java 中经常需要用到多线程来处理一些业务,我们非常不建议单纯使用继承 Thread 或者实现 Runnable 接口的方式来创建线程,那样势必有创建及销毁线程耗费资源、线程上下文切换问题,这个时候引入线程池比较合理。有些时候也需要把多线程的逻辑给异步话,接口不需要等待子线程逻辑执行完就马上返回,这里就需要异步任务。java 中涉及到线程池的相关类均在 jdk1.5 开始的 java.util.concurrent 包中,涉及到的几个核心类及接口包括:ExecutorService、Executors、ThreadPoolExecutor、FeatureTask、Callable、Runnable 等。后面会一一描述。
先来个业务场景 demo1:多线程的方式给客户发送短信 并 提交虚拟码给积分商城,流程如下图(只截取了部分)
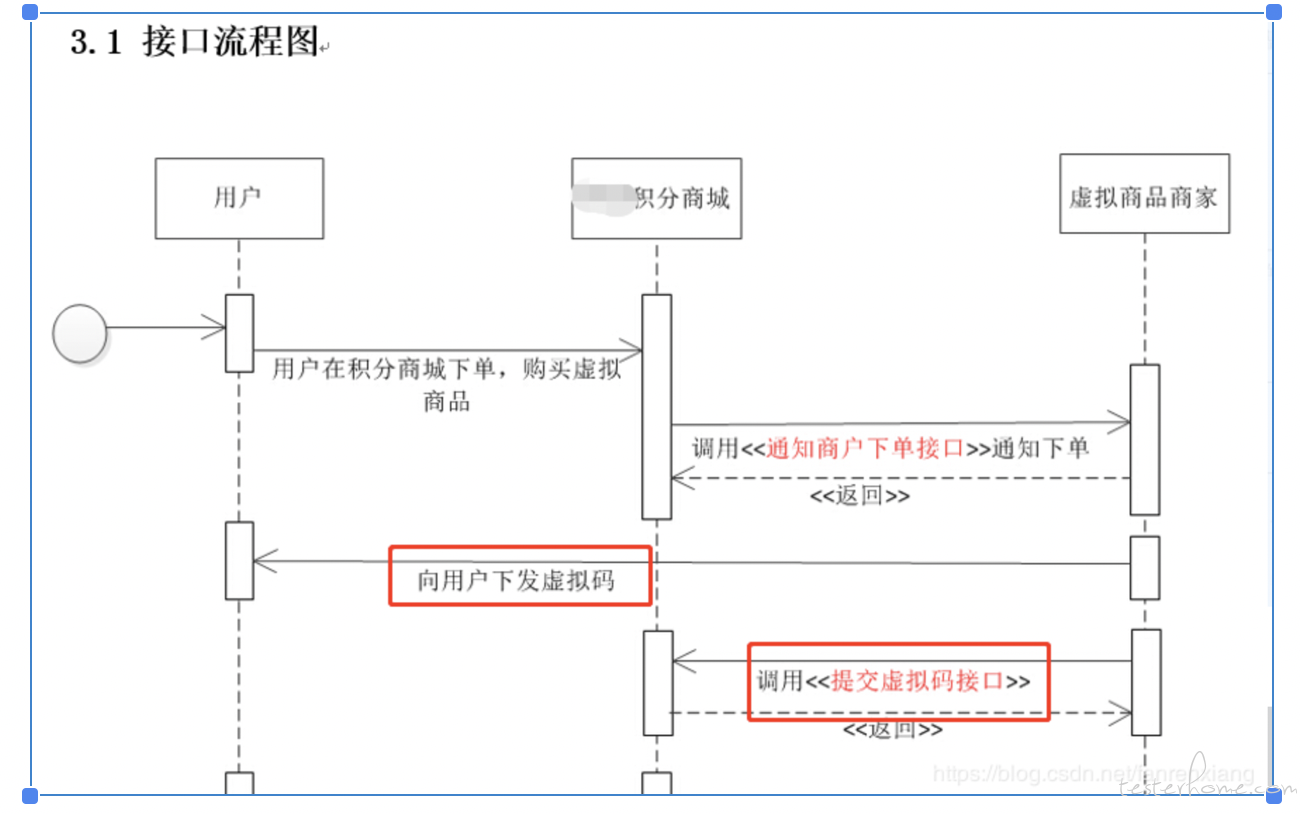
伪代码思路如下:
@ResponseBody
@RequestMapping(value = "/notifyOrder", method = RequestMethod.POST)
public CommonResult notifyOrder(@RequestParam(value = "req", required = false) String req) {
log.info("notifyOrder method parameter:req={}", req);
CommonResult result = new CommonResult();
// 1、校验工作
// 2、decode 送过来的原始数据并序列化
PointsMallOrderInfo orderInfo = StringToBean(req, "data", PointsMallOrderInfo.class);
// 3、保存推送过来的原始数据
orderInfoService.addOrderInfo(orderInfo);
// 4、获取系统中状态为可用的虚拟码
// 5、多线程异步处理 发送短信、提交虚拟码
AsynSendAndSubmitTask.asynSendAndSubmit(orderInfo);
// 6、持久化虚拟码流水号等信息
return result;
}
public class AsynSendAndSubmitTask {
private static ExecutorService asynSendAndSubmitThreadPool = new ThreadPoolExecutor(10, 10, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue(40));
public static void asynSendAndSubmit(final PointsMallOrderInfo orderInfo) {
asynSendAndSubmitThreadPool.execute(new Runnable() {
@Override
public void run() {
// 短信下发虚拟码给用户
Long messageId = smsService.sendSms(new SendSmsInfo());
// 给积分商城提交虚拟码
String submitResult = HttpUtil.httpPost(false, params, SETVIRTUALCODE_URL);
}
});
}
}
我们程序逻辑主线程中执行 “保存推送过来的基础数据、查询并取出可用的充值码、持久化充值码及相关流水号信息操作,但提交虚拟码和短信发送虚拟码则以多线程的方式异步处理,加快接口响应。(当然也可以用 kafka/MQ 之类的消息队列替代)
角色划分
1、任务:指的是实现了 Callable 或 Runnable 接口的类,里面包含主要的业务逻辑,任务用于提交至线程池里的线程去执行。实现 Callable 接口的任务类可以有返回值,而 Runnable 接口则无;
2、异步计算结果:主要是 FutureTask 类,里面包含了异步任务的计结结果,可以理解为执行单元,用于提交至线程池时使用;
3、线程池:ThreadPoolExecutor 和 Executors 类,用于构建线程池。
Executors 和 ThreadPoolExecutor
由源码可知 Executors 本质上还是使用的 ThreadPoolExecutor 来实例化线程池的,Executors 类可以创建四种类型的线程池,分别为 newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool、newScheduledThreadPool
FixedThreadPool
使用固定线程数,适用于为了平衡服务器资源而指定线程数的场景,一般用于负载比较高的服务器
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory);
}
如上是在 ThreadPoolExecutor 类中的源码,可以看到 newFixedThreadPool 线程池重用放在"共享无边界的队列 LinkedBlockingQueue"中的固定线程数,处理任务时,nThread 大部分都将以活动状态在处理任务,如果当所有线程都处于活动状态时又有额外的任务提交,那么新任务将在队列中等待直至线程可用。
SingleThreadExecutor
使用单个线程数,适用于需要保证顺序的执行各个任务;并且在任意时间点,不会有多个线程活动的场景
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory));
}
关于这种方式创建的线程池,源码中特别强调了:如果该单个线程在关闭之前由于执行过程中的失败而终止,那么如果需要执行后续任务,将替换一个新的线程,使用到的也是 LinkedBlockingQueue 队列。
CachedThreadPool
使用非固定线程数,适用于执行很多短期的异步任务,或者负载较轻的服务器
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue(),
threadFactory);
}
根据需要创建线程,如优重用先前创建的可用线程,否则将新建线程并放到池子中,从构造函数可以看到,默认超过 60 秒未使用的线程将被终止并从 cache 中移除,使用到的同步移交 SynchronousQueue 队列。
ScheduledThreadPool
包含多个线程,适用于需要多个后台执行周期任务(或延迟任务),同时为了满足资源管理的需求而需要限制线程数量的场景
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
SingleThreadScheduledExecutor
对应的还有个 SingleThreadScheduledExecutor 只包含单个线程,适用于需要单个后台线程执行周期性任务,同时需要保证顺序的执行各个任务的场景
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
使用 Executors 创建线程池的隐患
我这里以 newFixedThreadPool 构建的线程池为例,结合源码看看 Executors.newFixedThreadPool(n) 创建的线程池会有哪些潜在的隐患。进入 newFixedThreadPool 初始化的源码
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {……}
corePoolSize:线程池核心线程数,要注意线程池初创时候并不会启动 corePoolSize 个线程,而是随着任务的提交逐渐达到这个值;
maximumPoolSize:池中的最大线程数,要注意这个参数只有在任务数量大于 corePoolSize 时才会起作用;
keepAliveTime:当线程数大于 corePoolSize 时,多余空闲线程在终止之前等待新任务的最大时间;
unit:keepAliveTime 的时间单位;
workQueue:用于保存任务的队列,可以为无界、有界、同步移交类型的队列,这里是 BlockingQueue。当池子里的工作线程数大于 corePoolSize 时,这时新进来的任务才会放到阻塞队列中
threadFactory:创建新的线程时的工厂类,比如 guava 的 ThreadFactoryBuilder;
handler:队列已满且线程数达到 maximunPoolSize 时候的饱和策略,取值有 AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy;
上面说到了 FixedThreadPool、SingleThreadExecutor 源码中使用到的是 LinkedBlockingQueue 无界队列,而 CacheThreadPool 和 ScheduledThreadPool 实例化时默认最大线程数又是 Integer.MAX_VALUE,这可能导致什么结果呢?《阿里巴巴 Java 开发手册 v1.2.0》中这样说到:

结合源码看:FixedThreadPool、SingleThreadExecutor 的 LinkedBlockQueue 是一个用链表实现的有界阻塞队列,容量可以选择进行设置,默认将是一个无边界的阻塞队列,最大长度为 Integer.MAX_VALUE.
/**
- Creates a {@code LinkedBlockingQueue} with a capacity of
- {@link Integer#MAX_VALUE}. */ public LinkedBlockingQueue() { this(Integer.MAX_VALUE); } 而 CacheThreadPool 和 ScheduledThreadPool 实例化时默认最大允许创建的线程数是 Integer.MAX_VALUE
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS,
new DelayedWorkQueue());
}
所以上述两个"漏洞"在特定的场景下就有可能会导致 OOM,故而很多人都不建议使用这颗"定时炸弹"。
创建线程池的正确姿势?
那么上面说了使用 Executors 创建的线程池有隐患,那如何使用才能避免这个隐患呢?对症下药,既然 FixedThreadPool 和 SingleThreadPool"可能"导致的 OOM 是由于使用了无界队列任务堆积,CacheThreadPool 和 ScheduledThreadPool 是由于"可能"创建 Interger.MAX_VALUE,那创建线程池时我们就使用有界队列或者指定最大允许创建线程个数即可。使用下面的构造函数
private static ExecutorService executor = new ThreadPoolExecutor(10,10,60L, TimeUnit.SECONDS,new ArrayBlockingQueue(10));
这样可以指定 corePoolSize、maximumPoolSize、workQueue 为 ArrayBlockingQueue 有界队列
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
默认的 handler 队列饱和策略为 AbortPolicy(直接抛出异常),当提交任务线程数高于可用线程数,队列放满而无法处理新请求,这时候会抛出 java.util.concurrent.RejectedExecutionException 异常,然后手动捕获即可,总比 OOM 强吧。当然你也可以使用 guava 包中的 ThreadFactoryBuilder 工厂类来构造线程池:
private static ThreadFactory threadFactory = new ThreadFactoryBuilder().build();
private static ExecutorService executorService = new ThreadPoolExecutor(10, 10, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue(10), threadFactory, new ThreadPoolExecutor.AbortPolicy());
通过 guava 的 ThreadFactory 工厂类还可以指定线程的名称,这对于后期定位错误时也是很有帮助的
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("thread-pool-d%").build();
Future 和 FutureTask(异步任务结果
Future 接口和 FutureTask 类用来表示执行异步任务的结果,当向 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 提交了一个 Callable 或 Runnable 接口的实现类时,ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 就会返回 FutureTask。到目前的 jdk 版本为止,submit 返回的是都是实现了 Future 接口的 FutureTask。
Future submit(Callable task);
Future submit(Runnable task, T result);
Future<?> submit(Runnable task);
FutureTask 一般都是和线程池搭配使用,用于多线程的方式提交任务,通过 futureTask.get() 方法获取异步任务的计算结果即可。如下代码:
import java.util.concurrent.*;
public class FutureTaskTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newCachedThreadPool();
try {
CustomCallable callable = new CustomCallable();
FutureTask callableTask = new FutureTask(callable);
executor.submit(callableTask);
System.out.println("callableTask 任务计算结果=" + callableTask.get());
CustomRunnable runnable = new CustomRunnable();
FutureTask runnableTask = new FutureTask<>(runnable, null);
executor.submit(runnableTask);
} finally {
executor.shutdown();
}
}
}
class CustomCallable implements Callable {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
return sum;
}
}
class CustomRunnable implements Runnable {
@Override
public void run() {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i;
}
System.out.println("RunnableTask 任务计算结果=" + sum);
}
}
从上面代码和开头讲到的 demo1 场景来看,使用 FutureTask 后,提交给线程池的就变成了 futuretask 而不是简单的实现了 Runnable 或 Callable 接口的普通任务了,并且获取任务的结果也是通过 futuretask.get() 方法而不是 executorservice.submit() 返回值。
Callable 和 Runnable(任务类逻辑)
Callable 接口和 Runnable 接口的实现类(近似等价于被提交任务的逻辑)均可以被 ThreadPoolExecutor 或 ScheduledThreadPoolExecutor 所执行,区别在于执行的任务逻辑是否需要返回值,Callable 接口实现类可以有返回值,而 Runnable 接口实现类则没有返回值;比如这里自定义一个实现了 Callable 接口的任务类:
class CustomCallable implements Callable {
@Override
public Integer call() throws Exception {
System.out.println("子线程开始进行计算");
Thread.sleep(500);
int sum = 0;
for (int i = 0; i < 10; i++)
sum += i;
return sum;
}
}
也可以通过 Executors 类包装的如下两种方式创建任务
//此方式创建 Callable 对象,通过 futureTask.get() 方法可以获取到异步计算结果
public static Callable callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter(task, result);
}
//不返回异步计算结果
public static Callable callable(Runnable task) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter(task, null);
}
1、通过 futureTask.get() 方法获取任务计算结果时,当任务还未完成,会导致线程阻塞直至任务完成,一般会配合 futureTask.isDone() 方法判断子线程任务是否完成来一起使用;
2、当项目中有很多异步任务时,要着重测试下每个异步任务的执行时间,比如某个异步任务是调用其他系统的 web 服务,这时候就得测试调用需用的时间长短,如果过长,则建议使用生产/消费模式的消息队列去实现,不然容易使服务器的 jvm 进程崩溃;
线程池实现原理?
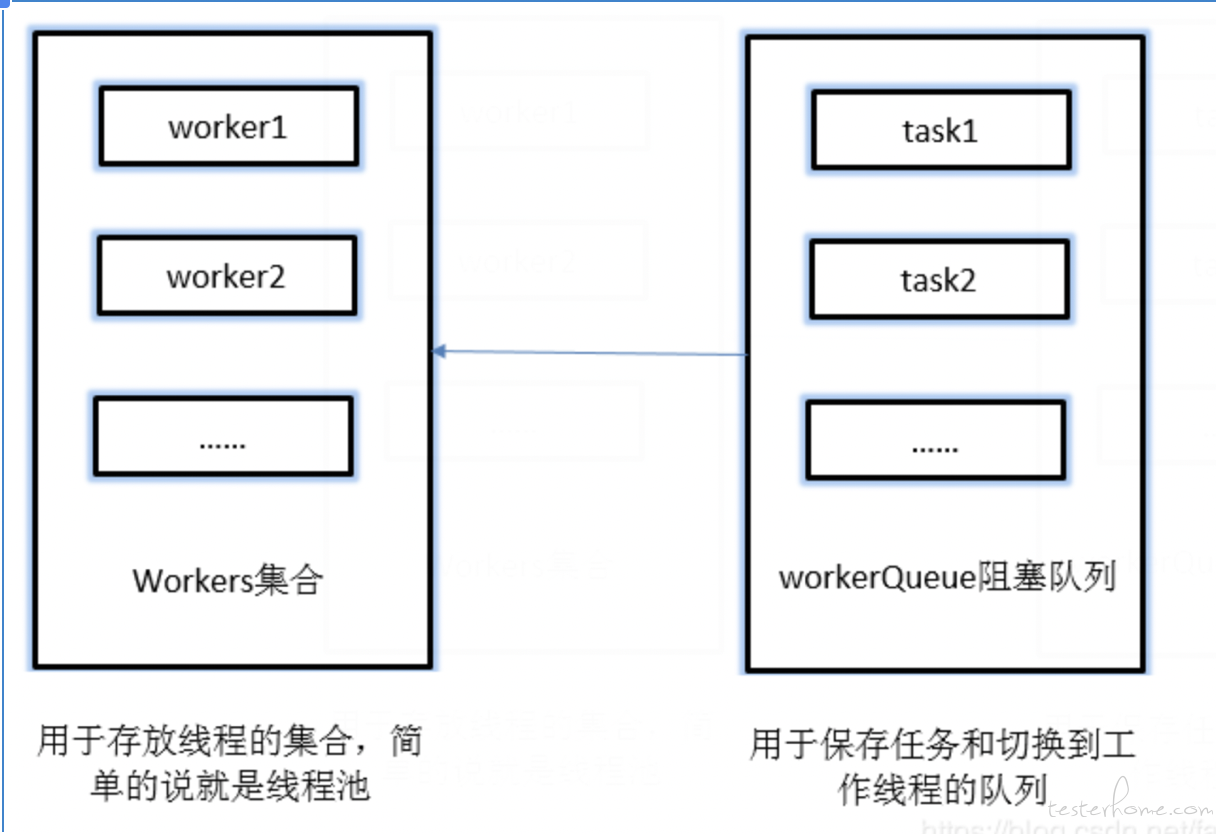
current 包下的线程池实现原理相对简单,就是一个线程集合 workers 和存放任务的阻塞队列 workQueue,当有新任务提交时就放到 workQueue 队列中(注:当池子里的核心线程数小于 corePoolSize 时任务会直接被执行),然后线程池从任务阻塞队列中"分配"任务并执行。
/**
- 设置线程池中的所有工作线程 */ private final HashSet workers = new HashSet();
/**
- 用于保存任务和切换到工作线程的队列 */ private final BlockingQueue workQueue;
Springboot 中使用线程池
springboot 可以说是非常流行了,下面说说如何在 springboot 中让 spring 来帮我们管理线程池
/**
- @ClassName ThreadPoolConfig
- @Description 构建 spring 管理的线程池实例,方便调用
- @Author simonsfan
- @Date 2018/12/20
-
Version 1.0
*/
@Configuration
public class ThreadPoolConfig {@Bean(value = "threadPoolInstance")
public ExecutorService createThreadPoolInstance() {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("thread-pool-d%").build();
ExecutorService threadPool = new ThreadPoolExecutor(10, 10, 30L, TimeUnit.SECONDS, new ArrayBlockingQueue(10), threadFactory, new ThreadPoolExecutor.AbortPolicy());
return threadPool;
}
}
@Resource(name = "threadPoolInstance")
private ExecutorService executorService;
@Override
public void spikeConsumer() {
//TODO
executorService.execute(new Runnable() {
@Override
public void run() {
//TODO
}
});
作者:simonsfan
来源:CSDN
原文:https://blog.csdn.net/fanrenxiang/article/details/79855992
版权声明:本文为博主原创文章,转载请附上博文链接!
