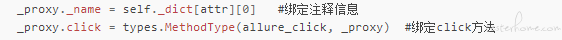Appium UI 自动化到底要不要用 Page Object 模式?(续 - 深入了解 PO 模式, 并改造 PO 模式)
背景
前几天发布了一个话题 “ UI 自动化到底要不要用 Page Object 模式?“ 原帖子:https://testerhome.com/topics/19831
大家给出了很多观点, 有倾向于 po 模式, 也有建议根据不同项目场景自行处理,最后还是一知半解,并没有搞懂,于是集中深入的了解了下 Page Object 模式
Page Object 模式 python webdriver 版本
这里介绍下我近期对 PO 模式的理解, 整体思想是分层,让不同层去做不同类型的事情,让代码结构清晰,增加复用性
一般分两层或三层(也有四层的):
两层:
- 对象逻辑层
- 业务数据层
三层:
- 对象库层
- 逻辑层
- 业务层
四层:
- 对象库层
- 逻辑层
- 业务层
- 数据层
不同层本质差不多
下面以登录为例子 (网上绝大多数都是以登录为例子,但登录只能让新手明白 PO 大概是怎样子,优势却很难传递出来)
普通方式:
def test_user_login():
driver = webdriver.Edge()
base_url = 'https://mail.qq.com/'
username = '3494xxxxx' # qq号码
password = 'kemixxxx' # qq密码
driver.get(base_url)
driver.switch_to.frame('login_frame') #切换到登录窗口的iframe
driver.find_element(By.ID, "u").send_keys(username) #输入账号
driver.find_element(By.ID, "p").send_keys(password) #输入密码
driver.find_element(By.ID, "login_button").click() #点击登录
PO 模式
对象库层
#创建基础类
class BasePage(object):
#初始化
def __init__(self, driver):
self.base_url = 'https://mail.qq.com/'
self.driver = driver
self.timeout = 30
#打开页面
def _open(self):
url = self.base_url
self.driver.get(url)
self.driver.switch_to.frame('login_frame') #切换到登录窗口的iframe
def open(self):
self._open()
#定位方法封装
def find_element(self,*loc):
return self.driver.find_element(*loc)
#创建LoginPage类
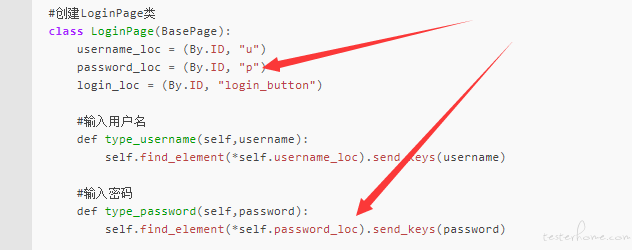
class LoginPage(BasePage):
username_loc = (By.ID, "u")
password_loc = (By.ID, "p")
login_loc = (By.ID, "login_button")
#输入用户名
def type_username(self,username):
self.find_element(*self.username_loc).send_keys(username)
#输入密码
def type_password(self,password):
self.find_element(*self.password_loc).send_keys(password)
#点击登录
def type_login(self):
self.find_element(*self.login_loc).click()
逻辑层
#创建test_user_login()函数
def user_login(driver, username, password):
"""测试用户名/密码是否可以登录"""
login_page = LoginPage(driver)
login_page.open()
login_page.type_username(username)
login_page.type_password(password)
login_page.type_login()
业务层
def test_user_login():
driver = webdriver.Edge()
username = '3494xxxxx' #qq号码
password = 'kemixxxx' #qq密码
test_user_login(driver, username, password)
分析
一 代码量多了大概三倍, 代码量增加是一定的先忽略,后面重点讨论
二 分层之后真的易于维护吗?
我们来看下当元素发生变化的时候,只需要在对象库层找打对应元素修改。 咦? 你会说普通方式不也一样吗, 看上去一样,其实有细微差异,而一些细微差异会导致很大不同
- 效率高 : PO 模式每个元素有变量定义,更方便查找。 而普通方式得通过备注或上下文来推断效率低。 ps:随着 case 不断增加,海量元素的定义对于英语一般的同学挑战也大,有人说有谷歌翻译。定义的时候可以通过翻译, 但到时候回过来查过元素怎么办? 翻译通常是 1 对多,我们当时选哪个? 用哪个来搜索? 这或许也是海量变量定义带来的困扰
- 复用多收益大: 当某个元素被多次引用的时候,只需要修改一处便可,而普通方式需要一处一处找出来并修改,可以看出来复用越多 PO 模式收益越大
当界面需求发生变化
- 1.新增或删除了一些功能点或调整操作步骤先后顺序,但上层业务不变
- 效率高 :同理,PO 模式的逻辑层方法有具体定义,情况和元素发生变化一样 修改逻辑层,业务层不变。这样看来结构简单清晰,舒服更符合人类习惯, 普通方式就是继续堆 case
- 复用多收益大: 同样这里如果逻辑复用越多,PO 模式收益越大,因为对于 PO 模式来说都只需要修改一个地方多处受益
-
- 上层业务发生变化
看上去两者差异不大
小结
总得来看:
- case 越多使用 PO 模式会使你的代码结构更清晰
- 元素复用越多 PO 模式下维护非常容易
- 逻辑复用越多 PO 模式下维护非常容易(如果逻辑复用多,需要多考虑逻辑层的颗粒度)
- 元素/逻辑/数据复用越多应选择更多层的 PO 模式
| PO 模式 | 普通方式 | |
|---|---|---|
| 代码量 | a*N(a>=2) | N |
| 可阅读性 | 强 | 很差 |
| 维护性 | 强 | 差 |
好,我们再回过头来看看代码量大的问题,有没有办法精简一些呢? 把 a*N 中的 a 变成 1.8, 1.5, 1.2, 甚至接近 1 呢?
开始下一轮探索:
探索 代码量大的问题
以三层 PO 为例我们大概的流程是这样的:
在对象库层,我们定义了元素,再为元素定义了一些基本的操作流, 在逻辑层 为集成了基本操作流,在业务层 组装逻辑 和 数据输入
看上去 第二 第三步骤 有点重复 能不能去掉? 如果只剩下第一 四个步骤 那代码量瞬间就下来了 那该有多爽
试试看
如果去掉第二/三步骤,那意味着我们只需要定义元素,并在业务层需要指定操作的时候再自动生成对应所需操作。即需要时生成,用完后丢弃。
这里需要用到 python 下面的魔法方法 "getattribute"
思路:
在访问类 App 属性时挡截下来,历遍对象库层找到对应元素返回对应的对象类 App.LoginPage,而对象库层都继承了 BasePage 类,在 BasePage 中同样重构了"getattribute",当 App.LoginPage 对象尝试调用 click() 之类的方法时,就临时绑定 click 方法(click/swip/get_text/set_text.....)。
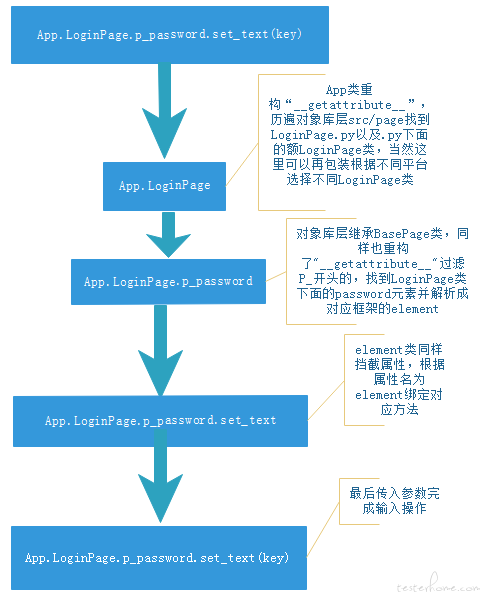
这样做的话,就只需要编写元素对象库,在 业务层直接自由调用,即时生成,用完丢弃。 代码量大幅减少
对象库层 (这里使用 airtest 下面的 poco 控件识别框架举例,和 Appium Selenium 略微不同)
class AndroidHomePage(BasePage):
def __init__(self, driver):
super().__init__(driver)
self.p_account= "NormalWindow/AccountInputField"
self.p_password = "NormalWindow/PwdInputField"
业务层
def test_login(id,pw)
App.LoginPage.p_account.set_text(id)
App.LoginPage.p_password.set_text(pw)
如此看来用例编写者就更接近只需要关注业务了
以下是关键思路的实现 以 App 类为例子 BasePage Element 大概相同
-
App 类
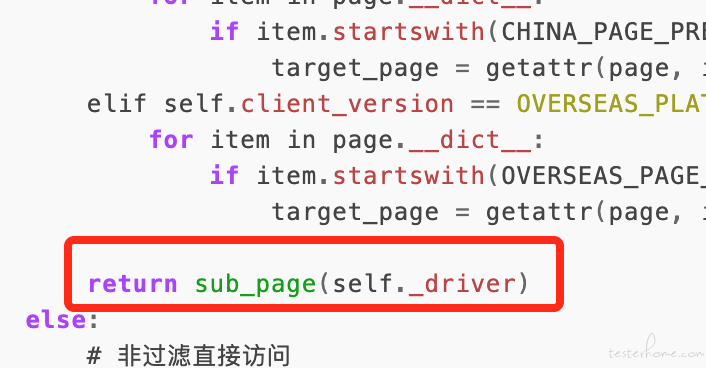
def __getattribute__(self, attr): """ 挡截属性访问 """ target_page = None if attr.endswith('page'): # 过滤page page = import_module(attr) #历遍 对象库层目录src/page 找到目标文件 if self.client_version == CHINA_PLATFORM: # 国内版本 for item in page.__dict__: if item.startswith(CHINA_PAGE_PREFIX) : target_page = getattr(page, item) elif self.client_version == OVERSEAS_PLATFORM: # 海外版本 for item in page.__dict__: if item.startswith(OVERSEAS_PAGE_PREFIX) : target_page = getattr(page, item) return target_page(self._driver) else: # 非过滤直接访问 return object.__getattribute__(self, attr)结尾
以上这近几天对 PO 的新认识,欢迎大家多多指点
添加部分具体代码
对象元素库层:
BasePage:
class BasePage(object):
def __init__(self, driver):
self.poco = driver
self._p_help_btn = ['帮助按钮', 'HelpBtn'] # “帮助按钮" 为注释,有几个作用:1.用于之后元素查找 2.访问self._p_help_btn 时自动绑定一个_name属性并赋值,在使用click()等具体操作时,会自动给对应方法添加 with allure.step(“步骤: 点击 %s”% self._name) (allure报告框架)从而使每个case都会展示具体的操作步骤信息; “HelpBtn” :具体的元素(这里是以poco框架的元素为例)
self._p_help_text = ['帮助文本信息', 'GuideDialog(Clone)/DialogTx']
self._p_help_continue_btn = ['帮助-》继续按钮', 'GuideDialog(Clone)/Continute/Glim']
self._dict = object.__getattribute__(self, '__dict__') # 获取属性集用于历遍查找目标属性
#解析key的方法,不同提取元素框架自行实现解析函数,返回一个对应框架的控件操作对象
def resolve_poco(self, key):
return poco_key(self.poco, key)
def __getattribute__(self, attr):
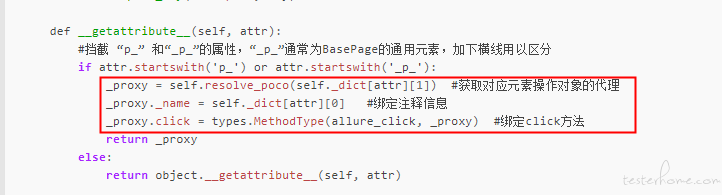
#挡截 “p_” 和“_p_”的属性,“_p_”通常为BasePage的通用元素,加下横线用以区分
if attr.startswith('p_') or attr.startswith('_p_'):
_proxy = self.resolve_poco(self._dict[attr][1]) #获取对应元素操作对象的代理
_proxy._name = self._dict[attr][0] #绑定注释信息
_proxy.click = types.MethodType(allure_click, _proxy) #绑定click方法
return _proxy
else:
return object.__getattribute__(self, attr)
#这里的帮助文档检查是每个功能模块都有的,所有放在BasePage里面,不同继承类如果有元素差异重写元素即可
def check_help_text(self, texts, timeout=3):
self._p_help_btn.click()
for text in texts:
self.regular_wait(timeout)
assert self._p_help_text.wait(2).get_text() == text
self._p_help_continue_btn.click()
ScoutingPage:
class ScoutingPage(BasePage):
def __init__(self, driver):
super().__init__(driver)
业务层:
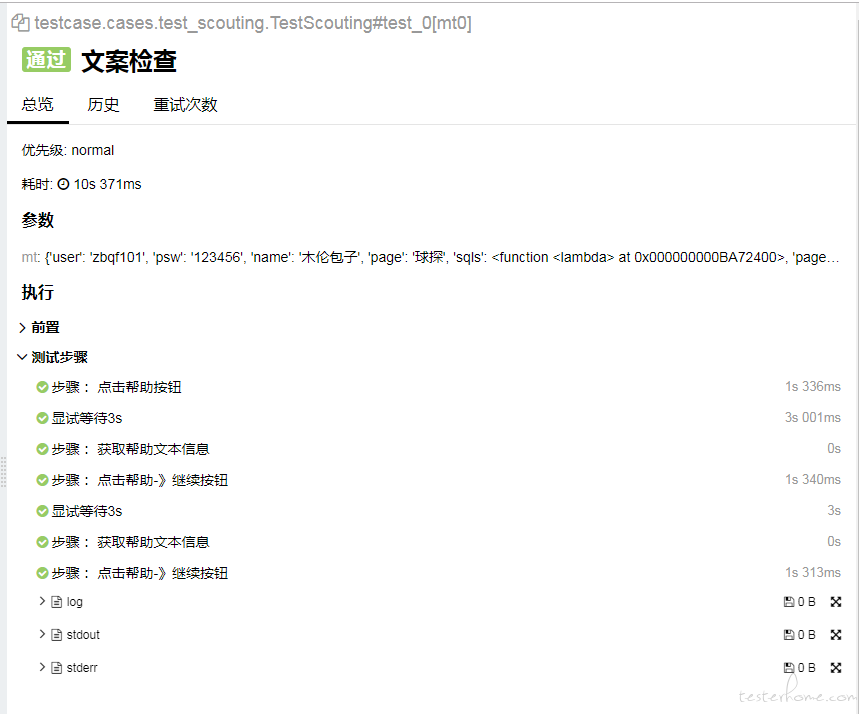
@allure.story('帮助')
@allure.title('文案检查')
def test_0(self, mt):
#mt 是pytest下面的一个fixture,完成了一系列操作最后返回对应的Page类对象,操作包括:登录/前置界面智能跳转/前置数据准备等等
mt.check_help_text([
'球探介绍所可以帮助球队搜索到潜力新星,但每次搜索需要消耗大量机票',
'董事会每<color=#FFBE34>5</color>分钟会赞助球队1张机票,解雇球员也可以获得大量机票'
])
执行报告如下: