哈哈,抱歉用了这样一个高大上的标题,实在是环境所迫啊。
毕竟现在要是张嘴还不能蹦出几个云,大数据,AI,数据孪生,网络切片,边缘计算,窄带物联网等等这些,实在是显得自己多少有点文盲。其实这只是一个小小的爬虫脚本。
前因
事情得从过年放假说起.......
原以为过年回家可以有好多亲相,毕竟老妈之前电话里已经承诺了好几次了。结果一直到了年初三,还没有任何要带我出去相亲的意思,我又不太好去问,毕竟要脸,直接问的话就显得我太不矜持了。
终于年初三晚上,那晚正在和大神在刺激战场里厮杀,老爸钻进了我的被窝,和我促膝长谈,先聊了工作,股票,然后终于聊到了我的个人问题了,实在顾不得大神了,放下了手机,兴奋地搓起了小手手,喇叭里还在传出大神 “扶我扶我” 的惨叫。我还在想该怎么组织语言委婉而不失礼貌地推辞下,来表现出我的矜持,老爸却说了一句 “个人问题还得靠个人自己解决啊” 就钻出了被窝,心情瞬间从云间跌到了谷底,重新拿起了手机,脚边怎么有个盒子,擦,还有八倍镜、98k,这是要吃鸡的节奏啊.......
回杭后,也就忘了这回事,昨天突然灵光一闪想到了张老师之前说的大名鼎鼎的萧内网,我竟然没想到,感觉错过一个亿,毕竟要是碰上个眼瞎的拆迁户,岂不是能少奋斗 100 年,还炒啥股,搬啥砖啊~~
立马注册了萧内网,原来有么多单身男女,再一次兴奋地搓起了小手手。额,好像上面的信息太多了,又没个筛选项,虽然很接地气,但是要一个个打开看的话,效率实在是不高,毕竟像我这种分分钟几千上下的人来说,时间就是金钱啊。要是能把上面的个人信息全摘下来,自己先筛一遍就很完美了,说干就干。
页面分析
我们进入征婚版块,抓到列表请求,可以看到一页有 40 条征婚信息,返回里面的 a 标签下放的就是帖子地址了,加上前缀后就可以进入对应的帖子,如图:

#coding:utf-8
import json
import re
import requests
from bs4 import BeautifulSoup
url = "https://share.zaixs.com"
#网站做了防爬,直接发请求会403,这里要在headers里加上User-Agent
headers = {'User-Agent': "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Mobile Safari/537.36",'Content-Type': "application/x-www-form-urlencoded"}
querystring = {"fid":"67"}
#payload = "page=3"
def gettid():
#访问征婚版块,获取该板块下的帖子id
url1 = url + "/wap/community/list"
tidlist = []
#page是页数从1开始,每页40条信息,6时为200条信息
for page in range(1,6):
payload = "page=" + str(page)
response_id = requests.request("GET", url1, data=payload, headers=headers, params=querystring)
soup_id = BeautifulSoup(response_id.text,'html.parser')
#每页返回的帖子地址,把tid保存到tidlist中
for link in soup_id.find_all('a'):
url_id = link.get('href')
if str(url_id)[:5] == '/wap/':
tidlist.append(url_id)
return tidlist
#print(gettid())
def getmessage():
messagelist = []
for j in gettid():
url2 = url+ str(j)
response = requests.request("GET", url2, headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
#print(soup)
try:#根据标签取出个人信息,取不到时忽略
message = soup.select('.typeoption')[0].text
#print(message)
message1 = url2 + str(message)
messagelist.append(message1)
except IndexError:
pass
return messagelist
#print(getmessage())
f = open('E:/git/changtang/message.txt','w')
for x in getmessage():
y = str(x) + '\n'
f.write(y)
f.close()
跑了下感觉好像还可以啊。
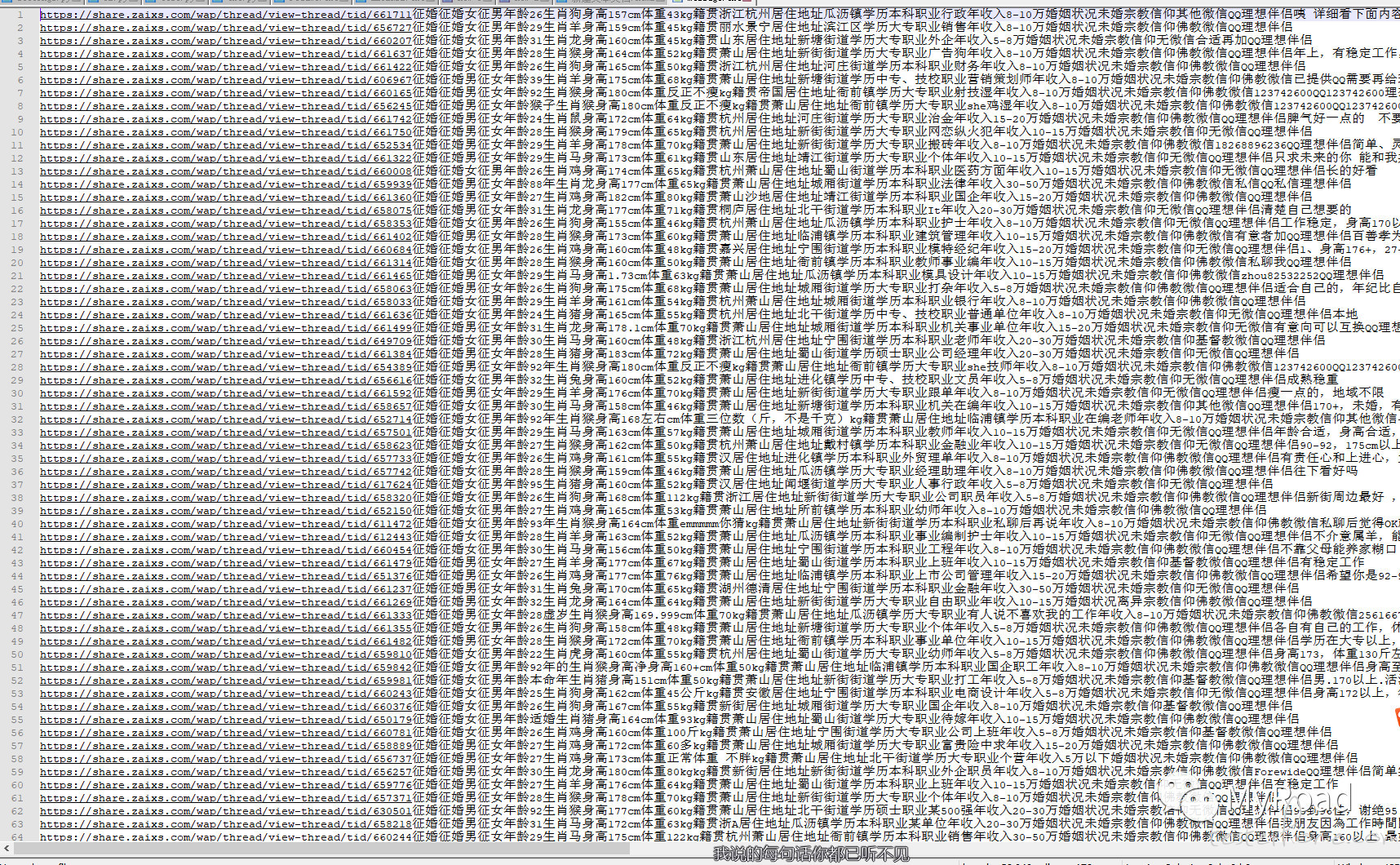
做完发现还相啥亲啊,开个婚介所当月老红娘吧~~~
下面是一些信息整合,仅供各位单身汪参考
籍贯分布

职业分布

生肖分布

另外有兴趣可以关注下公众号呀,不定期发一些好玩的东西: MyRoad

