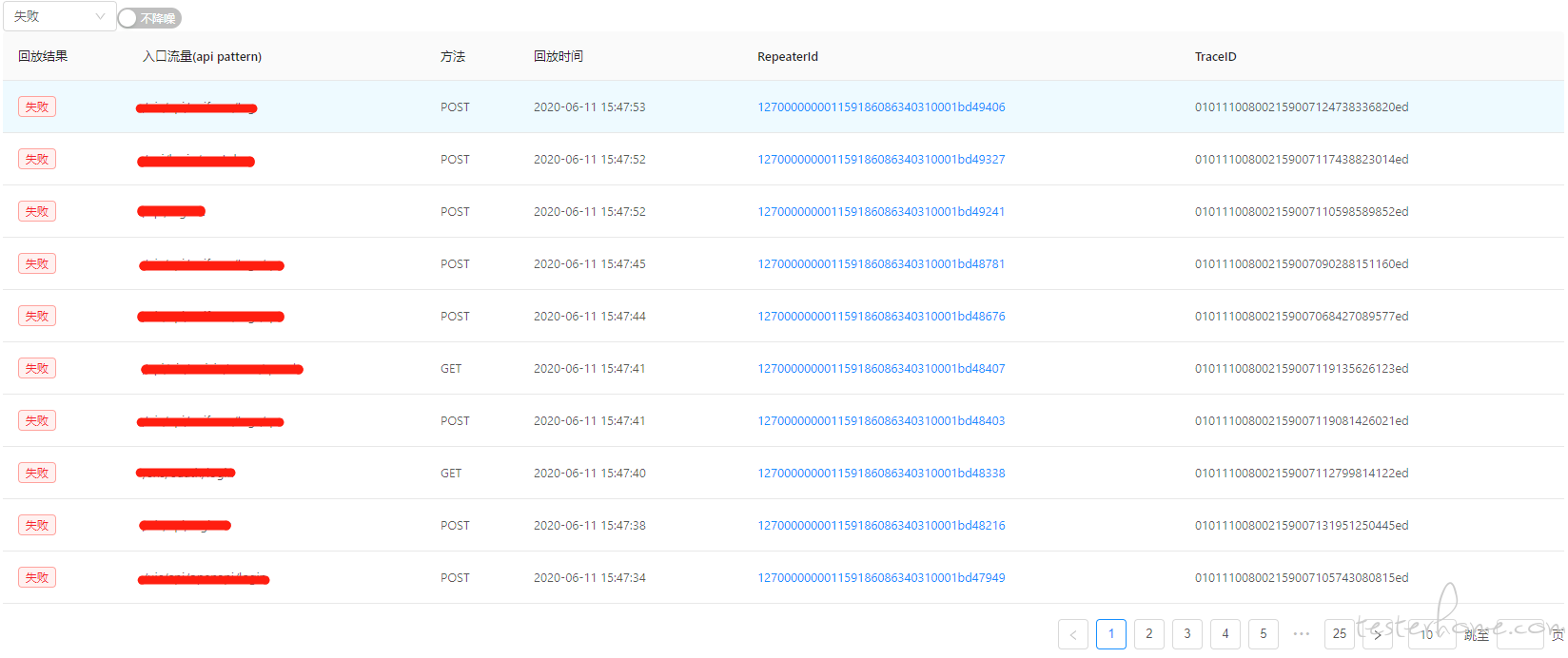
选择使用降噪功能后,经过滤能走到 dev 流量只剩约 19870 条,失败只剩约 120 条,都少了约一半。排查的工作量依旧是很大的
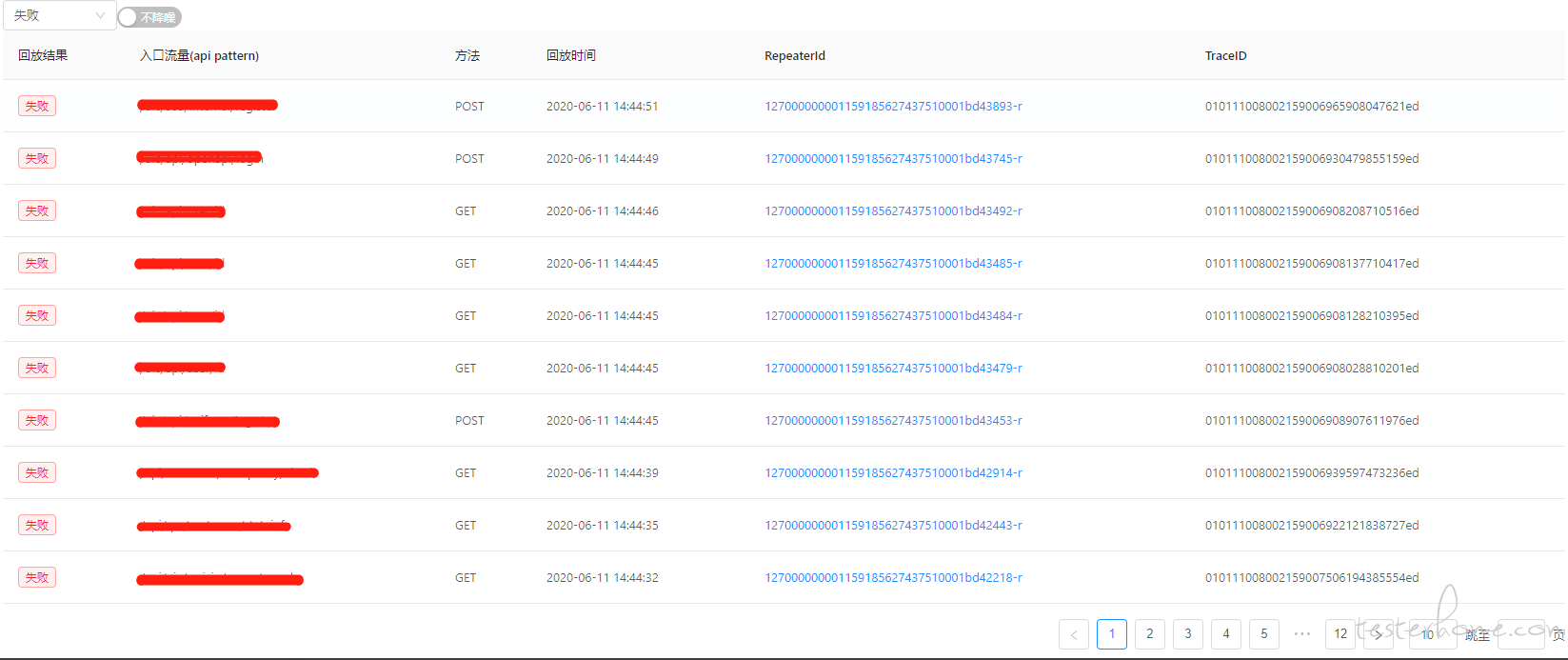
降噪回放查看结果时把 diffy 降噪判断的打开进行过滤,此时需要我们去仔细排查确认的只剩两条,如此就比较轻松了。

5.总结:
kurepater 平台已经在公司内部开始推广试用,目前已共在几十个服务上进行了数千次回放,回放功能对部分服务代码的行覆盖率已达到了 40% 以上。下一步,我们将考虑提升 kurepeater 平台的易用性,比如增加更多的插件支持,进一步优化接口采样配置,优化问题的排查效率等。感兴趣的可以一起讨论和学习。
想了解更多关于酷家乐技术质量的文章,欢迎关注我们的公众号