前言
在开始之前,想说下抱歉,如果是抱着解决问题的想法进来的话,对不起,让您失望了,本文不会讲解怎么解决这问题,因为研发说不处理了,但本文会介绍是怎么一路过来的,如果还感兴趣,请继续看~
上几篇文章有介绍到,jb 在负责一个 seo 的项目,关于 seo 是什么,请点击这里查看;
自从项目上线后,一波三折,遇到不少坑,其中在上面那篇文章里提及到,这里就不说明了;
某一天,运营老大贴了这么一张图:
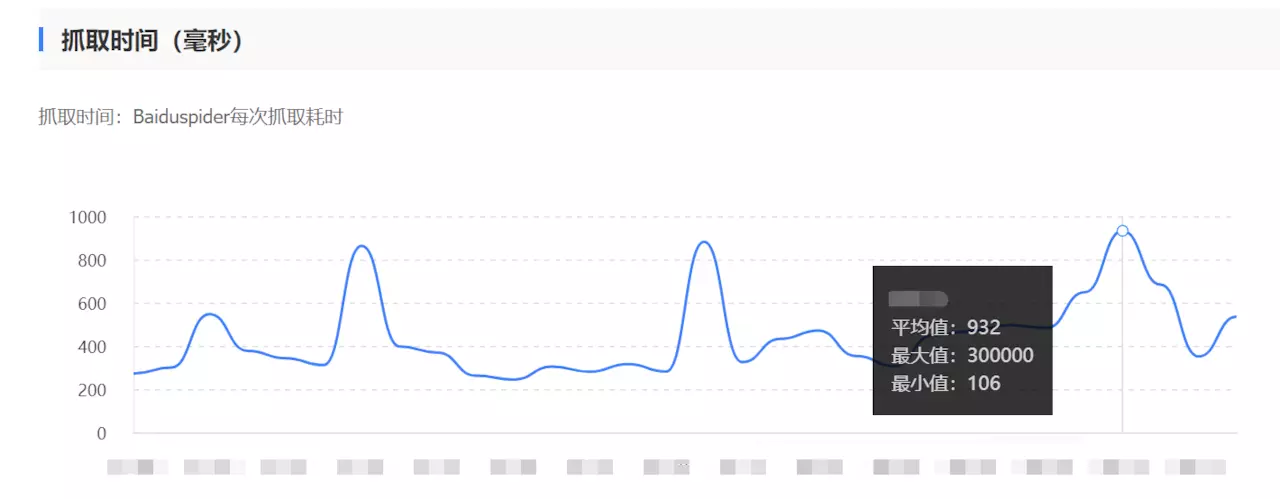
(把日期打码了,问题不大)
这个图是百度那边的一个爬虫耗时数据,从这个截图数据上看,爬取耗时平均值 932ms,最小值 106ms,怎么看都觉得合理,只是那个最大值 300s 的,看上去好别扭。。
心里想:虽然最大值看着别扭,但看平均值,正常范围,没啥问题啊,要不先观察?
接着,就用上面的内容回复说,平均值看上去很正常,应该没啥问题吧?
运营老大说,但是我们更加关心最大值,以前的产品都没有这种情况的,最大值都不超过 1000 的,基本都是 500-1000ms;
所以我们的产品肯定有问题啦;

因为之前的产品也没有具体量化数据,jb 之前也没弄过 seo,没啥概念,既然老板请的顾问也这样说,那就先断定有问题,试试跟进下;
网站介绍
在开始之前,先介绍下问题网站,http://www.51hjgt.com/, 图片就不贴了,免得有人说是广告,这个网站的是采用node+nginx+php,其他就没特别的;
百度数据
因为这个爬虫是百度的,而这个爬取耗时的数据,也是百度提供的,理所当然要看看,这个值是怎么算出来的,遗憾的是,百度的平台没有任何与爬取耗时有关的信息;
既然如此,那就 Google,内容为:百度爬虫耗时很长,在搜索的结果里面有很多百度爬虫的介绍,但是并没有任何一条有直接讲解到这个百度爬虫耗时是怎么算的~
问了很多朋友,甚至是百度内容同学,都不清楚,所以,这块数据对于开发者来说,是一个全黑盒的玩意;
既然如此,我们就先假设,这个时间是指发起请求后,到获取响应且前端渲染完内容的时间;

后端日志
拿到问题,第一反应就是让后端的同学去查下服务器日志,看是不是真的出现 300+s 的情况,
但实际查询后发现,并没有出现这种情况,后端的日志显示接口返回都很快,基本是 ms 级别,秒都谈不上,更何况 300s?
既然后端没有问题,那就肯定是前端了;
前端
既然怀疑是前端问题,那我们就尝试重现下吧,直接用 Chrome 按 F12 进入开发者模式,
直接刷新试试,手动重复几十次,基本都是 2 这个区间内,而且首页资源特别多,如果首页都没问题,其他页面就更不会有问题了;
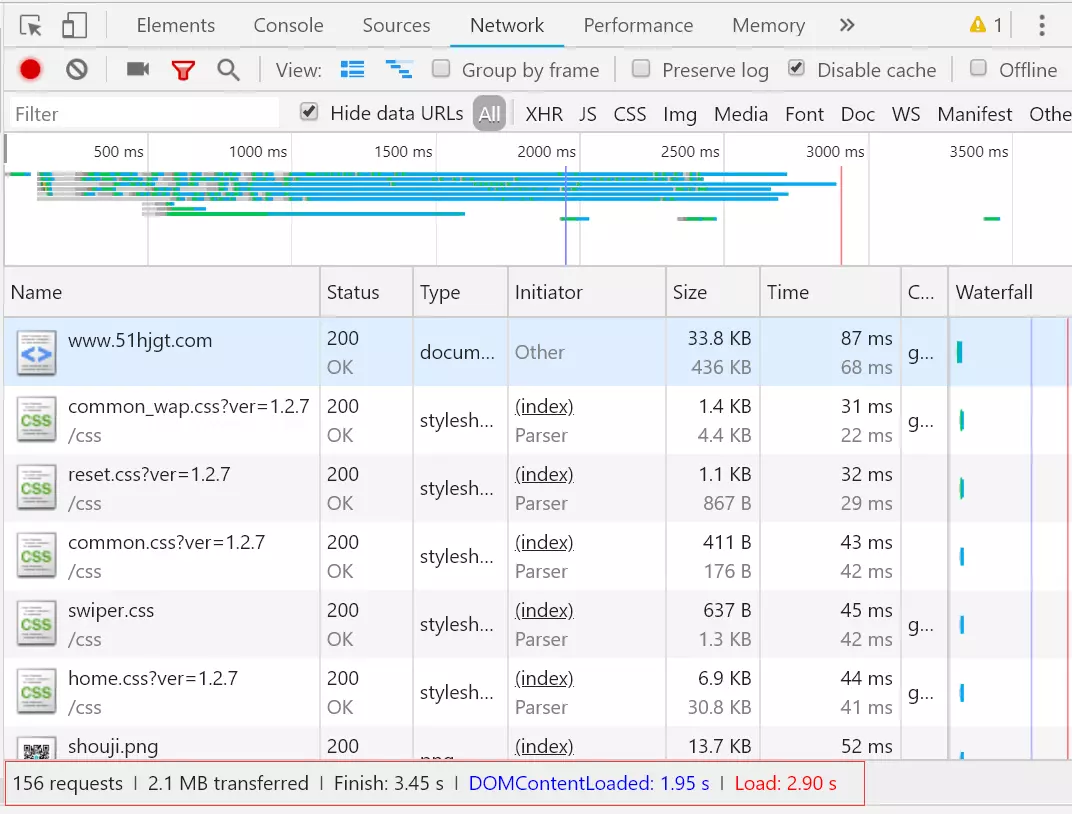
(手动重试中)突然会发现一次耗时比较久的,长达 10s,看了下时间的占比,如下:

咦,一个图片用了 3s?什么鬼?
而且会发现,有些图片 size 会高达 4M?
瞬间把苗头之前了资源这块,为了验证我们的想法,使用了webpagetest工具来验证下网页的耗时,这个工具是个网页,直接打开输入需要测试的网址即可;
先来一次结果:
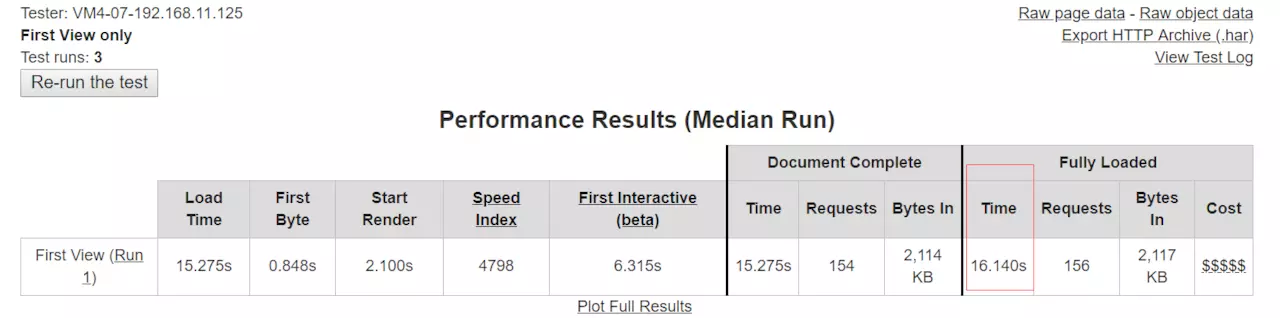
直接看顶部的截图,嘤嘤嘤,fully loaded time 居然去到 16S 了,这肯定有问题,接着继续看:

啧啧啧,一个图片的下载用了 8S,这性能不太行啊,而且有些图片的 size 的确很大,所以第一反应是,图片压缩,减少 size,另外,网站本身会偶尔出现 404,这块本身就会影响到 seo 的收录已经爬取,在这种情况,不得不怀疑任何一切相关的,因此就撸起袖子开始干了:
这里补充下,除了用 webpagetest,还用一些站长工具,当时怀疑可能是 CDN 的问题(当时网站没弄)、用了 LightHouse,也是给了一些建议,但是没有明确支持问题,因此就先把直觉上觉得需要优化的地方先优化,于是乎就有了下下面的改进;
1)资源压缩,部分业务逻辑合并,减少请求数量,缓存机制
2)出现 404 的原因是,当初设计时,如果众多接口里某一接口异常,前端直接判定伟 404,因此把这块逻辑修改下,接口异常不会导致前端跳 404,最多是数据不展示;
开发、测试、上线、绝望,一泼冷水浇下来,大家都痿了;
几个臭皮匠一起讨论了半天,也没个结论,此时,部分同学觉得这是个吃力不讨好的工作,慢慢的开始淡出这个工作了,有点所谓的选择性失盲了;
再次分析
即使运营老大、老板天天问,但是依然没有任何进展,这问题,就这么坑爹?
此时,某拍黄片 (php) 同学主动(被迫)出来跟进这个问题;
啪啪啪好几天过去了,突然某一天,钉钉群闪了,该拍黄片同学给出一个方向,这个问题有初步怀疑点了,那就是服务器带宽问题导致的,解决方案就是临时扩展带宽;

怎么分析的?
既然能给出这样的结论,肯定是有数据支撑他的,那我们就来看看,是什么支撑他这个结论;
依旧是先分析后台日志,过滤百度过来的请求,某一条有 40 几个,然后再根据接口响应超过 10S 的方式进行过来,发现剩下 2 条日志:

从日志上看,基本耗时都在 18S,也读是百度爬虫那过来的;
既然都有日志了,那就模拟下看看是不是真要那么久,这里的模拟爬虫用的是百度熊掌号自带的工具:
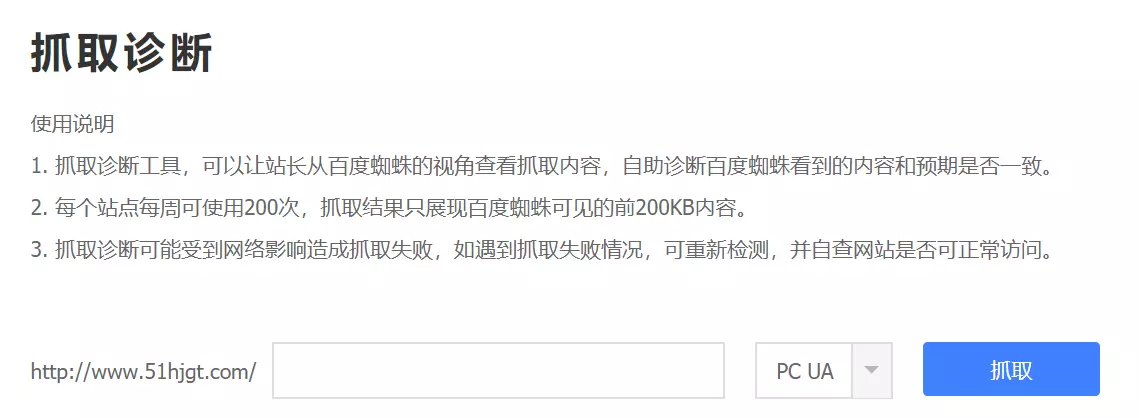
输入出现问题的地址,结果如下:

只需要关注最下面的下载时长:0.166s,重复多几次,依然如此;
这个后台的日志不一样,那就说明,这个问题不是必现的,而且有特定场景导致的;
从后台的日志上看,刚爬了几次的日志,也的确跟百度上显示的类似,那说明百度上的时长是可信的:

从上图可看出,最大一次也不超过 3S,与一开始反馈的 300S 相差甚远;
此时再去看下服务器的情况:
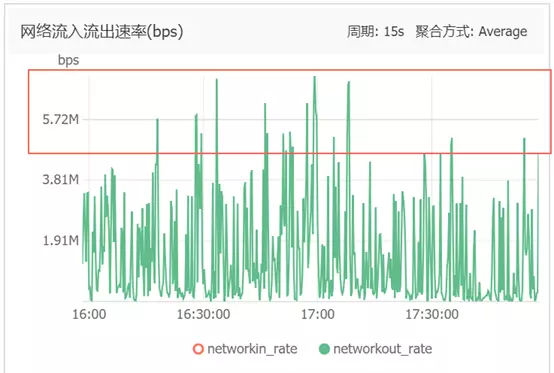
服务器是 5M 的带宽,从日志上看,的确有部分时间段是超过了 5M,而且出现爬取比较慢的时间刚好对的上服务器超过 5M 的时间;
因此该同学才敢说,怀疑是因为带宽,虽然听上去有点巧合,但是在百般无奈的情况下,只能相信是这种巧合了;
然后就调整带宽,观察几天,毕竟爬虫这种东西是靠别人的,心急不来,在等待的期间,做了 3 件事:
1)资料查询导致抓取时间达到几十万的情况
- 抓取该页面的时候部分图片无法抓取到;
- 链接超时;
- 百度内部调整导致;
从结果看,个人倾向 1、2 可能性大;
2)跟前端同学沟通下,后端返回的 18S,是怎样的标准?
回到文章顶部,有提及到这个网站架构是 node+nginx+php,那这 18S,
按照理解,应该就是 Php 返回到 nginx 的时间,那 nginx 到 node 中间传输会不会也有损耗,比如跟网速有关系、服务器性能等,都有可能有折损,然后 node 接收后,再渲染显示,等渲染完成,爬虫才认为整个过程完毕?(前面提及到,这里默认爬虫规则是开始请求到渲染完毕,但实际未知)
当时提到一个疑问,假如说,node 或者 nginx 有问题了,那是不是就会出现耗时很长的情况?
但当时因为没数据支撑,大家都觉得,嗯,有这种可能,这种想法一闪而过,但是有什么原因导致 node 或者 nginx 有问题,真没想到;
事实回头看,猜对了,的确是 node 出问题导致;
当也因为当时没想到,后面才更好的梳理了;
3)影响网络传输的原因有哪些?
找到一个答案,不知道对不对,仅参考:
线上响应速度取决于当前被访问的目的地带宽、并发数,还有,服务器机器当前使用时间,是否存在物理
存储器和各运算器控制器老化情况,以及发起爬取的机器信号发送和接收情况;
最重要的两点就是带宽,并发数,带宽验证是没影响,那这个会跟并发数有关吗?
再次梳理
回到正文,上线几天后发现,还是不行,依然有问题,说明带宽不是问题点,那怎么办?
上面提及到,既然带宽不是问题,那就可能跟并发数有关系了,而且爬虫过来肯定也是并发这么过,所以就把苗头对准并发了;
但是在实际去看并发之前,还是把逻辑梳理了一遍:

根据上面的信息,现在从后端 nginx 可以 get 到的是,PHP 和后端处理时间非常快,基本在 0.1-0.5 之间;
从流程上来看,前端负责接收和返回后端的是 nojs,所以有理由怀疑,异常发生的原因是在 node 层,结合上面的并发可能性,有可能是多并发,导致 nojs 进程 cpu 占用负载,导致处理时间加长。
这样也能很好地解释,为什么有的时候,抓取的时间只需要 0.1 到 0.5,但是有时却需要消耗长达 20 万毫秒;
既然有所怀疑,那就开始干吧~
实验
本次的实验目的很简单,就是在高并发的环境下,进行百度爬取的行为,看看数据是不是正常;
工具的选择,不纠结,压测用 apache ab,原因命令行,便捷,爬虫就直接用百度自带的;
分 3 组数据:
1)不使用并发,直接使用百度爬取
2)针对具体某一新闻页进行并发,并且爬取这条新闻页,链接
3)针对首页 (www.51hjgt.com) 进行并发,爬取上面的新闻页
并发命令:
ab -c 60 -n 100 http://www.51hjgt.com/
-n:执行请求的数量
-c:每个请求的并发连接数,理解成用户数也可以
结果发现,尝试多次,第三种情况下终于出现了抓起失败的情况!!撒花~


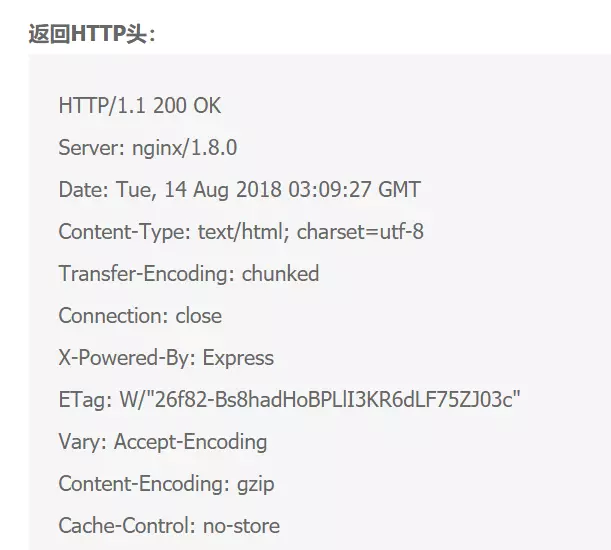
ok,虽然不是百分百能重现,但至少重现到一次了,也就说明的确有问题的;
下面是点击百度上的查看帮助里的内容:

Ok,拿着这个去跟前端反馈,结果前端负责人是这么回答的:
嗯,的确有可能存在这样的情况,原因是因为现在项目的 node 使用的是单进程,有可能会因并发问
题导致处理不来的情况,为什么要用单进程,是因为运维那边不会配置多进程导致的,这个下个版本
会处理;
嗯,这个问题就这样算是有个交代了;
小结
总结下这次遇到的问题吧;
收到问题->寻求数据如何统计->分析后端日志->压缩图片 size 及处理 404 问题->再次分析->怀疑跟带宽有关系->重新梳理流程,怀疑并发->验证->重现问题;
其实从上面的流程来说,貌似没太多的问题,在不了解或者不熟悉的业务上,也只能不停的去排查来验证假象;
但有个最大的问题是,像这类问题,理应第一时间想到并发跟带宽,但是在这次却是最后才想到,由此可见敏感度不够,无论是测试还是研发,对这种问题跟进能力比较欠缺,后面需要加强这类问题的敏感度;
上面提及到的压缩图片 size 和处理 404 的问题,即使没有这次的反馈,从网页本身考虑,本身就是需要去做的事情;
apache ab 介绍
最后,插一个 ab 的介绍,会的同学自行跳过,本文终;
对于网站而言,压测是必须要做的工作,那压测的工具有很多,jmeter,loadrunner,ab,那为什么会选择 ab?
个人觉得主要的原因是边界,命令行,windows\Linux\mac 都支持使用;
下载安装
但是试过好几次可能是网络原因,下载很慢,而且可能会断开,因为分享一个 2.3.4.3 版本的 zip 包,需要的同学自取:
链接:https://pan.baidu.com/s/1MRCmEoiUkwKBF1R6vu3HsQ
密码:seag
下载完就解压,使用 Windows 下的 cmd 命令行,去到刚解压的目录下的 bin 目录;

然后输入 ab,如果不报错,则说明是成功了;
当然,有同学觉得每次都进来这个目录很麻烦,那可以把 Apache24\bin 这个路径配置到环境变量,后续就可以直接 ab 使用了,具体 Windows 下环境变量怎么配置,网上搜索下,很多的~
直接压测网站
命令: ab -c 50 -n 50 http://www.baidu.com/
注意:网站地址,必须在后方加上"/",或指定相应文件。
执行后,就会有下图的结果输出:
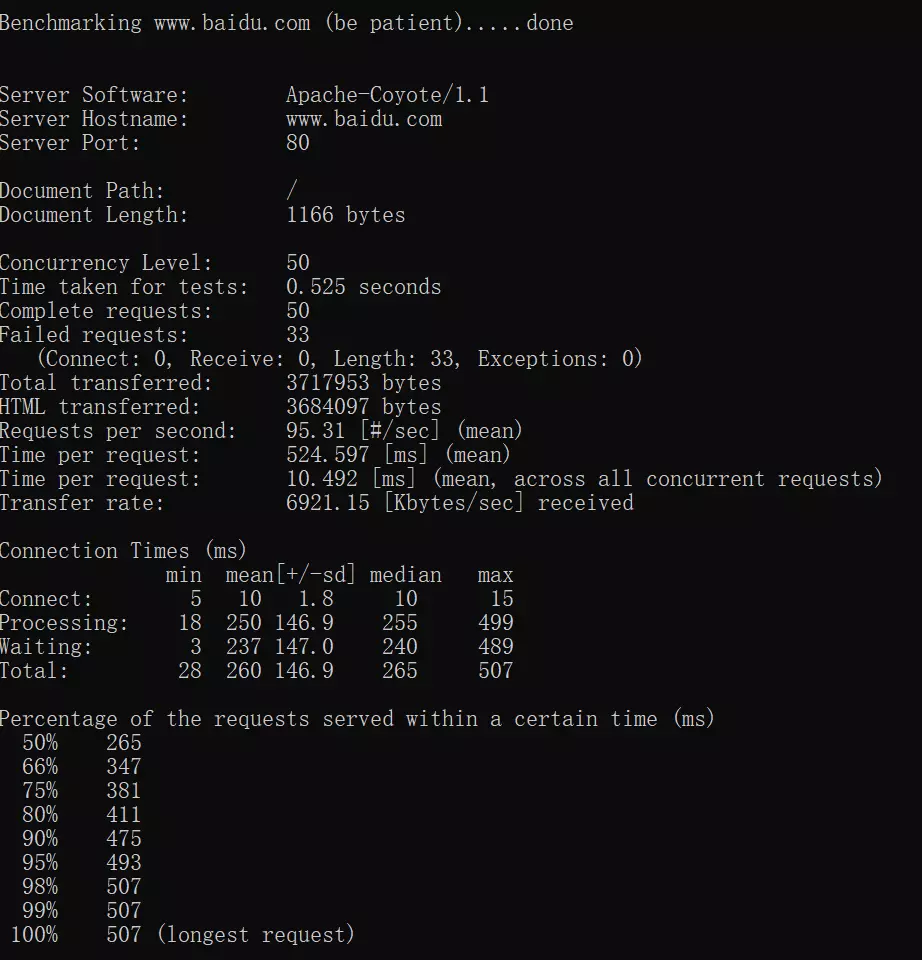
压测就是这么简单,但是要分析上图的内容,才有价值
这一陀看不懂?没关系,下面教你怎么看
ab 命令参数说明
第一次使用 ab 命令时,不知道有什么参数,可以输入 ab -help,然后就会弹出这么一坨东西:
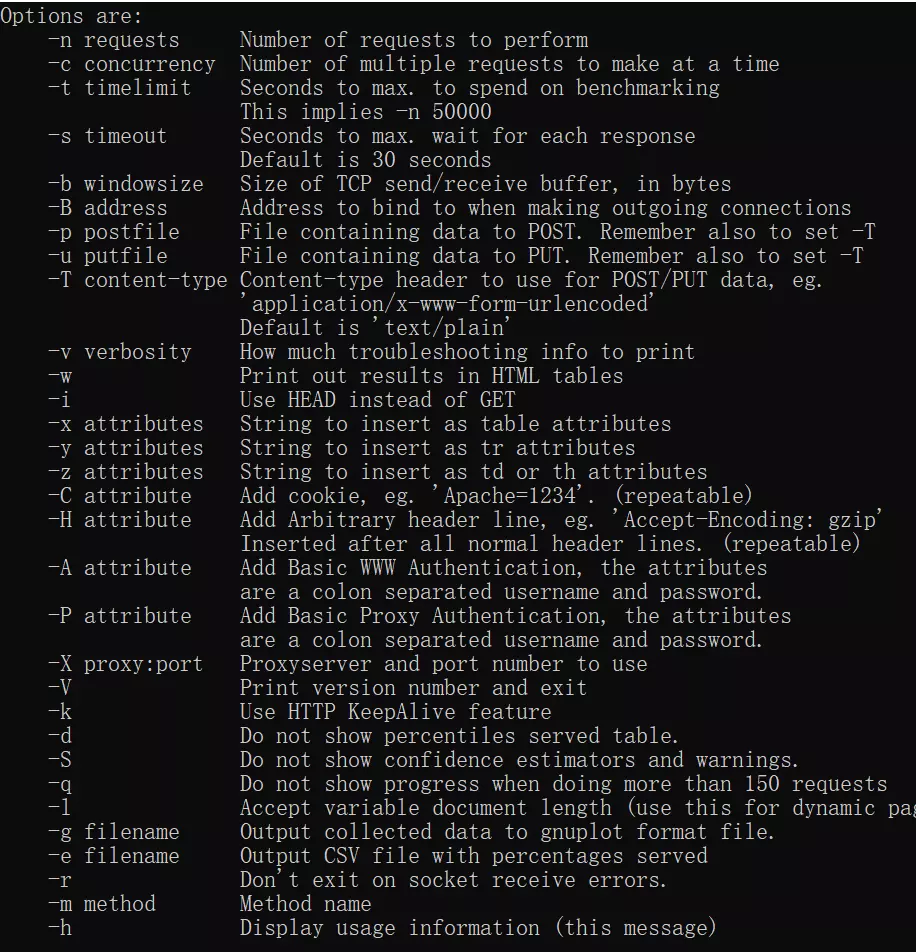
一般常用的参数就下面几个:
-n:执行请求的数量
-c:每个请求的并发连接数
-t:等待响应时间
-V:显示版本信息
更加多详细参数自行查询;
实例
ab -n 3000 -c 3000 https://www.baidu.com/
c 100 即:每次并发 3000 个
n 10000 即: 共发送 3000 个请求
ab -t 60 -c 100 https://www.baidu.com/
在 60 秒内发请求,一次 100 个请求。
带参数的的请求
ab -t 60 -c 100 -T "application/x-www-form-urlencoded" p p.txt https://www.baidu.com/jb.html
p.txt 是和 ab.exe 在一个目录 p.txt 中可以写参数,如 p=wdp&fq=78 要注意编码问题
参数中的三种形式
application/x-www-form-urlencoded (默认值)
就是设置表单传输的编码,典型的 post 请求
multipart/form-data.用来指定传输数据的特殊类型的,主要就是我们上传的非文本的内容,比如图片,mp3,文件等等
text/plain . 是纯文本传输的意思
结果分析
执行完后,会有这么一坨东西:
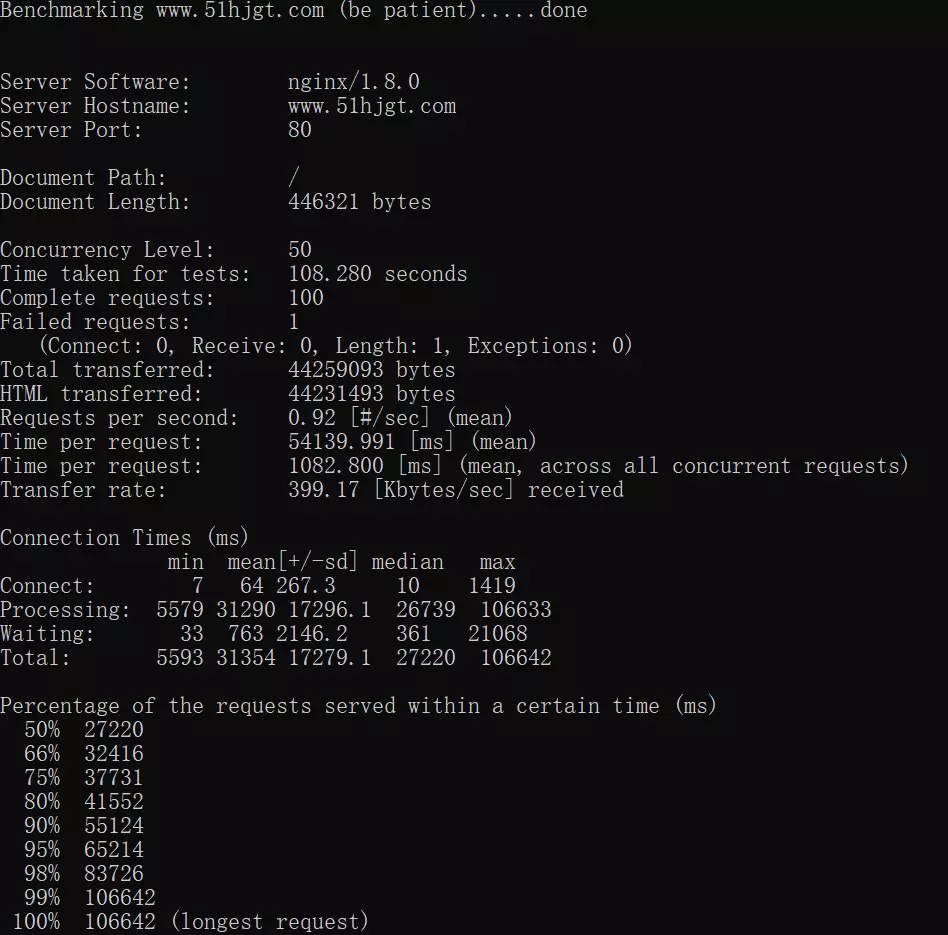
下面就来讲解,到底是什么意思:
This is ApacheBench, Version 2.3
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.80.157 (be patient)
Completed 400 requests
Completed 800 requests
Completed 1200 requests
Completed 1600 requests
Completed 2000 requests
Completed 2400 requests
Completed 2800 requests
Completed 3200 requests
Completed 3600 requests
Completed 4000 requests
Finished 4000 requests
Server Software: Apache/2.2.15
#Web服务器引擎
Server Hostname: 192.168.80.157
#服务器地址
Server Port: 80
#服务器端口
Document Path: /phpinfo.php
#请求的文件路径
Document Length: 50797 bytes
#文件大小
Concurrency Level: 1000
#测试的并发数
Time taken for tests: 11.846 seconds
#整个测试持续的时间,测试总耗时
Complete requests: 4000
#完成的请求数量,即成功收到返回的数目
Failed requests: 0
#失败的请求数量
Write errors: 0
Total transferred: 204586997 bytes
#整个过程中的网络传输量
HTML transferred: 203479961 bytes
#整个过程中的HTML内容传输量
Requests per second: 337.67 [#/sec] (mean)
#最重要的指标之一,相当于LR中的每秒事务数,后面括号中的mean表示这是一个平均值,即 每秒请求数,等于总请求数/测试总耗时,平均响应时间
Time per request: 2961.449 [ms] (mean)
#最重要的指标之二,相当于LR中的平均事务响应时间,后面括号中的mean表示这是一个平均值,可以理解为用户平均请求等待时间(响应时间)
Time per request: 2.961 [ms] (mean, across all concurrent requests)
#每个连接请求实际运行时间的平均值,可以理解为服务器平均请求等待时间(并发请求时间)
Transfer rate: 16866.07 [Kbytes/sec] received
#平均传输速率
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 483 1773.5 11 9052
Processing: 2 556 1459.1 255 11763
Waiting: 1 515 1459.8 220 11756
Total: 139 1039 2296.6 275 11843
#网络上消耗的时间的分解,响应时间小、中、大值
Percentage of the requests served within a certain time (ms)
50% 275
66% 298
75% 328
80% 373
90% 3260
95% 9075
98% 9267
99% 11713
100% 11843 (longest request)
#整个场景中所有请求的响应情况。在场景中每个请求都有一个响应时间,其中50%的用户响应时间
小于275毫秒,66%的用户响应时间小于298毫秒,最大的响应时间小于11843毫秒。对于并发请求,
cpu实际上并不是同时处理的,而是按照每个请求获得的时间片逐个轮转处理的,所以基本
上第一个Time per request时间约等于第二个Time per request时间乘以并发请求数。
使用 ab 常见的问题
1)ab 命令在一般系统上面做测试时候,一般并发不能超过 1024 个,其实是因为因为系统限制每个进程打开的最大文件数为 1024,可以用 ulimit -a 来查看;
2)-n 可以指定最大请求数,但是不能超过 50000 个;
3)-v n 当 n>=2 时,可以显示发送的 http 请求头,和响应的 http 头及内容,压力测试时不要这么做;
4) 在做压力测试的时候,一般情况下压力测试客户端接收到的数据量一定会远大于发送出去的数据量;
5)带参数的压力测试示例,ab https://www.baidu.com/?a=1&b=2&c=3
6)使用的时候,出现这个提示,The timeout specified has expired (70007),
原因是超时了,可以增加 -k(keep 的意思)参数,保持连接进行测试;

解决方案:
ab -c 50 -n 100 -k http://www.51hjgt.com/
大概就这样吧,谢谢大家~